该博客是针对Github上wudi/PHP-Interview-Best-Practices-in-China资源的答案整理
lz也是初学者,以下知识点均为自己整理且保持不断更新,也希望各路大神多多指点,若发现错误或有补充,可直接comment,lz时刻关注着。
由于内容比较多,没有目录,请自行对照GIthub包;没有仔细整理格式,各位见谅见谅!
基础篇
了解大部分数组处理函数
- array_chunk — 将一个数组分割成多个
- array_column — 返回数组中指定的一列
- array_combine — 创建一个数组,用一个数组的值作为其键名,另一个数组的值作为其值(另一种意义的合并数组)
- array_flip — 交换数组中的键和值
- array_key_exists — 检查数组里是否有指定的键名或索引
- array_key_first — Gets the first key of an array
- array_key_last — Gets the last key of an array
- array_keys — 返回数组中部分的或所有的键名
- array_merge — 合并一个或多个数组
- array_pop — 弹出数组最后一个单元(出栈)
- array_push — 将一个或多个单元压入数组的末尾(入栈)
- array_rand — 从数组中随机取出一个或多个单元
- array_reverse — 返回单元顺序相反的数组
- array_search — 在数组中搜索给定的值,如果成功则返回首个相应的键名
- array_shift — 将数组开头的单元移出数组
- array_slice — 从数组中取出一段
- array_sum — 对数组中所有值求和
- array_unique — 移除数组中重复的值
- array_unshift — 在数组开头插入一个或多个单元
- array_values — 返回数组中所有的值
- in_array — 检查数组中是否存在某个值
- list — 把数组中的值赋给一组变量
- shuffle — 打乱数组
- sort — 对数组排序
- uasort — 使用用户自定义的比较函数对数组中的值进行排序并保持索引关联
- uksort — 使用用户自定义的比较函数对数组中的键名进行排序
- usort — 使用用户自定义的比较函数对数组中的值进行排序
字符串处理函数 ,区别 mb_ 系列函数
- chunk_split — 将字符串分割成小块
- explode — 使用一个字符串分割另一个字符串
- implode — 将一个一维数组的值转化为字符串
- lcfirst — 使一个字符串的第一个字符小写
- ltrim — 删除字符串开头的空白字符(或其他字符)
- md5 — 计算字符串的 MD5 散列值
- money_format — 将数字格式化成货币字符串
- nl2br — 在字符串所有新行之前插入 HTML 换行标记
- number_format — 以千位分隔符方式格式化一个数字
- ord — 返回字符的 ASCII 码值
- rtrim — 删除字符串末端的空白字符(或者其他字符)
- str_replace — 子字符串替换
- str_ireplace — str_replace 的忽略大小写版本
- str_repeat — 重复一个字符串
- str_shuffle — 随机打乱一个字符串
- str_split — 将字符串转换为数组
- stripos — 查找字符串首次出现的位置(不区分大小写)
- strpos — 查找字符串首次出现的位置
- strstr — 查找字符串的首次出现
- stristr — strstr 函数的忽略大小写版本
- strlen — 获取字符串长度
- strrchr — 查找指定字符在字符串中的最后一次出现
- strrev — 反转字符串
- strripos — 计算指定字符串在目标字符串中最后一次出现的位置(不区分大小写)
- strrpos — 计算指定字符串在目标字符串中最后一次出现的位置
- strtok — 标记分割字符串
- strtolower — 将字符串转化为小写
- strtoupper — 将字符串转化为大写
- substr_count — 计算字串出现的次数
- substr_replace — 替换字符串的子串
- substr — 返回字符串的子串
- trim — 去除字符串首尾处的空白字符(或者其他字符)
- ucfirst — 将字符串的首字母转换为大写
- ucwords — 将字符串中每个单词的首字母转换为大写
- wordwrap — 打断字符串为指定数量的字串
普通字符串处理函数和mb_系列函数的区别:
不同编码的个别语言(比如中文)所占字节数不同,一个汉字在GB2312编码下占2个字节,在UTF-8(是变长编码)编码下占2-3个字节,普通字符串处理函数是按每个字符1字节来处理的,而mb_系列的函数在使用时可以多指定一个编码参数,方便处理不同编码的中文。
最简单的例子,strlen()会返回一个字符串所占字节数,而mb_strlen()会返回一个字符串的字符数。再比如,substr($str2, 2, 2)在$str为中文时可能会正好截取到一个汉字的一部分,这时就会发生乱码,而mb_substr($str, 2, 2, ‘utf-8’)指定编码后就不会发生乱码问题了,中文时即是取几个汉字。
& 引用,结合案例分析
PHP 的引用允许用两个变量来指向同一个内容。
$a =& $b;
$a 和 $b 在这里是完全相同的,这并不是 $a 指向了 $b 或者相反,而是 $a 和 $b 指向了同一个地方;
引用做的第二件事是用引用传递变量
function foo(&$var)
{ $var++; }
$a=5;
foo($a);
将使 $a 变成 6。这是因为在 foo 函数中变量 $var 指向了和 $a 指向的同一个内容。
引用不是指针,下面的结构不会产生预期的效果:
function foo(&$var)
{ $var =& $GLOBALS["baz"]; }
foo($bar);
当 unset 一个引用,只是断开了变量名和变量内容之间的绑定。这并不意味着变量内容被销毁了。例如:
$a = 1;
$b =& $a;
unset($a);
不会 unset $b,只是 $a。
== 与 === 区别
简单来说,==是不带类型比较是否相同(比如数字100 == ‘100’结果为true),===是带类型比较是否相同(比如100 == ‘100’结果为false),官方手册的解释也类似:
isset 与 empty 区别
看到一个简洁代码的解释:
再具体说:$a不存在和$a = null 两种情况在isset看来为true,其余为false(包括$a = ‘’;)
$a = null, 0, false, ‘ ’, 或不存在时在empty看来为true,其余为false。
再多说一句,isset用来判断变量是否存在;empty用来判断变量是否有值;这里要特别注意0这个值在某些表单验证情况下可能是有效值,此时不能仅用empty判断变量是否有值,需要另作处理。
全部魔术函数理解
- __construct 类的构造函数,常用来给类的属性赋值,注意事项:
如果子类中定义了构造函数则不会隐式调用其父类的构造函数。要执行父类的构造函数,需要在子类的构造函数中调用 parent::__construct()。如果子类没有定义构造函数则会如同一个普通的类方法一样从父类继承(假如没有被定义为 private 的话)
- __destruct 析构函数,析构函数会在到某个对象的所有引用都被删除或者当对象被显式销毁时执行。
- __call,__callStatic 在对象中调用一个不可访问方法时,__call() 会被调用。在静态上下文中调用一个不可访问方法时,__callStatic() 会被调用,作为调用类中不存在的方法时对开发者的一个友好提示
- __set,__get,__isset ,__unset 在给不可访问属性赋值时,__set() 会被调用;读取不可访问属性的值时,__get() 会被调用;当对不可访问属性调用 isset() 或 empty() 时,__isset() 会被调用;当对不可访问属性调用 unset() 时,__unset() 会被调用。
- __sleep,__wakeup serialize() 函数会检查类中是否存在一个魔术方法 __sleep()。如果存在,该方法会先被调用,然后才执行序列化操作。此功能可以用于清理对象,并返回一个包含对象中所有应被序列化的变量名称的数组。如果该方法未返回任何内容,则 NULL 被序列化,并产生一个 E_NOTICE 级别的错误.返回父类的私有成员的名字,常用于提交未提交的数据,或类似的清理操作;与之相反,unserialize() 会检查是否存在一个 __wakeup() 方法。如果存在,则会先调用 __wakeup 方法,预先准备对象需要的资源。__wakeup() 经常用在反序列化操作中,例如重新建立数据库连接,或执行其它初始化操作
- __toString 用于当直接echo $obj(一个对象)时该显示什么内容,必须返回一个字符串且不能在方法内抛出异常
- __invoke 当尝试以调用函数的方式调用一个对象时,__invoke() 方法会被自动调用,例如function __invoke($x) { var_dump($x); } $obj = new CallableClass; $obj(5);会输出int(5)
- __set_state 调用 var_export() 导出类时,此静态 方法会被调用。本方法的唯一参数是一个数组,其中包含按 array('property' => value, ...) 格式排列的类属性
- __clone 对象复制可以通过 clone 关键字来完成(如果可能,这将调用对象的 __clone() 方法)。对象中的 __clone() 方法不能被直接调用。
- $copy_of_object = clone $object; 当对象被复制后,PHP 5 会对对象的所有属性执行一个浅复制(shallow copy)。所有的引用属性 仍然会是一个指向原来的变量的引用。当复制完成时,如果定义了 __clone() 方法,则新创建的对象(复制生成的对象)中的 __clone() 方法会被调用,可用于修改属性的值(如果有必要的话)。
- __debugInfo 当var_dumo(new Class)(参数为一个对象时),该方法可以控制显示的内容,若没有定义此方法,var_dump()将默认展示对象的所有属性和方法
static、$this、self 区别
$this通俗解释就是当前类的一个实例,不必多说,主要是static::和self::的区别
class A {
public static function className(){
echo __CLASS__;
}
public static function test(){
self::className();
}}
class B extends A{
public static function className(){
echo __CLASS__;
}}
B::test();
这将打印出来A
另一方面static::它具有预期的行为
class A {
public static function className(){
echo __CLASS__;
}
public static function test(){
static::className();
}}
class B extends A{
public static function className(){
echo __CLASS__;
}}
B::test();
这将打印出来B
这在PHP 5.3.0中称为后期静态绑定。它解决了调用运行时引用的类的限制。
private、protected、public、final 区别
public:权限是最大的,可以内部调用,实例调用等。
protected: 受保护类型,用于本类和继承此类的子类调用。
private: 私有类型,只有在本类中使用。
static:静态资源,可以被子类继承。
abstract:修饰抽象方法,没有方法体,由继承该类的子类来实现。
final:表示该变量、该方法已经“完成”,不可被覆盖。修饰类时该类不能被继承。
(因此final和abstract不能同时出现)
OOP 思想
简单理解:
面向对象的编程就是编出一个人来,这个人可以做很多种动作,跑,跳,走,举手...他能做什么取决于你如何组合这些动作,有些动作在一些功能中是不用的。
而层次化的编程(面向过程)就是造出一个具体的工具,他只能干这样一件事,条件——结果。
抽象类、接口 分别使用场景
接口通常是为了抽象一种行为,接口是一种规范,在设计上的意义是为了功能模块间的解耦,方便后面的功能扩展、维护,接口不能有具体的方法;
抽象类可以有具体的方法,也可以有抽象方法,一旦一个类有抽象方法,这个类就必须声明为抽象类,很多时候是为子类提供一些共用方法;
所以,抽象类是为了简化接口的实现,他不仅提供了公共方法的实现,让你可以快速开发,又允许你的类完全可以自己实现所有的方法,不会出现紧耦合的问题。
应用场合很简单了
1 优先定义接口
2 如果有多个接口实现有公用的部分,则使用抽象类,然后集成它。
举个简单的例子:有一个动物接口,内有动物叫声和动物说你好两个方法,在实现该接口时各个动物的叫声肯定是不同的,但是他们都在说你好是相同的,此时就可以用抽象类,把相同的说你好的方法抽象出去,就不用在每个动物类中写了。
Trait 是什么东西
Trait 是为类似 PHP 的单继承语言而准备的一种代码复用机制。Trait 为了减少单继承语言的限制,使开发人员能够自由地在不同层次结构内独立的类中复用 method。Trait 和 Class 组合的语义定义了一种减少复杂性的方式,避免传统多继承和 Mixin 类相关典型问题。
Trait 和 Class 相似,但仅仅旨在用细粒度和一致的方式来组合功能。 无法通过 trait 自身来实例化。它为传统继承增加了水平特性的组合;也就是说,应用的几个 Class 之间不需要继承。
简单理解:Trait为不支持多继承的php实现了多继承,使用时不是用extends继承,而是在类内部用 use 类名 表示。
重名方法优先级问题:当前类的成员覆盖 trait 的方法,而 trait 则覆盖被继承的方法。
echo、print、print_r 区别(区分出表达式与语句的区别)
Echo,print是语言结构,print_r和var_dump是常规功能
print并且echo或多或少相同; 它们都是显示字符串的语言结构。差异很微妙:print返回值为1,因此可以在表达式中使用,但echo具有void返回类型; echo可以采用多个参数,尽管这种用法很少见; echo比print快一点。(就个人而言,我总是使用echo,从不print。)
var_dump打印出变量的详细转储,包括其类型大小和任何子项的类型和大小(如果它是数组或对象)。
print_r以更易于阅读的格式化形式打印变量(数组或对象):不能传递字符串,它省略了类型信息,不给出数组大小等。
var_dump, print_r根据我的经验,通常在调试时更有用。当您不确切知道变量中的值/类型时,它尤其有用。考虑这个测试程序:
$values = array(0, 0.0, false, '');
var_dump($values);
print_r ($values);
随着print_r你不能告诉之间的区别0和0.0,或false和'':
array(4) {
[0]=> int(0)
[1]=> float(0)
[2]=> bool(false)
[3]=> string(0) ""
}
Array(
[0] => 0
[1] => 0
[2] =>
[3] => )
__construct 与 __destruct 区别
在一个类中定义一个方法作为构造函数。具有构造函数的类会在每次创建新对象时先调用此方法,所以非常适合在使用对象之前做一些初始化工作。
析构函数会在到某个对象的所有引用都被删除或者当对象被显式销毁时执行。和构造函数一样,父类的析构函数不会被引擎暗中调用。要执行父类的析构函数,必须在子类的析构函数体中显式调用 parent::__destruct()。此外也和构造函数一样,子类如果自己没有定义析构函数则会继承父类的。析构函数即使在使用 exit() 终止脚本运行时也会被调用。在析构函数中调用 exit() 将会中止其余关闭操作的运行。
static 作用(区分类与函数内)手册 、SOF
声明类属性或方法为静态,就可以不实例化类而直接访问。静态属性不能通过一个类已实例化的对象来访问(但静态方法可以)。
为了兼容 PHP 4,如果没有指定访问控制,属性和方法默认为公有。
由于静态方法不需要通过对象即可调用,所以伪变量 $this 在静态方法中不可用。
静态属性不可以由对象通过 -> 操作符来访问,但可以由对象通过 :: 来访问
用静态方式调用一个非静态方法会导致一个 E_STRICT 级别的错误。
就像其它所有的 PHP 静态变量一样,静态属性只能被初始化为文字或常量,不能使用表达式。所以可以把静态属性初始化为整数或数组,但不能初始化为另一个变量或函数返回值,也不能指向一个对象。
也可以用一个值等于类名的字符串变量来动态调用类。但该变量的值不能为关键字 self,parent 或 static,比如有个class A{}, 则可以用$a=’A’; $a::这样调用
在类之外(即:在函数中),static变量是在函数退出时不会丢失其值的变量。在同一函数的不同调用中维护的变量只有一个值。从PHP手册的例子:
function test(){
static $a = 0;
echo $a;
$a++;}
test(); // prints 0
test(); // prints 1
test(); // prints 2
__toString() 作用
用于一个类被当成字符串时应怎样回应。例如 echo $obj; ($obj为一个对象) 应该显示些什么。此方法必须返回一个字符串,否则将发出一条E_RECOVERABLE_ERROR 级别的致命错误。类似与Java的toString方法
单引号'与双引号"区别
- 单引号字符串几乎完全“按原样”显示。变量和大多数转义序列都不会被解释。例外情况是,要显示单引号字符,必须使用反斜杠\'转义它,要显示反斜杠字符,必须使用另一个反斜杠转义它\\。
- 双引号字符串将显示一系列转义字符(包括一些正则表达式),并且将解析字符串中的变量。这里重要的一点是,您可以使用花括号来隔离要解析的变量的名称。例如,假设您有变量$type,那么您echo "The $type are"将查找该变量$type。绕过这个用途echo "The {$type} are"您可以在美元符号之前或之后放置左括号。看一下字符串解析,看看如何使用数组变量等。
- Heredoc字符串语法就像双引号字符串一样。它始于<<<。在此运算符之后,提供标识符,然后提供换行符。字符串本身如下,然后再次使用相同的标识符来关闭引号。您不需要在此语法中转义引号。
- Nowdoc(自PHP 5.3.0开始)字符串语法基本上类似于单引号字符串。不同之处在于,甚至不需要转义单引号或反斜杠。nowdoc用与heredocs相同的<<<序列标识,但后面的标识符用单引号括起来,例如<<<'EOT'。在nowdoc中没有解析。
常见 HTTP 状态码,分别代表什么含义,301 什么意思 404 呢?
- 1xx消息:这一类型的状态码,代表请求已被接受,需要继续处理。由于HTTP/1.0协议中没有定义任何1xx状态码,所以除非在某些试验条件下,服务器禁止向此类客户端发送1xx响应。
- 2xx成功:这一类型的状态码,代表请求已成功被服务器接收、理解、并接受
- 200 OK:请求已成功,请求所希望的响应头或数据体将随此响应返回。实际的响应将取决于所使用的请求方法。在GET请求中,响应将包含与请求的资源相对应的实体。在POST请求中,响应将包含描述或操作结果的实体
- 202 Accepted:服务器已接受请求,但尚未处理。最终该请求可能会也可能不会被执行,并且可能在处理发生时被禁止。
- 204 No Content:服务器成功处理了请求,没有返回任何内容
- 3xx重定向:这类状态码代表需要客户端采取进一步的操作才能完成请求。通常,这些状态码用来重定向,后续的请求地址(重定向目标)在本次响应的Location域中指明。
- 301 Moved Permanently:被请求的资源已永久移动到新位置,并且将来任何对此资源的引用都应该使用本响应返回的若干个URI之一。如果可能,拥有链接编辑功能的客户端应当自动把请求的地址修改为从服务器反馈回来的地址。除非额外指定,否则这个响应也是可缓存的。新的永久性的URI应当在响应的Location域中返回。除非这是一个HEAD请求,否则响应的实体中应当包含指向新的URI的超链接及简短说明。如果这不是一个GET或者HEAD请求,那么浏览器禁止自动进行重定向,除非得到用户的确认,因为请求的条件可能因此发生变化。注意:对于某些使用HTTP/1.0协议的浏览器,当它们发送的POST请求得到了一个301响应的话,接下来的重定向请求将会变成GET方式。
- 4xx客户端错误:这类的状态码代表了客户端看起来可能发生了错误,妨碍了服务器的处理。除非响应的是一个HEAD请求,否则服务器就应该返回一个解释当前错误状况的实体,以及这是临时的还是永久性的状况。这些状态码适用于任何请求方法。浏览器应当向用户显示任何包含在此类错误响应中的实体内容
- 400 Bad Request:由于明显的客户端错误(例如,格式错误的请求语法,太大的大小,无效的请求消息或欺骗性路由请求),服务器不能或不会处理该请求
- 401 Unauthorized:类似于403 Forbidden,401语义即“未认证”,即用户没有必要的凭据。[32]该状态码表示当前请求需要用户验证。该响应必须包含一个适用于被请求资源的WWW-Authenticate信息头用以询问用户信息。客户端可以重复提交一个包含恰当的Authorization头信息的请求。
- 403 Forbidden:服务器已经理解请求,但是拒绝执行它。与401响应不同的是,身份验证并不能提供任何帮助,而且这个请求也不应该被重复提交。如果这不是一个HEAD请求,而且服务器希望能够讲清楚为何请求不能被执行,那么就应该在实体内描述拒绝的原因。当然服务器也可以返回一个404响应,假如它不希望让客户端获得任何信息。
- 404 Not Found:请求失败,请求所希望得到的资源未被在服务器上发现,但允许用户的后续请求。[35]没有信息能够告诉用户这个状况到底是暂时的还是永久的。假如服务器知道情况的话,应当使用410状态码来告知旧资源因为某些内部的配置机制问题,已经永久的不可用,而且没有任何可以跳转的地址。404这个状态码被广泛应用于当服务器不想揭示到底为何请求被拒绝或者没有其他适合的响应可用的情况下。
- 405 Method Not Allowed:请求行中指定的请求方法不能被用于请求相应的资源。
- 408 Request Timeout:请求超时
- 5xx服务器错误:表示服务器无法完成明显有效的请求。[56]这类状态码代表了服务器在处理请求的过程中有错误或者异常状态发生,也有可能是服务器意识到以当前的软硬件资源无法完成对请求的处理。除非这是一个HEAD请求,否则服务器应当包含一个解释当前错误状态以及这个状况是临时的还是永久的解释信息实体。浏览器应当向用户展示任何在当前响应中被包含的实体。这些状态码适用于任何响应方法
- 500 Internal Server Error:通用错误消息,服务器遇到了一个未曾预料的状况,导致了它无法完成对请求的处理。没有给出具体错误信息
- 502 Bad Gateway:作为网关或者代理工作的服务器尝试执行请求时,从上游服务器接收到无效的响应
- 503 Service Unavailable:由于临时的服务器维护或者过载,服务器当前无法处理请求。这个状况是暂时的,并且将在一段时间以后恢复。
- 504 Gateway Timeout:作为网关或者代理工作的服务器尝试执行请求时,未能及时从上游服务器(URI标识出的服务器,例如HTTP、FTP、LDAP)或者辅助服务器(例如DNS)收到响应。注意:某些代理服务器在DNS查询超时时会返回400或者500错误。
进阶篇
Autoload、Composer 原理 PSR-4 、原理
Autoload机制可以使得PHP程序有可能在使用类时才自动包含类文件,而不是一开始就将所有的类文件include进来,这种机制也称为lazy loading(懒加载)
function __autoload($classname)
{
$classpath="./".$classname.'.class.php';
if(file_exists($classpath))
{ require_once($classpath); }
else
{ echo 'class file'.$classpath.'not found!'; }
}
$person = new Person(”Altair”, 6);
var_dump ($person);
通常PHP5在使用一个类时,如果发现这个类没有加载,就会自动运行__autoload()函数,在这个函数中我们可以加载需要使用的类。autoload至少要做三件事情,第一件事是根据类名确定类文件名,第二件事是确定类文件所在的磁盘路径(在我们的例子是最简单的情况,类与调用它们的PHP程序文件在同一个文件夹下),第三件事是将类从磁盘文件中加载到系统中(php7.2废除__autoload函数,建议使用spl_autoload_register() 实现相同功能)
Autoload原理简单概述:
1.检查执行器全局变量函数指针autoload_func是否为NULL。
2.如果autoload_func==NULL, 则查找系统中是否定义有__autoload()函数,如果没有,则报告错误并退出。
3.如果定义了__autoload()函数,则执行__autoload()尝试加载类,并返回加载结果。
4.如果autoload_func不为NULL,则直接执行autoload_func指针指向的函数用来加载类。注意此时并不检查__autoload()函数是否定义。
spl_autoload_register() 就是我们上面所说的__autoload调用堆栈,我们可以向这个函数注册多个我们自己的 autoload() 函数,当 PHP 找不到类名时,PHP就会调用这个堆栈,然后去调用自定义的 autoload() 函数,实现自动加载功能。如果我们不向这个函数输入任何参数,那么就会默认注册 spl_autoload() 函数
Composer 做了哪些事情:你有一个项目依赖于若干个库;其中一些库依赖于其他库;你声明你所依赖的东西;Composer 会找出哪个版本的包需要安装,并安装它们(将它们下载到你的项目中)。
执行 composer require 时发生了什么:composer 会找到符合 PR4 规范的第三方库的源;将其加载到 vendor 目录下;初始化顶级域名的映射并写入到指定的文件里;写好一个 autoload 函数,并且注册到 spl_autoload_register()里。
Composer是利用的遵循psr-4规范的类自动加载机制实现的,PSR-4规范简介:
- 完整的类名 必须 要有一个顶级命名空间,被称为 "vendor namespace";
- 完整的类名 可以 有一个或多个子命名空间;
- 完整的类名 必须 有一个最终的类名;
- 完整的类名中任意一部分中的下滑线都是没有特殊含义的;
- 完整的类名 可以 由任意大小写字母组成;
- 所有类名都 必须 是大小写敏感的。
- 完整的类名中,去掉最前面的命名空间分隔符,前面连续的一个或多个命名空间和子命名空间,作为「命名空间前缀」,其必须与至少一个「文件基目录」相对应;
- 紧接命名空间前缀后的子命名空间 必须 与相应的「文件基目录」相匹配,其中的命名空间分隔符将作为目录分隔符。
- 末尾的类名 必须 与对应的以 .php 为后缀的文件同名。
- 自动加载器(autoloader)的实现 一定不可 抛出异常、一定不可 触发任一级别的错误信息以及 不应该 有返回值。
Composer自动加载原理概述:
如果我们在代码中写下 new phpDocumentor\Reflection\Element(),PHP 会通过 SPL_autoload_register 调用 loadClass -> findFile -> findFileWithExtension。步骤如下:
将 \ 转为文件分隔符/,加上后缀php,变成 $logicalPathPsr4, 即 phpDocumentor/Reflection//Element.php;
利用命名空间第一个字母p作为前缀索引搜索 prefixLengthsPsr4 数组,查到下面这个数组:
p' =>
array (
'phpDocumentor\\Reflection\\' => 25,
'phpDocumentor\\Fake\\' => 19,
)
遍历这个数组,得到两个顶层命名空间 phpDocumentor\Reflection\ 和 phpDocumentor\Fake\
在这个数组中查找 phpDocumentor\Reflection\Element,找出 phpDocumentor\Reflection\ 这个顶层命名空间并且长度为25。
在prefixDirsPsr4 映射数组中得到phpDocumentor\Reflection\ 的目录映射为:
'phpDocumentor\\Reflection\\' =>
array (
0 => __DIR__ . '/..' . '/phpdocumentor/reflection-common/src',
1 => __DIR__ . '/..' . '/phpdocumentor/type-resolver/src',
2 => __DIR__ . '/..' . '/phpdocumentor/reflection-docblock/src',
),
遍历这个映射数组,得到三个目录映射;
查看 “目录+文件分隔符//+substr($logicalPathPsr4, $length)”文件是否存在,存在即返回。这里就是
'__DIR__/../phpdocumentor/reflection-common/src + substr(phpDocumentor/Reflection/Element.php,25)'
如果失败,则利用 fallbackDirsPsr4 数组里面的目录继续判断是否存在文件
Session 共享、存活时间
为什么要使用Session共享:
分布式开发项目中,用户通过浏览器登录商城,实际上会被转发到不同的服务器,当用户登录进入服务器A,session保存了用户的信息,用户再次点击页面被转发到服务器B,这时问题来了,服务器B没有该用户的session信息,无法验证通过,用户被踢回到登录页面,这样体验效果非常不好,甚至无法验证用户,购物车里面商品都不存在了。
利用Redis实现简单的Session共享:
- 用户第一次进入商城首页,给一个CSESSIONID,(不用JSESSIONID的原因),用户添加商品,各种需要记录的操作,都与这个CSESSIONID关联起来;
- 当使用登录操作时候,将这个用户的信息,如用户名等存入到redis中,通过K_V,将CSESSIONID加一个标志作为key,将用户信息作为value;
- 当用户点击页面被转发到其他服务器时候,在需要验证是否同一个用户时,就可以从redis中取出value,进行验证用户信息,实现共享。
Session 在php配置文件中的默认有效时间是24分钟,设置session永久有效的方法:
如果拥有服务器的操作权限,那么只需要进行如下的步骤:
1、把“session.use_cookies”设置为1,打开Cookie储存SessionID,不过默认就是1,一般不用修改;
2、把“session.cookie_lifetime”改为正无穷(当然没有正无穷的参数,不过999999999和正无穷也没有什么区别);
3、把“session.gc_maxlifetime”设置为和“session.cookie_lifetime”一样的时间;
异常处理
异常处理用于在指定的错误(异常)情况发生时改变脚本的正常流程。这种情况称为异常。
异常的简单使用:
抛出一个异常throw new Exception("Value must be 1 or below"),同时不去捕获它,服务器会报Fatal error: Uncaught exception 'Exception' 的错误;
抛出一个异常throw new Exception("Value must be 1 or below"),并try{} catch(Exception $e){echo:’Message:’ . $e->getMessage();},当异常发生时,服务器就会报预设的错误提示:Message: Value must be 1 or below
自定义Exception类:必须继承Exception类,可以使用Exception类的所有方法:
class customException extends Exception
{
public function errorMessage()
{
//error message
$errorMsg = 'Error on line '.$this->getLine().' in '.$this->getFile()
.': <b>'.$this->getMessage().'</b> is not a valid E-Mail address';
return $errorMsg;
}
}
异常的规则:
- 需要进行异常处理的代码应该放入 try 代码块内,以便捕获潜在的异常。
- 每个 try 或 throw 代码块必须至少拥有一个对应的 catch 代码块。
- 使用多个 catch 代码块可以捕获不同种类的异常。
- 可以在 try 代码块内的 catch 代码块中再次抛出(re-thrown)异常。
简而言之:如果抛出了异常,就必须捕获它
如何 foreach 迭代对象
展示foreach工作原理的例子:
class myIterator implements Iterator {
private $position = 0;
private $array = array(
"firstelement",
"secondelement",
"lastelement",
);
public function __construct() {
$this->position = 0;
}
//返回到迭代器的第一个元素
function rewind() {
var_dump(__METHOD__);
$this->position = 0;
}
// 返回当前元素
function current() {
var_dump(__METHOD__);
return $this->array[$this->position];
}
//返回当前元素的键
function key() {
var_dump(__METHOD__);
return $this->position;
}
//向前移动到下一个元素
function next() {
var_dump(__METHOD__);
++$this->position;
}
//检查当前位置是否有效
function valid() {
var_dump(__METHOD__);
return isset($this->array[$this->position]);
}
}
$it = new myIterator;
foreach($it as $key => $value) {
var_dump($key, $value);
echo "\n";
}
输出结果:
string(18) "myIterator::rewind"
string(17) "myIterator::valid"
string(19) "myIterator::current"
string(15) "myIterator::key"
int(0)
string(12) "firstelement"
string(16) "myIterator::next"
string(17) "myIterator::valid"
string(19) "myIterator::current"
string(15) "myIterator::key"
int(1)
string(13) "secondelement"
string(16) "myIterator::next"
string(17) "myIterator::valid"
string(19) "myIterator::current"
string(15) "myIterator::key"
int(2)
string(11) "lastelement"
string(16) "myIterator::next"
string(17) "myIterator::valid"
如何数组化操作对象 $obj[key];
PHP提供了ArrayAccess接口使实现此接口的类的实例可以向操作数组一样通过$obj[key]来操作,以下是php手册中对实现ArrayAccess接口的类的示例:
class obj implements arrayaccess {
private $container = array();
public function __construct() {
$this->container = array(
"one" => 1,
"two" => 2,
"three" => 3,
);
}
//设置一个偏移位置的值
public function offsetSet($offset, $value) {
if (is_null($offset)) {
$this->container[] = $value;
} else {
$this->container[$offset] = $value;
}
}
//检查一个偏移位置是否存在
public function offsetExists($offset) {
return isset($this->container[$offset]);
}
//复位一个偏移位置的值
public function offsetUnset($offset) {
unset($this->container[$offset]);
}
//获取一个偏移位置的值
public function offsetGet($offset) {
return isset($this->container[$offset]) ? $this->
container[$offset] : null;
}
}
对该类测试使用:
$obj = new obj;
var_dump(isset($obj["two"]));
var_dump($obj["two"]);
unset($obj["two"]);
var_dump(isset($obj["two"]));
$obj["two"] = "A value";
var_dump($obj["two"]);
$obj[] = 'Append 1';
$obj[] = 'Append 2';
$obj[] = 'Append 3';
print_r($obj);
?>
以上例程的输出类似于:
bool(true)
int(2)
bool(false)
string(7) "A value"
obj Object
(
[container:obj:private] => Array
(
[one] => 1
[three] => 3
[two] => A value
[0] => Append 1
[1] => Append 2
[2] => Append 3
)
)
如何函数化对象 $obj(123);
利用PHP提供的魔术函数__invoke()方法可以直接实现,当尝试以调用函数的方式调用一个对象时,__invoke() 方法会被自动调用,下面是官方手册示例:
class CallableClass
{
function __invoke($x) {
var_dump($x);
}
}
$obj = new CallableClass;
$obj(5);
var_dump(is_callable($obj));
输出结果:
int(5)
bool(true)
yield 是什么,说个使用场景 yield
PHP官方手册对yield的解释:
它最简单的调用形式看起来像一个return申明,不同之处在于普通return会返回值并终止函数的执行,而yield会返回一个值给循环调用此生成器的代码并且只是暂停执行生成器函数。
我的简单理解:yield起一个暂停程序的作用,比如在一个循环中,程序执行遇到yield语句就会返回yield声明的数据,而不是循环完整体返回,加了yield后就会挨个返回。
Caution:如果在一个表达式上下文(例如在一个赋值表达式的右侧)中使用yield,你必须使用圆括号把yield申明包围起来。 例如这样是有效的:$data = (yield $value);
属于PHP生成器语法,官方手册的解释:
一个生成器函数看起来像一个普通的函数,不同的是普通函数返回一个值,而一个生成器可以yield生成许多它所需要的值。
当一个生成器被调用的时候,它返回一个可以被遍历的对象.当你遍历这个对象的时候(例如通过一个foreach循环),PHP 将会在每次需要值的时候调用生成器函数,并在产生一个值之后保存生成器的状态,这样它就可以在需要产生下一个值的时候恢复调用状态。
一旦不再需要产生更多的值,生成器函数可以简单退出,而调用生成器的代码还可以继续执行,就像一个数组已经被遍历完了。
Note:一个生成器不可以返回值: 这样做会产生一个编译错误。然而return空是一个有效的语法并且它将会终止生成器继续执行。
使用场景:
laravel框架的model以游标方式取数据时,用的是yield来防止一次性取数据太多导致内存不足的问题
PSR 是什么,PSR-1, 2, 4, 7
PSR-1---基础编码规范
PSR-2---编码风格规范
PSR-4---自动加载规范
PSR-7---HTTP 消息接口规范
如何获取客户端 IP 和服务端 IP 地址
如何开启 PHP 异常提示
-
- php.ini 开启 display_errors 设置 error_reporting 等级
- 运行时,使用 ini_set(k, v); 动态设置
如何返回一个301重定向
-
- [WARNING] 一定当心设置 301 后脚本会继续执行,不要认为下面不会执行,必要时使用 die or exit
-
方法1:
header("HTTP/1.1 301 Moved Permanently");
header("Location: /option-a");
exit();
方法2:
http_response_code(301);
header('Location: /option-a');
exit;
如何获取扩展安装路径
-
- phpinfo(); 页面查找 extension_dir
- 命令行 php -i |grep extension_dir
- 运行时 echo ini_get('extension_dir');
字符串、数字比较大小的原理,注意 0 开头的8进制、0x 开头16进制
-
- 字符串比较大小,从左(高位)至右,逐个字符 ASCII 比较
-
- 字符串和数字比较,会先把字符串转换成数字类型,比如12se转换成12,abx转换成0,此时就不是字符的ASCII值与数字比较。0与任何不可转换成数字的字符串比较都是true
- 两个不同进制的数字比较会转成十进制比较(得出这个结论是因为我在php中直接输出其他进制数字时均显示十进制格式
- 猜想当数字字符串和非十进制数字比较大小时应该也是把数字转换成十进制形式再比较大小
BOM 头是什么,怎么除去
function remove_utf8_bom($text)
{
$bom = pack('H*','EFBBBF');
$text = preg_replace("/^$bom/", '', $text);
return $text;
}
什么是 MVC
MVC模式(Model–view–controller)是软件工程中的一种软件架构模式,把软件系统分为三个基本部分:模型(Model)、视图(View)和控制器(Controller)。
MVC模式最早由Trygve Reenskaug在1978年提出,是施乐帕罗奥多研究中心(Xerox PARC)在20世纪80年代为程序语言Smalltalk发明的一种软件架构。MVC模式的目的是实现一种动态的程序设计,使后续对程序的修改和扩展简化,并且使程序某一部分的重复利用成为可能。除此之外,此模式通过对复杂度的简化,使程序结构更加直观。软件系统通过对自身基本部分分离的同时也赋予了各个基本部分应有的功能。
1)最上面的一层,是直接面向最终用户的"视图层"(View)。它是提供给用户的操作界面,是程序的外壳。
2)最底下的一层,是核心的"数据层"(Model),也就是程序需要操作的数据或信息。
3)中间的一层,就是"控制层"(Controller),它负责根据用户从"视图层"输入的指令,选取"数据层"中的数据,然后对其进行相应的操作,产生最终结果。
依赖注入实现原理
一个用构造方法实现依赖注入的简单例子(原文链接):
<?php
//依赖注入(Dependency injection)也叫控制反转(Inversion of Control)是一种设计模式,这种模式用来减少程序间的耦合。
//假设我们有个类,需要用到数据库连接,我们可能这样写
class UseDataBase{
protected $adapter;
public function __construct(){
$this->adapter=new MySqlAdapter;
}
public function getList(){
$this->adapter->query("sql语句");//使用MySqlAdapter类中的query方法;
}
}
class MySqlAdapter{};
//我们可以通过依赖注入来重构上面这个例子
class UseDataBase{
protected $adapter;
public function __construct(MySqlAdapter $adapter){
$this->adapter=$adapter;
}
public function getList(){
$this->adapter->query("sql语句");//使用MySqlAdapter类中的query方法;
}
}
class MySqlAdapter{};
//但是,当我们有很多种数据库时,上面的这种方式就达不到要求或者要写很多个usedatabase类,所以我们再重构上面的这个例子
class UseDataBase{
protected $adapter;
poublic function __construct(AdapterInterface $adapter){
$this->adapter=$adapter;
}
public function getList(){
$this->adapter->query("sql语句");//使用AdapterInterface类中的query方法;
}
}
interface AdapterInterface{};
class MySqlAdapter implements AdapterInterface{};
class MSsqlAdapter implements AdapterInterface{};
//这样的话,当要使用不同的数据库时,我们只需要添加数据库类实现适配器接口就够了,
usedatabase类则不需要动。
?>
因为大多数应用程序都是由两个或者更多的类通过彼此合作来实现业务逻辑,这使得每个对象都需要获取与其合作的对象(也就是它所依赖的对象)的引用。如果这个获取过程要靠自身实现,那么将导致代码高度耦合并且难以维护和调试。
如何异步执行命令
不明白作者提出的这个问题是想问shell异步执行还是php异步执行脚本。
Shell异步执行:
bash提供了一个内置的命令来帮助管理异步执行。wait命令可以让父脚本暂停,直到指定的进程(比如子脚本)结束。
Php异步执行脚本:
必须在php.ini中注释掉disable_functions,这样popen函数才能使用。该函数打开一个指向进程的管道,该进程由派生给定的 command 命令执行而产生。打开一个指向进程的管道,该进程由派生给定的 command 命令执行而产生。所以可以通过调用它,但忽略它的输出
resource popen ( string $command , string $mode )
$command:linux命令 $mode:模式。
返回一个和 fopen() 所返回的相同的文件指针,只不过它是单向的(只能用于读或写)并且必须用 pclose() 来关闭。此指针可以用于fgets(),fgetss() 和 fwrite()。 当模式为 'r',返回的文件指针等于命令的 STDOUT,当模式为 'w',返回的文件指针等于命令的 STDIN。如果出错返回 FALSE。
这种方法不能通过HTTP协议请求另外的一个WebService,只能执行本地的脚本文件。并且只能单向打开,无法穿大量参数给被调用脚本。并且如果,访问量很高的时候,会产生大量的进程。如果使用到了外部资源,还要自己考虑竞争。
方法2
$ch = curl_init();
$curl_opt = array(
CURLOPT_URL=>'hostname/syncStock.php',
CURLOPT_RETURNTRANSFER=>1,
CURLOPT_TIMEOUT=>1,);
curl_setopt_array($ch, $curl_opt);
$out = curl_exec($ch);
curl_close($ch);
原理:通过curl去调用一个php脚本,如果响应时间超过了1秒钟,则断开该连接,程序继续往下走而syncStock.php这个脚本还在继续往下执行。
缺点:必须设置CURLOPT_TIMEOUT=>1这个属性,所以导致客户端必须至少等待1秒。但是这个属性不设置又不行,不设置的话,就会一直等待响应。就没有异步的效果了
模板引擎是什么,解决什么问题、实现原理(Smarty、Twig、Blade)
模板引擎是为了使用户界面与业务数据(内容)分离而产生的,它可以生成特定格式的文档,用于网站的模板引擎就会生成一个标准的HTML文档。
模板引擎的实现方式有很多,最简单的是“置换型”模板引擎,这类模板引擎只是将指定模板内容(字符串)中的特定标记(子字符串)替换一下便生成了最终需要的业务数据(比如网页)。
置换型模板引擎实现简单,但其效率低下,无法满足高负载的应用需求(比如有海量访问的网站),因此还出现了“解释型”模板引擎和“编译型”模板引擎等。
模板引擎可以让(网站)程序实现界面与数据分离,业务代码与逻辑代码的分离,这就大大提升了开发效率,良好的设计也使得代码重用变得更加容易。
我们司空见惯的模板安装卸载等概念,基本上都和模板引擎有着千丝万缕的联系。模板引擎不只是可以让你实现代码分离(业务逻辑代码和用户界面代码),也可以实现数据分离(动态数据与静态数据),还可以实现代码单元共享(代码重用),甚至是多语言、动态页面与静态页面自动均衡(SDE)等等与用户界面可能没有关系的功能。
Smarty:
Smarty是一个php模板引擎。更准确的说,它分离了逻辑程序和外在的内容,提供了一种易于管理的方法。Smarty总的设计理念就是分离业务逻辑和表现逻辑,优点概括如下:
速度——相对于其他的模板引擎技术而言,采用Smarty编写的程序可以获得最大速度的提高
编译型——采用Smarty编写的程序在运行时要编译成一个非模板技术的PHP文件,这个文件采用了PHP与HTML混合的方式,在下一次访问模板时将Web请求直接转换到这个文件中,而不再进行模板重新编译(在源程序没有改动的情况下),使用后续的调用速度更快
缓存技术——Smarty提供了一种可选择使用的缓存技术,它可以将用户最终看到的HTML文件缓存成一个静态的HTML页面。当用户开启Smarty缓存时,并在设定的时间内,将用户的Web请求直接转换到这个静态的HTML文件中来,这相当于调用一个静态的HTML文件
插件技术——Smarty模板引擎是采用PHP的面向对象技术实现,不仅可以在原代码中修改,还可以自定义一些功能插件(按规则自定义的函数)
强大的表现逻辑——在Smarty模板中能够通过条件判断以及迭代地处理数据,它实际上就是种程序设计语言,但语法简单,设计人员在不需要预备的编程知识前提下就可以很快学会
模板继承——模板的继承是Smarty3的新事物。在模板继承里,将保持模板作为独立页面而不用加载其他页面,可以操纵内容块继承它们。这使得模板更直观、更有效和易管理
Twig:
Twig是一个灵活,快速,安全的PHP模板语言。它将模板编译成经过优化的原始PHP代码。Twig拥有一个Sandbox模型来检测不可信的模板代码。Twig由一个灵活的词法分析器和语法分析器组成,可以让开发人员定义自己的标签,过滤器并创建自己的DSL。
Blade:
Blade 是 Laravel 提供的一个简单而又强大的模板引擎。和其他流行的 PHP 模板引擎不同,Blade 并不限制你在视图中使用原生 PHP 代码。所有 Blade 视图文件都将被编译成原生的 PHP 代码并缓存起来,除非它被修改,否则不会重新编译,这就意味着 Blade 基本上不会给你的应用增加任何负担。Blade 视图文件使用 .blade.php 作为文件扩展名,被存放在 resources/views 目录。
如何实现链式操作 $obj->w()->m()->d();
- 简单实现(关键通过做完操作后return $this;)
<?php
class Sql{
private $sql=array("from"=>"",
"where"=>"",
"order"=>"",
"limit"=>"");
public function from($tableName) {
$this->sql["from"]="FROM ".$tableName;
return $this;
}
public function where($_where='1=1') {
$this->sql["where"]="WHERE ".$_where;
return $this;
}
public function order($_order='id DESC') {
$this->sql["order"]="ORDER BY ".$_order;
return $this;
}
public function limit($_limit='30') {
$this->sql["limit"]="LIMIT 0,".$_limit;
return $this;
}
public function select($_select='*') {
return "SELECT ".$_select." ".(implode(" ",$this->sql));
}
}
$sql =new Sql();
echo $sql->from("testTable")->where("id=1")->order("id DESC")->limit(10)->select();
//输出 SELECT * FROM testTable WHERE id=1 ORDER BY id DESC LIMIT 0,10
?>
- 利用__call()方法实现
<?php
class String
{
public $value;
public function __construct($str=null)
{
$this->value = $str;
}
public function __call($name, $args)
{
$this->value = call_user_func($name, $this->value, $args[0]);
return $this;
}
public function strlen()
{
return strlen($this->value);
}
}
$str = new String('01389');
echo $str->trim('0')->strlen();
// 输出结果为 4;trim('0')后$str为"1389"
?>
Xhprof 、Xdebug 性能调试工具使用
XHProf:
XHProf 是一个轻量级的分层性能测量分析器。 在数据收集阶段,它跟踪调用次数与测量数据,展示程序动态调用的弧线图。 它在报告、后期处理阶段计算了独占的性能度量,例如运行经过的时间、CPU 计算时间和内存开销。 函数性能报告可以由调用者和被调用者终止。 在数据搜集阶段 XHProf 通过调用图的循环来检测递归函数,通过赋予唯一的深度名称来避免递归调用的循环。
XHProf 包含了一个基于 HTML 的简单用户界面(由 PHP 写成)。 基于浏览器的用户界面使得浏览、分享性能数据结果更加简单方便。 同时也支持查看调用图。
XHProf 的报告对理解代码执行结构常常很有帮助。 比如此分层报告可用于确定在哪个调用链里调用了某个函数。
XHProf 对两次运行进行比较(又名 "diff" 报告),或者多次运行数据的合计。 对比、合并报告,很像针对单次运行的“平式视图”性能报告,就像“分层式视图”的性能报告。
Xdebug:
Xdebug是一个开放源代码的PHP程序调试器(即一个Debug工具),可以用来跟踪,
调试和分析PHP程序的运行状况。Xdebug的基本功能包括在错误条件下显示堆栈轨迹,最大嵌套级别和时间跟踪。
索引数组 [1, 2] 与关联数组 ['k1'=>1, 'k2'=>2] 有什么区别
暂时没有研究太深,按简单理解:
索引数组的默认key是从0开始的数字,可省略不写;而关联数组的key是字符串,必须主动指明,字符串内容可为数字也可为其他字符。
缓存的使用方式、场景(原文copy的)
为什么使用缓存
提升性能:使用缓存可以跳过数据库查询,分布式系统中可以跳过多次网络开销。在读多写少的场景下,可以有效的提高性能,降低数据库等系统的压力。
缓存的适用场景
1.数据不需要强一致性
2.读多写少,并且读取得数据重复性较高
缓存的正确打开方式
1.Cache Aside 同时更新缓存和数据库
2.Read/Write Through 先更新缓存,缓存负责同步更新数据库
3.Write Behind Caching 先更新缓存,缓存负责异步更新数据库
下面具体分析每种模式
一、Cache Aside 更新模式
这是最常用的缓存模式了,具体的流程是:
读取:应用程序先从 cache 取数据,取到后成功返回;没有得到,则从数据库中取数据,成功后,放到缓存中。
更新:先把数据存到数据库中,再清理缓存使其失效。
不过这种模式有几个变种:
第一,如果先更新数据库再更新缓存。假设两个并发更新操作,数据库先更新的反而后更新缓存,数据库后更新的反而先更新缓存。这样就会造成数据库和缓存中的数据不一致,应用程序中读取的都是脏数据。
第二,先删除缓存再更新数据库。假设一个更新操作先删除了缓存,一个读操作没有命中缓存,从数据库中取出数据并且更新回缓存,再然后更新操作完成数据库更新。这时数据库和缓存中的数据是不一致的,应用程序中读取的都是原来的数据。
第三,先更新数据库再删除缓存。假设一个读操作没有命中缓存,然后读取数据库的老数据。同时有一个并发更新操作,在读操作之后更新了数据库并清空了缓存。此时读操作将之前从数据库中读取出的老数据更新回了缓存。这时数据库和缓存中的数据也是不一致的。
但是一般情况下,缓存用于读多写少的场景,所以第三种这种情况其实是小概率会出现的。
二、Read/Write Through 更新模式
Read Through 模式就是在查询操作中更新缓存,缓存服务自己来加载。
Write Through 模式和 Read Through 相仿,不过是在更新数据时发生。当有数据更新的时候,如果没有命中缓存,直接更新数据库,然后返回。如果命中了缓存,则更新缓存,然后由缓存自己更新数据库(这是一个同步操作)。
三、Write Behind Caching 更新模式
Write Behind Caching 更新模式就是在更新数据的时候,只更新缓存,不更新数据库,而我们的缓存会异步地批量更新数据库。但其带来的问题是,数据不是强一致性的,而且可能会丢失。
总结,三种缓存模式的优缺点:
Cache Aside 更新模式实现起来比较简单,最常用,实时性也高,但是需要应用需要关注核实加载数据进入缓存 。
Read/Write Through 更新模式只需要维护一个缓存,对应用屏蔽掉了缓存的细节,实时性也高。但是实现起来要复杂一些。
Write Behind Caching 吞吐量很高,多次操作可以合并。但是数据可能会丢失,例如系统断电等,实现起来最复杂。
实践篇
给定二维数组,根据某个字段排序
举例:一组学生信息,要按年龄大小升序或降序排序(类似与sql语句的order by功能)
$arr = [
['id' => 6, 'name' => '小明'],
['id' => 1, 'name' => '小亮'],
['id' => 13, 'name' => '小红'],
['id' => 2, 'name' => '小强'],
];
// 方法1:手动写排序方法:
/** 对给定二维数组按照某个字段升序或降序排序
* @param $arr 给定一个二维数组,这里的$arr
* @param $sortField 根据哪个字段排序,这里的id
* @param string $sort 升序还是降序,默认升序
*思路:取出所有要排序的字段的值组成一个新数组,根据升序降序保留键值排序,此时新数组的键值顺序就是要得到的排序后的二维数组的键值顺序,然后将原二维数组按照此键值顺序排列即可。
注意:这里没有重置排序后的二维数组的索引,如需重置可自行扩展
*/
private function arraySort($arr, $sortField, $sort = 'asc') {
$newArr = array();
foreach ($arr as $key => $value) {
$newArr[$key] = $value[$sortField];
}
($sort == 'asc') ? asort($newArr) : arsort($newArr);
foreach ($newArr as $k => $v) {
$newArr[$k] = $arr[$k];
}
return $newArr;
}
// 方法2:使用php提供的排序函数array_multisort(),默认会重置排序后的索引,即从0开始顺序往下排
foreach ($arr as $key => $value) {
$id[$key] = $value['id'];
}
array_multisort($id, SORT_ASC, $arr); // 返回True or False
如何判断上传文件类型,如:仅允许 jpg 上传
网上出现频率较高的一段代码:lz认为此段代码对上传文件的类型限制还是比较好的,因为之前看资料说仅通过mime类型判断有时候不太靠谱,而仅通过文件后缀名判断好像也不是很靠谱,所以这里采用双重判断,以下代码稍微加了点注释:
<?php
$allowedExts = array("gif", "jpeg", "jpg", "png"); // 限定可上传的文件后缀名
$extension = end(explode(".", $_FILES["file"]["name"])); // 从文件名中获取文件后缀名
// 判断上传文件mime类型是下列之一且大小小于20000B且文件后缀名也符合要求
if ((($_FILES["file"]["type"] == "image/gif")|| ($_FILES["file"]["type"] == "image/jpeg")|| ($_FILES["file"]["type"] == "image/jpg")|| ($_FILES["file"]["type"] == "image/pjpeg")|| ($_FILES["file"]["type"] == "image/x-png")|| ($_FILES["file"]["type"] == "image/png"))&& ($_FILES["file"]["size"] < 20000)&& in_array($extension, $allowedExts))
{
if ($_FILES["file"]["error"] > 0)
{
echo "Return Code: " . $_FILES["file"]["error"] . "<br>";
}
else
{
echo "Upload: " . $_FILES["file"]["name"] . "<br>";
echo "Type: " . $_FILES["file"]["type"] . "<br>";
echo "Size: " . ($_FILES["file"]["size"] / 1024) . " kB<br>";
echo "Temp file: " . $_FILES["file"]["tmp_name"] . "<br>"; //临时文件名
if (file_exists("upload/" . $_FILES["file"]["name"]))
{ // 同名文件已存在时提示文件已存在
echo $_FILES["file"]["name"] . " already exists. ";
}
else
{
move_uploaded_file($_FILES["file"]["tmp_name"],
"upload/" . $_FILES["file"]["name"]);
echo "Stored in: " . "upload/" . $_FILES["file"]["name"];
}
}
}else
{ // 文件类型或大小不合适时提示无效文件
echo "Invalid file";
}?>
不使用临时变量交换两个变量的值 $a=1; $b=2; => $a=2; $b=1;
最先想到的利用加减运算这里就不说了,因为那只适用于数字类型。
1.字符串截取法:
function myExchange(&$a = '', &$b = '') {
$a = $a . $b;
$b = substr($a,0,-strlen($b));
$a = substr($a,strlen($a)-strlen($b),strlen($b));
return true;
}
2.数组法:
private function myExchange(&$a = '', &$b = '') {
$a = array($a, $b);
$b = $a[0];
$a = $a[1];
return true;
}
strtoupper 在转换中文时存在乱码,你如何解决?php echo strtoupper('ab你好c');
php echo strtoupper('ab你好c');(经测试中文系统下不会出现乱码,网上资料说是英文系统或部分盗版系统或因编码格式问题可能出现题述情况。
- mb系列函数解决(mb系列函数可以显式指明编码)
string mb_convert_case (string $str ,int $mode [,string $encoding = mb_internal_encoding()])
$mode有三种模式:
1.MB_CASE_UPPER:转成大写
2.MB_CASE_LOWER:转成小写
3.MB_CASE_TITLE :转成首字母大写
$encoding默认使用内部编码;也可以显示使用如’UTF-8’;
可以用echo mb_internal_encoding();来查看;
此方法不仅可以解决中文问题,对其他问题也适用。
2.手动解决:用str_split(string $string, int $split_length = 1)按每个字节切割,像中文能切割成三个字节。对识别到的字节若是英文字母则进行转换。
<?php
function mystrtoupper($a){
$b = str_split($a, 1);
$r = '';
foreach($b as $v){
$v = ord($v);//对该字符转成acsii码
if($v >= 97 && $v<= 122){//判断是否为小写字母
$v -= 32;//转换成大写字母
}
$r .= chr($v);//将ascii码再转为相应的字符。
}
return $r;
}
$a = 'a中你继续F@#$%^&*(BMDJFDoalsdkfjasl';echo 'origin string:'.$a."\n";echo 'result string:';$r = mystrtoupper($a);
var_dump($r);
Websocket、Long-Polling、Server-Sent Events(SSE) 区别
感觉简书的这篇文章介绍的还不错:原文链接,这里只copy要点:
Long-Polling(基于AJAX长轮询)
浏览器发出XMLHttpRequest 请求,服务器端接收到请求后,会阻塞请求直到有数据或者超时才返回,浏览器JS在处理请求返回信息(超时或有效数据)后再次发出请求,重新建立连接。在此期间服务器端可能已经有新的数据到达,服务器会选择把数据保存,直到重新建立连接,浏览器会把所有数据一次性取回。
Websocket
Websocket是一个全新的、独立的协议,基于TCP协议,与http协议兼容、却不会融入http协议,仅仅作为html5的一部分。于是乎脚本又被赋予了另一种能力:发起websocket请求。这种方式我们应该很熟悉,因为Ajax就是这么做的,所不同的是,Ajax发起的是http请求而已。与http协议不同的请求/响应模式不同,Websocket在建立连接之前有一个Handshake(Opening Handshake)过程,在关闭连接前也有一个Handshake(Closing Handshake)过程,建立连接之后,双方即可双向通信。
Server-Sent Events(SSE)
是一种允许服务端向客户端推送新数据的HTML5技术。与由客户端每隔几秒从服务端轮询拉取新数据相比,这是一种更优的解决方案。与WebSocket相比,它也能从服务端向客户端推送数据。那如何决定你是用SSE还是WebSocket呢?概括来说,WebSocket能做的,SSE也能做,反之亦然,但在完成某些任务方面,它们各有千秋。WebSocket是一种更为复杂的服务端实现技术,但它是真正的双向传输技术,既能从服务端向客户端推送数据,也能从客户端向服务端推送数据。
另外一篇网上盛传的帖子:原文链接
StackOverflow上一篇对websockets和sse的比较
Websockets和SSE(服务器发送事件)都能够将数据推送到浏览器,但它们不是竞争技术。
Websockets连接既可以将数据发送到浏览器,也可以从浏览器接收数据。可以使用websockets的应用程序的一个很好的例子是聊天应用程序。
SSE连接只能将数据推送到浏览器。在线股票报价或更新时间轴或订阅源的twitters是可以从SSE中受益的应用程序的良好示例。
实际上,由于SSE可以完成的所有工作也可以通过Websockets完成,因此Websockets得到了更多的关注和喜爱,并且更多的浏览器支持Websockets而不是SSE。
但是,对于某些类型的应用程序来说,它可能会过度,并且使用SSE等协议可以更容易地实现后端。
此外,SSE可以填充到本身不支持它的旧版浏览器中,只需使用JavaScript就可实现。可以在Modernizr github页面上找到SSE polyfill的一些实现。
"Headers already sent" 错误是什么意思,如何避免
错误说明:“不能更改头信息-头已经发出”;意思大概是在你的代码中有修改header信息的代码段,但是在此代码段之前header已经发出,所以报错不能修改。
如何避免:在发送header前不能有任何输出,会发送header的部分方法:
类似于输出功能的操作(不能放在header相关处理之前):
无意的:
<?php之前或?>之后的空格
UTF-8编码的BOM头信息
以前的错误消息或通知
故意的:
print,echo等产生输出的输出
Raw <html> sections prior <?php code.(抱歉没有看懂)
算法篇
快速排序(手写)
快速排序:每一次比较都把最大数放置最右侧(不是很准确,不会描述了)(默认从小到大排列,倒序则相反)
没有再去寻找更好的实现,直接贴上上学时用各种语言写过的嵌套for循环形式:
for ($i = 0; $i < count($sortArr) - 1; $i++) {
for ($j = count($sortArr) - 1; $j > $i; $j--) {
if ($sortArr[$i] > $sortArr[$j]) {
$temp = $sortArr[$i];
$sortArr[$i] = $sortArr[$j];
$sortArr[$j] = $temp;
}
}
}
快速排序有点记不清了,话说除了面试也不会写这种算法了,不过以上代码是测试可以的,但不保证没有bug
冒泡排序(手写)
冒泡排序:两两比较,前者大于后者则交换(默认从小到大排列,倒序则相反)
没有再去寻找更好的实现,直接贴上上学时用各种语言写过的嵌套for循环形式:
for ($i = 0; $i < count($sortArr) - 1; $i++) {
for ($j = $i + 1; $j < count($sortArr); $j++) {
if ($sortArr[$i] > $sortArr[$j]) {
$temp = $sortArr[$i];
$sortArr[$i] = $sortArr[$j];
$sortArr[$j] = $temp;
}
}
}
我最喜欢的排序算法,主要是写的熟练,这里只有核心实现,没有细节校验
二分查找(了解)
二分查找:每次查找都将查找范围缩小一半,直至找到目标数据。
二分查找递归实现(csdn找的):
function binSearch2($arr,$low,$height,$k){
if($low<=$height){
$mid=floor(($low+$height)/2);//获取中间数
if($arr[$mid]==$k){
return $mid;
}elseif($arr[$mid]<$k){
return binSearch2($arr,$mid+1,$height,$k);
}elseif($arr[$mid]>$k){
return binSearch2($arr,$low,$mid-1,$k);
}
}
return -1;
}
查找算法 KMP(了解)
copy的KMP简介
Knuth-Morris-Pratt 字符串查找算法,简称为 “KMP算法”,常用于在一个文本串S内查找一个模式串P 的出现位置,这个算法由Donald Knuth、Vaughan Pratt、James H. Morris三人于1977年联合发表,故取这3人的姓氏命名此算法。
下面先直接给出KMP的算法流程(如果感到一点点不适,没关系,坚持下,稍后会有具体步骤及解释,越往后看越会柳暗花明☺):
假设现在文本串S匹配到 i 位置,模式串P匹配到 j 位置
如果j = -1,或者当前字符匹配成功(即S[i] == P[j]),都令i++,j++,继续匹配下一个字符;
如果j != -1,且当前字符匹配失败(即S[i] != P[j]),则令 i 不变,j = next[j]。此举意味着失配时,模式串P相对于文本串S向右移动了j - next [j] 位。
换言之,当匹配失败时,模式串向右移动的位数为:失配字符所在位置 - 失配字符对应的next 值(next 数组的求解会在下文的3.3.3节中详细阐述),即移动的实际位数为:j - next[j],且此值大于等于1。
深度、广度优先搜索(了解)
在学校算法课上学过,但是还是没信心能把他描述清楚,这里要求也只是简单了解,还是引用大神的文章了
**深度优先遍历图算法步骤:
1.访问顶点v;
2.依次从v的未被访问的邻接点出发,对图进行深度优先遍历;直至图中和v有路径相通的顶点都被访问;
3.若此时图中尚有顶点未被访问,则从一个未被访问的顶点出发,重新进行深度优先遍历,直到图中所有顶点均被访问过为止。
广度优先遍历算法步骤:
1.首先将根节点放入队列中。
2.从队列中取出第一个节点,并检验它是否为目标。如果找到目标,则结束搜寻并回传结果。否则将它所有尚未检验过的直接子节点加入队列中。
3.若队列为空,表示整张图都检查过了——亦即图中没有欲搜寻的目标。结束搜寻并回传“找不到目标”。
4.重复步骤2。
LRU 缓存淘汰算法(了解,Memcached 采用该算法)
LRU (英文:Least Recently Used), 意为最近最少使用,这个算法的精髓在于如果一块数据最近被访问,那么它将来被访问的几率也很高,根据数据的历史访问来淘汰长时间未使用的数据。
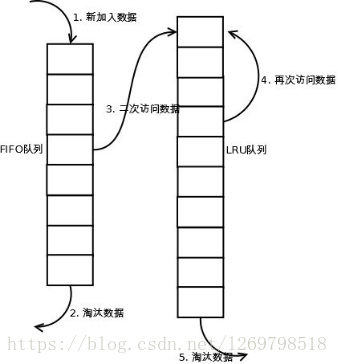
对图理解:
- 新数据插入到链表头部;
- 每当缓存命中(即缓存数据被访问),则将数据移到链表头部;
- 当链表满的时候,将链表尾部的数据丢弃。
数据结构篇(了解)
既然这一篇要求也为了解,那就直接放几句话的简单概述了。
堆、栈特性
1.栈就像装数据的桶或箱子
我们先从大家比较熟悉的栈说起吧,它是一种具有后进先出性质的数据结构,也就是说后存放的先取,先存放的后取。
这就如同我们要取出放在箱子里面底下的东西(放入的比较早的物体),我们首先要移开压在它上面的物体(放入的比较晚的物体)。
2.堆像一棵倒过来的树
而堆就不同了,堆是一种经过排序的树形数据结构,每个结点都有一个值。
通常我们所说的堆的数据结构,是指二叉堆。
堆的特点是根结点的值最小(或最大),且根结点的两个子树也是一个堆。
由于堆的这个特性,常用来实现优先队列,堆的存取是随意,这就如同我们在图书馆的书架上取书,虽然书的摆放是有顺序的,但是我们想取任意一本时不必像栈一样,先取出前面所有的书,书架这种机制不同于箱子,我们可以直接取出我们想要的书。
百度百科:
栈(操作系统):由操作系统自动分配释放 ,存放函数的参数值,局部变量的值等。其操作方式类似于数据结构中的栈。
堆(操作系统): 一般由程序员分配释放, 若程序员不释放,程序结束时可能由OS回收,分配方式倒是类似于链表。
栈使用的是一级缓存, 他们通常都是被调用时处于存储空间中,调用完毕立即释放。
堆则是存放在二级缓存中,生命周期由虚拟机的垃圾回收算法来决定(并不是一旦成为孤儿对象就能被回收)。所以调用这些对象的速度要相对来得低一些。
堆和栈的区别可以引用一位前辈的比喻来看出:
使用栈就象我们去饭馆里吃饭,只管点菜(发出申请)、付钱、和吃(使用),吃饱了就走,不必理会切菜、洗菜等准备工作和洗碗、刷锅等扫尾工作,他的好处是快捷,但是自由度小。
使用堆就象是自己动手做喜欢吃的菜肴,比较麻烦,但是比较符合自己的口味,而且自由度大。比喻很形象,说的很通俗易懂,不知道你是否有点收获。
队列
队列(queue)是一种采用先进先出(FIFO)策略的抽象数据结构,它的想法来自于生活中排队的策略。顾客在付款结账的时候,按照到来的先后顺序排队结账,先来的顾客先结账,后来的顾客后结账。队列的实现一般有数组实现和链表实现两种方式。
队列又分单链队列、循环队列、阵列队列,具体可参见维基
哈希表
Hash表也称散列表,也有直接译作哈希表,Hash表是一种特殊的数据结构,它同数组、链表以及二叉排序树等相比较有很明显的区别,它能够快速定位到想要查找的记录,而不是与表中存在的记录的关键字进行比较来进行查找。这个源于Hash表设计的特殊性,通过把关键码值(Key value)映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做Hash函数,存放记录的数组叫做Hash表。
链表
链表(Linked list)是一种常见的基础数据结构,是一种线性表,但是并不会按线性的顺序存储数据,而是在每一个节点里存到下一个节点的指针(Pointer)。由于不必须按顺序存储,链表在插入的时候可以达到O(1)的复杂度,比另一种线性表顺序表快得多,但是查找一个节点或者访问特定编号的节点则需要O(n)的时间,而顺序表相应的时间复杂度分别是O(logn)和O(1)。
使用链表结构可以克服数组链表需要预先知道数据大小的缺点,链表结构可以充分利用计算机内存空间,实现灵活的内存动态管理。但是链表失去了数组随机读取的优点,同时链表由于增加了结点的指针域,空间开销比较大。
对比篇
Cookie 与 Session 区别
GET 与 POST 区别
include 与 require 区别
include_once 与 require_once 区别
Memcached 与 Redis 区别
MySQL 各个存储引擎、及区别(一定会问 MyISAM 与 Innodb 区别)
HTTP 与 HTTPS 区别
Apache 与 Nginx 区别
define() 与 const 区别
traits 与 interfaces 区别 及 traits 解决了什么痛点?
Git 与 SVN 区别
数据库篇
MySQL
-
- CRUD
- JOIN、LEFT JOIN 、RIGHT JOIN、INNER JOIN
- UNION
- GROUP BY + COUNT + WHERE 组合案例
- 常用 MySQL 函数,如:now()、md5()、concat()、uuid()等
- 1:1、1:n、n:n 各自适用场景
- 了解触发器是什么,说个使用场景
- 数据库优化手段
- 索引、联合索引(命中条件)
- 分库分表(水平分表、垂直分表)
- 分区
- 会使用 explain 分析 SQL 性能问题,了解各参数含义
- 重点理解 type、rows、key
- Slow Log(有什么用,什么时候需要)
MSSQL(了解)
-
- 查询最新5条数据
NOSQL
-
- Redis、Memcached、MongoDB
- 对比、适用场景(可从以下维度进行对比)
- 持久化
- 支持多钟数据类型
- 可利用 CPU 多核心
- 内存淘汰机制
- 集群 Cluster
- 支持 SQL
- 性能对比
- 支持事务
- 应用场景
你之前为了解决什么问题使用的什么,为什么选它?
服务器篇
查看 CPU、内存、时间、系统版本等信息
find 、grep 查找文件
awk 处理文本
查看命令所在目录
自己编译过 PHP 吗?如何打开 readline 功能
如何查看 PHP 进程的内存、CPU 占用
如何给 PHP 增加一个扩展
修改 PHP Session 存储位置、修改 INI 配置参数
负载均衡有哪几种,挑一种你熟悉的说明其原理
数据库主从复制 M-S 是怎么同步的?是推还是拉?会不会不同步?怎么办
如何保障数据的可用性,即使被删库了也能恢复到分钟级别。你会怎么做。
数据库连接过多,超过最大值,如何优化架构。从哪些方便处理?
502 大概什么什么原因? 如何排查 504呢?
架构篇
偏运维(了解):
-
- 负载均衡(Nginx、HAProxy、DNS)
- 主从复制(MySQL、Redis)
- 数据冗余、备份(MySQL增量、全量 原理)
- 监控检查(分存活、服务可用两个维度)
- MySQL、Redis、Memcached Proxy 、Cluster 目的、原理
- 分片
- 高可用集群
- RAID
- 源代码编译、内存调优
缓存
-
- 工作中遇到哪里需要缓存,分别简述为什么
搜索解决方案
性能调优
各维度监控方案
日志收集集中处理方案
国际化
数据库设计
静态化方案
画出常见 PHP 应用架构图
框架篇
ThinkPHP(TP)、CodeIgniter(CI)、Zend(非 OOP 系列)
Yaf、Phalcon(C 扩展系)
Yii、Laravel、Symfony(纯 OOP 系列)
Swoole、Workerman (网络编程框架)
对比框架区别几个方向点
-
- 是否纯 OOP
- 类库加载方式(自己写 autoload 对比 composer 标准)
- 易用性方向(CI 基础框架,Laravel 这种就是高开发效率框架以及基础组件多少)
- 黑盒(相比 C 扩展系)
- 运行速度(如:Laravel 加载一大堆东西)
- 内存占用
设计模式
单例模式(重点)
工厂模式(重点)
观察者模式(重点)
依赖注入(重点)
装饰器模式
代理模式
组合模式
安全篇
SQL 注入
XSS 与 CSRF
输入过滤
Cookie 安全
禁用 mysql_ 系函数
数据库存储用户密码时,应该是怎么做才安全
验证码 Session 问题
安全的 Session ID (让即使拦截后,也无法模拟使用)
目录权限安全
包含本地与远程文件
文件上传 PHP 脚本
eval 函数执行脚本
disable_functions 关闭高危函数
FPM 独立用户与组,给每个目录特定权限
了解 Hash 与 Encrypt 区别
高阶篇
PHP 数组底层实现 (HashTable + Linked list)
Copy on write 原理,何时 GC
PHP 进程模型,进程通讯方式,进程线程区别
yield 核心原理是什么
PDO prepare 原理
PHP 7 与 PHP 5 有什么区别
Swoole 适用场景,协程实现方式
前端篇
原生获取 DOM 节点,属性
盒子模型
CSS 文件、style 标签、行内 style 属性优先级
HTML 与 JS 运行顺序(页面 JS 从上到下)
JS 数组操作
类型判断
this 作用域
.map() 与 this 具体使用场景分析
Cookie 读写
JQuery 操作
Ajax 请求(同步、异步区别)随机数禁止缓存
Bootstrap 有什么好处
跨域请求 N 种解决方案
新技术(了解)
-
- ES6
- 模块化
- 打包
- 构建工具
- vue、react、webpack、
- 前端 mvc
优化
-
- 浏览器单域名并发数限制
- 静态资源缓存 304 (If-Modified-Since 以及 Etag 原理)
- 多个小图标合并使用 position 定位技术 减少请求
- 静态资源合为单次请求 并压缩
- CDN
- 静态资源延迟加载技术、预加载技术
- keep-alive
- CSS 在头部,JS 在尾部的优化(原理)
网络篇
IP 地址转 INT
192.168.0.1/16 是什么意思
DNS 主要作用是什么?
IPv4 与 v6 区别
网络编程篇
TCP 三次握手流程
TCP、UDP 区别,分别适用场景
有什么办法能保证 UDP 高可用性(了解)
TCP 粘包如何解决?
为什么需要心跳?
什么是长连接?
HTTPS 是怎么保证安全的?
流与数据报的区别
进程间通信几种方式,最快的是哪种?
fork() 会发生什么?
API 篇
RESTful 是什么
如何在不支持 DELETE 请求的浏览器上兼容 DELETE 请求
常见 API 的 APP_ID APP_SECRET 主要作用是什么?阐述下流程
API 请求如何保证数据不被篡改?
JSON 和 JSONP 的区别
数据加密和验签的区别
RSA 是什么
API 版本兼容怎么处理
限流(木桶、令牌桶)
OAuth 2 主要用在哪些场景下
JWT
PHP 中 json_encode(['key'=>123]); 与 return json_encode([]); 区别,会产生什么问题?如何解决
加分项
了解常用语言特性,及不同场景适用性。
-
- PHP VS Golang
- PHP VS Python
- PHP VS JAVA
了解 PHP 扩展开发
熟练掌握 C