问题种类
时间复杂度
在集合里数据量小的情况下时间复杂度对于性能的影响看起来微乎其微。但如果某个开发的功能是一个公共功能,无法预料调用者传入数据的量时,这个复杂度的优化显得非常重要了。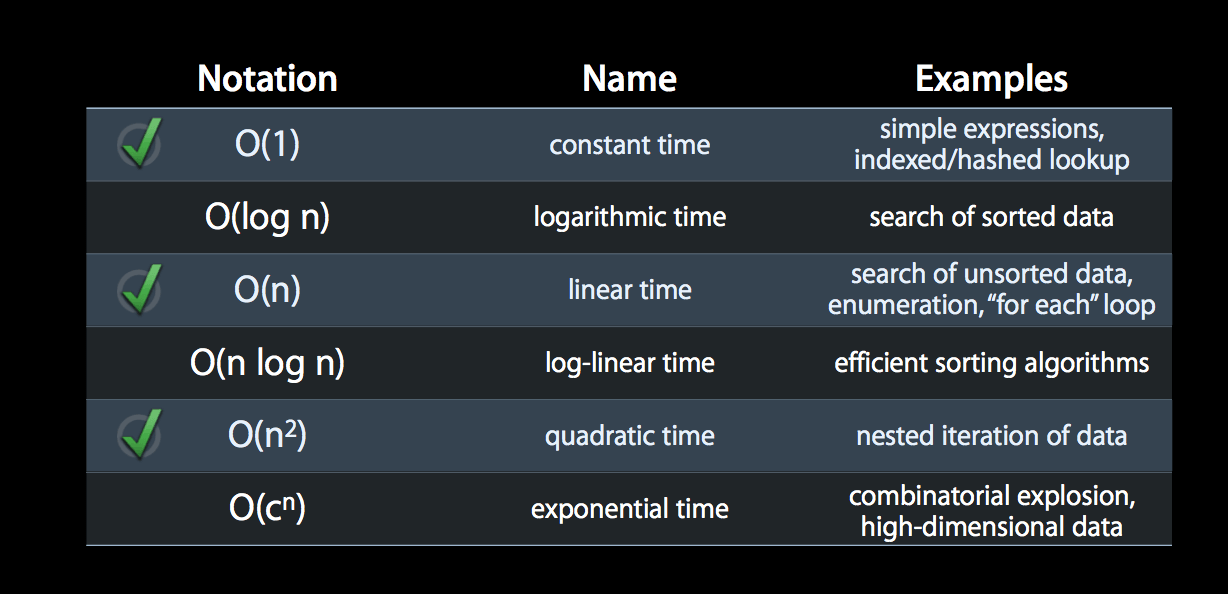
上图列出了各种情况的时间复杂度,比如高效的排序算法一般都是 O(n log n)。接下来看看下图: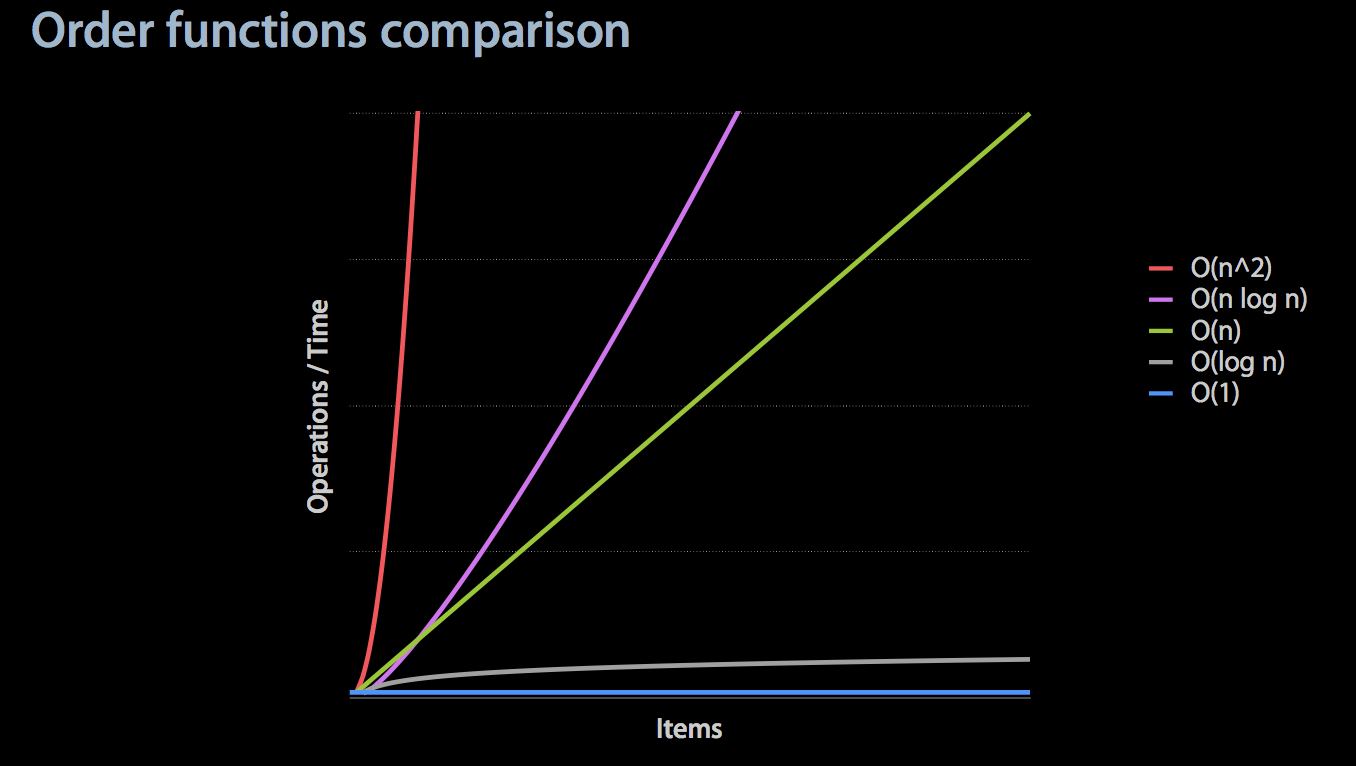
图中可以看出 O(n) 是个分水岭,大于它对于性能就具有很大的潜在影响,如果是个公共的接口一定要加上说明,自己调用也要做到心中有数。当然最好是通过算法优化或者使用合适的系统接口方法,权衡内存消耗争取通过空间来换取时间。
下面通过集合里是否有某个值来举个例子:
那么 OC 里几种常用集合对象提供的接口方法时间复杂度是怎么样的。
NSArray / NSMutableArray
首先我们发现他们是有排序,并允许重复元素存在的,那么这么设计就表明了集合存储没法使用里面的元素做 hash table 的 key 进行相关的快速操作,。所以不同功能接口方法性能是会有很大的差异。
- containsObject:,containsObject:,indexOfObject*,removeObject: 会遍历里面元素查看是否与之匹对,所以复杂度等于或大于 O(n)
- objectAtIndex:,firstObject:,lastObject:,addObject:,removeLastObject: 这些只针对栈顶栈底操作的时间复杂度都是 O(1)
- indexOfObject:inSortedRange:options:usingComparator: 使用的是二分查找,时间复杂度是 O(log n)
NSSet / NSMutableSet / NSCountedSet
这些集合类型是无序没有重复元素。这样就可以通过 hash table 进行快速的操作。比如 addObject:, removeObject:, containsObject: 都是按照 O(1) 来的。需要注意的是将数组转成 Set 时会将重复元素合成一个,同时失去排序。
NSDictionary / NSMutableDictionary
和 Set 差不多,多了键值对应。添加删除和查找都是 O(1) 的。需要注意的是 Keys 必须是符合 NSCopying。
containsObject 方法在数组和 Set 里不同的实现
在数组中的实现
可以看到会遍历所有元素在查找到后才进行返回.
接下来可以看看 containsObject 在 Set 里的实现:
找元素时是通过键值方式从 map 映射表里取出,因为 Set 里元素是唯一的,所以可以 hash 元素对象作为 key 达到快速获取值的目的。
用 GCD 来做优化
我们可以通过 GCD 提供的方法来将一些需要耗时操作放到非主线程上做,使得 App 能够运行的更加流畅响应更快。但是使用 GCD 时需要注意避免可能引起线程爆炸和死锁的情况,还有非主线程处理任务也不是万能的,如果一个处理需要消耗大量内存或者大量CPU操作 GCD 也没法帮你,只能通过将处理进行拆解分步骤分时间进行处理才比较妥当。
异步处理事件
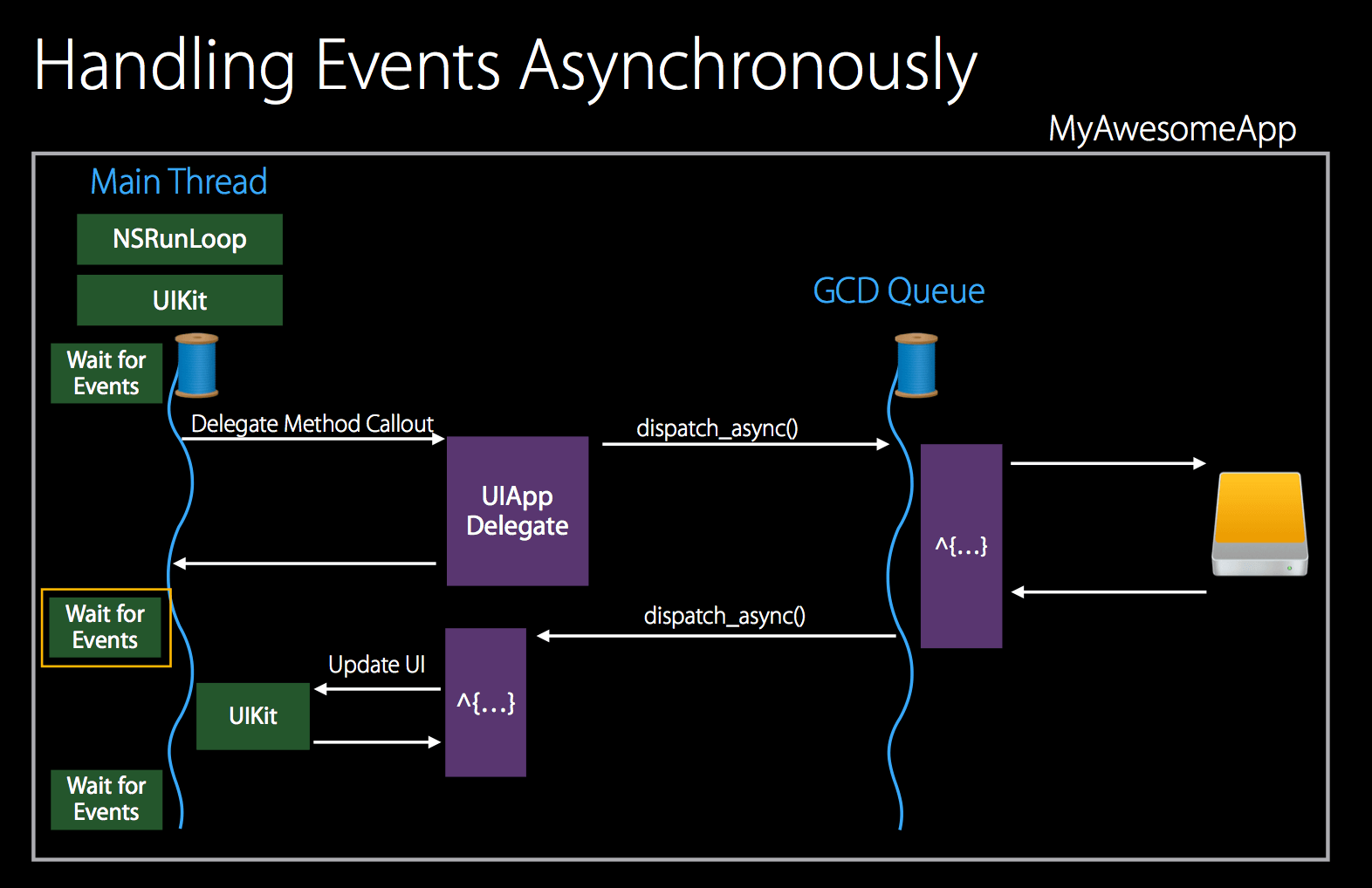
上图是最典型的异步处理事件的方法
需要耗时长的任务

将 GCD 的 block 通过 dispatch_block_create_with_qos_class 方法指定队列的 QoS 为 QOS_CLASS_UTILITY。这种 QoS 系统会针对大的计算,I/O,网络以及复杂数据处理做电量优化。
避免线程爆炸
- 使用串行队列
- 使用 NSOperationQueues 的并发限制方法 NSOperationQueue.maxConcurrentOperationCount
举个例子,下面的写法就比较危险,可能会造成线程爆炸和死锁

那么怎么能够避免呢?首先可以使用 dispatch_apply
或者使用 dispatch_semaphore
GCD 相关 Crash 日志
管理线程问题
线程闲置时
线程活跃时
主线程闲置时
主队列
I/O 性能优化
I/O 是性能消耗大户,任何的 I/O 操作都会使低功耗状态被打破,所以减少 I/O 次数是这个性能优化的关键点,为了达成这个目下面列出一些方法。
- 将零碎的内容作为一个整体进行写入
- 使用合适的 I/O 操作 API
- 使用合适的线程
- 使用 NSCache 做缓存能够减少 I/O
NSCache
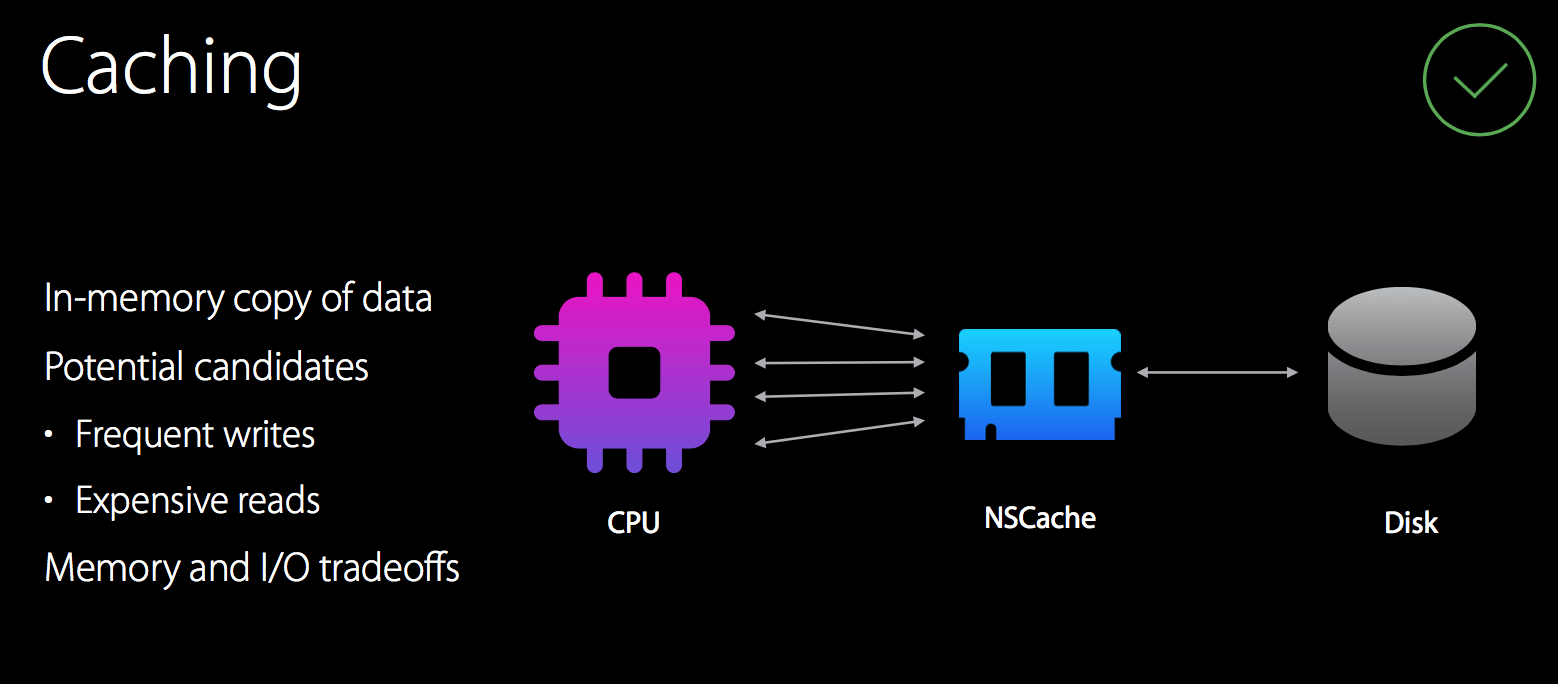
达到如图的目的为何不直接用字典来做呢?
NSCache 具有字典的所有功能,同时还有如下的特性:
- 自动清理系统占用内存
- NSCache 是线程安全
- -(void)cache:(NSCache *)cache willEvictObject:(id)obj; 缓存对象将被清理时的回调
- evictsObjectsWithDiscardedContent 可以控制是否清理
那么 NSCache是如何做到这些特性的呢?
接下来学习下 NSCache 是如何做的。首先 NSCache 是会持有一个 NSMutableDictionary。
需要设计一个 Cached 对象结构来保存一些额外的信息
在 Cache 读取的时候会对 _accesses 数组的添加删除通过 isEvictable 布尔值来保证线程安全操作。使用 Cached 对象里的 accessCount 属性进行 +1 操作为后面自动清理的条件判断做准备。具体实现如下:
在每次 Cache 添加时会先去检查是否自动清理,会创建一个 Cached 对象将 key,object,cost 等信息记录下添加到 _accesses 数组和 _objects 字典里。
那么上面提到的自动清理内存的方法是如何实现的呢?
既然是自动清理必定需要有触发时机和进入清理的条件判断,触发时机一个是发生在添加 Cache 内容时,一个是发生在内存警告时。条件判断代码如下:
所以 NSCache 的 totalCostLimit 的值会和每次 Cache 添加的 cost 之和对比,超出限制必然触发内存清理。
清理时会对经常访问的 objects 不清理,主要是通过 _totalAccesses 和总数获得平均访问频率,如果那个对象的访问次数是小于平均值的才需要清理。
在清理之前还需要一些准备工作,包括标记 Cached 对象的 isEvictable 防止后面有不安全的线程操作。将满足条件的清理 objects 放到清理数组里,如果空间释放足够就不用再把更多的 objects 加到清理数组里了,最后遍历清理数组进行逐个清理即可。
在清理时会执行回调内容,这样如果有些缓存数据需要持续化存储可以在回调里进行处理。
完整的实现可以查看 GNUstep Base 的 NSCache.m 文件。
下面可以看看 NSCache 在 SDWebImage 的运用是怎么样的:
可以看出利用 NSCache 自动释放内存的特点将图片都放到 NSCache 里这样在内存不够用时可以自动清理掉不常用的那些图片,在读取 Cache 里内容时如果没有被清理会直接返回图片数据,清理了的话才会执行 I/O 从磁盘读取图片,通过这种方式能够利用空间减少磁盘操作,空间也能够更加有效的控制释放。
控制 App 的 Wake 次数
通知,VoIP,定位,蓝牙等都会使设备从 Standby 状态唤起。唤起这个过程会有比较大的消耗,应该避免频繁发生。通知方面主要要在产品层面多做考虑。定位方面,下面可以看看定位的一些 API 看看它们对性能的不同影响,便于考虑采用合适的接口。
连续的位置更新
这个方法会时设备一直处于活跃状态。
延时有效定位
会更节能,对于那些只有在位置有很大变化的才需要回调的应用可以采用这种,比如天气应用。
区域监测
也是一种节能的定位方式,比如在博物馆里按照不同区域监测展示不同信息之类的应用比较适合这种定位。
经常访问的地方
总的来说,不要轻易使用 startUpdatingLocation() 除非万不得已,尽快的使用 stopUpdatingLocation() 来结束定位还用户一个节能设备。
内存对于性能的影响
首先 Reclaiming 内存是需要时间的,突然的大量内存需求是会影响响应的。
如何预防这些性能问题,需要刻意预防么
坚持下面几个原则争取在编码阶段避免一些性能问题。
- 优化计算的复杂度从而减少 CPU 的使用
- 在应用响应交互的时候停止没必要的任务处理
- 设置合适的 QoS
- 将定时器任务合并,让 CPU 更多时候处于 idle 状态
那么如果写需求时来不及注意这些问题做不到预防的话,可以通过自动化代码检查的方式来避免这些问题吗?
如何检查
根据这些问题在代码里查,写工具或用工具自动化查?虽然可以,但是需要考虑的情况太多,现有工具支持不好,自己写需要考虑的点太多需要花费太长的时间,那么什么方式会比较好呢?
通过监听主线程方式来监察
首先用 CFRunLoopObserverCreate 创建一个观察者里面接受 CFRunLoopActivity 的回调,然后用 CFRunLoopAddObserver 将观察者添加到 CFRunLoopGetMain() 主线程 Runloop 的 kCFRunLoopCommonModes 模式下进行观察。
接下来创建一个子线程来进行监控,使用 dispatch_semaphore_wait 定义区间时间,标准是 16 或 20 微秒一次监控的话基本可以把影响响应的都找出来。监控结果的标准是根据两个 Runloop 的状态 BeforeSources 和 AfterWaiting 在区间时间是否能检测到来判断是否卡顿。
如何打印堆栈信息,保存现场
打印堆栈整体思路是获取线程的信息得到线程的 state 从而得到线程里所有栈的指针,根据这些指针在 符号表里找到对应的描述即符号化解析,这样就能够展示出可读的堆栈信息。具体实现是怎样的呢?下面详细说说:
获取线程的信息
这里首先是要通过 task_threads 取到所有的线程,
遍历时通过 thread_info 获取各个线程的详细信息
获取线程里所有栈的信息
可以通过 thread_get_state 得到 machine context 里面包含了线程栈里所有的栈指针。
创建一个栈结构体用来保存栈的数据
符号化
符号化主要思想就是通过栈指针地址减去 Slide 地址得到 ASLR 偏移量,通过这个偏移量可以在 __LINKEDIT segment 查找到字符串和符号表的位置。具体代码实现如下:
需要注意的地方
需要注意的是这个程序有消耗性能的地方 thread get state。这个也会被监控检查出,所以可以过滤掉这样的堆栈信息。
能够获取更多信息的方法
获取更多信息比如全层级方法调用和每个方法消耗的时间,那么这样做的好处在哪呢?
可以更细化的测量时间消耗,找到耗时方法,更快的交互操作能使用户体验更好,下面是一些可以去衡量的场景:
- 响应能力
- 按钮点击
- 手势操作
- Tab 切换
- vc 的切换和转场
可以给优化定个目标,比如滚动和动画达到 60fps,响应用户操作在 100ms 内完成。然后逐个检测出来 fix 掉。
如何获取到更多信息呢?
通过 hook objc_msgSend 方法能够获取所有被调用的方法,记录深度就能够得到方法调用的树状结构,通过执行前后时间的记录能够得到每个方法的耗时,这样就能获取一份完整的性能消耗信息了。
hook c 函数可以使用 facebook 的 fishhook, 获取方法调用树状结构可以使用 InspectiveC,下面对于他们的实现详细介绍一下:
获取方法调用树结构
首先设计两个结构体,CallRecord 记录调用方法详细信息,包括 obj 和 SEL 等,ThreadCallStack 里面需要用 index 记录当前调用方法树的深度。有了 SEL 再通过 NSStringFromSelector 就能够取得方法名,有了 obj 通过 object_getClass 能够得到 Class 再用 NSStringFromClass 就能够获得类名。
存储读取 ThreadCallStack
pthread_setspecific() 可以将私有数据设置在指定线程上,pthread_getspecific() 用来读取这个私有数据,利用这个特性可以就可以将 ThreadCallStack 的数据和该线程绑定在一起,随时进行数据的存取。代码如下:
记录方法调用深度
因为要记录深度,而一个方法的调用里会有更多的方法调用,所以方法的调用写两个方法分别记录开始 pushCallRecord 和记录结束的时刻 popCallRecord,这样才能够通过在开始时对深度加一在结束时减一。
在 objc_msgSend 前后插入执行方法
最后是 hook objc_msgSend 需要在调用前和调用后分别加入 pushCallRecord 和 popCallRecord。因为需要在调用后这个时机插入一个方法,而且不可能编写一个保留未知参数并跳转到 c 中任意函数指针的函数,那么这就需要用到汇编来做到。
下面针对 arm64 进行分析,arm64 有31个64 bit 的整数型寄存器,用 x0 到 x30 表示,主要思路就是先入栈参数,参数寄存器是 x0 - x7,对于objc_msgSend方法来说 x0 第一个参数是传入对象,x1 第二个参数是选择器 _cmd。 syscall 的 number 会放到 x8 里。然后交换寄存器中,将用于返回的寄存器 lr 移到 x1 里。先让 pushCallRecord 能够执行,再执行原始的 objc_msgSend,保存返回值,最后让 popCallRecord 能执行。具体代码如下:
记录时间的方法
为了记录耗时,这样就需要在 pushCallRecord 和 popCallRecord 里记录下时间。下面列出一些计算一段代码开始到结束的时间的方法
第一种: NSDate 微秒
第二种:clock_t 微秒clock_t计时所表示的是占用CPU的时钟单元
第三种:CFAbsoluteTime 微秒
第四种:CFTimeInterval 纳秒
第五种:mach_absolute_time 纳秒
最后两种可用,本质区别
NSDate 或 CFAbsoluteTimeGetCurrent() 返回的时钟时间将会会网络时间同步,从时钟 偏移量的角度。mach_absolute_time() 和 CACurrentMediaTime() 是基于内建时钟的。选择一种,加到 pushCallRecord 和 popCallRecord 里,相减就能够获得耗时。
如何 hook msgsend 方法
那么 objc_msgSend 这个 c 方法是如何 hook 到的呢。首先了解下 dyld 是通过更新 Mach-O 二进制的 __DATA segment 特定的部分中的指针来邦定 lazy 和 non-lazy 符号,通过确认传递给 rebind_symbol 里每个符号名称更新的位置就可以找出对应替换来重新绑定这些符号。下面针对关键代码进行分析:
遍历 dyld
首先是遍历 dyld 里的所有的 image,取出 image header 和 slide。注意第一次调用时主要注册 callback。
找出符号表相关 Command
接下来需要找到符号表相关的 command,包括 linkedit segment command,symtab command 和 dysymtab command。方法如下:
获得 base 和 indirect 符号表
进行方法替换
有了符号表和传入的方法替换数组就可以进行符号表访问指针地址的替换,具体实现如下:
统计方法调用频次
在一些应用场景会有一些频繁的方法调用,有些方法的调用实际上是没有必要的,但是首先是需要将那些频繁调用的方法找出来这样才能够更好的定位到潜在的会造成性能浪费的方法使用。这些频繁调用的方法要怎么找呢?
大致的思路是这样,基于上面章节提到的记录方法调用深度的方案,将每个调用方法的路径保存住,调用相同路径的相同方法调用一次加一记录在数据库中,最后做一个视图按照调用次数的排序即可找到调用频繁的那些方法。下图是完成后展示的效果:

接下来看看具体实现方式
设计方法调用频次记录的结构
在先前时间消耗的 model 基础上增加路径,频次等信息
拼装方法路径
在遍历 SMCallTrace 记录的方法 model 和 遍历方法子方法时将路径拼装好,记录到数据库中
记录方法调用频次数据库
创建数据库
这里的 lastcall 是记录是否是最后一个方法的调用,展示时只取最后一个方法即可,因为也会有完整路径可以知道父方法和来源方法。
添加记录
添加记录时需要先检查数据库里是否有相同路径的同一个方法调用,这样可以给 frequency 字段加一已达到记录频次的目的。
检索记录
检索时注意按照调用频次字段进行排序即可。
找出 CPU 使用大的线程堆栈
在前面检测卡顿打印的堆栈里提到使用 thread_info 能够获取到各个线程的 cpu 消耗,但是 cpu 不在主线程即使消耗很大也不一定会造成卡顿导致卡顿检测无法检测出更多 cpu 消耗的情况,所以只能通过轮询监控各线程里的 cpu 使用情况,对于超过标准值比如70%的进行记录来跟踪定位出耗电的那些方法。下图是列出 cpu 过载时的堆栈记录的展示效果:

有了前面的基础,实现起来轻松多了
Demo
工具已整合到先前做的 GCDFetchFeed 里。
- 子线程检测主线程卡顿使用的话在需要开始检测的地方添加 [[SMLagMonitor shareInstance] beginMonitor]; 即可。
- 需要检测所有方法调用的用法就是在需要检测的地方调用 [SMCallTrace start]; 就可以了,不检测打印出结果的话调用 stop 和 save 就好了。这里还可以设置最大深度和最小耗时检测来过滤不需要看到的信息。
- 方法调用频次使用可以在需要开始统计的地方加上 [SMCallTrace startWithMaxDepth:3]; 记录时使用 [SMCallTrace stopSaveAndClean]; 记录到到数据库中同时清理内存的占用。可以 hook VC 的 viewWillAppear 和 viewWillDisappear,在 appear 时开始记录,在 disappear 时记录到数据库同时清理一次。结果展示的 view controller 是 SMClsCallViewController,push 出来就能够看到列表结果。
资料
https://ming1016.github.io/2017/06/20/deeply-ios-performance-optimization/
WWDC
- WWDC 2013 224 Designing Code for Performance
- WWDC 2013 408 Optimizing Your Code Using LLVM
- WWDC 2013 712 Energy Best Practices
- WWDC 2014 710 writing energy efficient code part 1
- WWDC 2014 710 writing energy efficient code part 2
- WWDC 2015 230 performance on ios and watchos
- WWDC 2015 707 achieving allday battery life
- WWDC 2015 708 debugging energy issues
- WWDC 2015 718 building responsive and efficient apps with gcd
- WWDC 2016 406 optimizing app startup time
- WWDC 2016 719 optimizing io for performance and battery life
- WWDC 2017 238 writing energy efficient apps
- WWDC 2017 706 modernizing grand central dispatch usage