这篇论文就不像是前面那篇图像分割的论文更像是计算机视觉的论文。这篇论文是属于机器学习领域并且更像于流形学习中的一类。但是基本方法还是很像前面那篇图像分割的论文,都是利用拉普拉斯矩阵来求其特征向量来实现我们降维的目的(也跟谱聚类的思想很类似),这里想简单的说明这篇利用Laplacian Eigenmaps来进行降维的基本算法流程:
降维的基本意思就是:我们现在有x_1,x_2,….,x_k的k个点在空间R_l中(可以简单理解每一个点的维度都是l),然后我们用y_1,y_2,…,y_k的k个点在空间R_m中(y的每一个点的维度都是m)来表示x点
(1)我们要先构建邻接图(也就是邻接矩阵),也就要确定图中的每一个结点应该要和其他哪些点相连。
准则有两个:
1. 判断两个i,j之间的距离
,即两点间的距离小于这个阈值就将这两个点相连起来。
这个方法的优点:这种方法有助于得到一个全局最优的图。缺点:这个阈值很难选取。
2. 选取点i周围最近的n个点相连起来,这个方法的优点:免去了选择阈值的困难。缺点:构建出来的图更多是局部最优的图。
(2)我们得到二二相连的信息之后,我们就要知道两个点相连的边权如何设置呀。这样同样给出了两种方法:
1. 借助Heat kernel的知识来计算我们的边权:
如果两个点相连接,则有:
如果两个点不相连,则有
(为什么选取热核,在论文的下面会有所说明)
2. 简单的相连为1,不相连为0。
(3)在图构建完成之后,得到图的邻接矩阵W,度矩阵D,以及最后得到的拉普拉斯矩阵L=D-W,并得到以下的公式:
也就是求其矩阵最小的m个特征值(非零)对应的特征向量来嵌入我们原来的高维数据,作为数据输出。
在解释下面为什么使用这些降维方法之前,我想先说一点有关流形学习的内容:
Reference: http://blog.pluskid.org/?p=533
这篇论文频繁的强调mainfold(流形)以及embedding map(低维嵌入)
举一个很简单的人脸识别的例子:

对于一张32*32的灰度图片来说,它的维度是1024维,但因为这张人脸都来自同一个人,实际上不同的人脸都是由同一张人脸进行上下俯仰的角度,左右转动的角度,以及亮度这三个因素决定的,那么理论上1024维的数据的自由度是3,用3维数据就可以表示1024维数据的不同。也就是说上下俯仰的角度,左右转动的角度,以及亮度就是1024维空间的一个3维嵌入,是不是有点感觉了呢,但是我们要怎样找这么一个低维嵌入呢。首先,我们不知道高维的流形是怎么样的,如下图:
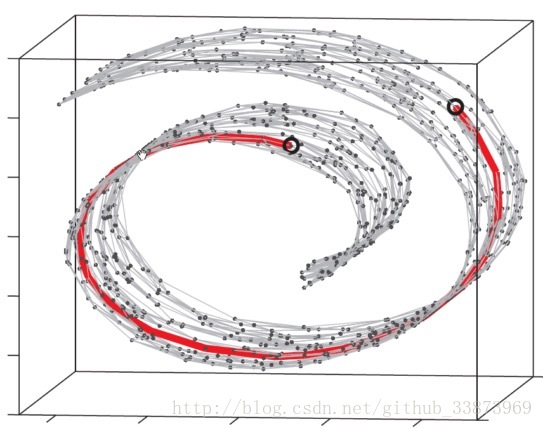
根据Isomap的说明,我们要使得在低维嵌入的两点间距离和在高维的mainfold相同(这个距离也就是图中的测地线,红线),由于我们不知道图形具体的流形是什么样的,肯定不能直接用两点距离来做距离(不能从流形中穿过去),这里我们就构建了一个图,将流形上所有点连接起来。那么,流形距离就是图中两点间最短距离了。
好了,知道了这个原理,我们就可以针对我们的论文继续看了。
我们如何找到这个最佳嵌入,根据这篇论文的思路,我们想要保持原有的流行性质,也就是说在原有空间中 , 越接近,那么在嵌入的空间中的 , 也要足够接近,抽象成以下的目标函数:
W_ij表示原有图中的 , 的边权,只有 和 的边权小且 和 的距离也小我们最后的目标函数也小,经过运算,就得到了运算后的目标函数:
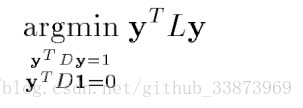
刚好符合我们求拉普拉斯矩阵的特征向量的例子。
文章中也说明了,我们为什么要选取Laplace Beltrami运算符和Heat kernel,这里面都是大段的数学推导。这里就不细说了哈。
这篇论文中也论证了和我们笔记一中的Normalized Cuts的方法是一致的方法。