很多人可能每天都要浏览新闻,但是每一天都需要刷很多的新闻客户端。今天就用Python大法来解决你的烦恼,让你一次看个够。。。
基本思路
爬取新闻的方法有很多,可以通过解析网页,也可以利用API爬取。今天就正式一点,利用网易的新闻API接口来爬取数据。通过访问接口,解析返回来的数据,保存你关心想要的信息。
API:http://c.m.163.com/nc/article/headline/T1348647853363/0-100.html
观察数据信息
访问网易新闻的API,可以看到一大堆的新闻数据,并且数据类型跟字典类似。所以转换为json格式,方便提取。
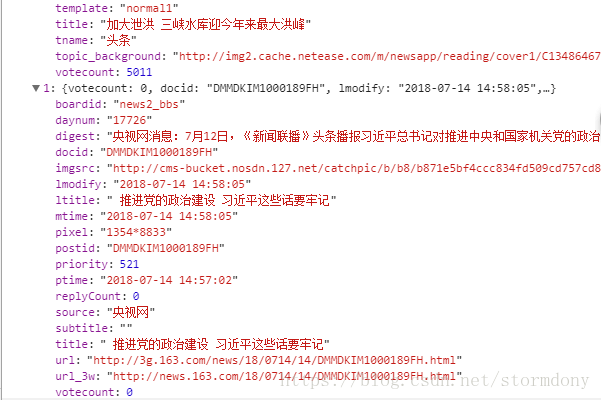
代码:
import requests
import json
url = 'http://c.m.163.com/nc/article/headline/T1348647853363/0-100.html'
header = {
'User-Agent': 'Mozilla/4.0(compatible;MSIE7.0;WindowsNT5.1)',
'Connection': 'keep - alive',
}
wbdata = requests.get(url,headers=header).text
data = json.loads(wbdata)
news = data['T1348647853363']
for item in news:
digest = item['digest']
mtime = item['mtime']
title = item['title']
source = item['source']
try:
url = item['url']
except:
url = ''
newes_data ={
'title': title,
}
print(newes_data)
input()
#更多数据
#newes_data ={
# 'title': title,
# #'内容': digest,
# '时间': mtime,
# '来源': source,
# '链接': url,
# }
由于只是想要快速的浏览一下,所以这里只提取了标题信息而已 。至于后面的input(),只是为了让Python运行完的时候不一闪而过。
运行结果:

总结
在网上搜索一下,可以发现有很多的接口,我这里这是选取了其中的一个,有兴趣可以自己去试一下其他的。当然也可以设计一个定时任务,让这个程序每天定时运行起来,这样子就可以,很方便的享受新鲜出炉的新闻啦。。。
ps: 这个API后面的0-100是参数,并且最大只能支持100
更多内容请关注公众号↓ ↓ ↓
