目录
服务器角色 |
node21 |
node22 |
node23 |
node24 |
JounralNode |
YES |
YES |
YES |
NO |
Zookeeper |
YES |
YES |
YES |
NO |
NameNode |
YES |
YES |
NO |
NO |
ZKFC |
YES |
YES |
NO |
NO |
DataNode |
NO |
NO |
YES |
YES |
ResourceManager |
YES |
YES |
NO |
NO |
Mysql |
Yes |
|||
Hive |
YES |
YES |
NO |
NO |
1 Local模式跑spark
./bin/spark-submit --classorg.apache.spark.examples.SparkPi \
--master local./examples/jars/spark-examples_2.11-2.3.0.jar 100
2配置Standalone模式
1 修改conf/slaves文件,添加
Node22
Node23
Node24
2 修改spark-env.sh 文件
export JAVA_HOME=/usr/java/jdk1.8.0_161
export SPARK_MASTER_IP=node21
export SPARK_MASTER_PORT=7077
export SPARK_WORKER_CORES=1
export SPARK_WORKER_MEMORY=1g
export SPARK_WORKER_INSTANCES=1
./bin/spark-submit --classorg.apache.spark.examples.SparkPi --master spark://node1:7077./examples/jars/spark-examples_2.11-2.3.0.jar 100
单独启动一个死节点:./start-slave.sh spark://node1:7077
3配置Standalone模式with HA
在Spark standlone单Master节点的基础上,只需要做如下修改
1.修改spark-env.sh将Spark/conf/spark-env.sh中的SPARK_MASTER_IP配置部分删除
2.在Spark/conf/spark-env.sh文件中加入如下配置
exportSPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=
ZOOKEEPER-Dspark.deploy.zookeeper.url=node21:2181,node22:2181,node23:2181,
node24:2181 -Dspark.deploy.zookeeper.dir=/spark"
3.将spark-env.sh文件同步到所有节点
4.在原节点上(native-lufanfeng-1-5-24-137)执行
Spark/sbin# ./start-all.sh
5.修改备选的Master的
conf/spark-env.sh
export SPARK_MASTER_IP=node22
6.在备选的Master节点上(native-lufanfeng-2-5-24-138)执行
Spark/sbin# ./start-master.sh
./spark-shell --master spark://node2:7077
4配置on YARN
先配置好Hadoop on Yarn
Spark on Yarn和Standalone是两种不同的资源调度方式,只用其中一种就行了,所以Saprk on Yarn模式的配置不用Standalone的调度方式,这里面没有./start-all.sh和./start-master.sh
Spark on Yarn运行方式是这样的,先配置好HadoopON Yarn,然后只是在Yarn上跑Spark程序,记住这时千万不要启动Spark上的Master什么的,只要把Spark提交到Yarn上就行了,Yarn会自动分配资源给Spark的。
修改文件/root/.bash_profile添加
exportSPARK_HOME=/hadoop/spark-2.3.0-bin-hadoop2.7
export PATH=$PATH:$SPARK_HOME/bin
分发到各个节点,source /root/.bash_profile
各个节点建Spark临时目录
mkdir-p /data/spark/tmp
/hadoop/spark-2.3.0-bin-hadoop2.7/conf/slaves这个文件在Yarn上没用,由于Yarn模式是Spark程序把程序提交到Yarn上,和Spark自己的slaves没关系。
[root@node21conf]# cat spark-env.sh
export JAVA_HOME=/hadoop/jdk1.8.0_161
#export SPARK_MASTER_IP=node21
#export SPARK_MASTER_PORT=7077
#export SPARK_WORKER_CORES=1
#export SPARK_WORKER_MEMORY=1g
#export SPARK_WORKER_INSTANCES=1
export SCALA_HOME=/hadoop/scala-2.11.8
export HADOOP_HOME=/hadoop/hadoop-2.7.5
exportHADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
exportYARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
export SPARK_LOCAL_DIR=/data/spark/tmp
#SPARK_JAVA_OPTS="-Dspark.storage.blockManagerHeartBeatMs=60000-Dspark.local.dir=$SPARK_LOCAL_DIR-XX:+PrintGCDetails -XX:+PrintGCTimeStamps -Xloggc:$SPARK_HOME/logs/gc.log-XX:+UseConcMarkSw
eepGC-XX:+UseCMSCompactAtFullCollection-XX:CMSInitiatingOccupancyFraction=60"
#exportSPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER-Dspark.deploy.zookeeper.url=node21:2181,node22:2181,node23:2181,node24:2181-Dspark.deploy.zookeeper.dir=/spark"
cd /hadoop/spark-2.3.0-bin-hadoop2.7
./bin/spark-submit --classorg.apache.spark.examples.SparkPi --master yarn --deploy-mode cluster--driver-memory 1G --executor-memory 1G --executor-cores 1/hadoop/spark-2.3.0-bin-hadoop2.7/examples/jars/spark-examples_2.11-2.3.0.jar40
./bin/spark-submit --classorg.apache.spark.examples.SparkPi --master yarn-client /hadoop/spark-2.3.0-bin-hadoop2.7/examples/jars/spark-examples_2.11-2.3.0.jar40
is running beyond virtual memory limits. Current usage: 89.0 MBof 1 GB physical memory used; 2.2 GB of 2.1 GB virtual memory used. Killingcontainer.
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
<description>Whether virtual memory limits will be enforced forcontainers.</description>
</property>
5 安装MySQL
CentOS6.9安装MySQL
卸载系统自带的MySQL
yum list installed | grep mysql
yum -y remove mysql-libs.x86_64
下载MySQL
https://dev.mysql.com/downloads/mysql/
选择redhat对应的MySQL,注意安装顺序
rpm -hiv mysql-community-common-5.7.21-1.el6.x86_64.rpm
rpm -hiv mysql-community-libs-5.7.21-1.el6.x86_64.rpm
rpm -hiv mysql-community-client-5.7.21-1.el6.x86_64.rpm
rpm -hiv mysql-community-server-5.7.21-1.el6.x86_64.rpm
启动mysql
service mysqld start
service mysqld status
mysql5.7 开始有默认的密码
# cat /var/log/mysqld.log|grep 'temporary password'
2018-03-28T09:57:19.729888Z 1 [Note] Atemporary password is generated for root@localhost: N6R6<A.tMtRe
登录
# mysql -uroot -p123456
登录输入密码登录后修改默认密码(mysql密码有安全要求,要求有大小写特殊字符):
mysql> SET PASSWORD = PASSWORD('123456');
也可更改默认密码强度
set global validate_password_policy=0;
授权远程连接
[sql] view plain copy
mysql> GRANT ALL PRIVILEGES ON *.* TO'root'@'%' IDENTIFIED BY '123456' WITH GRANT OPTION;
mysql>FLUSH PRIVILEGES;
说明:如果远程连接不上,关闭防火墙。
设置自启动
# chkconfig --add mysqld
# chkconfig --level 2345 mysqld
远程连接Mysql:
客户端安装MySQLclient,注意安装顺序
rpm –hiv mysql-community-common-5.7.21-1.el6.x86_64.rpm
rpm –hiv mysql-community-libs-5.7.21-1.el6.x86_64.rpm
rpm –hiv mysql-community-client-5.7.21-1.el6.x86_64.rpm
客户端登录Mysql
mysql -h node22 -P 3306 -u root -p123456
mysql安装目录说明
/var/lib/mysql 数据库文件
/usr/share/mysql 命令及配置文件
/usr/bin(mysqladmin、mysqldump等命令)
6 安装Hive
Hive只要安装到NameNode节点上就可以了,datanode节点不用安装
下载hive:apache-hive-2.3.2-bin.tar.gz
上传到/hadoop目录下并解压
tar zvxf apache-hive-2.3.2-bin.tar.gz
#配置hive环境变量
vim /root/.bash_profile
export HIVE_HOME=/hadoop/apache-hive-2.3.2-bin
export HIVE_CONF_DIR=$HIVE_HOME/conf
export PATH=$PATH:$HIVE_HOME/bin
#使配置文件的修改生效
source /root/.bash_profile
配置hive-site.xml
#进入目录cd $HIVE_CONF_DIR
cp hive-default.xml.template hive-site.xml
vim hive-site.xml
使用hadoop新建hdfs目录
因为在hive-site.xml中有这样的配置:
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
<name>hive.exec.scratchdir</name>
<value>/tmp/hive</value>
所以要在Hadoop集群新建/user/hive/warehouse目录,执行命令
cd $HADOOP_HOME #进入Hadoop主目录
bin/hadoop fs -mkdir-p /user/hive/warehouse #创建目录
bin/hadoop fs -chmod-R 777 /user/hive/warehouse #新建的目录赋予读写权限
bin/hadoop fs -mkdir-p /tmp/hive/#新建/tmp/hive/目录
bin/hadoop fs -chmod-R 777 /tmp/hive #目录赋予读写权限
#用以下命令检查目录是否创建成功
bin/hadoop fs -ls /user/hive
bin/hadoop fs -ls /tmp/hive
修改hive-site.xml中的临时目录
将hive-site.xml文件中的${system:java.io.tmpdir}替换为hive的临时目录,例如我替换为/tmp/hive/,该目录如果不存在则要自己手工创建,并且赋予读写权限。
cd /tmp
mkdir hive
chmod -R 777 hive
将配置文件中${system:user.name}都替换为root
说明: 以上给出的只是配置文件中截取了几处以作举例,你在替换时候要认真仔细的全部替换掉。
修改hive-site.xml数据库相关的配置
修改hive-site.xml数据库相关的配置
javax.jdo.option.ConnectionDriverName,将该name对应的value修改为MySQL驱动类路径:
<property
<name>javax.jdo.option.ConnectionDriverName</name
<value>com.mysql.jdbc.Driver</value>
</property>
javax.jdo.option.ConnectionURL,将该name对应的value修改为MySQL的地址:
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://192.168.56.101:3306/hive?createDatabaseIfNotExist=true</value>
javax.jdo.option.ConnectionUserName,将对应的value修改为MySQL数据库登录名:
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
javax.jdo.option.ConnectionPassword,将对应的value修改为MySQL数据库的登录密码:
<name>javax.jdo.option.ConnectionPassword</name><value>123456</value>
将MySQL驱动包上载到Hive的lib目录下
mysql-connector-java-5.1.46.tar.gz
cp /home/dtadmin/spark_cluster/mysql-connector-java-5.1.36.jar$HIVE_HOME/lib/
新建hive-env.sh文件并进行修改
cd $HIVE_CONF_DIR
cp hive-env.sh.template hive-env.sh
#基于模板创建hive-env.sh
vimhive-env.sh #编辑配置文件并加入以下配置:
-------------------------------------------------
export HADOOP_HOME=/hadoop/hadoop-2.7.5
exportHIVE_CONF_DIR=/hadoop/apache-hive-2.3.2-bin/conf
export HIVE_AUX_JARS_PATH=/hadoop/apache-hive-2.3.2-bin/lib
将node21上的hive目录cp 到node22上(namenode)
对MySQL数据库初始化
#进入到hive的bin目录
cd $HIVE_HOME/bin
#对数据库进行初始化
schematool -initSchema -dbType mysql
执行成功后,在mysql的hive数据库里已生成metadata数据表:
启动Hive
cd$HIVE_HOME/bin #进入Hive的bin目录
./hive #执行hive启动
测试Hive
Create database db_test;
Use db_test;
Create table prod(id int, namevarchar(10));
Insert into prod values(1,’sa’); 会发现Yarn上有个MapReduceJob 在跑
查看dfs有个Db_test目录
Hive删除重建:
Create database db_test;
Use db_test;
Create table prod(id int, namevarchar(10));
Insert into prod values(1,’sa’); 会发现Yarn上有个MapReduceJob 在跑
查看dfs有个Db_test目录
--删除MySQLhive
mysql -h node22 -P 3306 -u root-p123456
drop databases hive;
--删除文件
/hadoop/hadoop-2.7.5/bin/hadoop fs-rmr /user/hive/warehouse/*
/hadoop/hadoop-2.7.5/bin/hadoop fs -rmr/tmp/hive/*
rm -fr /tmp/hive/*
查看
/hadoop/hadoop-2.7.5/bin/hadoop fs -ls /user/hive/warehouse
/hadoop/hadoop-2.7.5/bin/hadoop fs -ls/tmp/hive
ls /tmp/hive/*
#进入到hive的bin目录cd$HIVE_HOME/bin#对数据库进行初始化
schematool -initSchema -dbType mysql
--打开hive
/hadoop/apache-hive-2.3.2-bin/bin/hive
测试Hive
Create database db_test;
Use db_test;
Create table prod(id int, namevarchar(10));
Insert into prod values(1,'sa');
会发现Yarn上有个MapReduceJob 在跑
查看dfs有个Db_test目录
7修改spark源码并编译部署
Spark源码编译的3大方式
1、Maven编译
2、SBT编译 (暂时没)
3、打包编译make-distribution.sh
Spark可以通过SBT和Maven两种方式进行编译,再通过make-distribution.sh脚本生成部署包。
SBT编译需要安装git工具,而Maven安装则需要maven工具,两种方式均需要在联网 下进行。
尽管maven是Spark官网推荐的编译方式,但是sbt的编译速度更胜一筹。因此,对于spark的开发者来说,sbt编译可能是更好的选择。由于sbt编译也是基于maven的POM文件,因此sbt的编译参数与maven的编译参数是一致的。
用maven对Spark源码编译时需要联网的。
下载spark源码: spark-2.3.0.tgz
下载之后解压到你想要的目录下,这样你就获得了spark的源码。
安装maven
这里是使用maven对spark进行编译,当然要下载maven
http://maven.apache.org/download.cgi
apache-maven-3.5.3-bin.tar.gz
老规矩下载只有解压到你需要的目录。
然后配置maven的环境变量如下:vi /root/.bash_profile
export JAVA_HOME=/hadoop/jdk1.8.0_161
export JRE_HOME=$JAVA_HOME/jre
export SCALA_HOME=/hadoop/scala-2.11.8
export SPARK_HOME=/hadoop/spark-2.3.0
exportCLASSPATH=$JAVA_HOME/lib/:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
exportMAVEN_HOME=/hadoop/apache-maven-3.5.3
export MAVEN=$MAVEN_HOME/bin
export PATH=$PATH:$SPARK_HOME/bin:$JAVA_HOME/bin:$MAVEN:$PATH:$SCALA_HOME/bin
source /root/.bash_profile
之后可以通过mvn –version来查看maven版本,如果出现版本信息说明安装成功。
这个地方如果行就重启下linux试下
编译spark源码,用Spark源码中的./build/mvn编译
这里我们使用源码包中自带的./build/mvn 文件进行编译。当然在编译之前你可以试着修改一些源代码。
在spark源码目录下运行
Cd /hadoop/spark-2.3.0
./build/mvn -Phadoop-2.7 -Pyarn -DskipTests -Dhadoop.version=2.7.5 -Phive-Phive-thriftserver clean package(这种编译方式好像不会打包)
./dev/make-distribution.sh --tgz-Phadoop-2.7 -Pyarn -DskipTests -Dhadoop.version=2.7.5 -Phive-Phive-thriftserver
编译成功后会在目录中生产:/hadoop/spark-2.3.0/spark-2.3.0-bin-2.7.5.tgz
参数解释:
-DskipTests,不执行测试用例,但编译测试用例类生成相应的class文件至target/test-classes下。
-Dhadoop.version 和-Phadoop: Hadoop 版本号,不加此参数时hadoop版本为1.0.4 。
-Pyarn :是否支持Hadoop YARN ,不加参数时为不支持yarn。
-Phive和-Phive-thriftserver:是否在Spark SQL中支持hive ,不加此参数时为不支持hive 。
–with-tachyon :是否支持内存文件系统Tachyon ,不加此参数时不支持tachyon 。
–tgz :在根目录下生成 spark-$VERSION-bin.tgz ,不加此参数时不生成tgz 文件,只生成/dist 目录。
ps:以前的–with-hive –with-yarn都不再支持了
这样大概要等二十分钟到一个多小时不等,主要取决于网络环境,因为要下载一些依赖包之类的。之后你就可以获得一个spark编译好的包了,解压之后就可以部署到机器上了。
编译后看到如下结果就代表成功了。
[INFO] Building jar:/hadoop/spark-2.3.0/examples/target/spark-examples_2.11-2.3.0-test-sources.jar
[INFO]------------------------------------------------------------------------
[INFO] Reactor Summary:
[INFO]
[INFO] Spark Project Parent POM 2.3.0..................... SUCCESS [ 5.652 s]
[INFO] Spark Project Tags................................. SUCCESS [ 11.982 s]
[INFO] Spark Project Sketch............................... SUCCESS [ 20.684 s]
[INFO] Spark Project Local DB............................. SUCCESS [ 13.715 s]
[INFO] Spark Project Networking........................... SUCCESS [ 25.031 s]
[INFO] Spark Project Shuffle StreamingService ............ SUCCESS [ 15.036 s]
[INFO] Spark Project Unsafe............................... SUCCESS [ 30.838 s]
[INFO] Spark Project Launcher............................. SUCCESS [ 27.486 s]
[INFO] Spark Project Core................................. SUCCESS [03:13 min]
[INFO] Spark Project ML Local Library .....................SUCCESS [ 49.975 s]
[INFO] Spark Project GraphX............................... SUCCESS [ 45.392 s]
[INFO] Spark Project Streaming............................ SUCCESS [01:17 min]
[INFO] Spark Project Catalyst............................. SUCCESS [02:32 min]
[INFO] Spark Project SQL.................................. SUCCESS [03:17 min]
[INFO] Spark Project ML Library........................... SUCCESS [03:59 min]
[INFO] Spark Project Tools................................ SUCCESS [ 11.875 s]
[INFO] Spark Project Hive................................. SUCCESS [02:39 min]
[INFO] Spark Project REPL................................. SUCCESS [ 21.567 s]
[INFO] Spark Project YARN Shuffle Service................. SUCCESS [ 25.241 s]
[INFO] Spark Project YARN................................. SUCCESS [ 41.376 s]
[INFO] Spark Project Hive Thrift Server................... SUCCESS [01:16 min]
[INFO] Spark Project Assembly............................. SUCCESS [ 15.336 s]
[INFO] Spark Integration for Kafka 0.10................... SUCCESS [ 21.147 s]
[INFO] Kafka 0.10 Source for StructuredStreaming ......... SUCCESS [01:09 min]
[INFO] Spark Project Examples............................. SUCCESS [ 45.890 s]
[INFO] Spark Integration for Kafka 0.10Assembly 2.3.0 .... SUCCESS [ 6.404 s]
[INFO]------------------------------------------------------------------------
[INFO] BUILD SUCCESS
[INFO]------------------------------------------------------------------------
[INFO] Total time: 14:47 min (Wall Clock)
这样做完后好像整个/hadoop/spark-2.3.0就是一个可以运行的spark了
Other build examples can be found below.
如果中间有报错,请重新跑,多试几次,一般都能成功。
其中大多会有JAVA_HOME的错误,所以需要在make-distribution.sh配置JAVA_HOME路径,在make-distribution.sh文件中添加:
exportJAVA_HOME=/usr/local/jdk1.7.0_03
编译成功后,其安装文件在根目录下:
spark-1.5.1-bin-2.2.0.tgz
Buildinga Runnable Distribution
To create a Spark distribution like those distributed by the Spark Downloads page, and that is laid out so as to be runnable, use ./dev/make-distribution.sh in the project root directory. It can be configured with Mavenprofile settings and so on like the direct Maven build. Example:
./dev/make-distribution.sh --name custom-spark --pip --r --tgz -Psparkr -Phadoop-2.7 -Phive -Phive-thriftserver -Pmesos -Pyarn -PkubernetesThis will build Spark distribution along with Python pip and Rpackages. For more information on usage, run ./dev/make-distribution.sh--help
1. ## 简单的编译Spark和example程序
2. mvn -DskipTests clean package
3.
4. ## 指定hadoop版本compile
5. mvn -Pyarn -Phadoop-2.6 -Dhadoop.version=2.7.1 -DskipTests clean package
6.
7. ## 打包
8. bash make-distribution.sh --tgz --mvn /opt/maven/bin/mvn -Phive -Pyarn -Phadoop-2.6 -Phadoop-provided -Pnetlib-lgpl -Phive -Pscala-2.10 -Dhadoop.version=2.7.1 [--name 如果需要指定自己的tar名称]
9.
10.## 打包 -- spark 1.4以后,取消了compute-classpath.sh脚本,导致所有通过本地起的程序无法找到hadoop相关的jar包,因此本地的程序需要使用如下的方式打包
11. make-distribution.sh --tgz --mvn /opt/maven/bin/mvn -Phive -Pyarn -Phadoop-2.6 -Pnetlib-lgpl -Phive -Pscala-2.10 -Dhadoop.version=2.7.1
12.
13.## 指定hive
14. sh make-distribution.sh --tgz --mvn /opt/maven/bin/mvn -Phive -Phive-thriftserver -Pyarn -Phadoop-2.6 -Pnetlib-lgpl -Phive -Pscala-2.10 -Dhadoop.version=2.7.1 -Dhive.version.short=1.2.1
8 添加Spark读取hive元数据
hive-site.xml ->/hadoop/apache-hive-2.3.2-bin/conf/hive-site.xml
ln -s /hadoop/apache-hive-2.3.2-bin/conf/hive-site.xmlhive-site.xml
##将连接mysql-connector-java-5.1.35-bin.jar拷贝到spark的jars目录下 cp$HIVE_HOME/lib/ mysql-connector-java-5.1.46-bin.jar $SPARK_HOME/jars
运行spark-sql时会报如下错误:
message:Hive Schemaversion 1.2.0 does not match metastore's schema version 2.3.0 Metastore is notupgraded or corrupt
By default property "hive.metastore.schema.verification" is set to false. Try by changing the value to true in hive-site.xml
修改:/hadoop/apache-hive-2.3.2-bin/conf/hive-site.xml,讲true改为false
测试:Node22
输入spark-sql命令,在终端中执行如下一些sql命令:
启动spark-sql客户端:
spark-sql --master yarn
在启动的命令行中执行如下sql:insert into prodvalues(2,’aa2’);
Node21:打开hive命令查看hive表是否多了一行数据
https://www.cnblogs.com/honeybee/p/6402903.html
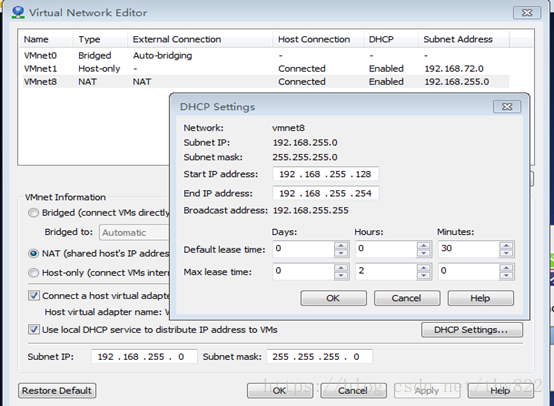
9 Vmwate网络配置
Linux虚拟网络连接有以下几种:
首先,要注意安装完VMware后,控制面板\网络和 Internet\网络连接会多出两块虚拟网卡VMnet1、VMnet2,两个网卡各有用途。
NAT方式(这种方式CentOS可以上外网)
依靠物理主机的VMnet8网卡上网。
1. NAT方式使虚拟机接入外网方便,不需要进行其他配置,只需要物理主机可以上网即可
2. 如果想安装个虚拟机,又不想配置网络,就推荐用NAT方式上网
3. NAT模式下的虚拟系统的TCP/IP配置信息是由VMnet8(NAT)虚拟网络的DHCP服务器提供的,无法进行手工修改,因此虚拟系统也就无法和本局域网中的其他真实主机进行通讯。(不能用NAT配置集群的原因)
Bridged(桥接)(这种方式CentOS可以上外网)
基于以上的拓扑测试,桥接方式虚拟出来的系统就像是在局域网中单独存在的独立“物理机”一样,它可以访问同一局域网内任何一台机器,也可以单独通过局域网网关或者路由访问外网。不过需要在每台机器上都要去单独配置IP,网关、网段、DNS等。
由于这个虚拟系统是局域网中的一个独立的主机系统,那么就可以手工配置它的TCP/IP配置信息,以实现通过局域网的网关或路由器访问互联网。
利用相同的网关网段配置,Bridged可用来配置集群。
Host-Only(主机)(注意:这种方式CentOS不可以上外网)
虚拟机的TCP/IP配置信息(如IP地址、网关地址、DNS服务器等),都是由VMnet1(host-only)虚拟网络的DHCP服务器来动态分配的。
这种模式下,所有局域网内所有虚拟机互通,但虚拟机无法访问外网,与外网完全隔离。
此种模式同样可以配置集群,但是集群无法访问外网,比较适合公司内网。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。