本篇文章主要介绍如何让电脑预测年龄性别,具体实现代码与运行步骤请参考Github.
github上有详细的运行步骤,这里我介绍一下模型训练过程。
1、 数据提取
有很多与年龄性别相关的公开数据集,这里先根据原实验采用IMBD-wiki数据集,数据集来自IMDB-WIKI — 50多万张标注了年龄和性别的人脸图像集 。 在把图像数据输入模型之前,我们进行与前述预处理相同的步骤,即检测人脸区域并添加边距。
import os
list = os.listdir(Agepath)
for i in range(0, len(list)):
imgName = os.path.basename(list[i])
if os.path.splitext(imgName)[1] != ".jpg":
continue
if i % 50==0:
print(imgName)
for j in range(0, len(imgName)):
if imgName[j] == "_":
age1 = imgName[j+1:j+5]
for n in range(j+1, len(imgName)):
if imgName[n] == "_":
age2 = imgName[n+1:n+5]
age = int(age2) - int(age1)这里的Agepath就是我们的数据集图片对应的地址,首先我们通过遍历找到第一个” _ “的位置,然后将后四位字符存储到age1数组里(此时数组的形式默认为字符串类型), 然后我们在之后通过便利剩余字符找到第二个” _ “的位置,然后将后四位字符存储到age2数组里。此时两个数组的格式都是字符串类型,但是里面存储的是数字, 所以我们简单的通过将数组转换为int型就可以转换为数字数组了。我们知道拍摄年份一定大于出生年份,所以我们就放心大胆的减就可以得到这张照片对应人物的年龄了。
得到这张照片的年龄后我们只需要将这张照片通过shutil模块移动到我们需要的位置就好了,当然了这个你可以根据你自己的需要移动,比如说我就想找35岁的人物, 你只需要加个判断语句就OK了,上述处理后你就可以得到你想要的年龄段分好的图片了,由于只是处理字符串,整个过程非常的快,普通的电脑估计1分钟可以处理不下于一万张左右的图片。
我们筛选出154666张作为训练集,17186张作为验证集,wiki作为测试集,图片统一缩放到64*64大小。
2、网络模型
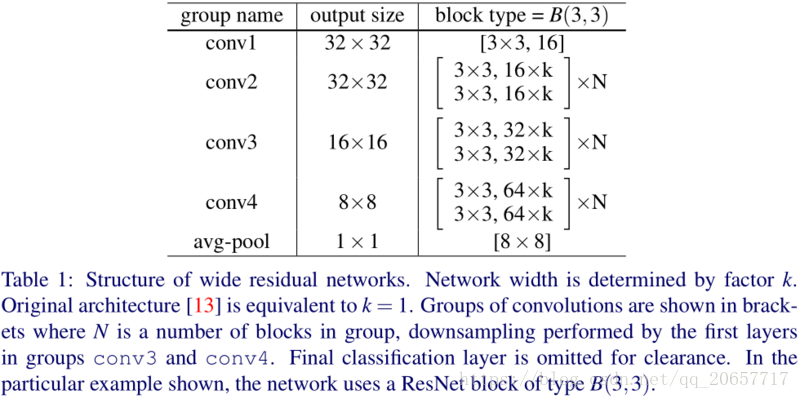
网络不断向更深发展,但是有时候为了得到少量的accuracy的增加,却需要将网络层数翻倍,也会减少feature的reuse,降低训练速度。作者提出了wide residual network,16层的表现就比之前的ResNet效果要好。ResNets因为过深,梯度反向传播时,并不能保证能够流经每一个残差模块(residual block)的weights,以至于它很难学到东西,因此在整个训练过程中,只有很少的几个残差模块能够学到有用的表达,而绝大多数的残差模块起到的作用并不大。因此作者希望使用一种较浅的,但是宽度更宽的模型,来更加有效的提升模型的性能。作者的16层网络能与1000层的resnet类似,所以作者认为ResNet的主要的能力来自于Residual block ,深度的增加只是辅助而已。 作者提出增加residual block的三种简单途径:
1. 更多卷基层
2. 加宽(more feature planes)
3. 增加卷基层的filter sizes
作者的思路比较简单粗暴,第一组的conv不增加宽度,在后面的conv中将feature map扩宽(k倍卷积核)
,小的filters更高效,所以不准备使用超过3x3的卷积核,提出了宽度放大倍数k和卷积层数l,参数随着长度的增加成线性增长,但是随着width却是平方增大,虽然参数会增多,但是卷积运算更适合gpu。
参数的增多需要regularization来减少过拟合,He使用了batch normalization,可是这种方法需要heavy augmentation,作者使用了dropout。
网络共有16个conv2d层,13个激活函数,每一层都进行了批规范化操作,最后由一个平均池化层,一个flatten层输入到分类层,性别是2分类,年龄是101分类(0~100)。训练集参数24463856,可训练参数24456656,不可训参数7200。
总结:
1. 宽度的增加提高了性能
2. 增加深度和宽度都有好处,直到参数太大,regularization不够
3. 相同参数时,宽度比深度好训练
4. 对于参数较少的16-4得到的结果反而差了。
3、网络训练
作者给了两种训练方式,一种是数据顺序输方式,每次输入32张图片,一个周期训练154666张,训练30个周期,另一种是标准数据混合并随机选用数据,一次输入一张,一周期训练4833张,训练30个周期,后者方法可以降低误差,减少过拟合。
本人训练了半天,最终的loss:2.6721,pred_gerder_loss:0.1625,pred_age_loss:1.9285,pred_gender_acc:0.9207,pred_age_acc:0.4425,val_loss:6.1582,val_pred_gender_loss:0.3546,val_pred_age_loss:5.1934,val_pred_gender_acc: 0.8706 - val_pred_age_acc: 0.0619
因为训练时间会很久,所以我只训练了16x4(16层,宽度为4)的架构,使用GTX1060训练。
4、评估模型
实验所得结果与作者相近(毕竟啥也没改),选用数据增大方法将验证误差降低了0.25左右,精度不是特别高。
进一步深入研究
如果你对演示效果不满意,并希望更多的了解如何建立和训练模型,作者提出了一下三方面改进方法。
1.采用更大尺寸的训练图像
2.采用更好的初始模型
3.采用更有效的数据集