我们平时创建普通的mapreduce项目,在遍代码当你需要导包使用一些工具类的时候,
你需要自己找到对应的架包,再导进项目里面其实这样做非常不方便,我建议我们还是用maven项目来得方便多了
话不多说了,我们就开始吧
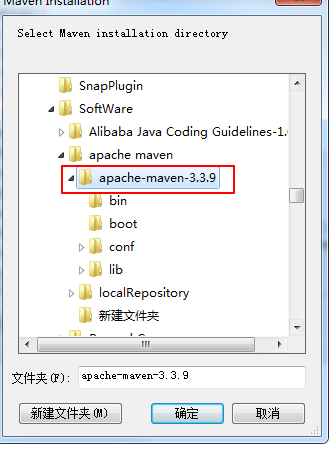
首先你在eclipse里把你本地安装的maven导进来
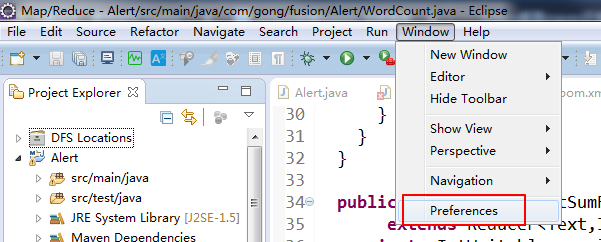
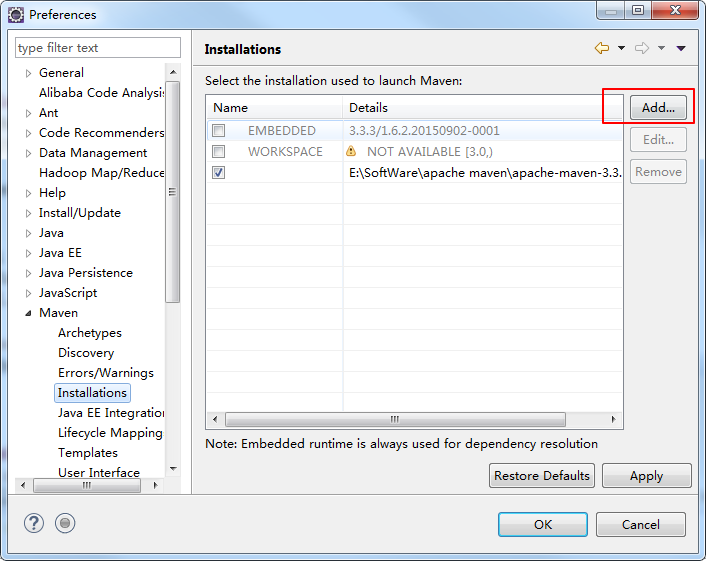
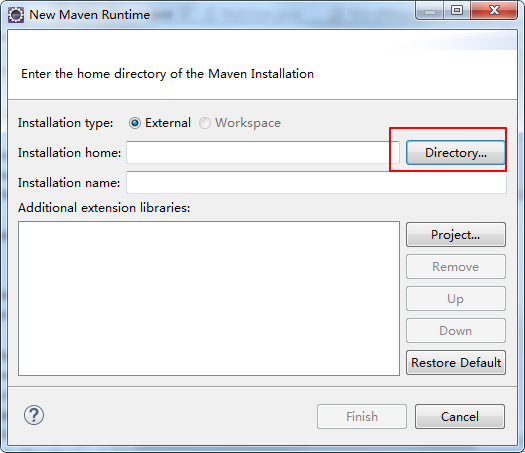
选择你本地安装的maven路径
勾选中你添加进来的maven
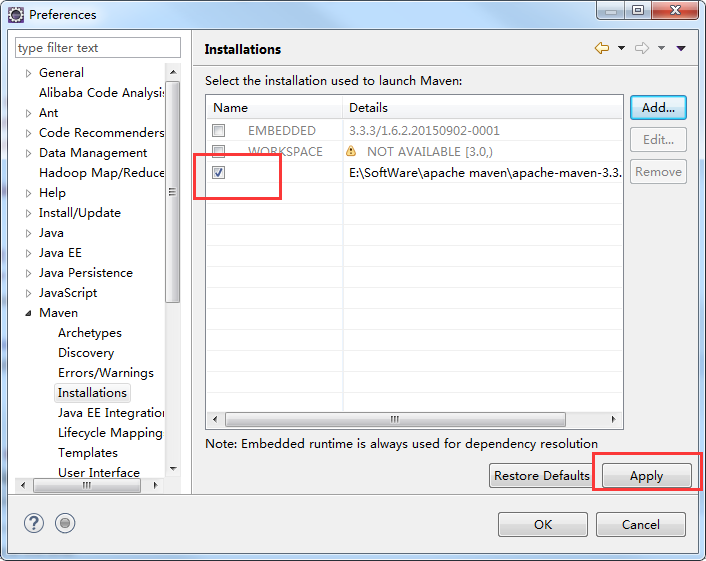
把本地安装的maven的setting文件添加进来

接下来创建一个maven项目

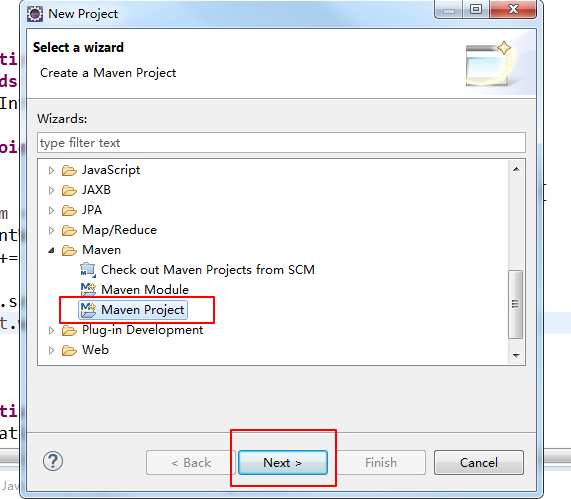
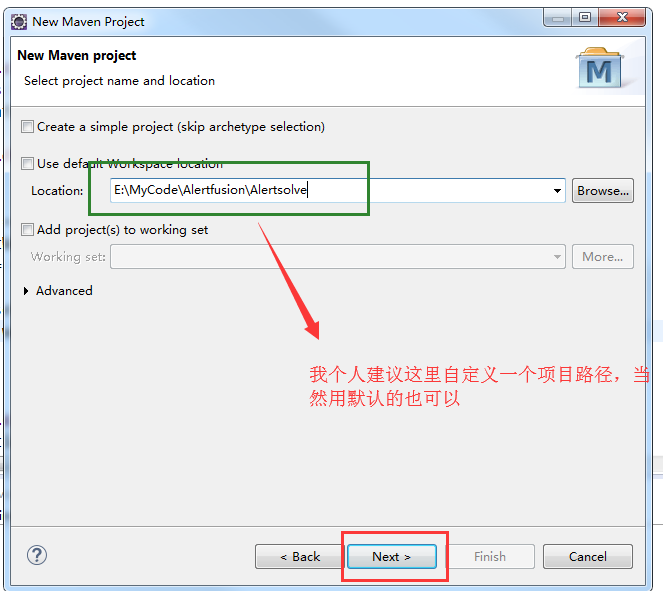
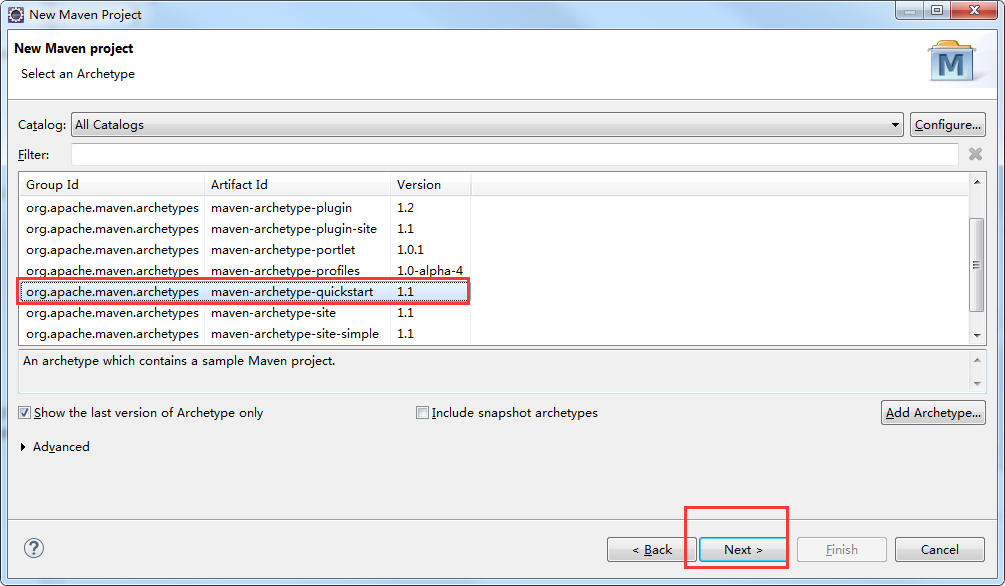
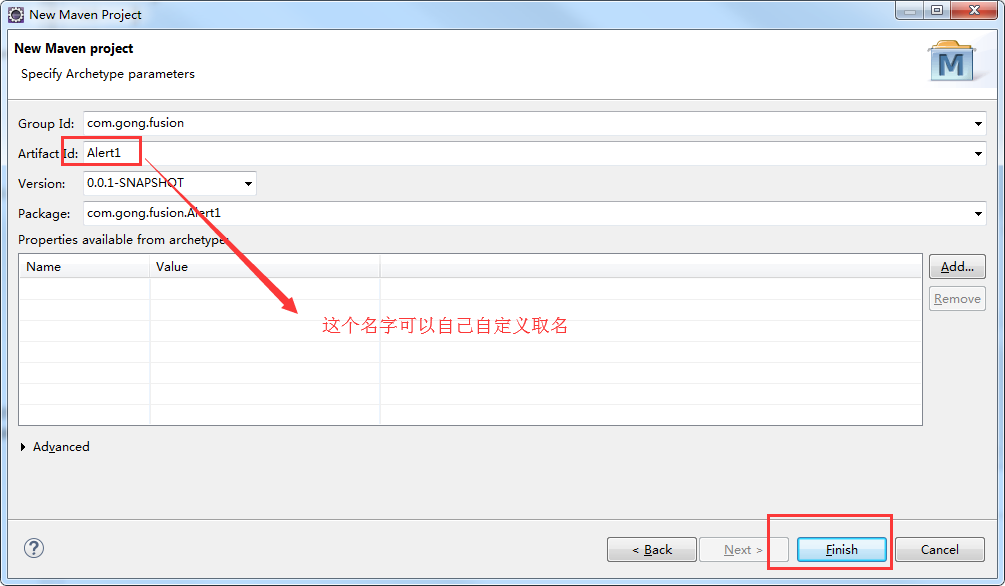
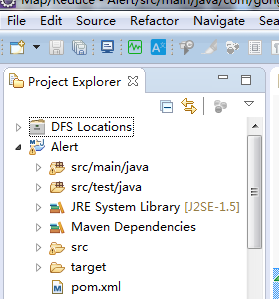
可以看到一个maven项目创建成功!!
现在我们来配置pom.xml文件,把mapreduce程序运行的一些架包通过maven导进来
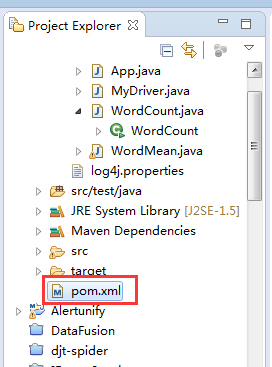
这个是我的项目文件可以给大家作参考
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.gong.fusion</groupId> <artifactId>Alert</artifactId> <version>0.0.1-SNAPSHOT</version> <packaging>jar</packaging> <name>Alert</name> <url>http://maven.apache.org</url> <properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> </properties> <dependencies> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>3.8.1</version> <scope>test</scope> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-common</artifactId> <version>2.6.0</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>2.6.0</version> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-hdfs</artifactId> <version>2.6.0</version> </dependency> <dependency> <groupId>jdk.tools</groupId> <artifactId>jdk.tools</artifactId> <version>1.7</version> <scope>system</scope> <systemPath>${JAVA_HOME}/lib/tools.jar</systemPath> </dependency> <dependency> <groupId>commons-lang</groupId> <artifactId>commons-lang</artifactId> <version>2.6</version> </dependency> </dependencies> <build> <plugins> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-shade-plugin</artifactId> <version>2.4.1</version> <executions> <!-- Run shade goal on package phase --> <execution> <phase>package</phase> <goals> <goal>shade</goal> </goals> <configuration> <transformers> <!-- add Main-Class to manifest file --> <transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer"> <mainClass>com.gong.fusion.Alert.MyDriver</mainClass> //这里是你自己项目的目录 </transformer> </transformers> <createDependencyReducedPom>false</createDependencyReducedPom> </configuration> </execution> </executions> </plugin> </plugins> </build> </project>
下面我们来写一个经典例子wordcount代码来实验一下
如何新建一个类来写我就不说了,我直接把代码放上来
package com.gong.fusion.Alert; import java.io.IOException; import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class WordCount { public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable>{ private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(Object key, Text value, Context context ) throws IOException, InterruptedException { StringTokenizer itr = new StringTokenizer(value.toString()); while (itr.hasMoreTokens()) { word.set(itr.nextToken()); context.write(word, one); } } } public static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable> { private IntWritable result = new IntWritable(); public void reduce(Text key, Iterable<IntWritable> values, Context context ) throws IOException, InterruptedException { int sum = 0; for (IntWritable val : values) { sum += val.get(); } result.set(sum); context.write(key, result); } } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); Job job = Job.getInstance(conf, "word count"); job.setJarByClass(WordCount.class); job.setMapperClass(TokenizerMapper.class); job.setCombinerClass(IntSumReducer.class); job.setReducerClass(IntSumReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.addInputPath(job, new Path("hdfs://cdh-master:9000/user/kfk/data/wc.input")); FileOutputFormat.setOutputPath(job, new Path("hdfs://cdh-master:9000/data/user/gong/wordcount-out1")); System.exit(job.waitForCompletion(true) ? 0 : 1); } }
我的eclipse是已经跟我的大数据集群HDFS连接的.

大家记得添加这个文件

我们运行一下这个代码
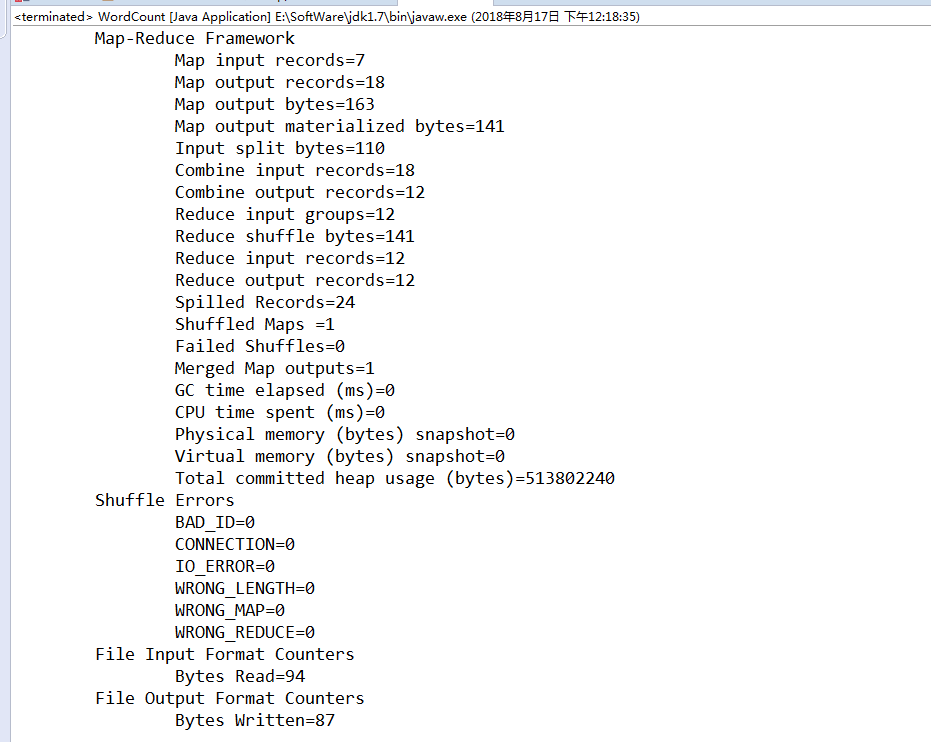
运行成功!!!!!
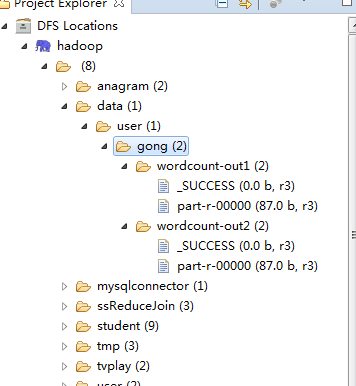
我们在hdfs上查看运行结果
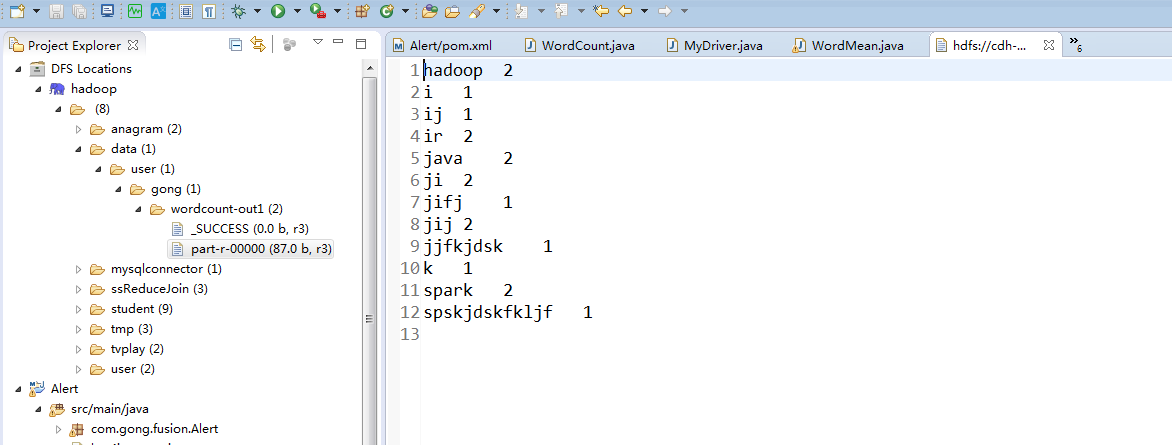
这样们就实现了在maven 项目里面运行mapreduce程序了
接下来要讲的就是怎么管理多个mapreduce程序
我们新建一个MyDriver类用来管理多个mapreduce程序的类,和再创建另外一个mapreduce程序类wordmean

wordmean的内容跟wordcount是一样的,我就是把名字和输出路径改了一下!!!
当然在实际的开发中不会有这样的情况的,我是方便测试才这样做
package com.gong.fusion.Alert; import java.io.IOException; import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.Reducer.Context; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; import com.gong.fusion.Alert.WordCount.IntSumReducer; import com.gong.fusion.Alert.WordCount.TokenizerMapper; public class WordMean { public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable>{ private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(Object key, Text value, Context context ) throws IOException, InterruptedException { StringTokenizer itr = new StringTokenizer(value.toString()); while (itr.hasMoreTokens()) { word.set(itr.nextToken()); context.write(word, one); } } } public static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable> { private IntWritable result = new IntWritable(); public void reduce(Text key, Iterable<IntWritable> values, Context context ) throws IOException, InterruptedException { int sum = 0; for (IntWritable val : values) { sum += val.get(); } result.set(sum); context.write(key, result); } } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); Job job = Job.getInstance(conf, "word count"); job.setJarByClass(WordCount.class); job.setMapperClass(TokenizerMapper.class); job.setCombinerClass(IntSumReducer.class); job.setReducerClass(IntSumReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); FileInputFormat.addInputPath(job, new Path("hdfs://cdh-master:9000/user/kfk/data/wc.input")); FileOutputFormat.setOutputPath(job, new Path("hdfs://cdh-master:9000/data/user/gong/wordcount-out2")); System.exit(job.waitForCompletion(true) ? 0 : 1); } }
package com.gong.fusion.Alert; import org.apache.hadoop.util.ProgramDriver; public class MyDriver { public static void main(String argv[]){ int exitCode = -1; ProgramDriver pgd = new ProgramDriver(); try { pgd.addClass("wordcount", WordCount.class, "A map/reduce program that counts the words in the input files."); pgd.addClass("wordmean", WordMean.class, "A map/reduce program that counts the average length of the words in the input files."); exitCode = pgd.run(argv); } catch(Throwable e){ e.printStackTrace(); } System.exit(exitCode); } }
现在就通过Mydriver这个类来同时管理两个mapreduce代码了
我们现在把程序通过maven打包放到大数据集群上面运行一下
在我们的电脑打开cmd窗口,切换到你的项目路径下,用mvn clean清除一下

然后我们通过命令mvn package对项目进行打包
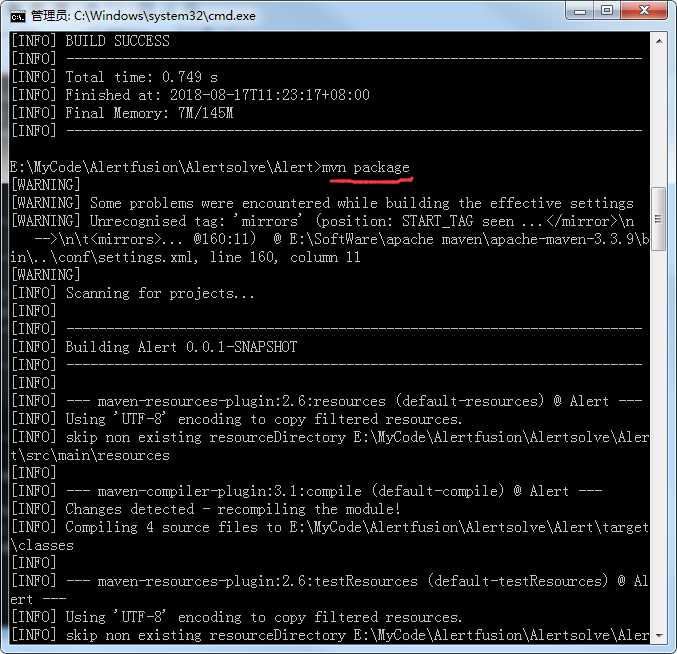
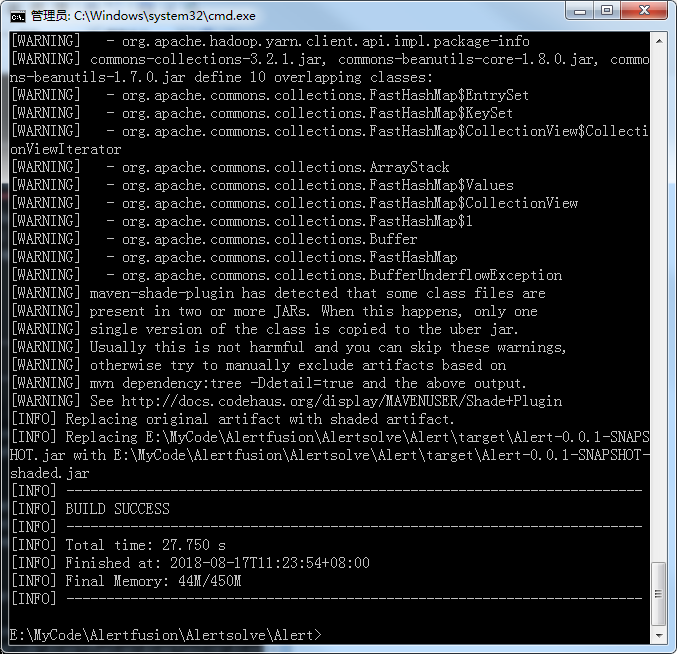
打包成功!!!
一般都会打包在target目录下的

我们把这个包上传到我们的大数据集群上面去,怎么上传我就不多说了,用工具上传,或者用rz命令上传就可以了

我们在集群上运行一下
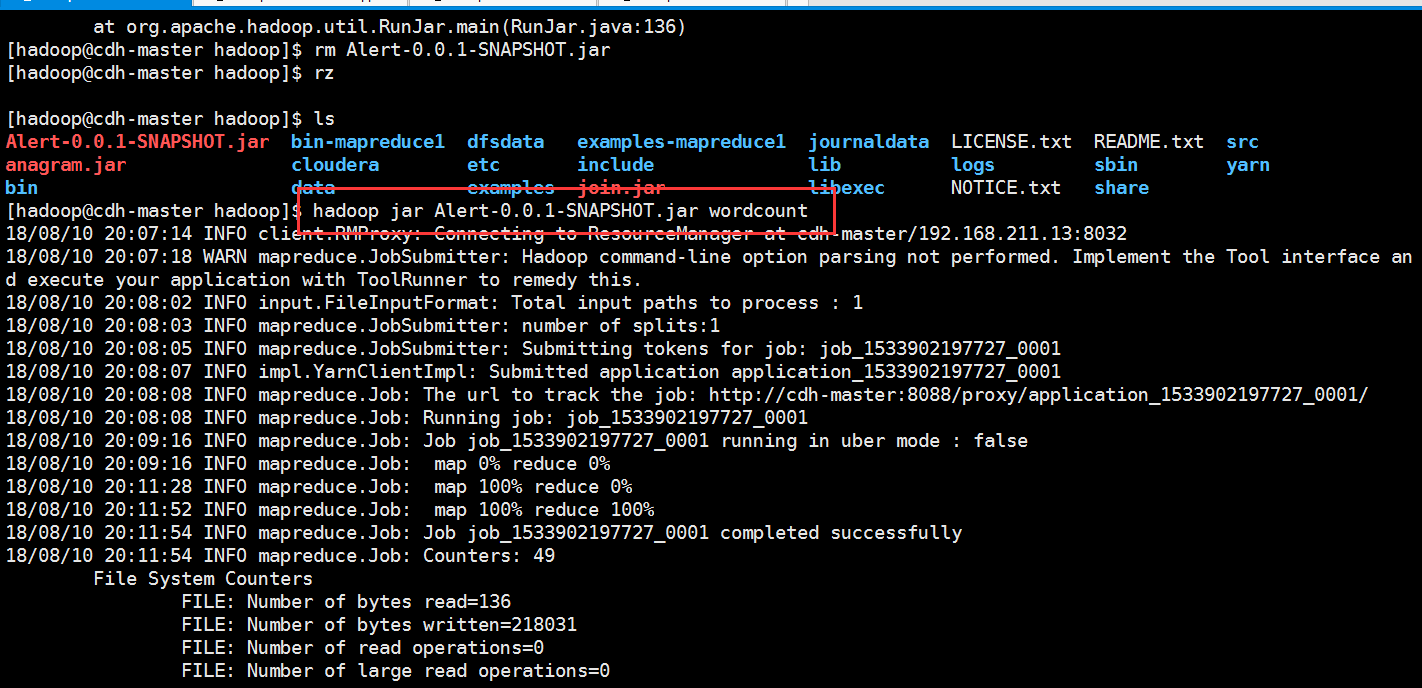
我们直接在代码包后面加上其中一个mapreduce类的别名就可以了,这个别名在Mydiver类里面定义的

可以看到我们对两个不同的mapreduce都起了不同的别名
下面我们看看运行的结果
[hadoop@cdh-master hadoop]$ hadoop jar Alert-0.0.1-SNAPSHOT.jar wordcount 18/08/10 20:07:14 INFO client.RMProxy: Connecting to ResourceManager at cdh-master/192.168.211.13:8032 18/08/10 20:07:18 WARN mapreduce.JobSubmitter: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this. 18/08/10 20:08:02 INFO input.FileInputFormat: Total input paths to process : 1 18/08/10 20:08:03 INFO mapreduce.JobSubmitter: number of splits:1 18/08/10 20:08:05 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1533902197727_0001 18/08/10 20:08:07 INFO impl.YarnClientImpl: Submitted application application_1533902197727_0001 18/08/10 20:08:08 INFO mapreduce.Job: The url to track the job: http://cdh-master:8088/proxy/application_1533902197727_0001/ 18/08/10 20:08:08 INFO mapreduce.Job: Running job: job_1533902197727_0001 18/08/10 20:09:16 INFO mapreduce.Job: Job job_1533902197727_0001 running in uber mode : false 18/08/10 20:09:16 INFO mapreduce.Job: map 0% reduce 0% 18/08/10 20:11:28 INFO mapreduce.Job: map 100% reduce 0% 18/08/10 20:11:52 INFO mapreduce.Job: map 100% reduce 100% 18/08/10 20:11:54 INFO mapreduce.Job: Job job_1533902197727_0001 completed successfully 18/08/10 20:11:54 INFO mapreduce.Job: Counters: 49 File System Counters FILE: Number of bytes read=136 FILE: Number of bytes written=218031 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=204 HDFS: Number of bytes written=87 HDFS: Number of read operations=6 HDFS: Number of large read operations=0 HDFS: Number of write operations=2 Job Counters Launched map tasks=1 Launched reduce tasks=1 Data-local map tasks=1 Total time spent by all maps in occupied slots (ms)=118978 Total time spent by all reduces in occupied slots (ms)=20993 Total time spent by all map tasks (ms)=118978 Total time spent by all reduce tasks (ms)=20993 Total vcore-seconds taken by all map tasks=118978 Total vcore-seconds taken by all reduce tasks=20993 Total megabyte-seconds taken by all map tasks=121833472 Total megabyte-seconds taken by all reduce tasks=21496832 Map-Reduce Framework Map input records=7 Map output records=18 Map output bytes=163 Map output materialized bytes=132 Input split bytes=110 Combine input records=18 Combine output records=12 Reduce input groups=12 Reduce shuffle bytes=132 Reduce input records=12 Reduce output records=12 Spilled Records=24 Shuffled Maps =1 Failed Shuffles=0 Merged Map outputs=1 GC time elapsed (ms)=852 CPU time spent (ms)=37740 Physical memory (bytes) snapshot=316510208 Virtual memory (bytes) snapshot=3017236480 Total committed heap usage (bytes)=136122368 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=94 File Output Format Counters Bytes Written=87
我们运行一下另外一个mapreduce程序

[hadoop@cdh-master hadoop]$ hadoop jar Alert-0.0.1-SNAPSHOT.jar wordmean 18/08/10 20:13:22 INFO client.RMProxy: Connecting to ResourceManager at cdh-master/192.168.211.13:8032 18/08/10 20:13:24 WARN mapreduce.JobSubmitter: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this. 18/08/10 20:13:33 INFO input.FileInputFormat: Total input paths to process : 1 18/08/10 20:13:33 INFO mapreduce.JobSubmitter: number of splits:1 18/08/10 20:13:34 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1533902197727_0002 18/08/10 20:13:35 INFO impl.YarnClientImpl: Submitted application application_1533902197727_0002 18/08/10 20:13:35 INFO mapreduce.Job: The url to track the job: http://cdh-master:8088/proxy/application_1533902197727_0002/ 18/08/10 20:13:35 INFO mapreduce.Job: Running job: job_1533902197727_0002 18/08/10 20:15:22 INFO mapreduce.Job: Job job_1533902197727_0002 running in uber mode : false 18/08/10 20:15:22 INFO mapreduce.Job: map 0% reduce 0% 18/08/10 20:16:30 INFO mapreduce.Job: map 100% reduce 0% 18/08/10 20:16:56 INFO mapreduce.Job: map 100% reduce 100% 18/08/10 20:16:57 INFO mapreduce.Job: Job job_1533902197727_0002 completed successfully 18/08/10 20:16:58 INFO mapreduce.Job: Counters: 49 File System Counters FILE: Number of bytes read=136 FILE: Number of bytes written=218025 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=204 HDFS: Number of bytes written=87 HDFS: Number of read operations=6 HDFS: Number of large read operations=0 HDFS: Number of write operations=2 Job Counters Launched map tasks=1 Launched reduce tasks=1 Data-local map tasks=1 Total time spent by all maps in occupied slots (ms)=65084 Total time spent by all reduces in occupied slots (ms)=23726 Total time spent by all map tasks (ms)=65084 Total time spent by all reduce tasks (ms)=23726 Total vcore-seconds taken by all map tasks=65084 Total vcore-seconds taken by all reduce tasks=23726 Total megabyte-seconds taken by all map tasks=66646016 Total megabyte-seconds taken by all reduce tasks=24295424 Map-Reduce Framework Map input records=7 Map output records=18 Map output bytes=163 Map output materialized bytes=132 Input split bytes=110 Combine input records=18 Combine output records=12 Reduce input groups=12 Reduce shuffle bytes=132 Reduce input records=12 Reduce output records=12 Spilled Records=24 Shuffled Maps =1 Failed Shuffles=0 Merged Map outputs=1 GC time elapsed (ms)=493 CPU time spent (ms)=8170 Physical memory (bytes) snapshot=312655872 Virtual memory (bytes) snapshot=3007705088 Total committed heap usage (bytes)=150081536 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=94 File Output Format Counters Bytes Written=87 [hadoop@cdh-master hadoop]$
可以看到两个不同的输出路径上,是两个程序分别运行的结果