一、主板
1,设备I/O位址与IRQ中断信道
主板是负责各个电脑元件之间的沟通,但是电脑元件实在太多了,有输出/输入/不同的储存设备等等, 主板芯片组怎么知道如何负责沟通呐?这个时候就需要用到所谓的I/O位址与IRQ咯。
I/O位址有点类似每个设备的门牌号码,每个设备都有他自己的位址,一般来说,不能有两个设备使用同一个I/O位址, 否则系统就会不晓得该如何运行这两个设备了。
如果I/O位址想成是各设备的门牌号码的话,那么IRQ就可以想成是各个门牌连接到邮件中心(CPU)的专门路径啰!老式的主板芯片组IRQ只有15个,如果你的周边接口太多时可能就会不够用, 这个时候你可以选择将一些没有用到的周边接口关掉,以空出一些IRQ来给真正需要使用的接口喔! 当然,也有所谓的sharing IRQ的技术就是了!
2,CMOS与BIOS
CMOS主要的功能为记录主板上面的重要参数, 包括系统时间、CPU电压与频率、各项设备的I/O位址与IRQ等,由于这些数据的记录要花费电力,因此主板上面才有电池。BIOS为写入到主板上某一块 flash 或 EEPROM 的程序,他可以在开机的时候执行,以载入CMOS当中的参数, 并尝试调用储存设备中的开机程序,进一步进入操作系统当中。
3,连接周边设备的接口
PS/2接口:这原本是常见的键盘与鼠标的接口,不过目前渐渐被USB接口取代,甚至较新的主板可能就不再提供 PS/2 接口了;这个借口长这样,我的主板是没有这个接口了,0几年的电脑有用到。

USB接口:通常只剩下 USB 2.0 与 USB 3.0,为了方便区分,USB 3.0 为蓝色的插槽颜色喔!之前的笔记有记录,蓝色的比较特别,是3.0的接口。
声音输出、输入与麦克风:这个是一些圆形的插孔,而必须你的主板上面有内置音效芯片时,才会有这三个东西;
分别说明下颜色的意义:(1)声卡输出接口、颜色 绿、可以插耳机听或用信号线送给音响输入接口;(2)声卡输入接口、颜色 蓝、可以插入其他音频信号以便声卡处理;(3)麦克输入接口、颜色 粉、插入麦克视频或录音;(4)橘色c/sub:指接5.1或者7.1多声道音箱的中置声道和低音声道;(5)黑色rear:接5.1或者7.1声道的后置环绕左右声道。黑色和橘色用的少,应该是接音响的。

RJ-45网络头:如果有内置网络芯片的话,那么就会有这种接头出现。 这种接头有点类似电话接头,不过内部有八蕊线喔!接上网络线后在这个接头上会有灯号亮起才对!

HDMI、Display port,笔记2里有说明,大概长这样:

主板全貌是这样,侧面就是上面说的那些接口,中间有个能提起来的架子就是cpu部分,然后就是一些pci、PCIe插槽,按照长度来看,下面的三个插槽是PCIe插槽右边的是PCI插槽,而且显然主板是集成了声卡、网卡显卡:

二、电源供应器
我们的CPU/RAM/主板/硬盘等等都需要用电,而近来的电脑元件耗电量越来越高,以前很古早的230W电源已经不够用了, 有的系统甚至得要有500W以上的电源才能够运行~真可怕。
能源转换率——电源供应器本身也会吃掉一部份的电力的!如果你的主机系统需要 300W 的电力时,因为电源供应器本身也会消耗掉一部份的电力, 因此你最好要挑选400W以上的电源供应器。所谓的高转换率指的是“输出的功率/输入的功率”。电源就是黑色这个有风扇的东东,还挺好装。另外,买电器感觉京东比较靠谱(虽然老在淘宝买水货)~~

速度的快慢与“整体系统的最慢的那个设备有关!
例题:你的系统使用 i7 的 4790 CPU,使用了 DDR3-1600 内存,使用了 PCIe 2.0 x8 的磁盘阵列卡,这张卡上面安装了 8 颗 3TB 的理论速度可达 200MByte/s 的硬盘 (假设为可加总速度的 RAID0 配置), 是安插在 CPU 控制芯片相连的插槽中。网络使用 giga 网卡,安插在PCIe 2.0 x1 的接口上。在这样的设备中,上述的哪个环节速度可能是你的瓶颈?答:
DDR3-1600 的带宽可达:12.8GBytes/s
磁盘阵列卡理论传输率: PCIe 2.0 x8 为 4GBytes/s
磁盘每颗 200MBytes/s,共八颗,总效率为: 200MBytes*8 ~ 1.6GBytes/s
网络接口使用 PCIe 2.0 1x 所以接口速度可达 500MBytes/s,但是 Giga 网络最高为125MBytes/s
通过上述分析,我们知道,速度最慢的为网络的 125MBytes/s !所以,如果想要让整体性能提升,网络恐怕就是需要克服的一环!这个分析在服务器端恐怕是很重要的,清楚效率提升的主要环节。
三、数据表示方式
1,二进制
早期的电脑使用的是利用通电与否的特性的真空管,如果通电就是1,没有通电就是0, 后来沿用至今,我们称这种只有0/1的环境为二进制制,英文称为binary的哩。
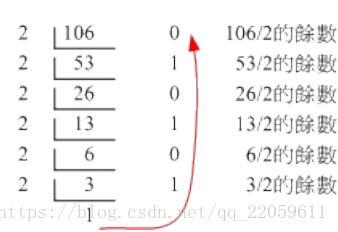
计算一个数的二进制表示方法,记得学的时候还想了一会,算出了余数,然后逆向过来表示出来就是1101010,是不是挺巧妙的:
2,文字编码系统
文字该如何记录啊?事实上文字文件也是被记录为0与1而已,而这个文件的内容要被取出来查阅时,必须要经过一个编码系统的处理才行。这个编码问题,在python2还是挺烦人的。
常用的英文编码表为ASCII系统,这个编码系统中, 每个符号(英文、数字或符号等)都会占用1Bytes的记录, 因此总共会有28=256种变化。还有几个常用的编码集,像unicode、utf-8、gbk系列等。
为解决编码不统一的问题,由国际组织ISO/IEC跳出来制订了所谓的Unicode编码系统, 我们常常称呼的UTF8或万国码的编码就是这个咚咚。编码集在这里想详细说明下,读书的时候搞jsp编码集老出问题。
(1)ASCII
最早编码是ASCII码,它用7个二进制位来表示。这个编码集能够表示256个字符,主要就是英文的大小写和一些符号。 ASCII可被扩展,最优秀的扩展方案是ISO 8859-1,通常称之为Latin-1。Latin-1包括了足够的附加字符集来写基本的西欧语言。ISO 8859-1主要对应的是西欧的编码。最后,这个人人参与的OEM终于以ANSI标准的形式形成文件。在ANSI标准中,每个人都认同如何使用低端的128个编码,这与ASCII相当一致。不过,根据所在国籍的不同,处理编码128以上的字符有许多不同的方式。
作用:表语英语及西欧语言。
位数:ASCII是用7位表示的,能表示128个字符;其扩展使用8位表示,表示256个字符。
范围:ASCII从00到7F,扩展从00到FF。
(2)iso8859-1
属于单字节编码,最多能表示的字符范围是0-255,应用于英文系列。比如,字母'a'的编码为0x61=97。很明显,iso8859-1编码表示的字符范围很窄,无法表示中文字符。但是,由于是单字节编码,和计算机最基础的表示单位一致,所以很多时候,仍旧使用iso8859-1编码来表示。而且在很多协议上,默认使用该编码。
作用:扩展ASCII,表示西欧、希腊语等。
位数:8位
范围:从00到FF,兼容ASCII字符集。
(3) GB码字符集
全称是GB2312-80《信息交换用汉字编码字符集基本集》,1980年发布,是中文信息处理的国家标准,在大陆及海外使用简体中文的地区(如新加坡 等)是强制使用的唯一中文编码。P-Windows3.2和苹果OS就是以GB2312为基本汉字编码, Windows 95/98则以GBK为基本汉字编码、但兼容支持GB2312。
双字节编码
范围:A1A1~FEFE
A1-A9:符号区,包含682个符号
B0-F7:汉字区,包含6763个汉字
(4)GB2312字符集
GB2312(1980年)一共收录了7445个字符,包括6763个汉字和682个其它符号。汉字区的内码范围高字节从B0-F7,低字节从 A1-FE,占用的码位是72*94=6768。其中有5个空位是D7FA-D7FE。GB2312-80中共收录了7545个字符,用两个字节编码一个 字符。每个字符最高位为0。GB2312-80编码简称国标码。
GB2312支持的汉字太少。1995年的汉字扩展规范GBK1.0收录了21886个符号,它分为汉字区和图形符号区。汉字区包括21003个字符。
作用:国家简体中文字符集,兼容ASCII。
位数:使用2个字节表示,能表示7445个符号,包括6763个汉字,几乎覆盖所有高频率汉字。
范围:高字节从A1到F7, 低字节从A1到FE。将高字节和低字节分别加上0XA0即可得到编码。
(5)GB12345-90字符集
1990年制定了繁体字的编码标准GB12345-90《信息交换用汉字编码字符集第一辅助集》,目的在于规范必须使用繁体字的各种场合,以及古籍整理 等。该标准共收录6866个汉字(比GB2312多103个字,其它厂商的字库大多不包括这些字),纯繁体的字大概有2200余个。
双字节编码
范围:A1A1~FEFE
A1-A9:符号区,增加竖排符号
B0-F9:汉字区,包含6866个汉字
(6)GBK字符集
GBK编码(Chinese Internal Code Specification)是中国大陆制订的、等同于UCS的新的中文编码扩展国家标准。gbk编码能够用来同时表示繁体字和简体字,而gb2312只 能表示简体字,gbk是兼容gb2312编码的。GBK工作小组于1995年10月,同年12月完成GBK规范。该编码标准兼容GB2312,共收录汉字 21003个、符号883个,并提供1894个造字码位,简、繁体字融于一库。Windows95/98简体中文版的字库表层编码就采用的是GBK,通过 GBK与UCS之间一一对应的码表与底层字库联系。
英文名:Chinese Internal Code Specification
中文名:汉字内码扩展规范1.0版
双字节编码,GB2312-80的扩充,在码位上和GB2312-80兼容
范围:8140~FEFE(剔除xx7F)共23940个码位
包含21003个汉字,包含了ISO/IEC 10646-1中的全部中日韩汉字
作用:它是GB2312的扩展,加入对繁体字的支持,兼容GB2312。
位数:使用2个字节表示,可表示21886个字符。
范围:高字节从81到FE,低字节从40到FE。
(7)BIG5字符集
是目前台湾、香港地区普遍使用的一种繁体汉字的编码标准,包括440个符号,一级汉字5401个、二级汉字7652个,共计13060个汉字。BIG5又 称大五码或五大码,1984年由台湾财团法人信息工业策进会和五间软件公司宏碁 (Acer)、神通 (MiTAC)、佳佳、零壹 (Zero One)、大众 (FIC)创立,故称大五码。Big5码的产生,是因为当时台湾不同厂商各自推出不同的编码,如倚天码、IBM PS55、王安码等,彼此不能兼容;另一方面,台湾政府当时尚未推出官方的汉字编码,而中国大陆的GB2312编码亦未有收录繁体中文字。
Big5字符集共收录13,053个中文字,该字符集在中国台湾使用。耐人寻味的是该字符集重复地收录了两个相同的字:“兀”(0xA461及0xC94A)、“嗀”(0xDCD1及0xDDFC)。
Big5码使用了双字节储存方法,以两个字节来编码一个字。第一个字节称为“高位字节”,第二个字节称为“低位字节”。高位字节的编码范围0xA1-0xF9,低位字节的编码范围0x40-0x7E及0xA1-0xFE。
尽管Big5码内包含一万多个字符,但是没有考虑社会上流通的人名、地名用字、方言用字、化学及生物科等用字,没有包含日文平假名及片假字母。
例如台湾视“着”为“著”的异体字,故没有收录“着”字。康熙字典中的一些部首用字(如“亠”、“疒”、“辵”、“癶”等)、常见的人名用字(如“堃”、“煊”、“栢”、“喆”等) 也没有收录到Big5之中。
(8)GB18030字符集
GB 18030-2000全称是《信息技术信息交换用汉字编码字符集基本集的扩充》,由信息产业部和原国家质量技术监督局于2000年3月17日联合发布,作为国家强制性标准自发布之日起实施。
为了适应信息处理技术快速发展的需要,1998年10月,由信息产业部电子四所、北京大学计算机技术研究所、北大方正集团、新天地公司、四通新世纪公司、 中科院软件所、长城软件公司、中软总公司、金山软件公司和联想公司的技术人员组成标准起草组。在标准研制过程中,全国信息技术标准化技术委员会多次召集标 准起草组和知名公司对标准草案进行充分地研究论证,并且特邀了微软公司、惠普公司、Sun公司和IBM公司等参加,广泛征求意见。标准起草组经过反复斟酌 和验证,提出了标准制定原则——与GB 2312信息处理交换码所对应的事实上的内码标准兼容,在字汇上支持GB 13000.1的全部中、日、韩(CJK)统一汉字字符和全部CJK扩充A的字符,并且确定了编码体系和27484个汉字,形成兼容性、扩展性、前瞻性兼 备的方案。
该标准采用单字节、双字节和四字节三种方式对字符编码。
作用:它解决了中文、日文、朝鲜语等的编码,兼容GBK。
位数:它采用变字节表示(1 ASCII,2,4字节)。可表示27484个文字。
范围:1字节从00到7F; 2字节高字节从81到FE,低字节从40到7E和80到FE;4字节第一三字节从81到FE,第二四字节从30到39。
(9)通用字符集(UCS)字符集
ISO/IEC 10646-1 [ISO-10646]定义了一种多于8比特字节的字符集,称作通用字符集(UCS),它包含了世界上大多数可书写的字符系统。已定义了两种多8比特字节编码,对每一个字符采用四个8比特字节编码的称为UCS-4,对每一个字符采用两个8比特字节编码的称为UCS-2。它们仅能够对UCS的前64K字符进 行编址,超出此范围的其它部分当前还没有分配编址。
作用:国际标准 ISO 10646 定义了通用字符集 (Universal Character Set)。它是与UNICODE同类的组织,UCS-2和UNICODE兼容。
位数:它有UCS-2和UCS-4两种格式,分别是2字节和4字节。
范围:目前,UCS-4只是在UCS-2前面加了0x0000。
(10)Unicode字符集
Unicode字符集(简称为UCS),国际标准组织于1984年4月成立ISO/IEC JTC1/SC2/WG2工作组,针对各国文字、符号进行统一性编码。1991年美国跨国公司成立Unicode Consortium,并于1991年10月与WG2达成协议,采用同一编码字集。目前Unicode是采用16位编码体系,其字符集内容与 ISO10646的BMP(Basic Multilingual Plane)相同。Unicode于1992年6月通过DIS(Draf International Standard),目前版本V2.0于1996公布,内容包含符号6811个,汉字20902个,韩文拼音11172个,造字区6400个,保留 20249个,共计65534个。Unicode编码后的大小是一样的.例如一个英文字母 "a" 和 一个汉字 "好",编码后都是占用的空间大小是一样的,都是两个字节!
Unicode可以用来表示所有语言的字符,而且是定长双字节(也有四字节的)编码,包括英文字母在内。所以可以说它是不兼容iso8859-1编码的, 也不兼容任何编码。不过,相对于iso8859-1编码来说,uniocode编码只是在前面增加了一个0字节,比如字母'a'为"00 61"。
需要说明的是,定长编码便于计算机处理(注意GB2312/GBK不是定长编码),而unicode又可以用来表示所有字符,所以在很多软件内部是使用unicode编码来处理的,比如java。
UNICODE字符集有多个编码方式,分别是UTF-8,UTF-16,UTF-32和UTF-7编码。
(11) UTF-8
UTF:UCS Transformation Format.考虑到unicode编码不兼容iso8859-1编码,而且容易占用更多的空间:因为对于英文字母,unicode也需要两个字节来表示。所以unicode不便于传输和存储。因此而产生了utf编码,utf编码兼容iso8859-1编码,同时也可以用来表示所有语言的字符,不过,utf编码是不定长编码,每一个字符的长度从1-6个字节不等。另外,utf编码自带简单的校验功能。一般来讲,英文字母都是用一个字节表示,而汉字 使用三个字节。
注意,虽然说utf是为了使用更少的空间而使用的,但那只是相对于unicode编码来说,如果已经知道是汉字,则使用GB2312/GBK无疑是 最节省的。不过另一方面,值得说明的是,虽然utf编码对汉字使用3个字节,但即使对于汉字网页,utf编码也会比unicode编码节省,因为网页中包 含了很多的英文字符。
UTF8编码后的大小是不一定,例如一个英文字母"a" 和 一个汉字 "好",编码后占用的空间大小就不样了,前者是一个字节,后者是三个字节!编码的方法是从低位到高位。黄色为标志位其它着色为了显示其,编码后的位置。
(12)UTF-16
采用2 字节,Unicode中不同部分的字符都同样基于现有的标准。这是为了便于转换。从 0x0000到0x007F是ASCII字符,从0x0080到0x00FF是ISO-8859-1对ASCII的扩展。希腊字母表使用从0x0370到 0x03FF 的代码,斯拉夫语使用从0x0400到0x04FF的代码,美国使用从0x0530到0x058F的代码,希伯来语使用从0x0590到0x05FF的代 码。中国、日本和韩国的象形文字(总称为CJK)占用了从0x3000到0x9FFF的代码;
由于0x00在c语言及操作系统文件名等中有特殊意义,故很多情况下需要UTF-8编码保存文本,去掉这个0x00。举例如下:
UTF-16: 0x0080 = 0000 0000 1000 0000
UTF-8: 0xC280 = 1100 0010 1000 0000
(13)UTF-32
采用4字节。
(14)UTF-7
A Mail-Safe Transformation Format of Unicode(RFC1642)。这是一种使用 7 位 ASCII 码对 Unicode 码进行转换的编码。它的设计目的仍然是为了在只能传递 7 为编码的邮件网关中传递信息。 UTF-7 对英语字母、数字和常见符号直接显示,而对其他符号用修正的 Base64 编码。符号 + 和 - 号控制编码过程的开始和暂停。所以乱码中如果夹有英文单词,并且相伴有 + 号和 - 号,这就有可能是 UTF-7 编码。
作用:为世界650种语言进行统一编码,兼容ISO-8859-1。
位数:UNICODE字符集有多个编码方式,分别是UTF-8,UTF-16和UTF-32。
很多人以为UTF-8等和Unicode都是字符集或都是编码方式,其实这是误区。
到以上为止,大部分常用的字符集已经基本列举完毕,再看一些其他的编码方式:
(15)MIME 编码
MIME 是“多用途网际邮件扩充协议”的缩写,在 MIME 协议之前,邮件的编码曾经有过 UUENCODE 等编码方式 ,但是由于 MIME 协议算法简单,并且易于扩展,现在已经成为邮件编码方式的主流,不仅是用来传输 8 bit 的字符,也可以用来传送二进制的文件 ,如邮件附件中的图像、音频等信息,而且扩展了很多基于MIME 的应用。从编码方式来说,MIME 定义了两种编码方法Base64与QP(Quote-Printable)
(16)Base64
按照RFC2045的定义,Base64被定义为:Base64内容传送编码被设计用来把任意序列的8位字节描述为一种不易被人直接识别的形式。
为什么要使用Base64?
在设计这个编码的时候,我想设计人员最主要考虑了3个问题:
1.是否加密?
2.加密算法复杂程度和效率
3.如何处理传输?
加密是肯定的,但是加密的目的不是让用户发送非常安全的Email。这种加密方式主要就是“防君子不防小人”。即达到一眼望去完全看不出内容即可。 基 于这个目的加密算法的复杂程度和效率也就不能太大和太低。和上一个理由类似,MIME协议等用于发送Email的协议解决的是如何收发Email,而并不是如何安全的收发Email。因此算法的复杂程度要小,效率要高,否则因为发送Email而大量占用资源,路就有点走歪了。
但是,如果是基于以上两点,那么我们使用最简单的恺撒法即可,为什么Base64看起来要比恺撒法复杂呢?这是因为在Email的传送过程中,由于历史原 因,Email只被允许传送ASCII字符,即一个8位字节的低7位。因此,如果您发送了一封带有非ASCII字符(即字节的最高位是1)的Email通 过有“历史问题”的网关时就可能会出现问题。网关可能会把最高位置为0!很明显,问题就这样产生了!因此,为了能够正常的传送Email,这个问题就必须 考虑!所以,单单靠改变字母的位置的恺撒之类的方案也就不行了。关于这一点可以参考RFC2046。
基于以上的一些主要原因产生了Base64编码。
Base64编码要求把3个8位字节(3*8=24)转化为4个6位的字节(4*6=24),之后在6位的前面补两个0,形成8位一个字节的形式。
(17)QP(Quote-Printable)
通常缩写为“Q”方法,其原理是把一个 8 bit 的字符用两个16进制数值表示,然后在前面加“=”。所以我们看到经过QP编码后的文件通常是这个样子:=B3=C2=BF=A1=C7=E5=A3=AC=C4=FA=BA=C3=A3=A1。
最后,我们希望你看了这篇文章之后不要混淆字符集和字符编码的概念,还有对以上谈到的各种编码方式的原因有大致的了解,象utf-8这类是为了解析 unicode这种字符集而制定,而base64这类是为了解决实际的网络应用而制定。为了让你便于记忆,对先前介绍的字符集进行统计和分类:
参考:1,各种字符集和编码详解 https://www.cnblogs.com/happyday56/p/4135845.html