文章目录
第一节:关于函数
函数的基本概念
【函数】,是将一段代码进行封装和命名,这个名称对应的就是一个函数,调用该名称即等于执行该代码段;
【函数参数】,是调用者给函数传入的值;
【返回值】,是函数返回给调用者的结果;
函数的定义和调用
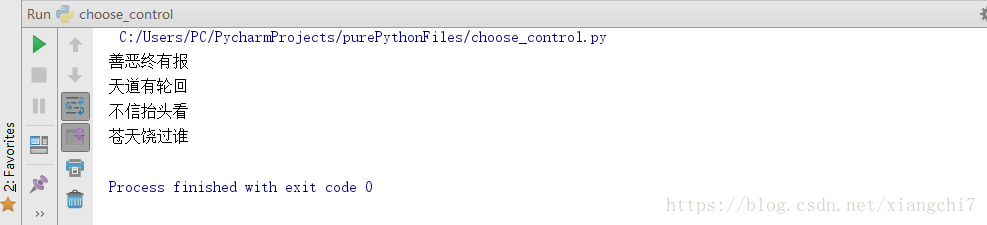
本例定义一个函数talk(),通过调用talk(),即打印四句话
# 定义一个函数
def talk():
# 缩进的部分是函数体,函数体的范围叫做这个函数的作用域
print("善恶终有报")
print("天道有轮回")
print("不信抬头看")
print("苍天饶过谁")
# 调用该函数,注意此处的缩进
talk()
执行结果:
函数的参数和返回值
# 加入两个参数,分别由两人说两句
def talk(man1,man2):
# 缩进的部分是函数体,函数体的范围叫做这个函数的作用域
print("%s说:善恶终有报" % man1)
print("%s说:天道有轮回" % man1)
print("%s说:不信抬头看" % man2)
print("%s说:苍天饶过谁" % man2)
return "你要我说什么?"
# 调用该函数,输入参数
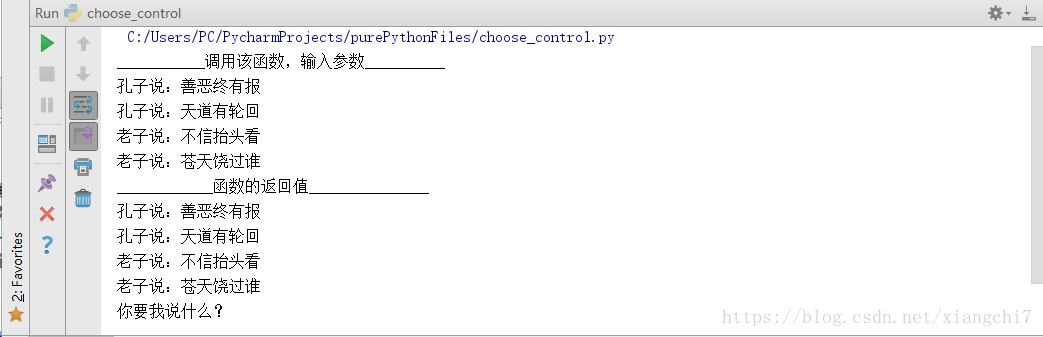
talk("孔子","老子")
# 直接打印此函数,看返回给函数的返回值是什么
print(talk("孔子","老子"))
执行结果:
函数的作用
将重复使用的代码片段进行封装,以提高代码的易用性和复用率;
第二节:函数参数
位置参数 & 关键字参数
【位置参数】,在函数的参数定义中仅仅给出参数名称的参数;在下面的函数定义中,
man1和man2是位置参数;
【关键字参数】,在函数的参数定义中以key=default_value形式给出的参数,下面的函数中place、date是关键字参数,因为都是以键值对形式进行定义的;
【注意】在函数定义时,通常把关键字参数定义在位置参数的后面,位置参数是要按顺序传,而且必须传
例如
# 加入位置参数和关键字参数
def talk(man1,man2,place="书塾",date='10月16日'):
#使用位置参数
print("%s说:善恶终有报" % man1)
print("%s说:天道有轮回" % man1)
print("%s说:不信抬头看" % man2)
print("%s说:苍天饶过谁" % man2)
#使用关键字参数
print("——%s 于 %s"%(date,place))
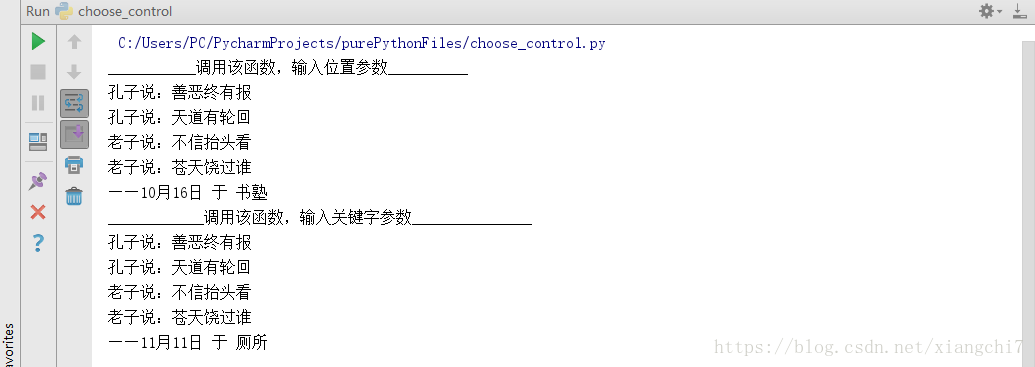
# 调用该函数,输入位置参数
talk("孔子","老子")
#调用该函数,输入关键字参数
talk("孔子","老子",date="11月11日",place="厕所")
执行结果:
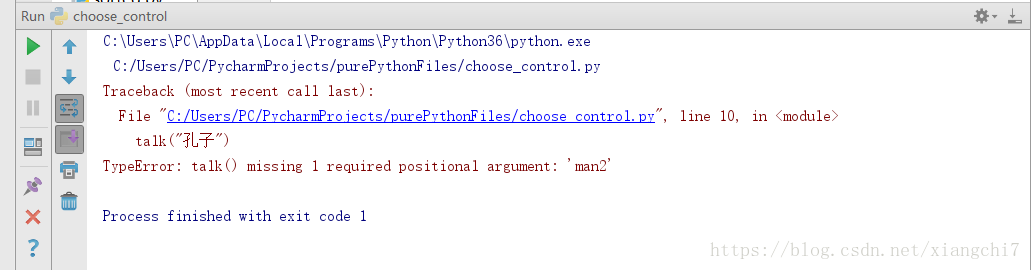
位置参数的传参原则:位置参数一个也不能少、顺序也不能乱,对位置参数传参时如果少传或者乱序传入,会引起
TypeError,而不能正常执行
比如上面的例子:
def talk(man1,man2,place="书塾",date='10月16日'):
print("%s说:善恶终有报" % man1)
print("%s说:天道有轮回" % man1)
print("%s说:不信抬头看" % man2)
print("%s说:苍天饶过谁" % man2)
print("——%s 于 %s"%(date,place))
# 调用该函数,但位置参数只输少了
talk("孔子")
执行结果:
关键字参数传参原则:
关键字参数是选传的,而不是必传的,当不传时传用默认值。可以以key=value形式进行传参,此时传参的顺序是可以随意的。也可以省去key,直接传value,但此时传参的顺序就必须与函数参数定义的顺序保持一致
不定长参数
- 不定长位置参数
*args
使用不定长位置参数,用于表示任意多个位置参数;
Python标准库中习惯使用*args来命名不定长位置参数,不定长位置参数的类型为元组;
以下用一个例子说明不定长位置参数,使用*someone,表示不确定有多少人点赞,注意*args要放在关键字参数的前面、位置参数的后面。
def talk(man1,man2,*someone,place="书塾",date='10月16日',):
print("%s说:善恶终有报" % man1)
print("%s说:天道有轮回" % man1)
print("%s说:不信抬头看" % man2)
print("%s说:苍天饶过谁" % man2)
print("——%s 于 %s"%(date,place))
#这里因为有*someone,无论有多少点赞者都照单全收,而且是用元组表示
print(someone,"表示点赞!")
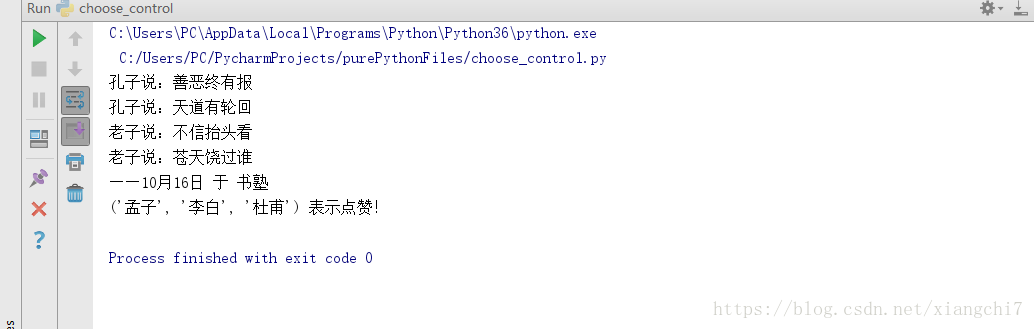
# 调用该函数,输入位置参数和不定长位置参数
talk("孔子","老子","孟子","李白","杜甫",)
执行结果:
- 不定长关键字参数
**kwargs
使用不定长关键字参数,用于表示任意多个关键字参数;
Python标准库中习惯使用**kwargs来命名不定长位置参数,不定长关键字参数的类型为字典;并且要安排在最后
例如:
def talk(man1,man2,*args,place="书塾",date='10月16日',**kwargs):
print("%s说:善恶终有报" % man1)
print("%s说:天道有轮回" % man1)
print("%s说:不信抬头看" % man2)
print("%s说:苍天饶过谁" % man2)
print("——%s 于 %s"%(date,place))
print(args,"表示点赞!")
print('评论:',kwargs)
# 调用该函数,输入各种参数,注意不定长关键字参数一定要在最后
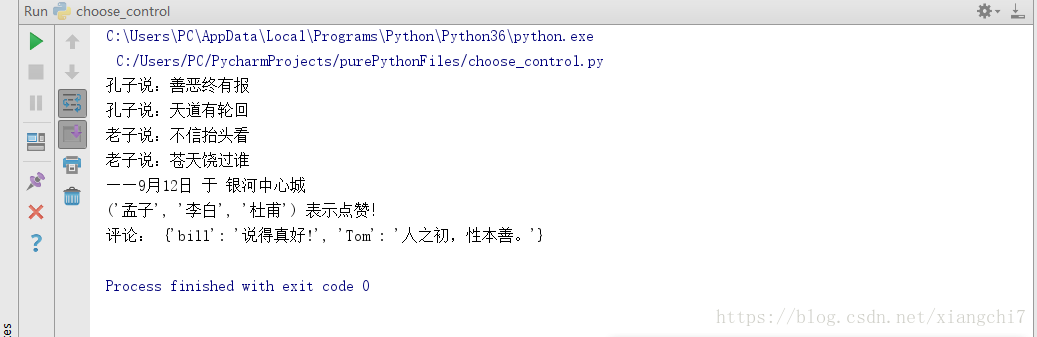
talk(
"孔子","老子", # 位置参数
"孟子","李白","杜甫", # 不定长位置参数
date="9月12日",place="银河中心城", # 关键字参数
bill = '说得真好!',Tom = '人之初,性本善。' # 不定长关键字参数
)
执行结果:
参数顺序总结:位置参数-不定长位置参数-关键字参数-不定长关键字参数
第三节:函数返回值
- 反回值
函数返回值是函数体返回给函数的一个结果,如果函数体没有返回一个结果给函数,那么,此时的的返回值就是
None
- 多个返回值
Python语言中的函数返回值可以是一个,也可以是多个,这是Python相比其他语言的简便和灵活之处;
接收者可以用一个结果来接收多个返回值,此时该结果的类型是元组;
接收者也可以用多个变量来接收多个结果,此时变量的个数和返回值的个数应相等;
例如:
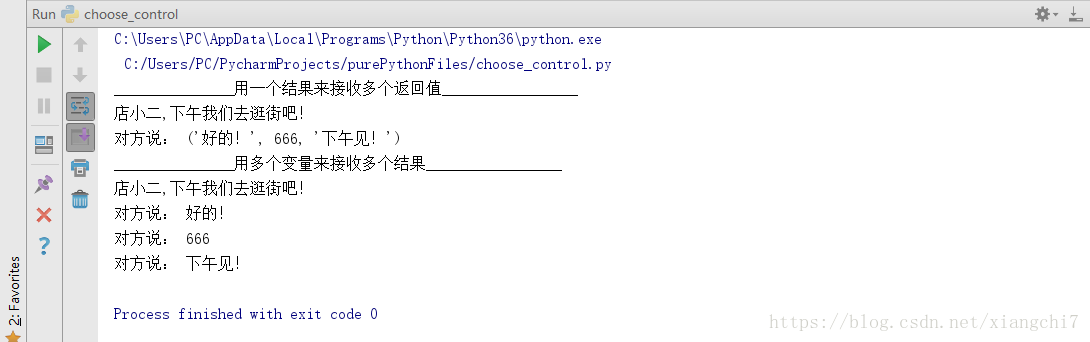
def date(man):
print('%s,下午我们去逛街吧!'%man)
#一次返回多个返回值
return '好的!',666,'下午见!'
if __name__ == '__main__':
# 用一个结果来接收多个返回,类型是元组
ret = date('店小二')
print('对方说:',ret)
# 用多个变量来接收多个结果
r1 , r2 , r3 = date('店小二')
print('对方说:',r1)
print('对方说:',r2)
print('对方说:',r3)
执行结果:
第四节:变量作用域
局部变量&全局变量
变量根据其作用域不同,可以分为
局部变量、全局变量;
【局部变量】是只在函数内起作用的变量、在函数外部无法访问;局部变量随函数执行而创建,随函数的结束而消亡,其生命周期只在函数执行中;
【全局变量】是定义在函数外的变量,函数内外都可以访问;函数内访问全局变量要使用global关键字;全局变量的生命周期与程序本身是相同的(除非使用del xxx进行删除);
形式参数&实际参数
函数方法定义中的参数名称,我们称之为形式参数;形式参数的名称是任意的,它是接收实际参数的一个符号,在函数未被调用时,它是没有值的;
在调用函数时传入的参数的【值】,称为实际参数;
【形参】与【实参】的关系,即【定义】与【传参】,亦即【符号】与【实值】;
形参将实参接入函数内部,是一个局部变量;
基本类型的函数传参是拷贝式的,也就是说,无论实参在函数内部被重新赋值多少次,对外界的“本体”都是没有影响的;
对象类型的函数传参是引用式的,函数内的改变,会影响函数外
例:
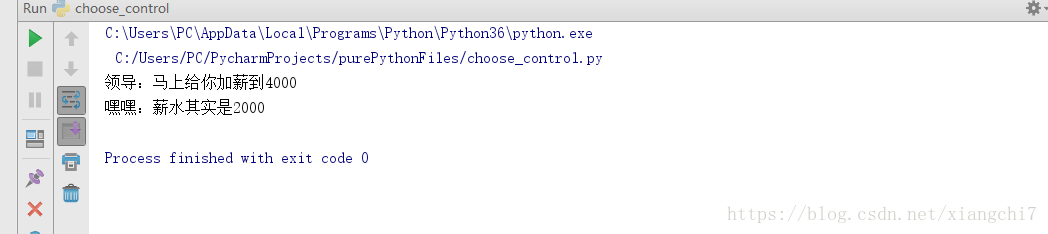
def raiseSalary(salary):
# 将参数增大
salary *= 2
print("领导:马上给你加薪到%d"%(salary))
if __name__ == '__main__':
# 加薪以前的薪水
salary = 2000
# 执行加薪函数,实参为2000
raiseSalary(salary)
#实参salary到函数内部变成了拷贝,拷贝版只是一个局部变量,函数结束以后消失于无形,对实参不产生任何实际影响
print("嘿嘿:薪水其实是%d"%(salary))
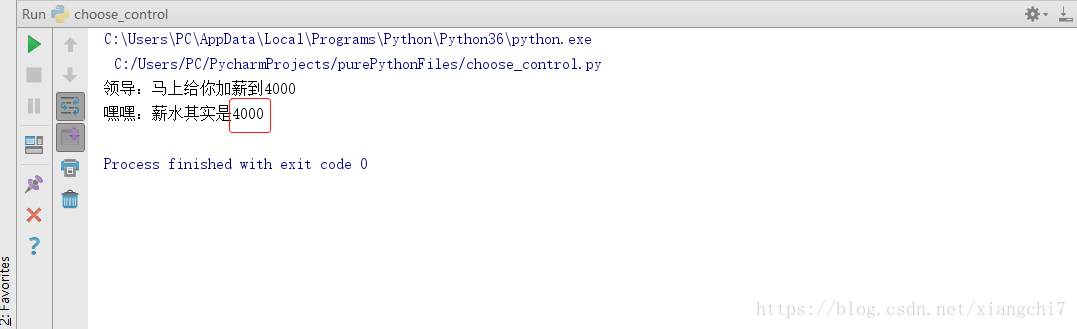
执行结果:
总结:我们发现函数外的那个值为2000的salary,在函数内被修改为4000,但函数执行结束后,其值依然为2000。这是因为,当raiseSalary(salary)时,只是拷贝了salary的值而已,因此无论函数如何修改拷贝形成的局部变量,对全局变量salary都是没有任何影响的!如果想要实际访问和修改全局变量,函数内要加
global关键字进行声明.
例如:
def raiseSalary():
#明使用全局变量salary
global salary
salary *= 2
print("领导:马上给你加薪到%d"%(salary))
if __name__ == '__main__':
# 加薪以前的薪水
salary = 2000
# 执行加薪函数,函数使用了全局变量,对salary进行了修改
raiseSalary()
print("嘿嘿:薪水其实是%d"%(salary))
执行结果:
第五节:函数的封装与复用
封装ASCII字符生成器
ord()——把ASCII字符转为对应的序号chr()——把ASCII序号转为对应的字符
例:
新建一个python文档,自定义一个名字(这里取名为character)
在character.py文档,写入几个方法:
import random
# 方法一:在起止字符之间随机生成一个中间字符
def getRandomCharBetween(startChar, endChar):
start = ord(startChar) # 得到字符的序号
end = ord(endChar) # 得到字符的序号
index = random.randint(start, end) #序号中随机取一个
letter = chr(index) #得到序号对应的字符
return letter
#方法二: 随机获取小写字母
def getRandomLowerCase():
#调用上面方法一,获取‘a’-‘z’的随机字母
letter = getRandomCharBetween('a', 'z')
return letter
# 方法三:随机获取大写字母
def getRandomUpperCase():
# 调用上面方法一,获取‘A’-‘Z’的随机字母
letter = getRandomCharBetween('A', 'Z')
return letter
# 方法四:生成随机数字字符
def getRandomNumber():
# 调用上面方法一,获取‘0’-‘9’的随机数字
char = getRandomCharBetween('0', '9')
return char
# 方法五:随机获取任意一个ASCII字符
def getRandomASCII():
startChar = chr(0) #得到序号0对应的字符
endChar = chr(127) #得到序号127对应的字符
# 调用上面方法一,获取字符间的随机字符
char = getRandomCharBetween(startChar, endChar)
return char
这样就完成了对ASCII字符生成器模块的封装,里面有几个生成方法,方便日后的使用,而不必再一点一点的重新写关于随机字符的代码。
复用模块
完成了自定义的模块的封装,就可以把其看作是一个工具来进行使用,以下在一个全新的python文档中使用自己封装好的character模块
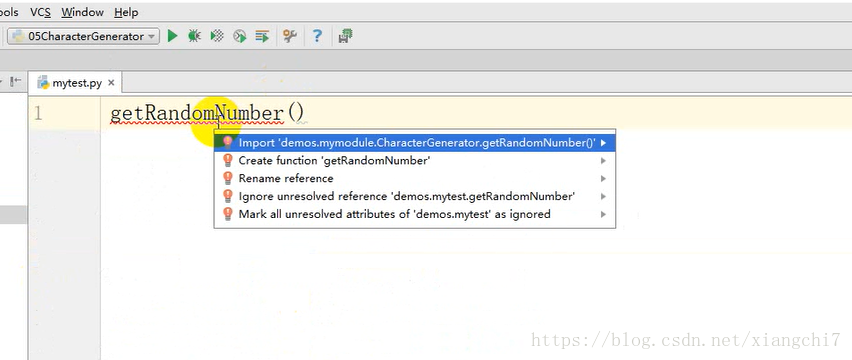
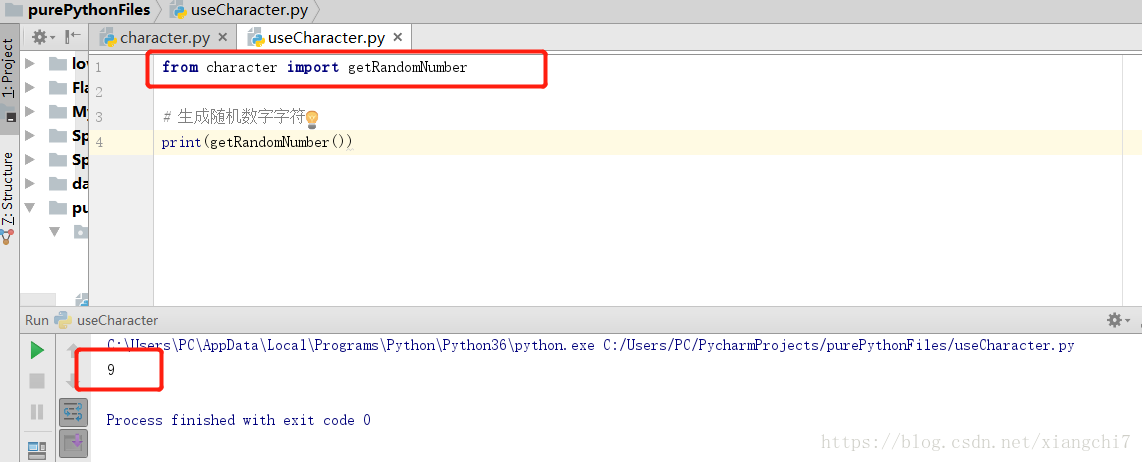
例:获取0-9随机数字,把光标放在getRandomNumber()方法上,使用快捷键Alt+Enter,调用曾经写的模块的方法四:
把这个方法生成的结果print()一下,便可生成随机数字:
同样道理,其实我们所使用的所有API,都是第三方库模块中的方法
标准库与第三方库
python标准库和第三方库的区别
- python的标准库是随着pyhon安装的时候默认自带的库。
- python的第三方库,需要下载后安装到python的安装目录下,不同的第三方库安装及使用方法不同。
- 它们调用方式是一样的,都需要用import语句调用。
简单的说,一个是默认自带不需要下载安装的库,一个是需要下载安装的库。它们的调用方式是一样的。
标准库与第三方库的位置
-
标准库 ——lib 目录下(home 目录/pythonXX.XX/lib)
-
第三方库 ——在 lib 下的 site-packages 目录下
第七节:迭代器与生成器
可迭代对象iterable
迭代就是逐个审查,但不一定要完成全部遍历(这是迭代与遍历的区别);
可迭代对象就是由若干并列的子元素集合而成的对象;
常见的容器和字符串都属于可迭代对象;
例:
# 字符串和常见的容器都是可迭代对象,迭代出来的是一个个的元素
iterable1 = "hello"
iterable2 = (1,2,3,4,5)
iterable3 = [1,2,3,4,5]
iterable4 = {1,2,3,4,5}
# 迭代器访问字典时,迭代出来的元素为键
iterable5 = {1:"hello",2:345,3:None,4:[1,2,3],5:""}
迭代器
基于一个可迭代对象,我们可以创建它的迭代器;
有了迭代器,我们就可以对可迭代对象中的元素进行逐个审查(但不一定要完成遍历);
iter()
# 创建基于iterable的迭代器
it = iter(miterable)
迭代器的迭代操作
- 通过
next(it)的方式,可以对迭代器进行轮询迭代; - 但迭代已经完成时继续迭代,系统会抛出
StopIteration异常;
例:
iterable1 = [6,5,3,7,4,8]
#创建基于iterable的迭代器
it = iter(iterable1)
# 通过next(it)逐个访问
print(next(it)) # 6
print(next(it)) # 5
print(next(it)) # 3
print(next(it)) # 7
print(next(it)) # 4
print(next(it)) # 8
# 迭代已经完成时,如果继续迭代,系统会抛出StopIteration异常
print(next(it))
- 使用
next(it)配合异常捕获,我们可以实现对迭代器的完整遍历
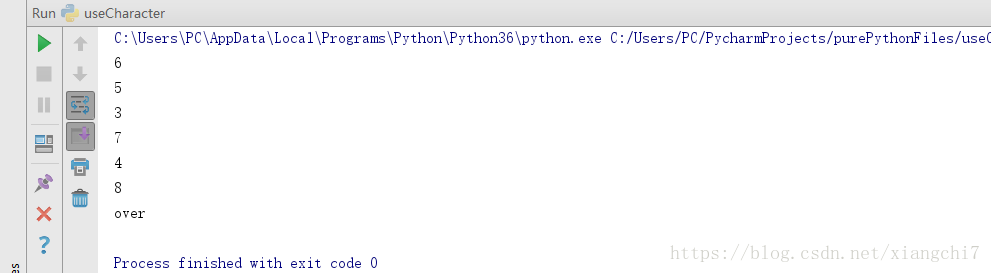
iterable1 = [6,5,3,7,4,8]
#创建基于iterable的迭代器
it = iter(iterable1)
while True:
try:
print(next(it))
# 当遍历到越界时会抛出StopIteration异常,此时break
except StopIteration:
break
print("over")
执行结果:
生成器
生成器是一种分多次进行“返回”(即生成)的函数;
生成器是迭代器的一种,所以一个生成器对象可以通过next(it)的方式来进行轮询迭代,也就是分批次地生成数据;
它不同于常规函数,一次性地垄断一定的CPU时间片,完成返回后再彻底让出CPU,生成器是在每次生成(yield value)过后,暂时性地让出CPU执行权给外界,直到下一次的数据请求,即next(it)发生时,再重新拿回CPU的执行权;
即:像纸抽似的,请求一次生成一次,直至迭代结束(系统抛出StopIteration错误);
例:
import time
def myGenerator():
mlist = [1,2,3]
# 一次性地返回内容,函数结束
# return mlist[0],mlist[1]
# 生成:每次“返回”一部分,分多次完成全部“返回”
for item in mlist:
print("yield %d..." % (item))
yield item # 完成一次生成后,函数并未结束,但CPU执行权被让出,直到下一次的数据请求发生
# 外界下一次提出数据请求时,才会执行到这里
print("yield next!")
it = iter(myGenerator())
# print(type(mg)) # <class 'generator'>
while True:
try:
print("give me one")
# 分批次向生成器索取数据
item = next(it)
print("-----item=%d-----\n" % (item))
time.sleep(3)
# 像迭代器一样捕获迭代停止异常
except StopIteration:
break
执行结果:
