1.数据来源:
可针对自己的模型需要在imagenet官网上下载所需类别对应的txt文件。

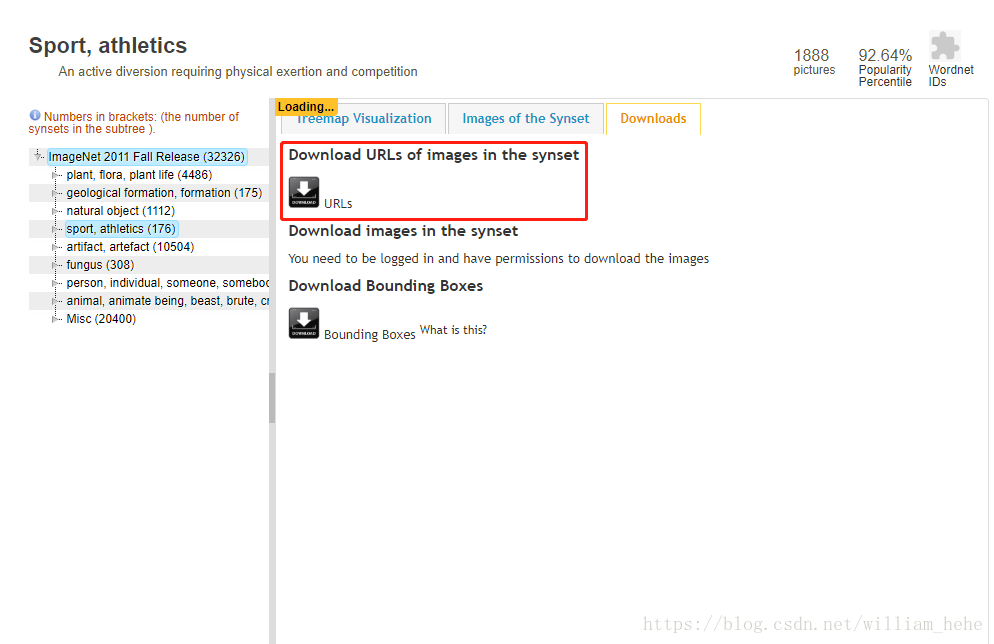
2.数据下载:
import os
from urllib.request import urlretrieve
def download():
categories = ['bird', 'fish','invertebrate','mammal'] #需要下载图片所对应的txt文件
for category in categories:
#将下载到的图片保存在文件夹dataset中
os.makedirs('./dataset1/%s' % category, exist_ok=True)
#txt文件所在路径
with open('./Animal/%s.txt' % category, 'r') as file:
urls = file.readlines()
n_urls = len(urls)
for i, url in enumerate(urls):
try:
urlretrieve(url.strip(), './Animal/%s/%s' % (category, url.strip().split('/')[-1]))
print('%s %i/%i' % (category, i, n_urls))
except:
print('%s %i/%i' % (category, i, n_urls), 'no image')
if __name__ == '__main__':
download()