强化学习最重要的特点是利用训练信息来评估动作,而不是指出最优动作。这就要求需要探索(explore)多个动作来评估、比较出最优动作。即前者只反馈动作的好坏程度,但没有直接指出哪个动作是最好或最坏的;而后者可以指导处哪个动作是最好的,并且该指导反馈与已经发生的动作无关。这也是非监督学习(评价性反馈)与监督学习(指导性反馈)的区别。评价性反馈完全依赖于所选择的动作(即所产生的样本),而指导性反馈则与所选择的动作(即所产生的样本)无关。
因此,所有RL的算法思路都是为了评估一个动作的好坏,有的用Value,有的用策略梯度,异曲同工之妙。
在Sutton的RL入门经典书本中最先出现的强化学习问题叫Bandit,即在该问题中,只有一个state,经历完该state,该问题就结束了。k-armed Bandit则是在该state中有k个选择。每个动作选择都有即时回报R,但这个R不是一个确定值,是一个服从某种概率分布的随机值,我们可用R的期望来表示该动作的真实价值,记为q。但是,在实际问题中我们并不知道哪个选择的真实价值最大,因此我们可以利用大数定理,通过多次采样,利用 sample average的方法求得动作的估计值Q,用Q来逼近真实值q。这个过程称为探索(explore)。
Bandit问题根据动作的即时回报R的概率分布分为:
1. Stationary,即概率分布确定不变。
2. Nonstationary,即概率分布不确定。
对于Stationary情况,在此举一个10-armed bandit问题,来测试单纯的greedy学习策略和ε-greedy学习策略的学习效率和效果,以验证explore和exploit的相关性质。
对于每一次实验中,都是同一个bandit问题,即动作价值的真实值(q)不变。每一次实验将进行1000个回合(注意,这里),或称为时间步(time step)。在这1000个回合中,每个动作的即时回报R(actual reward)的概率分布都一样,即每个动作i的即时回报R(actual reward)服从均值为q*(i),方差为1的高斯分布,如图中灰色部分所示。(可以将下图理解为某一次实验中的bandit问题的动作即时回报的概率分布,简称为R概率分布图。)
为了避免特殊性,减少实验误差,将进行2000次不同bandit问题的实验(run/episode),即每次实验的动作价值的真实值(q )都不一样,每一次实验是都独立的。并且每次实验每个动作i的真实值q*(i)分布服从均值为0,方差为1的高斯分布。(即每一个实验中的Bandit问题的R概率分布图都不一样)
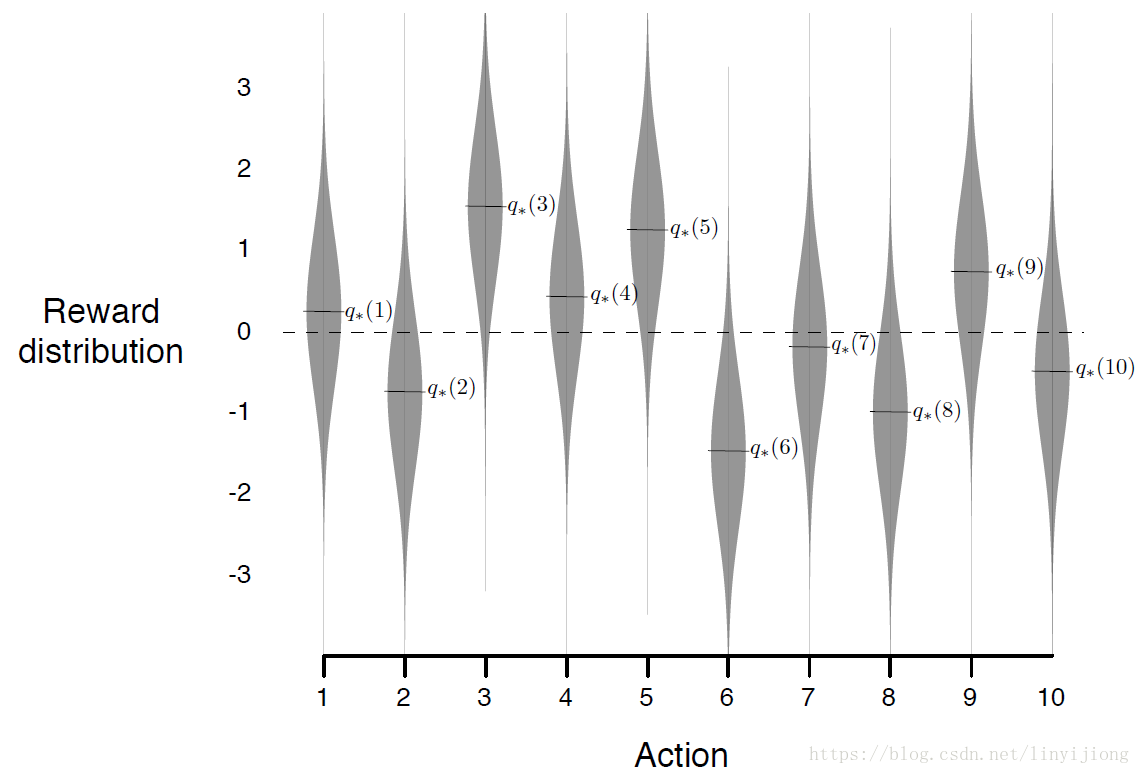
(上述关于实验的描述就涉及到两个容易混淆的概率分布,q distribution和actual reward distribution:每个动作i的真实值q*(i)服从均值为0,方差为1的高斯分布;而每一个动作i的即时回报R(actual reward)服从均值为q*(i),方差为1的高斯分布,如图中灰色部分所示。)
实验结果如下,第一幅图利用sample average方法来比较三种学习策略的效果:纯greedy策略虽然在一开始能够快速改善、提升学习效果,但是从长远来看并不是优于其他两种策略,陷入了一个为1的局部最优。在这里ε-greedy在长远学习效果更好。不过单纯的greedy并不是总表现很差:对于方差为0的即时回报R分布,则用纯greedy最好,因为把所有动作都试一次就能知道最优动作。但对于即时回报R服从方差比较大的分布,则用较大的ε会比较好,这样会有更多的探索。(方差为即时回报R的离散程度)
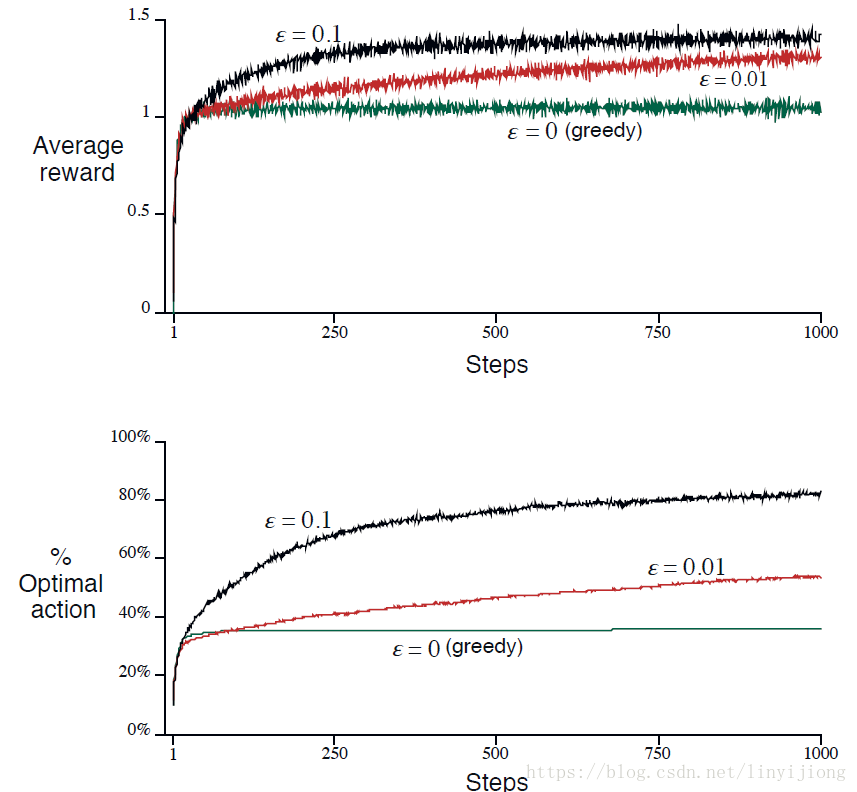
而在实际问题中,Nonstationary更为常见,因此鼓励用ε-greedy学习策略。
step-size parameter (步距参数)
step-size parameter (步距参数)序列需要满足两个数学条件才能确保estimate百分百收敛。
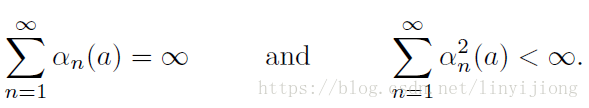
前面条件确保了步距(step)最终足够大,来克服初始条件和随机震动带来的不稳定因素。
后面条件确保了步距最终足够小来确保收敛。
针对Nonstationary,通常情况下步距设为一个常数值,这样的话该步距序列并不满足上述条件2,但正因为这样能够符合nonstationary的情况,即estimate从来不会完全收敛,而是随着最近收到的奖励(nonstationary情况下奖励的期望也是变化的)而继续变化。 在这种情况下,我们需要更加依赖近期的reward信息,而不太依赖很远时间前的reward信息。另外,满足上述两个条件的stepsize收敛通常都非常慢,并且需要大量的调参,才能使得其收敛效果令人满意。尽管这种条件上的限制性在理论上很重要,在实际应用中其实大家都不怎么在意这些限制条件。
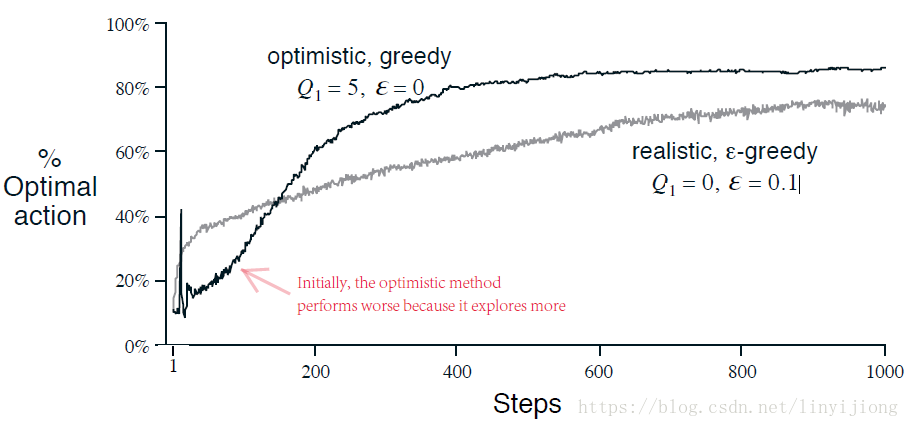
Optimistic Initial Values
大部分RL的算法都与初始动作价值的选取有关,在统计学上这种称为“偏移”(bias)。不过一部分可以通过大数定理消除这种偏移。但若果步距选择是一个常数的话,就这种偏移就是永久存在的(即使可以淡化)。不过这种偏移可以作为关于价值评估的先验知识(prior knowledge),来提高学习策略的效果。
比如,我们把之前实验中的estimate value的初始值都设置为5,而不是0。由于real value来源于均值为0,方差为1的正态分布(实际选择时会有一定的噪声),那么相对于real value,estiamate value的初始值就偏大了。这样的话,执行机构就会发现第一个动作选项的reward小于estimate value,于是转而尝试第二个选项,很大概率上执行机构会发现几乎所有选项的reward都小于estimate value,结果就是无形中把这些选项都exploration了一遍,就算是greedy算法也是如此。
这种技巧称为Optimistic Initial Values,它也仅能作为技巧,不能作为一种通用的方法。而且这种技巧对于stationary有效,但对于Nonstationary没有效果,因为Nonstationary中,但任务改变,需要重新探索的时候,我们不可能再去设置初始价值。