| 什么是索引? |
排好序的快速查找数据结构
| 目的: |
提高查找效率
在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结枘以某种方式引用(指向)数据,
这样就可以在这些数据结构上实现高级查找算法。这种数据结构,就是索引。下图就是一种可能的索引方式示例:
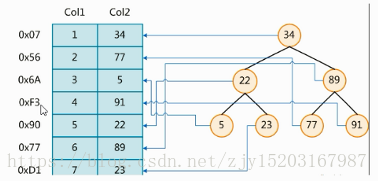
左边是数据表,一共有两列七条记录,最左边的是数据记录的物理地址
为了加快Col2的查找,可以维护一个右边所示的二叉查找树,每个节点分别包含索引键值和一个指向对应数据记录物理地址的指针,这样就可以运用二叉查找在一定的复杂度内获取到相应数据,从而快速的检索出符合条件的记录。
| 索引分类: |
单值索引:即一个索引只包含单个列,一个表可以有多个单列索引
唯一索引:索引列的值必须唯一,但允许有空值
复合索引:即一个索引包含多个列
| 索引结构和检索原理: |
MySQL的索引结构:BTree索引,Hash索引,full-text全文索引,R-Tree索引
| 初始化介绍: |
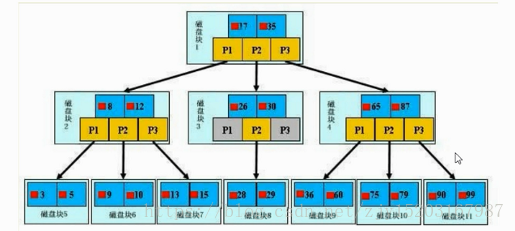
一颗b+树,浅蓝色的块我们称之为一个磁盘块,可以看到每个磁盘块包含几个数据项(深蓝色所示)和指针(黄色所示〕
如盘块1包含数据项17和35。包含指针P1、P2、P3,
P1表示小于17的磁盘块,P2表示在17和35之间的磁盘块,P3表示大于35的磁盘块。
真实的数据存在叶子节点即3、5、9、10、13、15、28、29、36、60、75、79、90、99.
非叶子节点不存真实的数据,只存指引搜素万向的数据项,如17、35并不真实存在于数据表中。
【查找过程】
如果要查找数据项29,那么首先会把磁盘块1由磁盘加载到内存,此时发生一次℃,在内存中用二分查找确定29在17和35之间,锁定磁盘块1的P2指针,内存时间因为非常短(相比磁盘的IO)可以忽略不计,通过过盘块1的P2指针的过盘地址把过盘块3由盘加载到内存,发生第二次IO,29在26和30之间,锁定磁盘块3的P2指针,通过指针加载磁盘块8到内存,发生第三次IO,同时内存中做二分查找找到29。结束查询,总计三次IO:
真实的情况是,3层的b+树可以表示上百万的数据,如果上百万的数据查找只需要三次IO,性能提高将是巨大的,如果没有索引,每个数据项都要发生一IO,那么总共要百万次IO,显然成本非常高。
| 什么情况下建索引? |
1.主键自动建立唯一索引
2.频繁作为杳询条件的字段应该创建索引
3.查询中与其它表关联的字段,外键关系建立索引
4.频繁更新的字段不适合创建索引,因为每次更新不单单是更新了记录还会更新索弓
5.Where条件里用不到的字段不创建索引
6.单键/组合索引的选择问題(在高并发下倾向创建组合索引)
7.查询中排序的字段,排序字段若通过索引去访问将大大提高排序速度
8.查询中统计或者分组字段
| 不适合建索引: |
1.表记录太少
2.经常增改的表,提高了查询速度,同时却会降低更新的速度,如对表进行INSERT、UPDATE和DELETE。因为更新表时,MySQL不仅要保存数据,还要保存一下索引文件
3.数据重复且分布平均的表字段,因此应该只为最经常查询和最经常排扉的数据列建立索引。注意,如果某个数据列包含许多重复的内容,为它建立索引没有太大的实际效果。(比如性别:男,女)
假如一个表有10万行记录,有一个字段A只有T和F两种值,且每个值的分步概率大约为50%,那么对这种表A字段建索引一般不会提高数据库的查询速度。
索引的选择性是指索引列中不同值的数目与表中记录数的比。如果一个表中有2000条记录,表索引列有1980个不同的值,那么这个索引的选择性就是1980/2000=0.99一个索引的选择性越接近于1,这个索引的效率就越高