在开始今天内容的学习之前我们先来了解一下背景知识。
mongodb的数据是存储在服务启动时指定的--dbpath目录下,备份数据只需要拷贝该目录即可。
学过mysql、sql server数据库的同学对于数据库数据的冷热备份一定不陌生,其中mysql数据库提供了mysqldump的备份命令来进行数据的热备份。那MongoDB是不是也原生的提供了一些命令来支持我们的备份操作呢?
答案是肯定的,MongoDB中也有mongodump/mongorestore的备份还原命令。
这里我们主要来说明一下数据库数据的热备份,毕竟生产环境中把服务关闭进行数据冷备份的方式实在不太理想。
mongodump是一种在服务运行时备份数据的客户端,这个客户端也是mongodb原生自带的。
mongodump的工作原理是对运行的mongodb做查询,然后将所有查询到的文档写入磁盘。mongodump热备份有以下两个缺点。
缺点:
(1)作为普通的查询机制,所产生的备份不一定是服务器数据的实时快照,而且数据可能有损坏
(2)mongodb备份数据时需要查询,会对其他客户端的性能产生不利影响
如果我们想在复制数据时不损坏数据,而且是获取数据的实时快照呢?
答案是你可以使用fsync命令。fsync命令会强制服务器将所有缓冲区写入磁盘。fsync命令常和写入锁一起使用:数据复制期间通过加锁阻止对数据库的进一步写入,直到释放写入锁。
OK,这种方式较最开始是的直接mongodump已经改进了很多,但还是有一个问题:数据备份期间会造成写入操作被阻塞。那有没有更好的方式呢?答案是肯定的,这也就是我们今天学习的主题:主从复制,利用从节点备份数据
MongoDB的主从复制是将数据同步到多个服务器的过程。复制提供了数据的冗余备份,在多个服务器上存储数据副本,提高了数据的可用性, 保证数据的安全性以及MongoDB服务的高可用性。
实际的生产环境中为了保证服务的高可用性以及数据的安全性,我们需要进行主从复制,OK,今天我们就来学习一下。
常见的主从复制架构是一主多从,如下图所示:
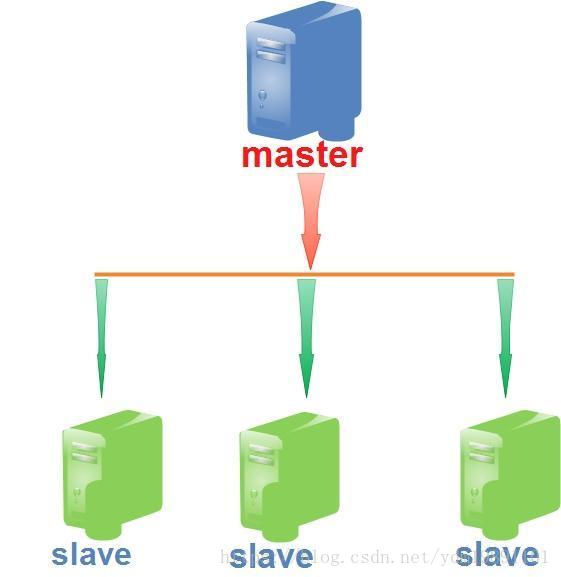
主节点:处理客户端的请求,包括写操作和读操作
从节点:作为故障恢复机制,防止主节点数据丢失或机器囧机;同时可以作为备份的数据源、扩展数据读取性能(通过slaveOkay选项开启从节点的请求处理能力)。
在深入学习主从复制之前我们需要认识一下master节点的oplog。
(1)master结点的操作记录称为oplog,oplog存储在local数据库的oplog.$main固定集合中,oplog.$main中的每个文档就代表master节点上执行的一个操作。既然是固定集合,就需要在服务启动时指定固定集合的大小,具体就是通过oplogSize参数来指定的,空间是在服务启动时进行预分配的。oplog中的每个文档就代表主节点上执行的一个操作。文档包含的键如下。
{ "ts" : Timestamp(1533130932, 1), "op" : "n", "ns" : "", "o" : { } }- ts
操作的时间戳
- op
操作的类型 如i标识插入操作
- ns
执行操作的集合名
- o
操作的具体对象,在这里就是指的文档
(2)oplog只记录更新操作而不记录查询操作。
(3)oplog一定要配置的足够大,当然也不是无限大,5%的剩余磁盘空间占比就差不多可以了,这样做是为了防止从库跟不上主库的更新速度,具体内容文章结尾会进行展开描述。
(4)如果运行过程中发现oplog的大小不够用,则需要停掉mongo服务,重新指定oplogSize的大小,启动服务,同时还有自动同步从节点数据。
其实,主从复制就是通过oplog来实现的:从节点定期轮询主节点来获取这些操作,然后对自己的数据副本执行这些操作。由于和主节点执行了相同的操作,从节点就能保持和主节点的数据同步。这里有个问题:从节点是根据什么来决定执行主节点上的oplog的,也即是从节点如何决定执行某些oplog而不执行另外的oplog的呢?OK,这个问题我们也留在最后解答。
note:一个从节点可能有多个主节点
为了便于演示,我在一台机器上部署主从mongodb服务。我这边为master、slave指定了不同的监听端口、数据存储路径。具体原因下面会详述。
maste:27017 /data/db/
slave1:27018 /data/db/slave1
slave2:27019 /data/db/slave2/1、配置主服务
./mongod --dbpath /data/db --port 27107 --logpath /data/db/masterlog.log --master2、配置从服务
./mongod --dbpath /data/db/slave1 --port 27018 --logpath /data/db/slave1/slavelog.log --slave --source 127.0.0.1:27017./mongod --dbpath /data/db/slave2 --port 27018 --logpath /data/db/slave2/slavelog.log --slave --source 127.0.0.1:27017./mongod --dbpath /data/db/slave3 --port 27018 --logpath /data/db/slave3/slavelog.log --slave --source 127.0.0.1:27017OK,我们上面配置了一个master和三个slave,四个服务监听不同的端口、不同的数据路径、日志存储路径。
下面解答一下我们上面学习过程中遗留的一下点:
(1)同一台机器上多个mongod进程为何不能配置相同的数据库存放目录。
想要了解这个知识点,我们需要了解mongod.lock这样一个文件。这个文件中存放的是当前mongod进程的进程号,在每个dbpath下均有。mongod.lock限定当前目录的数据只能由与其存储的进程号相同的mongob来读取。
(2)通过开启slaveOkay参数可以开启从节点的处理功能
当负载是读取密集型时,开启这项功能是个不错的选择;要是写入密集型,就需要考虑使用自动分片来进行扩展了。
但是这个时候有一个主从同步延迟的问题:主节点更新数据之后,一段时间内,从结点中的数据并没有进行更新,高并发场景下更容易出现问题。
(3)oplogSize要设置的尽可能的大一些
首先,oplogSize是一个固定集合,从节点通过定期轮询主节点下的oplog来完成主从节点的同步。如果从节点的同步很慢,可能会造成从节点在同步完一次oplog之后再进行同步时发现oplog数据已经部分丢失了,因为oplog是固定集合,一些旧的操作被清除了,而从节点还没来得及同步,所以,oplogSize要设置的尽可能的大一些。讲到这里我们再重述一下固定集合的创建方式
>db.createCollection("cappedLogCollection",{capped:true,size:10000,max:1000})size设置固定集合的大小,单位为kB;max设置文档的个数
(4)从节点如何决定执行某些oplog而不执行另外的oplog的呢
每个从节点中有记录上次同步主节点的时间戳,等到下次再轮询主节点的oplog时便会将oplog下每个文档的时间戳与该时间戳进行对比,如果在该时间戳之后,则是新的更新操作(个人的理解)。
OK,上面我们只是简单的搭了一个主从同步的mongodb服务,其实,里面还有很多细节。
如
(1)从节点是如何保证从主节点拿到最新的oplog的,是有版本控制还是有时间戳?
(2)如何配置客户端的写操作是写主节点,而查询操作是查询的从节点
(3)从节点的轮询查询主节点的时间是可配置的吗
(4)如何查看某个主节点下的所有从节点以及某个从节点下的所有主节点
。。。
。。。
本片文章只是一个引子,关于主从复制是一个大的内容,文章内容后期会逐步完善。