第二章讲的是K-邻近算法
from numpy import*
import operator
def createDataSet():
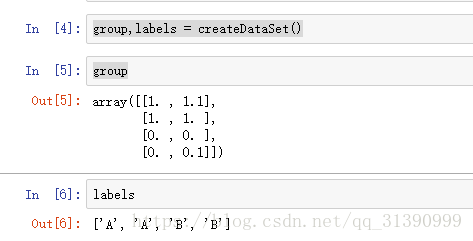
group = array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]])
labels = ['A','A','B','B']
return group,labels
group,labels = createDataSet()
K-邻近算法报错 还没有解决 好像是python2和3的版本问题,百度了一圈没有解决方法。
def classify0(inX, dataSet, labels, k):
dataSetSize = dataSet.shape[0]
diffMat = tile(inX, (dataSetSize,1)) - dataSet
sqDiffMat = diffMat**2
sqDistances = sqDiffMat.sum(axis=1)
distances = sqDistances**0.5
sortedDistIndicies = distances.argsort()
classCount={}
for i in range(k):
voteIlabel = labels[sortedDistIndicies[i]]
classCount[voteIlabel] = classCount.get(voteIlabel,0) + 1
sortedClassCount = sorted(classCount.items(), key=operator.itemgetter(1), reverse=True)
return sortedClassCount[0][0]
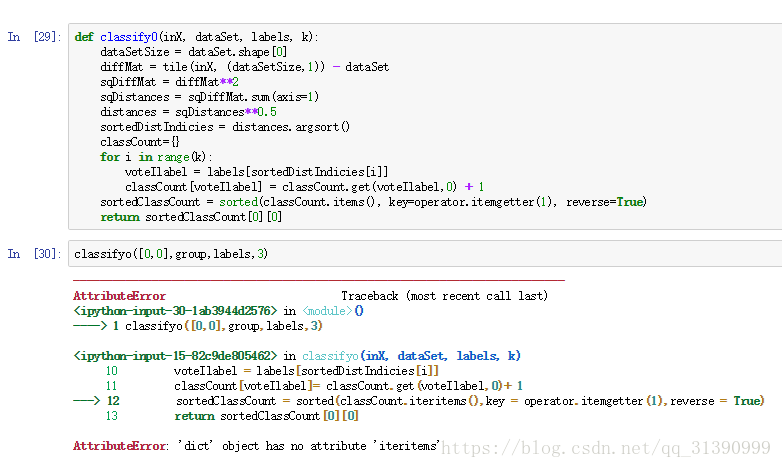
2.2中代码有错误,报错原因 invalid literal for int() with base 10: 'largeDoses' 详情请见https://blog.csdn.net/michaelhan3/article/details/74017111,更正方法:重新处理txt文件中的内容,将浮点数改为整数,
def file2matrix(filename):
fr = open(filename)
numberOfLines = len(fr.readlines()) #get the number of lines in the file
returnMat = zeros((numberOfLines,3)) #prepare matrix to return
classLabelVector = [] #prepare labels return
fr = open(filename)
index = 0
for line in fr.readlines():
line = line.strip()
listFromLine = line.split('\t')
returnMat[index,:] = listFromLine[0:3]
classLabelVector.append(int(listFromLine[-1]))
index += 1
return returnMat,classLabelVector
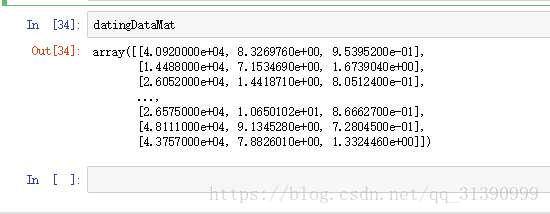
datingDataMat,datingLabels = file2matrix('datingTestSet2.txt')
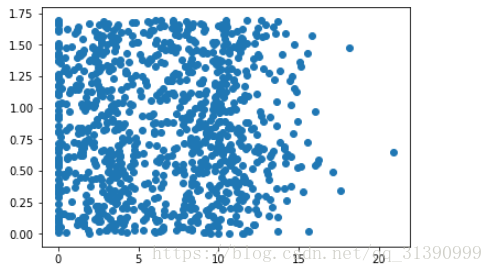
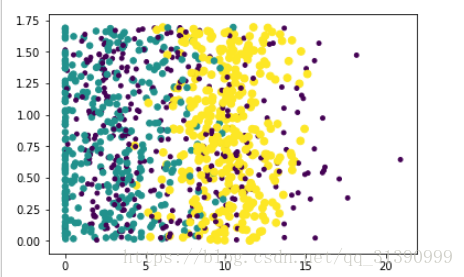
数据分析:使用Matplotlib创建散点图
import matplotlib
import matplotlib.pyplot as plt
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(datingDataMat[:,1],datingDataMat[:,2])
plt.show()
ax.scatter(datingDataMat[:,1],datingDataMat[:,2],15.0 * array(datingLabels),15.0 * array(datingLabels))
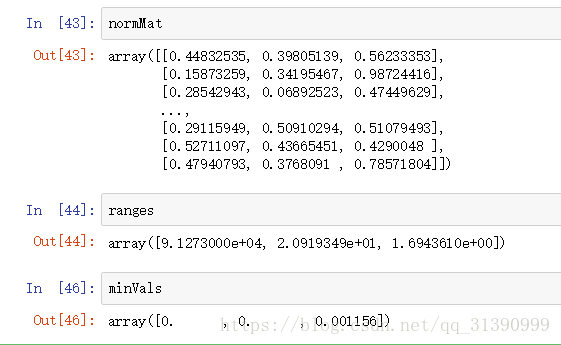
归一化特征值
def autoNorm(dataSet):minVals = dataSet.min(0)
maxVals = dataSet.max(0)
ranges = maxVals - minVals
normDataSet = zeros(shape(dataSet))
m = dataSet.shape[0]
normDataSet = dataSet - tile(minVals, (m,1))
normDataSet = normDataSet/tile(ranges, (m,1)) #element wise divide
return normDataSet, ranges, minVals
normMat,ranges,minVals = autoNorm(datingDataMat)
分类器针对约会网站的测试代码
def datingClassTest():hoRatio = 0.10 #hold out 10%
datingDataMat,datingLabels = file2matrix('datingTestSet2.txt') #load data setfrom file
normMat, ranges, minVals = autoNorm(datingDataMat)
m = normMat.shape[0]
numTestVecs = int(m*hoRatio)
errorCount = 0.0
for i in range(numTestVecs):
classifierResult = classify0(normMat[i,:],normMat[numTestVecs:m,:], datingLabels[numTestVecs:m],3)
print "%d, %d" % (classifierResult, datingLabels[i])
if (classifierResult != datingLabels[i]): errorCount += 1.0
print "the total error rate is: %f" % (errorCount/float(numTestVecs))
print errorCount
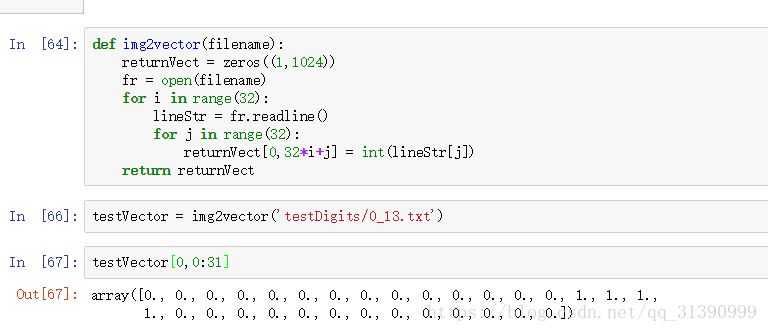
测试算法:使用K-邻近算法识别手写数字
import os #第一二句一定要写,否则会报错from os import listdir
def handwritingClassTest():
hwLabels = []
trainingFileList = listdir('trainingDigits') #load the training set
m = len(trainingFileList)
trainingMat = zeros((m,1024))
for i in range(m):
fileNameStr = trainingFileList[i]
fileStr = fileNameStr.split('.')[0] #take off .txt
classNumStr = int(fileStr.split('_')[0])
hwLabels.append(classNumStr)
trainingMat[i,:] = img2vector('trainingDigits/%s' % fileNameStr)
testFileList = listdir('testDigits') #iterate through the test set
errorCount = 0.0
mTest = len(testFileList)
for i in range(mTest):
fileNameStr = testFileList[i]
fileStr = fileNameStr.split('.')[0] #take off .txt
classNumStr = int(fileStr.split('_')[0])
vectorUnderTest = img2vector('testDigits/%s' % fileNameStr)
classifierResult = classify0(vectorUnderTest, trainingMat, hwLabels, 3)
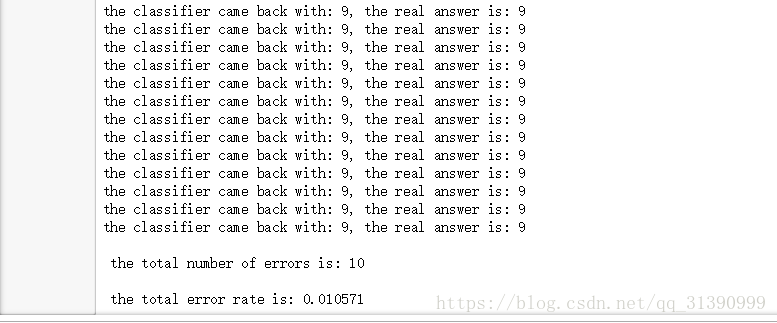
print ('the classifier came back with: %d, the real answer is: %d' % (classifierResult, classNumStr))
if (classifierResult != classNumStr): errorCount += 1.0
print ("\n the total number of errors is: %d" % errorCount)
print ("\n the total error rate is: %f" % (errorCount/float(mTest)))
这一章是我第一次实现代码,以前都是只看书学习理论知识不实践,书中内容上代码最大的错误是书本是Python2版本的,但是目前大家普遍使用python3版本,所以代码输入输出引号之类的需要修改。