从基本数据结构-表,浅析Collection中表实现(Arraylist(数组表)和Linkedlist(双链表))
表是一种最简单和最基本的数据结构,实际上,每个有意义的程序都将显式的使用这样的数据结构。
带有一组操作的一些对象的集合被称为抽象数据类型(ADT),表就是一种抽象数据类型。表ADT也有一些常用的操作,printList,find,insert,remove等等,其功能是显而易见的。下面进入正题。
表的简单数组实现
像刚才描述的所有操作,都可以通过数组实现。虽然数组长度是固定的,但是在必要时可以对数组进行扩容。类似这样:
int[] arr = new int[10];
//扩大arr
int[] newArr = new int[arr.length * 2];
for (int i = 0; i < arr.length; i++) {
newArr[i] = arr[i];
}
arr = newArr;数组对表的实现可以使printList以线性的时间执行,而且查找的速度也很快,花费常数时间。但是插入和删除却可能存在巨大的开销。假设所有的操作都发生在0索引,那么无论插入和删除都会使得剩下的元素集体移动一个位置,时间复杂度为O(N)。即使平均的来看,也需要花费线性的时间。当然,假如插入和删除发生在最后一个索引,那么就啥也不用移动,则只花费O(1)的时间。
这样看来,当插入和删除只发生在表的末尾,和之后只发生查找之类的操作,那么表的数组实现的确是一个不错的选择。但是插入和删除的发生位置无法确定,特别要是发生在前端,那么数组对表的实现就不是很恰当了。
简单链表
结合上部分的描述,为了避免插入和删除的线性开销,我们需要保证表可以不连续的存储。这就是另一种数据结构,链表。
链表由一系列节点组成,这些节点不需要在内存中连续。每个节点只需要包含当前元素和指向下一个节点的引用,称之为链,最后一个节点引用null。
对于printList或find,只需要从表的第一个节点开始,利用链遍历表即可。这些操作的时间显然是线性的,和数组实现一样(同样是花费线性时间,这种方式花费的时间是可能大于数组实现的)。但是对于remove(删除)这种操作,完全可以用修改一个链的引用实现。而对于insert(插入)而言,可以从系统中获得一个新的节点,然后执行两次引用的调整。这些是常数时间的操作。在删除操作中,删除最后一项相对复杂,因为必须找出指向最后节点的项,把它的链改为null,然后再更新持有最后节点的链。在经典的链表中,当前节点不会提供上上一节点的信息。
我们的做法是让当前节点不仅持有指向下一节点的链,还持有指向上一节点的链,这种链表被称之为双链表。
Collection中的表
Collection接口
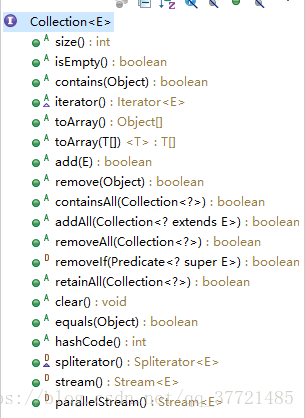
表ADT是Collections API中实现的数据结构之一。Collections API在util包中,集合的概念在Collection接口中得到抽象,collection中有很多可以见名知意的属性和方法。
Iterator接口
实现Iterable接口的集合必须要实现一个称为iterator的方法,该方法返回一个Iterator类型(这里的Iterator是一个接口)的对象。
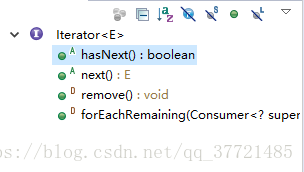
Iterator接口的思路是:每次返回iterator方法,每隔集合均可创建并返回一个实现Iterator接口的对象,并将当前位置的数据在对象内部存储下来。每次对hasNext的调用都会验证是否存在下一项,对next的调用会给出下一项。
Iterator接口还提供了一个remove的方法,用来删除next最新返回的项。Collection接口同样也提供了remove方法,但是Iterator提供的remove可能有更多的优点。
其一,Collocation的remove必须先找到要被删除的项。Iterator的remove是删除next最新返回的项(当前项)。Iterator的remove方法潜藏着更高的效率和更小的开销。
其二,合法性。使用Iterator是一个基本法则,正在被迭代的集合如果发生了结构上的改变(即使用了add,remove等方法),那么这个迭代器就不在合法。然而,如果调用Iterator的remove方法,那么这个迭代器依旧是是合法的。
其三,感觉说着说着跑题了,但是一说到集合,就绕不开Iterator。2333333333
可能有些大兄弟会疑惑为什么一定要实现Iterable接口,为什么不直接实现Iterator接口呢。其实我也有这疑惑,后来看了一些大神的分析明白了。( 因为Iterator接口的核心方法next()或者hasNext() 是依赖于迭代器的当前迭代位置的。如果Collection直接实现Iterator接口,势必导致集合对象中包含当前迭代位置的数据。当集合在不同方法间被传递时,由于当前迭代位置不可预置,那么next()方法的结果会变成不可预知。除非再为Iterator接口添加一个reset()方法,用来重置当前迭代位置。但即时这样,Collection也只能同时存在一个当前迭代位置。而Iterable则不然,每次调用都会返回一个从头开始计数的迭代器。多个迭代器是互不干扰的。)这个过程就是小白的进阶之路吧。
ArraList和LinkedList
在Collection API中我们主要讨论表(List),它对应的是java.util中的List接口。List接口继承了Collection接口,因此它包含Collection的所有方法,外加一些其他方法。列举几个常用的,无非就是增删改查。
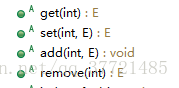
listIterator方法会返回一个ListIterator(也是个接口)类型的对象,ListIterator继承了Iterator接口,实现了对List集合的反向迭代。有兴趣可以去看下源码,就不介绍了。
List ADT有两种流行的实现方式:ArraList和LinkedList。
- ArraList:ArraList提供了一种可增长数组的实现。使用ArrayList的优点在于,对于get和set的调用花费常数时间。其缺点是删除和增加的代价昂贵(除非发生在末尾)。
- LinkedList:LinkedList则提供了一种双链表的实现。它对删除和增加的开销很小(而且这个类还直接提供了对表两端直接操作的方法,例如addFirst、removeLast等等)。它的缺点是不容易做索引(前面提到过,因为它在内存上不连续),所以他对于get的调用是昂贵的。
下面举例说明:
public void addFirst(List<Integer> list,int N) {
list.clear();
for (int i = 0; i < N; i++)
list.add(0, i);
}这段代码对于LinkedList来说,运行时间是O(N)。但是对于ArrayList来说是O(N*2),因为在ArrayList中在前端的add操作是O(N)。
public int sum(List<Integer> list,int N) {
int sum = 0;
//假设N=list.size(),用N看时间复杂度明显些
for (int i = 0; i < N; i++)
sum += list.get(i);
return sum;
}对于这段代码,ArrayList的运行时间是O(N),而LinkedList的运行时间是O(N*2),因为LinkedList对get的操作是O(N)。
public int sum(List<Integer> list) {
int sum = 0;
for (int tem:list)
sum += tem;
return sum;
}之前说了些Iterator,有些跑题,那就在拉回来点。这段代码,对于两种List运行时间都是O(N)。因为增强for是对迭代器的使用,迭代器可以有效地从一项推进到另一项。
另外,这两种List的搜索都是低效的,对于contains和remove方法的调用均花费线性时间。这里的remove方法指的是返回值是boolean的remove(Object)方法。
emmmmmm
本来接下来是想分析下ArrayList和LinkedList的源码的,emmmmmm,写的不少了也,有机会再说吧。再补充一些。
最基本的三种数据结构是表,栈和队列。但是栈和队列其实也是表。栈是限制添加和删除都只能在末端的表,队列是插入和删除分别在两端的表。也就是说,一切实现表的方法都能实现队列和栈。那么自然ArrayList和LinkedList同样能实现栈和列队,而且只需要两个集合现有的功能就能实现,有兴趣的话可以自己试试。