写在前面的话:爬虫有风险,使用需谨慎(应当遵守行业道德及职业操守,遵守国家法律法规。以下内容均是在此前提下进行操作)
反爬技术基本有:
模拟登陆,模拟浏览器,代理服务器......文章在持续更新总结梳理中......
1.代理服务器的设置
目的:防止自有IP地址被屏蔽
推荐免费的代理服务器列表:
http://www.xicidaili.com/
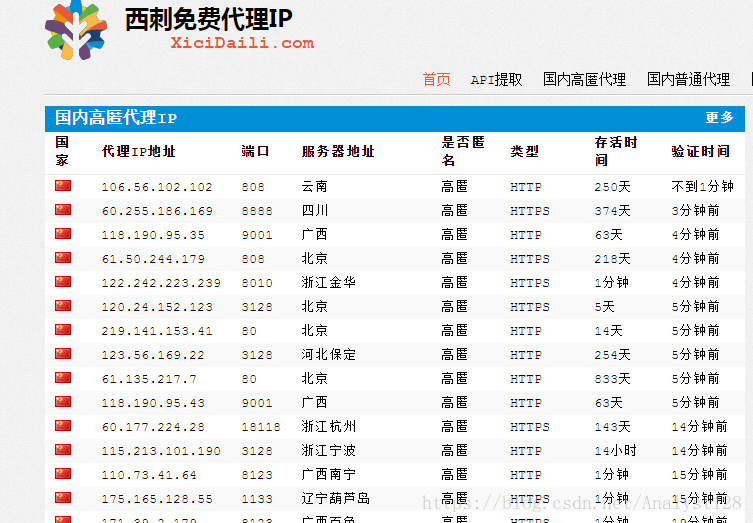
建立自定义函数,利用代理服务器爬取网页内容
#代理服务器设置
import urllib.request
def use_proxy(url,proxy_addr): #定义一个具有代理服务器功能的函数
proxy=urllib.request.ProxyHandler({"http":proxy_addr})
opener=urllib.request.build_opener(proxy,urllib.request.HTTPHandler) #添加代理IP
urllib.request.install_opener(opener) #安装opener为全局变量
data=urllib.request.urlopen(url).read().decode("utf-8","ignore")
#用"ignore"忽略编码错误问题
return data
proxy_addr="106.56.102.102:808" #有部分代理服务器可能没有效果,此时应该更换
url="http://xxxxx.com"
data=use_proxy(url,proxy_addr) #调用use_proxy()函数,传入实参proxy_addr and url
print(len(data)) #返回获取内容的大小2. 模拟登陆问题(自动模拟HTTP请求)
http请求有多种类型,常用get(get请求通过URL网址传递信息)和post
查询时常用到get请求.
比如:
下面是模拟get请求思路:
1.构建对应的URL地址
2.以对应的URL为参数,构建Request对象
3.通过urlopen()打开构建的Request对象
4.后续操作
具体代码实现如下:
import urllib.request
keyword="90后"
keyword=urllib.request.quote(keyword) #需要对中文关键字进行编码处理
url="http://www.baidu.com/?wd="+keyword
#https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=0&rsv_idx=1&tn=02049043_8_pg&wd=python&rsv_pq=bfc660810002b9aa&rsv_t=7649UHhrgN4vYkpzTfzJxRWBTXhIXWYnuS3WPgvk4CZWpTAVC0UQYI9ATIQNTK3j2e%2Bsyg&rqlang=cn&rsv_enter=1&rsv_sug3=7&rsv_sug1=7&rsv_sug7=101&rsv_sug2=0&inputT=3503&rsv_sug4=4273
req=urllib.request.Request(url) #网址以请求方式获取(封装为一个请求)
data=urllib.request.urlopen(req).read()
fh=open("D:\xxx.txt",'wb') #以二进制写入的方式打开
fh.write(data)
fh.close()在注册或者登陆时常用到post请求:
(登陆需要的cookie知识点在此省略)
post请求思路如下:
1.构建好URL网址
2.构建表单数据(urllib.parse.urlencode对数据编码)
3.创建Request对象(参数应包含URL地址和传递的数据)
4.用add_header()添加头信息,模拟浏览器进行爬取
5.使用urllib.request.urlopen()打开对应的Request对象,完成信息的传递
6.后续操作
具体代码实现如下:
import urllib.request
import urllib.parse
url="网址" #备注:网址应是http形式,因为urllib不支持HTTPS协议
postdata=urllib.parse.urlencode({
"name":"qingfengxiyu.com",
"pass":"密码lalala"
}).encode("utf-8") #对数据进行编码处理
req=urllib.request.Request(url,postdata)
req.add_header('User-Agent','Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36 SE 2.X MetaSr 1.0')
data=urllib.request.urlopen(req).read()
fh=open("D:/..../90hou.html","wb") #以二进制方式创建并打开文件
fh.write(data)
fh.close() #有开必有关,否则编译会出错
为了增强代码的健壮性,可有时也可进行超时设置(可根据网页的服务器反应速度来设置),尤其适合大型项目时,设置好恰当的时间可以提高效率
用timeout来表示
file=urllib.request.urlopen("网址",timeout=10)
#设置10秒反应时间,超时则报错
案例:
for i in range(0,100):
try:
file=urllib.request.urlopen("网址",timeout=10)
data=file.read()
print(len(data))
except Exception as e:
print("出现异常:"+str(e)) #输出异常的内容
异常处理增强了程序的健壮性
爬虫的异常处理:
未来防止程序遇到异常时,停止或者崩溃,一般用异常处理来增强程序的健壮性
常见状态码:
200:运行正常 301: 重新定向到新的URL 403: 禁止访问
异常处理的两种方式:urlError与HTTPError(其中后者是前者的子类)由于HTTPError有异常状态码与异常原因,urlerror没有异常状态码,所以不能用urlerror直接代替httperror,如要代替,必须判断是否有状态码属性.
urlerror产生原因:
1.连接不上
2.远程的URL不存在
3.本地没有网络
4.假若触发了httperror子类
import urllib.error
import urllib.request
try:
urllib.request.urlopen("http://blog.csdn.net")
except urllib.error.URLError as e:
if hasattr(e,"code"):
print(e.code)
if hasattr(e,"reason"):
print(e.reason)
#判断是否有状态码产生 浏览器伪装技术:
防屏蔽,把爬虫爬取页面内容,伪装成是以浏览器的方式进行
简单伪装技术(user-Agent)
#简单伪装技术
import urllib.request
url="......"
headers=("user-Agent","......")
opener=urllib.request.build_opener() #创建opener对象,urlopen默认不支持高级报头,所以做此设置opener.addheader=[headers] #添加报头信息
data=opener.open(url).read()
fh=("D:......","wb") #以二进制形式写入文件
fh.write(data)
fh.close()
高仿真伪装技术(文章更新总结梳理中):