一、背景
日志收集并入hbase
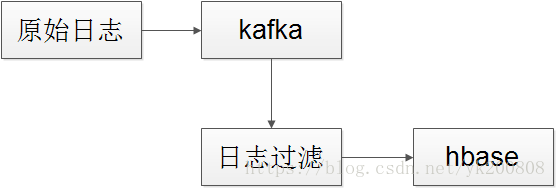
1、框架
2、日志量
每日产生3000万条日志,高峰期每小时产生300多万条
3、日志过滤
80%的日志需要过滤掉【由于特殊性,无法将需要的日志生成到一个指定文件,这里不做过多讨论】
4、机器部署
4台机器,每台20个线程,kafka80个partition
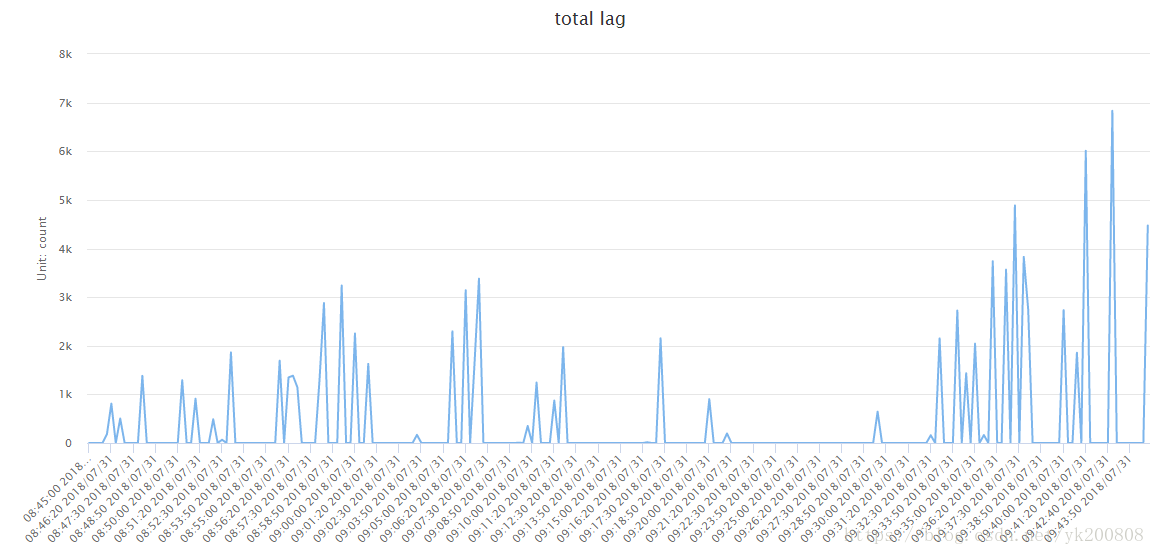
5、日志处理延迟情况
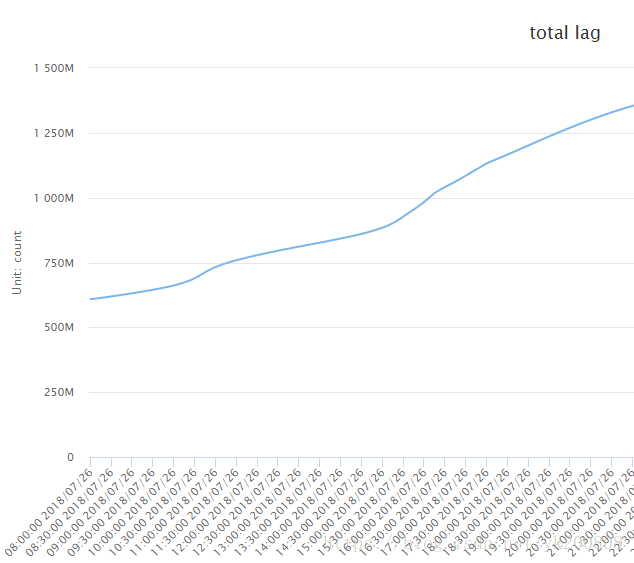
6、问题:
如上可以看到,每日的日志处理都有严重的积压,现在数据量一直在上涨,而且10倍的涨幅是近期就会发生的事情,不能单纯的通过扩充机器数量来解决问题
二、问题分析
1、罪魁祸首就是日志不能定制,需要过滤掉80%的不需要的日志量,耗时严重【这个无法解决】
2、日志处理程序日志打印过多,每条日志耗时1ms,打印量也是N千万条
3、关键字过滤没有太好的方法,关键字在日志的中间位置,而且位置不确定。并非开头位置、非固定位置
4、hbase服务器写入CPU消耗很多
5、hbase的写入耗时,每100条,耗时从200ms~1300ms都有
6、增加partition不是解决问题的正常思维
7、增加服务器不是解决问题的正常思维
三、【第一次优化】问题解决
1、为了能快速看到结果,将日志处理的业务日志全部删除了
2、关键字过滤逻辑
a)之前的过滤逻辑

b)修改之后的过滤逻辑
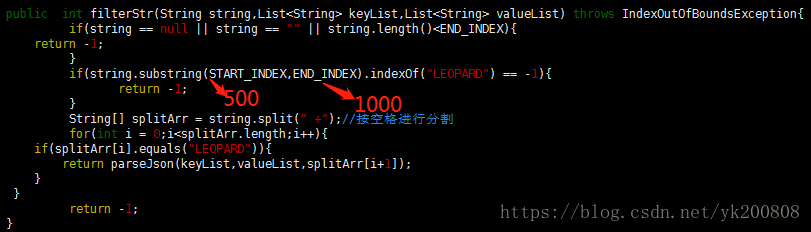
单条日志的长度大于2000字符,少于5000字符
通过分析,发现关键字 "LEOPARD" 稳定出现在日志的 500~1000字节处
如上两种方法大家可以尝试一下。每1万处理耗时,前者是4000ms左右,后者是18ms左右
四、效果
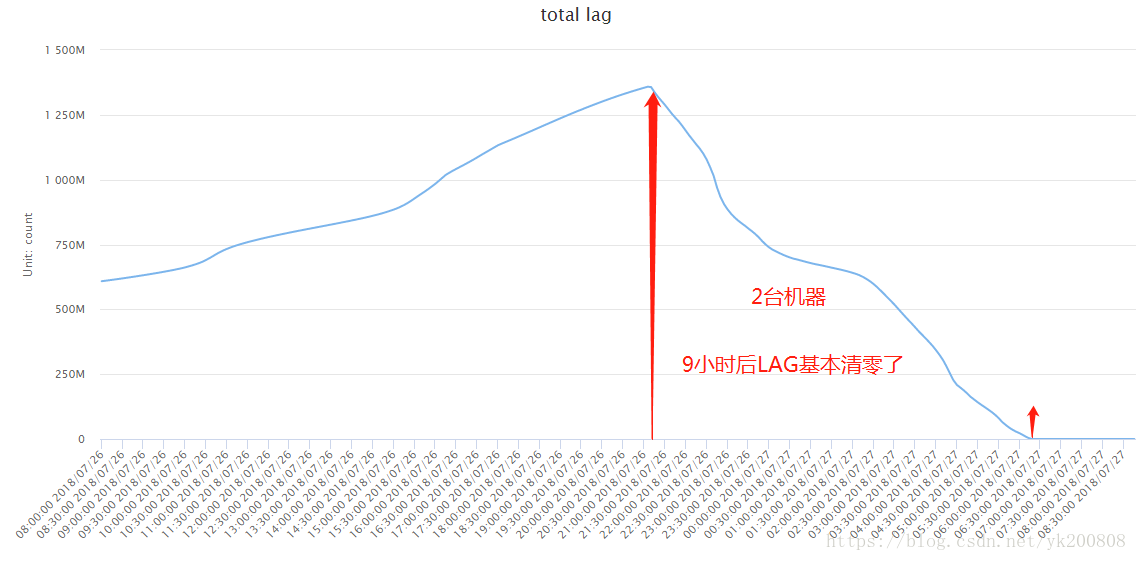
1、考虑hbase服务器压力,只使用2台服务器进行日志处理,另外2台服务器没有启用
2、上线9小时后,堆积的1300万条日志消耗完了,同时业务实时产生的日志也消耗完了。
3、高峰期LAG数量是7千条,而且很快就消耗掉了。
五、之后对hbase的业务表进行了拆分
拆分hbase表,主要是因对hbase服务器写入压力问题
同时也能缓解批量写入hbase时,耗时差异很大的问题,等后续有数据了再更新。
六、总结
编码时,一定要注意代码的效率。尤其是消费类型的业务,一定要提高消费的能力。