算法思想
先举一个可能不是很恰当的例子:“近朱者赤近墨者黑”,想象一下,假如你是一个女孩纸,新认识一个男性朋友,如果你了解到他周围的朋友大部分是性格开朗,阳关帅气的,你潜意识会觉得这个大概也是这样的人,那如果他周围大部分是那些“臭名昭著”,名声不是很好的朋友,你潜意识的会觉得,emmmmm这个人可能不是很靠谱,有待考量……这么说来你的潜意识就是一个典型的KNN分类器。(hhhh,扯得有点远,朋友用心交,情谊比天高,祝各位开心!)
让我们回归正题,KNN(k-NearestNeighbor)也可以叫做k-近邻,首先它属于有监督学习,将预测集的每个特征与样本集对应的特征进行比较,然后算法提取“若干个”样本集中特征最相似数据(最近邻)的分类标签,其中出现次数最多的标签即作为最终预测的结果。上述描述中的“若干个”就是我们knn中的“k”要定义的事情,至于如何取值我会在后续的博客中说明,现在我们只需要知道k是我们根据经验取得的正整数值,一般不大于20。那如何对对应的特征进行比较呢?这就是我们knn中“Neighbor”要做的事了,这里用的是一种距离公式——欧氏距离
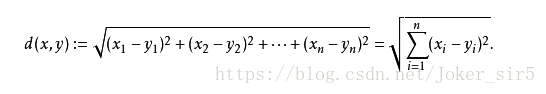
当然还可以推广到闵可夫斯基距离(了解即可,本文用的欧式距离)
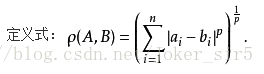
我们可以看到闵可夫斯基距离公式中,当p=2时,即为欧氏距离;当p=1时,即为曼哈顿距离;当p趋于无穷时,即为切比雪夫距离。
算法优缺点
优点: 精度高,对异常值不敏感,无数据输入假定
缺点: 计算复杂度高、空间复杂度高
适用数据范围: 数值型
算法步骤
KNN(k-NearestNeighbor):
1.计算已知类别数据集中的点与带预测点之间的距离(欧氏距离)(Neighbor)
2.按照距离递增次序排序
3.选取当前距离最小的k个点(k)
4.确定前k个点所在类别的出现频率
5.返回前k个点出现频率最高的类别作为当前待预测点的分类(Nearest)
关键代码
在了解KNN的基本思想和步骤之后,我们话不多说,直接撸代码!
def knn_Classifier(X_in, X_train, y_train, k):
# 使用欧氏距离公式求距离
distances = [(np.sum((x_train - X_in)**2))**0.5
for x_train in X_train]
#取最近的k个距离,argsort函数拿到前k个值的下标,对应到y_train中,将对应的标签存到topK_y中
nearest = np.argsort(distances)
topK_y = [y_train[neighbor] for neighbor in nearest[:k]]
# 选出前k个标签中票数最多的一个标签作为最终的预测值
votes = Counter(topK_y)
predict_y = votes.most_common(1)[0][0]
return predict_yX_in:待预测的数据集;X_train:训练数据集;y_train:训练数据对应的标签;k:根据经验取一个正整数
随后我们取一些数据来测试一下我们写的knn分类器:
Data:[ [3.393533211, 2.331273381], [3.110073483, 1.781539638],[1.343808831, 3.368360954],[3.582294042,4.679179110],[2.280362439, 2.866990263],[7.423436942, 4.696522875],[5.745051997, 3.533989803],[9.172168622, 2.511101045],[7.792783481, 3.424088941],[7.939820817, 0.791637231] ]
label:[0, 0, 0, 0, 0, 1, 1, 1, 1, 1]
predict:[8.093607318, 3.365731514]
我们先来分析下数据,这样光看这些数字好像并没有什么概念,不妨试试将上述数据绘制成散点图:
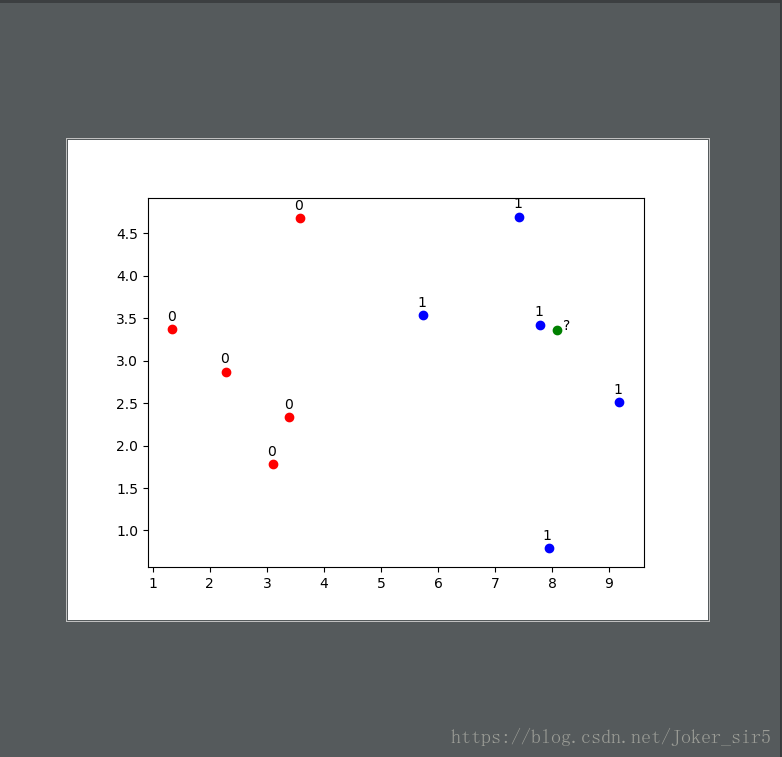
这样子一看就清晰了很多,直观上好像我们的待预测点(绿点)离标签为1(蓝点)的数据更近些,那我们就可以猜测该点的标签大概率也是‘1’。接下来调用一下我们之前写好KNN分类器来验证一下:
predict_y = KNN.knn_Classifier(x, X_train, y_train, 6)
print(predict_y)最终的预测结果为‘1’:

总结
1.实验数据:为了方便最初理解KNN,并简单实现数据可视化,所以上述DATA格式非常简单,只有两个特征,在实际应用场景中DATA维度可能非常庞大,具有很多个特征;待预测的数据量也可能非常庞大,当然同时也会增加KNN的计算量,这也是KNN的一个不可避免的缺点。
2.参数设置:开篇提到k是由经验取得的一个正整数,那么问题来了,我就是一个机器学习小白,没有什么经验,你让我设置k的值,我一脸懵*,到底该如何设置k的值?然后再试想一下,会不会有这样的情况:

按照KNN来说,当k=3时,绿点应该判定为蓝点的类,但是我们从可视化的数据中能看到绿点离红点更近些,理应判定为红点的类,这个时候距离的权重该如何取舍呢 ?
3.实验结果:我们写的KNN分类将待预测的数据类别预测出来了,但如何知道预测的结果是否可信呢,这就涉及到在训练数据时要有个较高的准确率,这样才能使得我们预测的结果可信度高!
综上,这些就是我下篇博客要解决的问题,请参照:KNN优化之参数设置