上一篇文章(点击链接:点击链接阅读上一篇文章)讲了:
- CPU/IO消耗型进程
- 吞吐率 vs. 响应
- SCHED_FIFO算法 与 SCHED_RR算法
- SCHED_NORMAL算法 和 CFS算法
- nice与renice
- chrt
本篇文章接着上一篇文章讲解以下内容:
- 多核下负载均衡
- 中断负载均衡,RPS软中断负载均衡
- cgroups与CPU资源分群分配
- Linux为什么不是硬实时
- preempt-rt对Linux实时性的改造
1、多核下负载均衡
我们知道现在的CPU都是多核的。我们可以认为在同一时刻,同一个核中只能有一个进程(task_struct,调度单位但是task_struct)在运行。但是多核的时候,在同一个时刻,不同的核中的进程是可以同时运行的。

假设你电脑有四个核,现在每个核都在跑一个线程。各个核上都是独立的使用SCHED_FIFO算法、SCHED_RR算法与CFS完全公平调度算法去调度自己核上的task_struct,但是为了能够使整个系统的负载能够达到均衡(各个核的调度情况尽量保持一致,不要使某一个核太忙也不能使某一个核太轻松),某一个核也有可能会把自己的task_struct给另一个核,让另一个核来调度它。各个核都是以劳动为乐,会接收更多的任务,核与核之间进行pull与push操作将各自的task_struct给其他核或者拿其他核的task_struct来调度。这样的话,整个系统就会达到一种负载均衡的效果。我们称之为多核下的负载均衡。
那么不同的进程如何做到负载均衡呢?
- RT进程
N个优先级最高的进程分不到N个不同的核,使用pull_rt_task与push_rt_task来达到负载均衡的效果。RT进程的话,实际上强调的是实时性而不是负载均衡。
- 普通进程
分为:
- 周期性负载均衡(普通进程不会抢占,就所有的进程周期性的被各个核调度达到多个CPU的负载均衡)
- IDLE时负载均衡(某一个核假设为CPU1是空闲的,0号进程想要过来让CPU1跑,CPU1才不会去跑0号进程,CPU1会去看其他核是否在忙,如果其他核在忙,CPU1就会拿其他核的任务过来跑,CPU是尽量不会去跑0号进程的,因为一旦跑了0号进程,说明整个系统处于一种低功耗的状态,这种状态下整个系统只有0号进程会跑,其他进程都在休眠)
- fork和exec时负载均衡(fork会创建一个新的task_struct,而exec只是替换进程虚拟地址空间的.data与.text,当创建一个新的进程或者替换了一个新进程,就会把这个新的task_struct推给一个最空闲的核去调度。)
- 实验
two-loops.c
#include <stdio.h>
#include <pthread.h>
#include <sys/types.h>
void *thread_fun(void *param)
{
printf("thread pid:%d, tid:%lu\n", getpid(), pthread_self());
while (1) ;
return NULL;
}
int main(void)
{
pthread_t tid1, tid2;
int ret;
printf("main pid:%d, tid:%lu\n", getpid(), pthread_self());
ret = pthread_create(&tid1, NULL, thread_fun, NULL);
if (ret == -1) {
perror("cannot create new thread");
return 1;
}
ret = pthread_create(&tid2, NULL, thread_fun, NULL);
if (ret == -1) {
perror("cannot create new thread");
return 1;
}
if (pthread_join(tid1, NULL) != 0) {
perror("call pthread_join function fail");
return 1;
}
if (pthread_join(tid2, NULL) != 0) {
perror("call pthread_join function fail");
return 1;
}
return 0;
}
编译运行:
$ gcc two-loops.c -pthread
$ time ./a.out
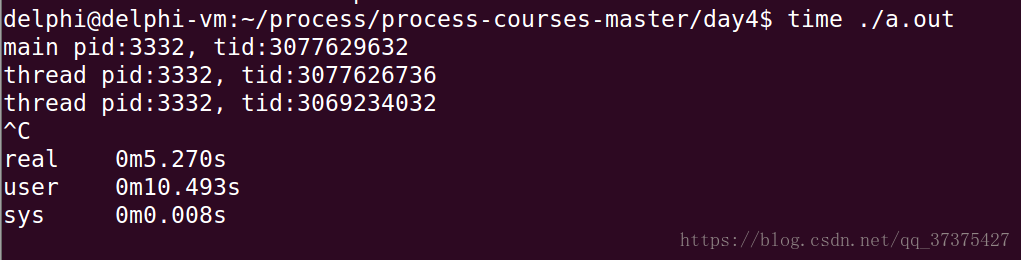
- 结果分析
由于我的虚拟机中Linux是两个核的,在两个核中分别跑的时间加起来,大概等于我们用户态的时间。这说明两个线程被分配到两个核中分别跑的。
2、CPU task affinity
affinity的意思是亲和,实际上我们这里是指,让task_struct对某一个或若干个CPU亲和。也就是让task_struct只在某几个核上跑,不去其他核上跑。这样实际上破坏了多核的负载均衡。
如何实现CPU task affinity?
- 可以在程序中直接写代码设置掩码
int pthread_attr_setaffinity_np(pthread_attr_t *, size_t, const cpu_set_t *);
int pthread_attr_getaffinity_np(pthread_attr_t *, size_t, cpu_set_t *);
int sched_setaffinity(pid_t pid, unsigned int cpusetsize, cpu_set_t *mask);
int sched_getaffinity(pid_t pid, unsigned int cpusetsize, cpu_set_t *mask);
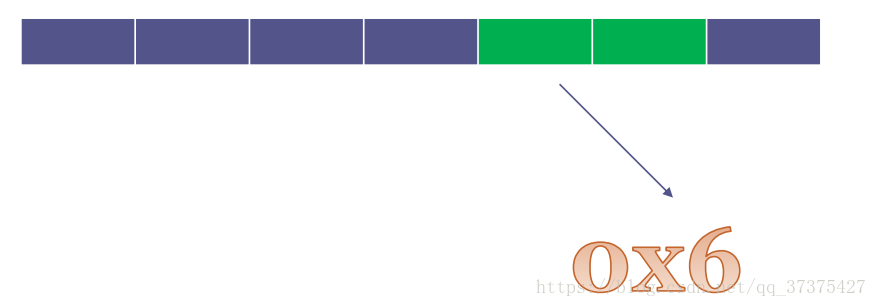
设置掩码来保证某一个线程对某几个核亲和,比如下方的0x6(110),就是设置线程只能在核2与核1上运行
- taskset工具
比如:
$ taskset -a -p 01 19999
-a:进程中的所有线程,01掩码,19999进程pid
- 实验
编译上述two-loops.c, gcc two-loops.c -pthread,运行一份
$ ./a.out &
top查看CPU占用率:
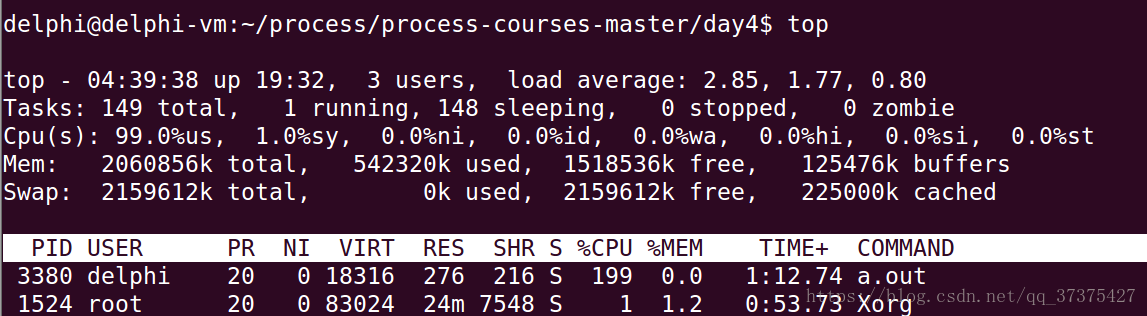
把它的所有线程affinity设置为01, 02, 03后分辨来看看CPU利用率
$ taskset -a -p 02 进程PID
$ taskset -a -p 01 进程PID
$ taskset -a -p 03 进程PID
- 前两次设置后,a.out CPU利用率应该接近100%,最后一次接近200%
3、IRQ affinity
中断也可以达到负载均衡。
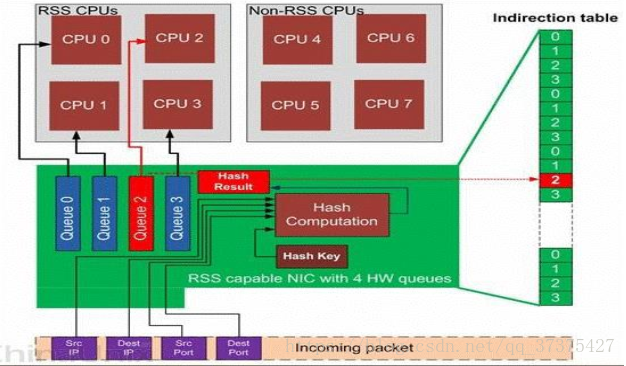
假设有四个网卡,当网卡收到数据,会触发中断,将四个网卡队列的中断均分给四个CPU
- mq ethernet
/proc/irq/74/smp_affinity 000001
/proc/irq/75/smp_affinity 000002
/proc/irq/76/smp_affinity 000004
/proc/irq/77/smp_affinity 000008
以上四个网卡的中断全部均分给了四个CPU。
当然中断也可以像进程一样让其affinity某个进程,比如向下面这样,可以让01号中断分配给某个CPU,让其affinity该CPU。
分配IRQ到某个CPU
[root@boss ~]# echo 01 > /proc/irq/145/smp_affinity
[root@boss ~]# cat /proc/irq/145/smp_affinity
00000001
有一种情况比较特殊:假设一个CPU0上有一个中断IRQ,该中断处理函数中可能会调用软中断(soft_irq)处理函数。那么这个软中断处理函数又会占用该CPU0。那么该CPU0就会处于非常忙的状态,达不到负载均衡。如何使软中断去其他核执行?
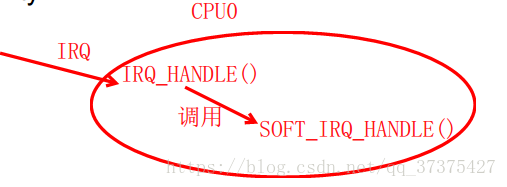
使用RPS解决多核间的softIRQ scaling 。
RPS可以将包处理(中断里面的处理,其实就是软中断)负载均衡到多个CPU
例如:
[root@machine1 ~]# echo fffe > /sys/class/net/eth1/queues/rx-0/rps_cpus
将中断分配给0~15的核,这样可以使所有核共同处理中断以及中断内部的软中断,处理TCP/IP包的解析过程
4、进程间的分群(cgroup)
进程间的分群:假设有一个编译Android系统的服务器,两个人A与B同时要使用该服务器编译程序,A编译程序创建了1000个线程,B编译程序创建了32个线程,那么如果按正常的CFS调度的话,A的程序会获得1000/1032的CPU时间,B的程序会获得32/1032的CPU时间,这样的话就会导致编译B可能会花与A相同的时间才能将程序编译完,这样就显得很对B不公平(想想我B本身可能是一个小程序,却要编译半天,多难受啊)。Linux为了解决类似的这种问题,采用了进程间的分群思想:让A的线程放在一个群中,B的线程放在一个群中,给A群与B群采用CFS调度各个群,然后再在A群与B群内部采用CFS调度群内的进程。这样的话,就显得公平一些。不会说编译一个小程序花费太多时间。
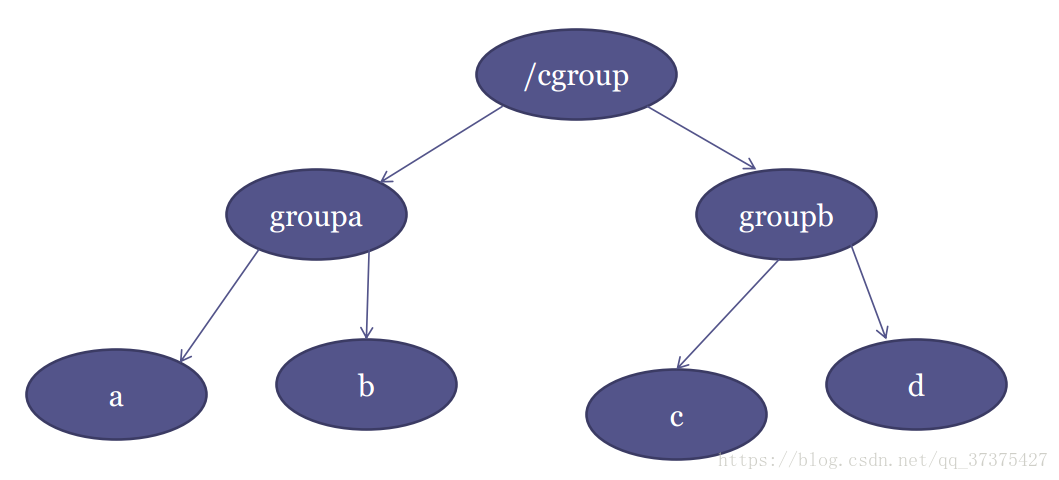
实际上分群使用的是树结构,上图可以清晰的理解。
- 实验
编译two-loops.c, gcc two-loops.c -pthread,运行三份
$ ./a.out &
$ ./a.out &
$ ./a.out &
用top观察CPU利用率,大概各自66%。

-
创建A,B两个cgroup
/sys/fs/cgroup/cpu$ sudo mkdir A
/sys/fs/cgroup/cpu$ sudo mkdir B -
把3个a.out中的2个加到A,1个加到B。
/sys/fs/cgroup/cpu/A$ sudo sh -c ‘echo 3407 > cgroup.procs’
/sys/fs/cgroup/cpu/A$ sudo sh -c ‘echo 3413 > cgroup.procs’
/sys/fs/cgroup/cpu/A$ cd …
/sys/fs/cgroup/cpu$ cd B/
/sys/fs/cgroup/cpu/B$ sudo sh -c ‘echo 3410 > cgroup.procs’ -
这次发现3个a.out的CPU利用率大概是50%, 50%, 100%。
5、 Hard realtime - 可预期性
硬实时:可预期性。当一个线程被唤醒,直到这个线程被调度的这个时间段,不超过某一个预定的截止期限。称为硬实时。如果该线程被唤醒后,被调度的时间允许超过那个截止期限,那么就不是硬实时。Linux系统不是硬实时。
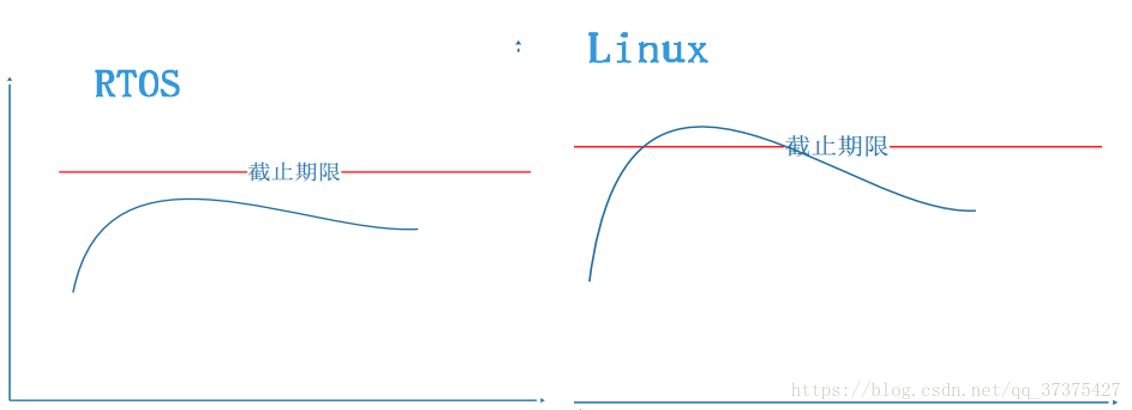
以上图我们可以看到。Linux系统并不是硬实时系统,也就是说对于一个进程,什么时间之前(注意我们不能说在什么时候能够被调度到,因为我们无法确定一个进程什么时候能够被调度到)能够被调度到,我们并不知道。那么Linux为什么不是硬实时?
首先我们需要理解Linux系统中,有四类区间:
当Linux跑起来后,CPU的时间都花在上述四类区间上。
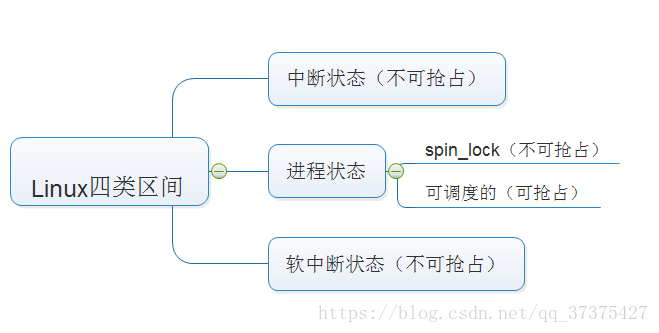
- 中断状态:
当系统中有中断,CPU不能再调度任何其他进程,就算RT进程来了也一样得等着中断结束后的一瞬间才能抢占CPU。而且,在中断中,不能再进行中断,也就是说,中断必须结束才能干其他事。中断是必须要被处理的。
- 软中断
软中断中可以被中断。但是软中断中如果唤醒一个RT进程,此RT进程也不会被调度。
- 进程处于spin_lock(自旋锁)
自旋锁是发生在两个核之间的。当某一个核如CPU0上的进程获取spin_lock后,该核的调度器将被关闭。如果另一个核如CPU1的进程task_struct1此时想要获取spin_lock,那么task_struct1将自旋。自旋的意思就是不停的来查看是否spin_lock被解锁,不停的占用CPU直到可以获取spin_lock为止。
所以进程如果处于spin_lock,那么其他任何进程不会被调度。
- 进程处于THREAD_RUNNING态
当进程处于THREAD_RUNNING态,它就是可调度的,只有在这种状态下,CPU才支持抢占。也就是说在这种状态,加入CPU正在运行一个普通进程,此时如果某一个RT进程被唤醒,那么该RT进程就会去抢占CPU。
上述四类区间:如果可抢占的RT进程被唤醒在前三类区间,那么该RT进程,必须等待这三类区间的事件完成结束的一瞬间抢占,否则RT进程也不会被CPU调度。如果在第四类区间上唤醒一个RT进程,则该RT进程立即抢占CPU。
理解了以上四类区间,就很容易理解Linux为什么不是硬实时了,看下图:
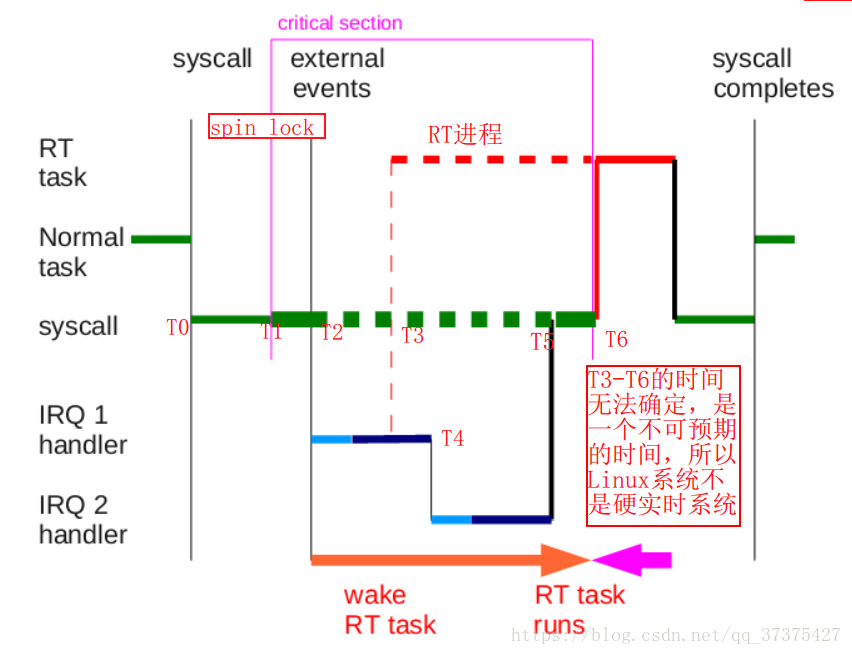
分析:
上图横轴为时间轴。T0,T1,T2…为某一时刻。
- 系统运行分析:
在T0时刻,假设有一个四通调用陷入到内核中。此时在跑的是一个普通进程(Normal task),在T1时刻,该Normal task获取了一个spin_lock。
到了T2时刻,突然来了一个中断IRQ1,则系统执行中断处理函数IRQ1 handle人(),再中断处理函数中又调用软中断(Soft IRQ),在软中断中的T3时刻,唤醒了一个RT进程。此时由于系统处于软中断状态,所以RT进程无法抢占CPU(红色虚线部分为无法抢占CPU)。在T4(软中断执行期间)时刻,又来了一个中断IRQ2(说明软中断中可以中断),然后系统执行中断处理函数IRQ2 handler(),然后执行软中断处理函数。到T5时刻中断与软中断执行完毕。但是由于此时Normal task还处于spin_lock状态,所以之前被唤醒的RT进程还是依然无法占用CPU。直到T6时刻,Normal task释放了spin_lock的一瞬间,RT进程抢占了CPU。当RT进程执行完,才会把CPU还给最开始还没有执行完的Normal task。Normal task执行完后,退出内核的系统调用。
- 结果分析:
从以上分析可以看出,从T3时刻RT进程被唤醒,到T6时刻,RT进程开始执行,这段时间,我们是无法预测的,我们无法给出一个有限的上限值来度量T6-T3的值。因为在这期间,有可能会来各种中断,有可能进程会一直处于spin_lock状态不放。所以,我们无法确定T6-T3的时间段。所以根据硬实时的概念知,Linux系统,不是硬实时。
6、PREEMPT_RT补丁
可以对Linux系统打实时补丁来增加Linux 的实时性。
比如PREEMPT_RT补丁,主要的原理如下:
- spinlock迁移为可调度的mutex,同时报了raw_spinlock_t
- 实现优先级继承协议
- 中断线程化
- 软中断线程化
将spin_lock与中断,软中断,都改造成第四类区间的可调度区间,就可以实现Linux系统的硬实时性。比如当中断线程化,当产生中断时,不执行中断处理程序,直接返回。只有很小的区间是不可抢占的。
- 以上四种方法原理,后期会详细研究,这里不再赘述。
7、总结
本文主要掌握:
- 多核下负载均衡
- 中断负载均衡,RPS软中断负载均衡
- cgroups与CPU资源分群分配
- Linux为什么不是硬实时
- preempt-rt对Linux实时性的改造
探讨学习加:
qq:1126137994
微信:liu1126137994