摘要: PyODPS是MaxCompute的Python版本的SDK,SDK的意思非常广泛,辅助开发某一类软件的相关文档、范例和工具的集合都可以叫做“SDK”。 PyODPS在这里的作用是提供了对MaxCompute对象的基本操作和DataFrame框架,可以轻松地在MaxCompute上进行数据分析。
近日,阿里云发布PyODPS 0.7.18,主要是针对聚合函数进行优化同时新增对Python 3.7支持。
PyODPS是MaxCompute的Python版本的SDK,SDK的意思非常广泛,辅助开发某一类软件的相关文档、范例和工具的集合都可以叫做“SDK”。 PyODPS在这里的作用是提供了对MaxCompute对象的基本操作和DataFrame框架,可以轻松地在MaxCompute上进行数据分析。
PyODPS对于MaxCompute来说有多重要?
首先MaxCompute是一种快速、完全托管的GB/TB/PB级数据仓库解决方案。MaxCompute可以为用户提供完善的数据导入方案以及多种经典的分布式计算模型,更快速的解决海量数据计算问题,有效降低企业成本,并保障数据安全。
在MaxCompute上,大家有很多种分析和机器学习的方式。大家可以用在数加的web界面编写SQL,提交SQL作业;可以用console直接执行SQL,等等等。那机器学习呢,大家需要通过PAI命令提交PAI任务,或者在xlab上操作xlib;画图呢?导出数据绘图或者使用xlab。而这一切工具,都是割裂的,你不得不在各个地方进行切换,而且,也没有传统的数据分析和机器学习的快感。
那传统的任务是怎么做的呢,使用RStudio或者jupyter notebook,但对于Pythoner,用pandas进行数据分析、绘图,再用scikit-learn执行机器学习算法,在一个notebook里,能做所有想做的事情,非常高效。
现在呢,整合这一切的就是PyODPS,包含有基础MaxCompute SDK,因此一切对MaxCompute模型都可以操作。除此之外,还包括了DataFrame框架,和机器学习模块,这一切操作都进行了整合。
PyODPS具体实操
安装
PyODPS支持Python2.6以上(包括Python3),系统安装pip后,只需运行pip install pyodps,PyODPS的相关依赖便会自动安装。
快速开始
首先,用阿里云账号初始化一个MaxCompute的入口,如下所示:
根据上述操作初始化后,便可对表、资源、函数等进行操作。
项目空间
项目空间是MaxCompute的基本组织单元,类似于Database的概念。
您可通过 get_project获取到某个项目空间,如下所示:
表操作
通过调用 list_tables可以列出项目空间下的所有表,如下所示:
通过调用 exist_table可以判断表是否存在,通过调用 get_table可以获取表。
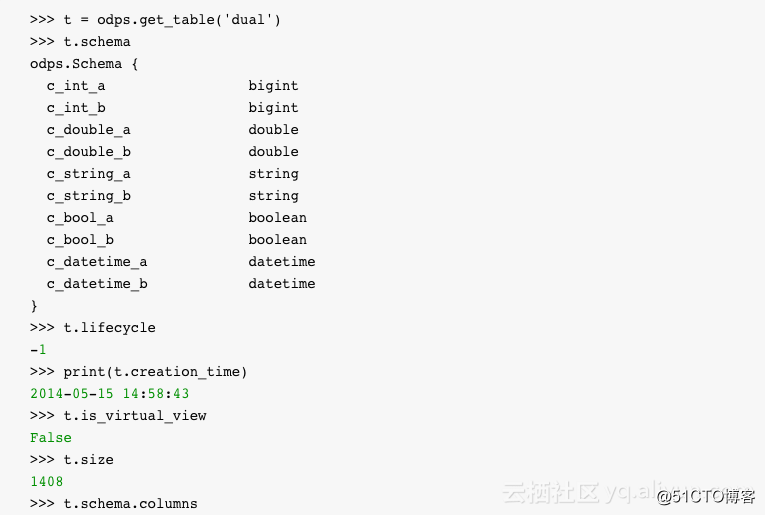
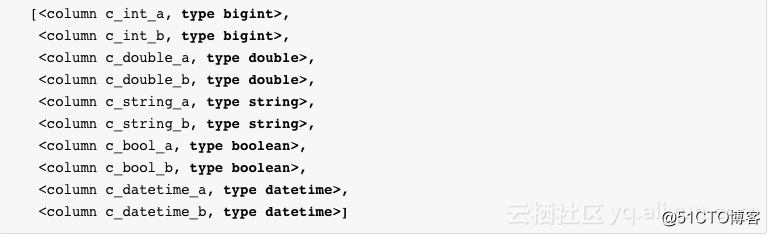
创建表的Schema
初始化的方法有两种,如下所示:
通过表的列和可选的分区来初始化。
通过调用Schema.from_lists,虽然调用更加方便,但显然无法直接设置列和分区的注释。
创建表
您可以使用表的Schema来创建表,操作如下所示:

也可以使用逗号连接的 字段名 字段类型字符串组合来创建表,操作如下所示:
在未经设置的情况下,创建表时,只允许使用bigint、double、decimal、string、datetime、boolean、map和array类型。
如果您的服务位于公共云,或者支持tinyint、struct等新类型,可以设置 options.sql.use_odps2_extension = True,以打开这些类型的支持,示例如下:
获取表数据
您可通过以下两种方法获取表数据。
通过调用head获取表数据,但仅限于查看每张表开始的小于1万条的数据,如下所示:
通过在table上执行open_reader操作,打开一个reader来读取数据。您可以使用with表达式,也可以不使用。
通过使用Tunnel API读取表数据,open_reader操作其实也是对Tunnel API的封装。
写入数据
类似于 open_reader,table对象同样可以执行 open_writer来打开writer,并写数据。如下所示:
同样,向表中写入数据也是对Tunnel API的封装,更多详情请参见数据上传下载通道。
删除表
删除表的操作,如下所示:

了解更多关于PyODPS 0.7.18详情请戳:https://help.aliyun.com/document_detail/34615.html?spm=a2c4g.11186623.6.694.175c517cSWoptV
本文为云栖社区原创内容,未经允许不得转载。