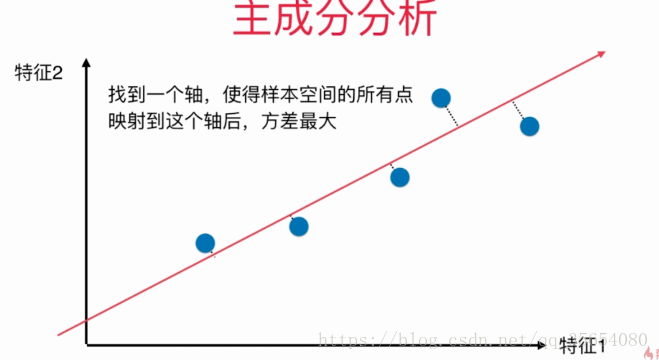
主成分分析:主成分分析 ( Principal Component Analysis , PCA )是一种掌握事物主要矛盾的统计分析方法,它可以从多元事物中解析出主要影响因素,揭示事物的本质,简化复杂的问题。计算主成分的目的是将高纬数据投影到较低维空间。给定 n 个变量的 m个观察值,形成一个 n *m 的数据矩阵,n通常比较大。对于一个由多个变量描述的复杂事物,认识难度会很大,于是我们可以抓住事物主要方面进行重点分析,如果事物的主要方面刚好体现在几个主要变量上,那么我们只需要将体现事物主要方面的较少的几个主要变量分离出来,对此进行详细分析。但是,在一般情况下,并不能直接找出这样的关键变量。这时我们可以用原有变量的线性组合来表示事物的主要方面, PCA 就是这样一种分析方法。




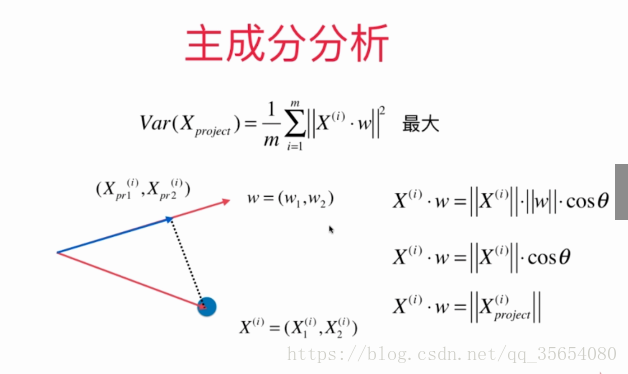


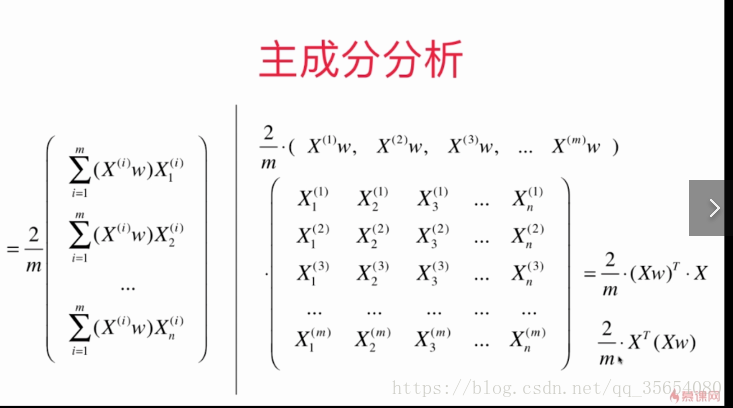
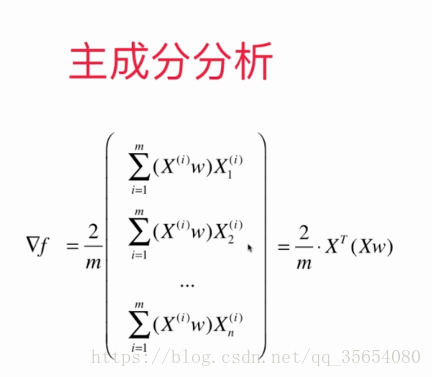
结果为n*1维的向量。
"""使用梯度上升法求解主成分"""
import numpy as np
import matplotlib.pyplot as plt
X=np.empty((100,2))
X[:,0]=np.random.uniform(0.,100.,size=100)
X[:,1]=0.75*X[:,0]+3.+np.random.normal(0,10.,size=100)
plt.scatter(X[:,0],X[:,1])
plt.show()
"""demean过程"""
def demean(X):
return X-np.mean(X,axis=0)
X_demean=demean(X)
plt.scatter(X_demean[:,0],X_demean[:,-1])
plt.show()
"""梯度上升法"""
def f(w, X):
"""求目标函数"""
return np.sum((X.dot(w) ** 2)) / len(X)
def df(w,X):
"""求梯度"""
return X.T.dot(X.dot(w)) * 2. / len(X)
def direction(w):
"""将w单位化"""
return w / np.linalg.norm(w)
def first_components(df,X, initial_w, eta=0.01, n_iters=1e4, epsilon=1e-8):
w = direction(initial_w)
cur_iter = 0
while cur_iter < n_iters:
gradient = df(w, X)
last_w = w
w = w + eta * gradient
w = direction(w) #每次求一个单位方向
if (abs(f(w, X) - f(last_w, X)) < epsilon):
break
cur_iter += 1
return w
initial_w=np.random.random(X.shape[1])
eta=0.01
w=first_components(df,X_demean,initial_w,eta)
plt.scatter(X_demean[:,0],X_demean[:,1])
plt.plot([0,w[0]*30],[0,w[1]*30],color='r')
plt.show()
"""求数据的前n个主成分"""
def first_n_components(n,X,eta=0.01,n_iters=1e4,epsilon=1e-9):
X_pca=X.copy()
X_pca=demean(X_pca)
res=[]
for i in range(n):
initial_w=np.random.random(X_pca.shape[1])
w=first_components(df,X_pca,initial_w,eta)
res.append(w)
X_pca=X_pca-X_pca.dot(w).reshape(-1,1)*w
return res
print(first_n_components(2,X))
高维数据转化为低维数据:

低维数据转为高维数据:
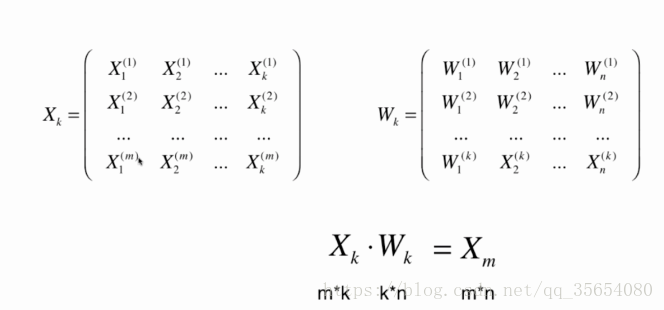
import numpy as np
class PCA:
def __init__(self, n_components):
"""初始化PCA"""
assert n_components >= 1, "n_components must be valid"
self.n_components = n_components
self.components_ = None
def fit(self, X, eta=0.01, n_iters=1e4):
"""获得数据集X的前n个主成分"""
assert self.n_components <= X.shape[1], \
"n_components must not be greater than the feature number of X"
def demean(X):
return X - np.mean(X, axis=0)
def f(w, X):
"""求目标函数"""
return np.sum((X.dot(w) ** 2)) / len(X)
def df(w, X):
"""求梯度"""
return X.T.dot(X.dot(w)) * 2. / len(X)
def direction(w):
return w / np.linalg.norm(w)
def first_component(X, initial_w, eta=0.01, n_iters=1e4, epsilon=1e-8):
w = direction(initial_w)
cur_iter = 0
while cur_iter < n_iters:
gradient = df(w, X)
last_w = w
w = w + eta * gradient
w = direction(w)
if (abs(f(w, X) - f(last_w, X)) < epsilon):
break
cur_iter += 1
return w
X_pca = demean(X)
"""components_其实是一个k*n的矩阵"""
self.components_ = np.empty(shape=(self.n_components, X.shape[1]))
for i in range(self.n_components):
initial_w = np.random.random(X_pca.shape[1])
w = first_component(X_pca, initial_w, eta, n_iters)
self.components_[i,:] = w
X_pca = X_pca - X_pca.dot(w).reshape(-1, 1) * w
return self
def transform(self, X):
"""将给定的X,映射到各个主成分分量中"""
assert X.shape[1] == self.components_.shape[1]
return X.dot(self.components_.T)
def inverse_transform(self, X):
"""将给定的X,反向映射回原来的特征空间"""
assert X.shape[1] == self.components_.shape[0]
return X.dot(self.components_)
def __repr__(self):
return "PCA(n_components=%d)" % self.n_components"""高低维之间的映射"""
import numpy as np
import matplotlib.pyplot as plt
from PCA import PCA
X=np.empty((100,2))
X[:,0]=np.random.uniform(0.,100.,size=100)
X[:,1]=0.75*X[:,0]+3.+np.random.normal(0,10.,size=100)
pca=PCA(n_components=1)
pca.fit(X)
print(pca.components_)
x_reduction=pca.transform(X)
x_restore=pca.inverse_transform(x_reduction)
plt.scatter(X[:,0],X[:,1],color='b',alpha=0.5)
plt.scatter(x_restore[:,0],x_restore[:,1],alpha=0.5)
plt.show()"""使用scikit-learn中的PCA"""
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.decomposition import PCA
digits=datasets.load_digits()
X=digits.data
y=digits.target
x_train,x_test,y_train,y_test=train_test_split(X,y,random_state=666)
knn_clf=KNeighborsClassifier()
knn_clf.fit(x_train,y_train)
print(knn_clf.score(x_test,y_test))
pca=PCA(0.95) #降维到保持0.95的精度
pca.fit(x_train)
print(pca.n_components_)
x_train_reduction=pca.transform(x_train)
x_test_reduction=pca.transform(x_test)
knn_clf.fit(x_train_reduction,y_train)
print(knn_clf.score(x_test_reduction,y_test))"""试手MNIST数据集"""
import numpy as np
from sklearn.datasets import fetch_mldata
from sklearn.neighbors import KNeighborsClassifier
from sklearn.decomposition import PCA
#from tensorflow.examples.tutorials.mnist import input_data
mnist=fetch_mldata("MNIST original",data_home='./')
X,y=mnist['data'],mnist['target']
X_train=np.array(X[:60000],dtype=float)
y_train=np.array(y[:60000],dtype=float)
X_test=np.array(X[60000:],dtype=float)
y_test=np.array(y[60000:],dtype=float)
"""使用kNN"""
knn_clf=KNeighborsClassifier()
knn_clf.fit(X_train,y_train)
print(knn_clf.score(X_test,y_test))
"""PCA进行降维"""
pca=PCA(0.9)
pca.fit(X_train)
X_train_reduction=pca.transform(X_train)
X_test_reduction=pca.transform(X_test)
print(knn_clf.score(X_test_reduction,y_test))
"""降噪 手写识别的例子"""
from sklearn import datasets
import numpy as np
import matplotlib.pyplot as plt
from PCA import PCA
digits=datasets.load_digits()
X=digits.data
y=digits.target
noisy_digits=X+np.random.normal(0,4,size=X.shape)
example_digits=noisy_digits[y==0,:][:10]
for num in range(1,10):
X_num=noisy_digits[y==num,:][:10]
example_digits=np.vstack([example_digits,X_num])
def plot_digits(data):
"""在图中画子图"""
fig,axes=plt.subplots(10,10,figsize=(10,10),subplot_kw={'xticks':[],'yticks':[]},gridspec_kw=dict(hspace=0.1,wspace=0.1))
for i,ax in enumerate(axes.flat):
ax.imshow(data[i].reshape(8,8),cmap='binary',interpolation='nearest',clim=(0,16))
plt.show()
plot_digits(example_digits)
"""利用PCA降噪"""
pca=PCA(0.5)
pca.fit(noisy_digits)
components=pca.transform(example_digits)
filtered_digits=pca.inverse_transform(components)
plot_digits(filtered_digits)"""特征脸"""
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import fetch_lfw_people
from sklearn.decomposition import PCA
faces=fetch_lfw_people()
random_index=np.random.permutation(len(faces.data))
X=faces.data[random_index]
example_faces=X[:36,:]
def plot_faces(data):
"""图中画子图"""
fig,axes=plt.subplots(6,6,figsize=(10,10),subplot_kw={'xticks':[],'yticks':[]},gridspec_kw=dict(hspace=0.1,wspace=0.1))
for i,ax in enumerate(axes.flat):
ax.imshow(data[i].reshape(62,47),cmap='bone')
plt.show()
plot_faces(example_faces)
pca=PCA(svd_solver='randomized')
pca.fit(X)
example_faces(pca.components_[:36,:])