技术选型
技术选型常常是一个非常严谨的过程。由于一个项目通常是由数十位甚至上百位开发人员协同开发的,因此一个精准的技术选型常常能够大幅提高整个项目的开发效率。在尝试为某一类需求设计解决方案时,我们常常会有很多种可以选择的技术。为了能够精准地选择一个适合于这些需求的技术,我们就需要考虑一系列有关学习曲线,开发,维护等众多方面的因素。这些因素主要包括:
- 该技术所提供的功能是否能够完整地解决问题。
- 该技术的扩展性如何。是否允许用户添加自定义组成来满足特殊的需求。
- 该技术是否有丰富完整的文档,并且能够以免费甚至付费的形式得到专业的支持。
- 该技术是否有很多人使用,尤其是一些大型企业在使用,并存在着成功的案例。
在该过程中,我们会逐渐筛选市面上所能找到的各种技术,并最终确定适合我们需求的那一种。
针对我们刚刚所提到的需求——记录并处理系统自动生成的大量数据,我们在技术选型的初始阶段会有很多种选择:Key-Value数据库,如Redis,Document-based数据库,如MongoDB,Column-based数据库,如Cassandra等。而且在实现特定功能时,我们常常可以通过以上所列的任何一种数据库来搭建一个解决方案。可以说,如何在这三种数据库之间选择常常是NoSQL数据库初学者所最为头疼的问题。导致这种现象的一个原因就是,Key-Value,Document-based以及Column-based实际上是对NoSQL数据库的一种较为泛泛的分类。不同的数据库提供商所提供的NoSQL数据库常常具有略为不同的实现方式,并提供了不同的功能集合,进而会导致这些数据库类型之间的边界并不是那么清晰。
恰如其名所示,Key-Value数据库会以键值对的方式来对数据进行存储。其内部常常通过哈希表这种结构来记录数据。在使用时,用户只需要通过Key来读取或写入相应的数据即可。因此其在对单条数据进行CRUD操作时速度非常快。而其缺陷也一样明显:我们只能通过键来访问数据。除此之外,数据库并不知道有关数据的其它信息。因此如果我们需要根据特定模式对数据进行筛选,那么Key-Value数据库的运行效率将非常低下,这是因为此时Key-Value数据库常常需要扫描所有存在于Key-Value数据库中的数据。
因此在一个服务中,Key-Value数据库常常用来作为服务端缓存使用,以记录一系列经由较为耗时的复杂计算所得到的计算结果。最著名的就是Redis。当然,为Memcached添加了持久化功能的MemcacheDB也是一种Key-Value数据库。
Document-based数据库和Key-Value数据库之间的不同主要在于,其所存储的数据将不再是一些字符串,而是具有特定格式的文档,如XML或JSON等。这些文档可以记录一系列键值对,数组,甚至是内嵌的文档。如:

1 { 2 Name: "Jefferson", 3 Children: [{ 4 Name:"Hillary", 5 Age: 14 6 }, { 7 Name:"Todd", 8 Age: 12 9 }], 10 Age: 45, 11 Address: { 12 number: 1234, 13 street: "Fake road", 14 City: "Fake City", 15 state: "NY", 16 Country: "USA" 17 } 18 }
有些读者可能会有疑问,我们同样也可以通过Key-Value数据库来存储JSON或XML格式的数据,不是么?答案就是Document-based数据库常常会支持索引。我们刚刚提到过,Key-Value数据库在执行数据的查找及筛选时效率非常差。而在索引的帮助下,Document-based数据库则能够很好地支持这些操作了。有些Document-based数据库甚至允许执行像关系型数据库那样的JOIN操作。而且相较于关系型数据库,Document-based数据库也将Key-Value数据库的灵活性得以保留。
而Column-based数据库则与前面两种数据库非常不同。我们知道,一个关系型数据库中所记录的数据常常是按照行来组织的。每一行中包含了表示不同意义的多个列,并被顺序地记录在持久化文件中。我们知道,关系型数据库中的一个常见操作就是对具有特定特征的数据进行筛选及操作,而且该操作常常是通过WHERE子句来完成的:
1 SELECT * FROM customers WHERE country='Mexico';
在一个传统的关系型数据库中,该语句所操作的表可能如下所示:

而在该表所对应的数据库文件中,每一行中的各个数值将被顺序记录,从而形成了如下图所示的数据文件:
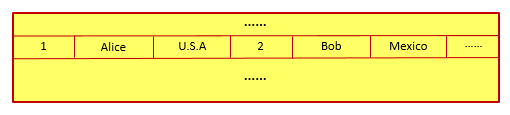
因此在执行上面的SQL语句时,关系型数据库并不能连续操作文件中所记录的数据:

这大大降低了关系型数据库的性能:为了运行该SQL语句,关系型数据库需要读取每一行中的id域和name域。这将导致关系型数据库所要读取的数据量显著增加,也需要在访问所需数据时执行一系列偏移量计算。况且上面所举的例子仅仅是一个最简单的表。如果表中包含了几十列,那么数据读取量将增大几十倍,偏移量计算也会变得更为复杂。
那么我们应该如何解决这个问题呢?答案就是将一列中的数据连续地存在一起:

而这就是Column-based数据库的核心思想:按照列来在数据文件中记录数据,以获得更好的请求及遍历效率。这里有两点需要注意:首先,Column-based数据库并不表示会将所有的数据按列进行组织,也没有那个必要。对某些需要执行请求的数据进行按列存储即可。另外一点则是,Cassandra对Query的支持实际上是与其所使用的数据模型关联在一起的。也就是说,对Query的支持很有限。我们马上就会在下面的章节中对该限制进行介绍。
至此为止,您应该能够根据各种数据库所具有的特性来为您的需求选择一个合适的NoSQL数据库了。