版权声明:本文为博主原创文章,未经博主允许不得转载。 https://blog.csdn.net/u014665013/article/details/81531620
其实在实习之前对于一些知识点的理解还是欠缺的,很多时候感觉没什么用的基础知识为什么还会在面试的时候被问到,比如,“你画一下GRU的基本结构”,你在做工程的时候回修改GRU的结构吗?居然会问这种问题哎,或许你现在也是这么想的~
前言
首先最简单的LSTM结构可以详见我之前的帖子(GRU和LSTM总结
i t = δ ( W i x x t + W i m m t − 1 + W i c c t − 1 + b i )
i
t
=
δ
(
W
i
x
x
t
+
W
i
m
m
t
−
1
+
W
i
c
c
t
−
1
+
b
i
)
f t = δ ( W f x x t + W f m m t − 1 + W f c c t − 1 + b i )
f
t
=
δ
(
W
f
x
x
t
+
W
f
m
m
t
−
1
+
W
f
c
c
t
−
1
+
b
i
)
c t = f t ⊙ c t − 1 + i t ⊙ g ( W c x x t + W c m m t − 1 + b c )
c
t
=
f
t
⊙
c
t
−
1
+
i
t
⊙
g
(
W
c
x
x
t
+
W
c
m
m
t
−
1
+
b
c
)
o t = δ ( W o x x t + W o m m t − 1 + W o c c t + b o )
o
t
=
δ
(
W
o
x
x
t
+
W
o
m
m
t
−
1
+
W
o
c
c
t
+
b
o
)
m t = o t ⊙ h ( c t )
m
t
=
o
t
⊙
h
(
c
t
)
y t = ϕ ( W y m m t + b y )
y
t
=
ϕ
(
W
y
m
m
t
+
b
y
)
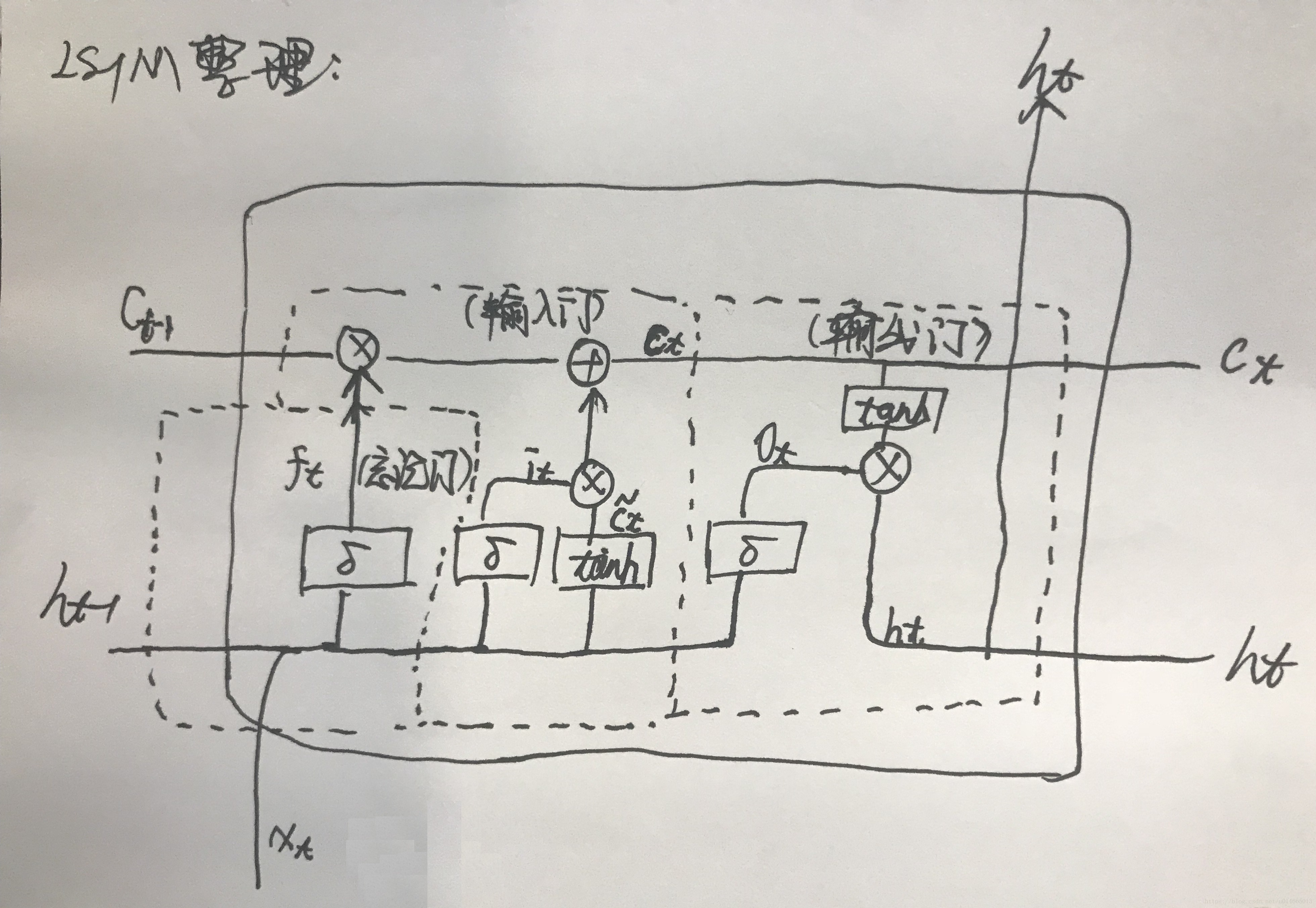
where the W terms denote weight matrices (e.g. Wix is the matrix of weights from the input gate to the input),
W i c
W
i
c
,
W f c
W
f
c
,
W o c
W
o
c
are diagonal weight matrices for peephole connectionsLong Short-Term Memory Recurrent Neural Network Architectures long short-term memory based recurrent neural network architectures for large vocabulary speech recognition ,但是你会发现在介绍参数的时候还没有上一篇讲的清楚。这里注意下
W i c
W
i
c
,
W f c
W
f
c
,
W o c
W
o
c
都是对角矩阵!!!
细心的读者肯定能发现这个表达形式和我之前介绍LSTM博客在表达形式和结构上都有些区别,对于表达形式都是换汤不换药,但是这里结构上也发生了一定的变化,增加了几项:
+ W i c c t − 1 、 + W f c c t − 1 、 + W o c c t
+
W
i
c
c
t
−
1
、
+
W
f
c
c
t
−
1
、
+
W
o
c
c
t
例如:即便是LSTM也有很多个变种。一个变种方式是调控门的输入。例如下面两种gate:
g = s i g m o i d ( W x g ⋅ x t + W h g ⋅ h t − 1 + b )
g
=
s
i
g
m
o
i
d
(
W
x
g
⋅
x
t
+
W
h
g
⋅
h
t
−
1
+
b
)
:
x t
x
t
和上一时刻的隐藏状态
h t − 1
h
t
−
1
, 表示gate是将这两个信息流作为控制依据而产生输出的。
g = s i g m o i d ( W x g ⋅ x t + W h g ⋅ h t − 1 + W c g ⋅ c t − 1 + b )
g
=
s
i
g
m
o
i
d
(
W
x
g
⋅
x
t
+
W
h
g
⋅
h
t
−
1
+
W
c
g
⋅
c
t
−
1
+
b
)
:
x t
x
t
和上一时刻的隐藏状态
h t − 1
h
t
−
1
,以及上一时刻的cell状态
c t − 1
c
t
−
1
, 表示gate是将这三个信息流作为控制依据而产生输出的。这种方式的LSTM叫做peephole connections
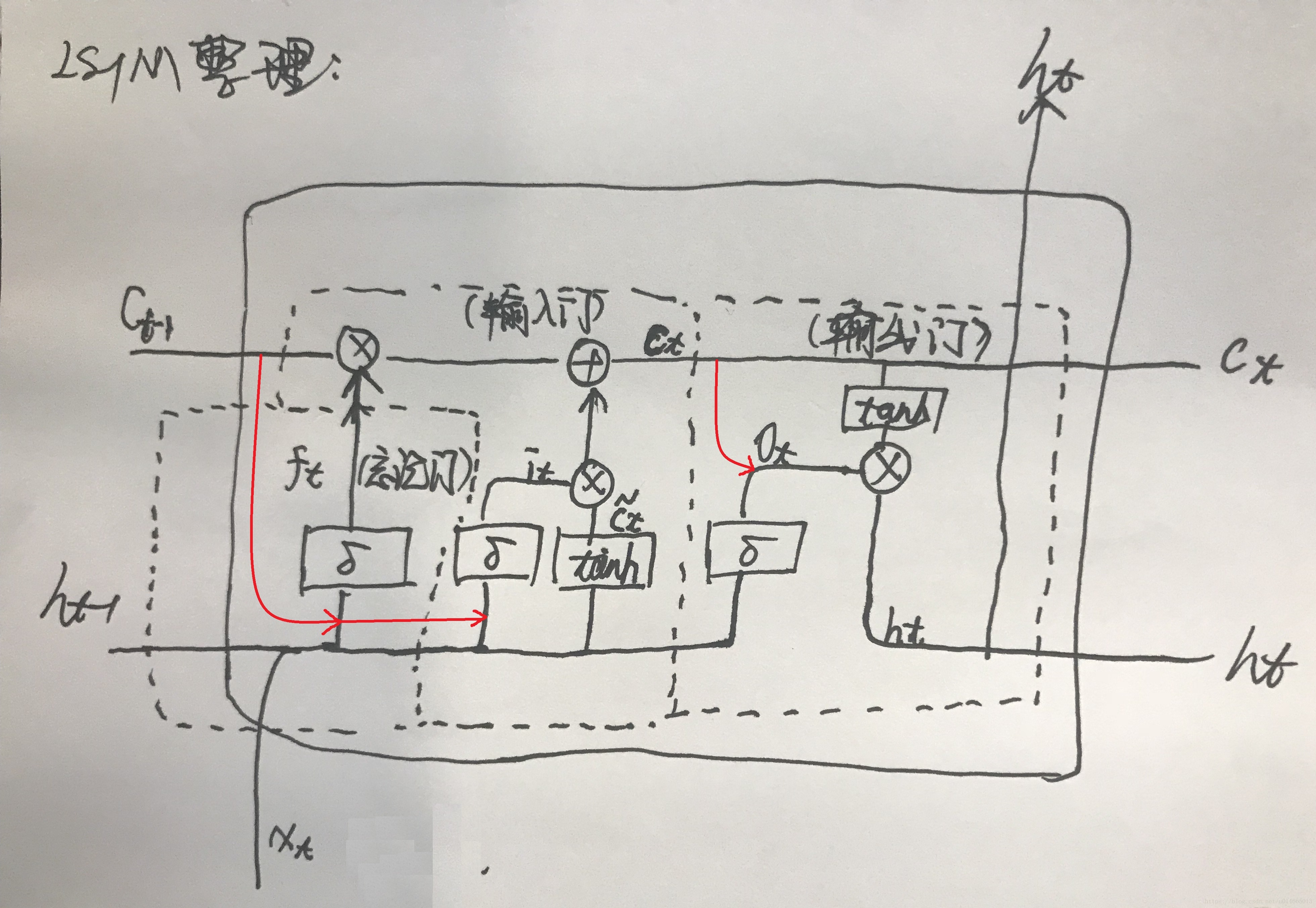
上面两幅图很清晰,就是在用细胞状态 (就是图里面的
C t C t − 1
C
t
C
t
−
1
,也就是最上面的额那条信息流)的时候有些区别。(leader说第二种的这种结构效果会比之前博客中写到的简单LSTM效果要好,我并没有试过。。。)
在下面的讲解中用到的就是第二种这个,来对比参数等一些区别。
为什么要用projection layer
首先在LSTM中的Projection layer是为了减少计算量的,它的作用和全连接layer很像,就是对输出向量做一下压缩,从而能把高纬度的信息降维,减小cell unit的维度,从而减小相关参数矩阵的参数数目! What is the meaning of ‘projection layer’ in lstm?
传统LSTM 如上面所列出的一样,传统的LSTM的结构为:
i t = δ ( W i x x t + W i m m t − 1 + W i c c t − 1 + b i )
i
t
=
δ
(
W
i
x
x
t
+
W
i
m
m
t
−
1
+
W
i
c
c
t
−
1
+
b
i
)
f t = δ ( W f x x t + W f m m t − 1 + W f c c t − 1 + b i )
f
t
=
δ
(
W
f
x
x
t
+
W
f
m
m
t
−
1
+
W
f
c
c
t
−
1
+
b
i
)
c t = f t ⊙ c t − 1 + i t ⊙ g ( W c x x t + W c m m t − 1 + b c )
c
t
=
f
t
⊙
c
t
−
1
+
i
t
⊙
g
(
W
c
x
x
t
+
W
c
m
m
t
−
1
+
b
c
)
o t = δ ( W o x x t + W o m m t − 1 + W o c c t + b o )
o
t
=
δ
(
W
o
x
x
t
+
W
o
m
m
t
−
1
+
W
o
c
c
t
+
b
o
)
m t = o t ⊙ h ( c t )
m
t
=
o
t
⊙
h
(
c
t
)
y t = ϕ ( W y m m t + b y )
y
t
=
ϕ
(
W
y
m
m
t
+
b
y
)
最后的
y t
y
t
是输出,
公式里面的所有
m t
m
t
表示的是图中的
h t
h
t
,其他所有的m变成h即可 ,只不过写法不同而已!
那么如果不计算里面的bias(也就是
b i b c b o
b
i
b
c
b
o
),那么最终的参数数目是:
W = n c ∗ n c ∗ 4 + n i ∗ n c ∗ 4 + n c ∗ n o + n c ∗ 3
W
=
n
c
∗
n
c
∗
4
+
n
i
∗
n
c
∗
4
+
n
c
∗
n
o
+
n
c
∗
3
其中
n c
n
c
表示cell units的大小,也就是隐层的维度,
n i
n
i
是当前输入向量的维度,
n o
n
o
表示的是最终
m t
m
t
得到的最终输出y的维度
n c ∗ n c ∗ 4
n
c
∗
n
c
∗
4
表示的是
W i m
W
i
m
、
W f m
W
f
m
、
W c m
W
c
m
、
W o m
W
o
m
的参数个数
n i ∗ n c ∗ 4
n
i
∗
n
c
∗
4
表示的是
W i x
W
i
x
、
W f x
W
f
x
、
W c x
W
c
x
、
W o x
W
o
x
的参数个数
n c ∗ n o
n
c
∗
n
o
表示的是
W y m
W
y
m
输出的时候的全连接层的参数个数
n c ∗ 3
n
c
∗
3
表示的是
W i c
W
i
c
、
W f c
W
f
c
、
W o c
W
o
c
这几个
对角矩阵 的参数个数
LSTM projection layer 结构(LSTMP)
而加入projection layer改进后的公式结构如下:
i t = δ ( W i x x t + W i r r t − 1 + W i c c t − 1 + b i )
i
t
=
δ
(
W
i
x
x
t
+
W
i
r
r
t
−
1
+
W
i
c
c
t
−
1
+
b
i
)
f t = δ ( W f x x t + W f r r t − 1 + W f c c t − 1 + b i )
f
t
=
δ
(
W
f
x
x
t
+
W
f
r
r
t
−
1
+
W
f
c
c
t
−
1
+
b
i
)
c t = f t ⊙ c t − 1 + i t ⊙ g ( W c x x t + W c r r t − 1 + b c )
c
t
=
f
t
⊙
c
t
−
1
+
i
t
⊙
g
(
W
c
x
x
t
+
W
c
r
r
t
−
1
+
b
c
)
o t = δ ( W o x x t + W o r r t − 1 + W o c c t + b o )
o
t
=
δ
(
W
o
x
x
t
+
W
o
r
r
t
−
1
+
W
o
c
c
t
+
b
o
)
m t = o t ⊙ h ( c t )
m
t
=
o
t
⊙
h
(
c
t
)
r t = W r m m t
r
t
=
W
r
m
m
t
y t = ϕ ( W y r r t + b y )
y
t
=
ϕ
(
W
y
r
r
t
+
b
y
)
这里的参数个数发生了变化,参数为:
W = n c ∗ n r ∗ 4 + n i ∗ n c ∗ 4 + n r ∗ n o + n c ∗ n r + n c ∗ 3
W
=
n
c
∗
n
r
∗
4
+
n
i
∗
n
c
∗
4
+
n
r
∗
n
o
+
n
c
∗
n
r
+
n
c
∗
3
其中
n c
n
c
表示cell units的大小,也就是隐层的维度,
n i
n
i
是当前输入向量的维度,
n o
n
o
表示的是最终
m t
m
t
得到的最终输出y的维度,
n r
n
r
表示的是projection layer的输出维度。
n c ∗ n r ∗ 4
n
c
∗
n
r
∗
4
表示的是
W i m
W
i
m
、
W f m
W
f
m
、
W c m
W
c
m
、
W o m
W
o
m
的参数个数
n i ∗ n c ∗ 4
n
i
∗
n
c
∗
4
表示的是
W i x
W
i
x
、
W f x
W
f
x
、
W c x
W
c
x
、
W o x
W
o
x
的参数个数
n c ∗ n o
n
c
∗
n
o
表示的是
W y m
W
y
m
输出的时候的全连接层的参数个数
n c ∗ n r
n
c
∗
n
r
表示的是projection layer的参数矩阵
n c ∗ 3
n
c
∗
3
表示的是
W i c
W
i
c
、
W f c
W
f
c
、
W o c
W
o
c
这几个
对角矩阵 的参数个数
所以最终在举个例子,假设我们的cell units的大小是256,输入的维数是100,输出的维数是30,那么传统的LSTM参数个数是:
W = n c ∗ n c ∗ 4 + n i ∗ n c ∗ 4 + n c ∗ n o + n c ∗ 3 = 256 ∗ 256 ∗ 4 + 100 ∗ 256 ∗ 4 + 256 ∗ 30 + 256 ∗ 3 = 256 ∗ 1457
W
=
n
c
∗
n
c
∗
4
+
n
i
∗
n
c
∗
4
+
n
c
∗
n
o
+
n
c
∗
3
=
256
∗
256
∗
4
+
100
∗
256
∗
4
+
256
∗
30
+
256
∗
3
=
256
∗
1457
但是加入projection layer之后,假设输出维度为128,的参数个数是:
W = n c ∗ n r ∗ 4 + n i ∗ n c ∗ 4 + n r ∗ n o + n c ∗ n r + n c ∗ 3 = 256 ∗ 128 ∗ 4 + 100 ∗ 256 ∗ 4 + 128 ∗ 30 + 256 ∗ 128 + 256 ∗ 3
W
=
n
c
∗
n
r
∗
4
+
n
i
∗
n
c
∗
4
+
n
r
∗
n
o
+
n
c
∗
n
r
+
n
c
∗
3
=
256
∗
128
∗
4
+
100
∗
256
∗
4
+
128
∗
30
+
256
∗
128
+
256
∗
3
所以减少的个数可以很容易看出来了。
相关细节未完待续!
参考网址