第一部分
在这个博客中,实现了一个简单的语意情感分析,将文件中的所有单词,逐句进行分析,并对每个句子给出一个评分。1表示正面,0表示中立,-1表示负面。
其中用到了语意字典,拿到某个名次或动词后,要在字典中查找其感情色彩,并将该值记录。每个句子输出一个分数。
代码如下:
import nltk
from nltk.tokenize import sent_tokenize
import csv
import numpy
def getposneg(searchword):
wordcsv_file = open("wordcsv_simp.csv","r")
pos = []
neg = []
found = 0
for row in csv.DictReader(wordcsv_file):
if row['Word'] == searchword:
pos.append(float(row['Pos']))
neg.append(float(row['Neg']))
found = 1
if found == 0:
return 0
else:
#print "pos=%s, neg=%s"%(numpy.mean(pos),numpy.mean(neg))
if numpy.mean(pos) - numpy.mean(neg) > 0.1:
return 1
elif numpy.mean(pos) - numpy.mean(neg) < -0.1:
return -1
else:
return 0
wordcsv_file.close()
file = open('1155099711.txt')
text = file.read()
filename = open('sentiment_scores.txt','a')
text = text.replace(",",".")
# tokenize opinion into sentences. Try to break the sentences by comma as well
sent_tokenize_list = sent_tokenize(text)
lenSent = len(sent_tokenize_list)#remember the counts of sentences
#negative_prefix_list,for checking the pre words of adj so to find if it is not positive
negative_prefix_list = ['no','not','nor','none','never','nothing','neither','hardly','barely','rarely','scarcely','little','few','seldom']
# examine each sentence one by one
for k in range(lenSent):
total_score = 0
#print sent_tokenize_list[k]
filename.write(sent_tokenize_list[k]+'\n')
text_tok = nltk.word_tokenize(sent_tokenize_list[k])
Tag = nltk.pos_tag(text_tok)
#print "Number of tag = %s"%len(Tag)
lenTag = len(Tag)
np = [];
flag = [1 for i in range(lenTag)]#set all the flag of Tag is 1
nlist = [];
# try to group several nouns 'NN' / 'NNP' into noun phrases
for t in range(lenTag):
if flag[t] == 1:
if Tag[t][1] == "NN":
if Tag[t+1][1] == "NN":
np.append(text_tok[t]+" "+ text_tok[t+1])
flag[t+1] = 0
flag[t] = 0
nlist.append(t+1)
else:
flag[t] = 0
np.append(text_tok[t])
nlist.append(t)
elif Tag[t][1] == "NNP":
if Tag[t+1][1] == "NNP" and Tag[t+2][1] == "NN":
flag[t] = 0
flag[t+1] = 0
flag[t+2] = 0
np.append(text_tok[t]+" "+text_tok[t+1]+" "+ text_tok[t+2])
nlist.append(t+2)
elif Tag[t+1][1] == "NN":
flag[t] = 0
flag[t+1] = 0
np.append(text_tok[t]+" "+text_tok[t+1])
nlist.append(t+1)
else:
flag[t] = 0
np.append(text_tok[t])
nlist.append(t)
#print "List of noun=%s"%np
#print "Corresponding number=%s"%nlist
# Find sentiment + check negation
jlist = [];
sentlist = [];#sentiments of adj and verbs
for t in range(lenTag):
if Tag[t][1] == "JJ" or Tag[t][1] =='JJS' or Tag[t][1] == 'JJR': # find adjectives
jlist.append(t)
#print 'adj',text_tok[t]
sentiment = getposneg(text_tok[t])
#print 'adj sentiment',sentiment
if text_tok[t-1] in negative_prefix_list or text_tok[t-2] in negative_prefix_list: # you should add more negative words
sentiment *= -1
total_score = total_score + sentiment # add every single sentiment score to total score
if sentiment > 0:
jj_sentiment = "positive"
elif sentiment < 0:
jj_sentiment = "negative"
else:
jj_sentiment = "neutral"
sentlist.append(jj_sentiment)
#print "Adj: %s at %s is %s"%(Tag[t][0],t,jj_sentiment)
if len(jlist) == 0: # if there is no adjectives, find verbs that may have sentiments
for t in range(lenTag):
if (Tag[t][1] == "VB" or Tag[t][1] == "VBD" or Tag[t][1] == "VBG" or Tag[t][1] == "VBN" or Tag[t][1] == "VBP" or Tag[t][1] == "VBZ"):
#print 'verb word',text_tok[t]
sentiment = getposneg(text_tok[t])
total_score = total_score + 0.5*sentiment
#print 'verb sentiment',sentiment
if sentiment > 0:
verb_sentiment = "positive"
elif sentiment < 0:
verb_sentiment = "negative"
else:
verb_sentiment = "neutral"
sentlist.append(verb_sentiment)
#print "Verb: %s at %s is %s"%(Tag[t][0],t,verb_sentiment)
if total_score > 0:
total_score = 1
elif total_score <0:
total_score = -1
else:
total_score = 0
#print 'Total score of this sentence: ',total_score
input_string = 'Total score of this sentence: ' + str(total_score) +'\n' +"---------------------------------------------"+'\n\n'
#with open(filename,'a') as f:
filename.write(input_string)
file.close()
第二部分
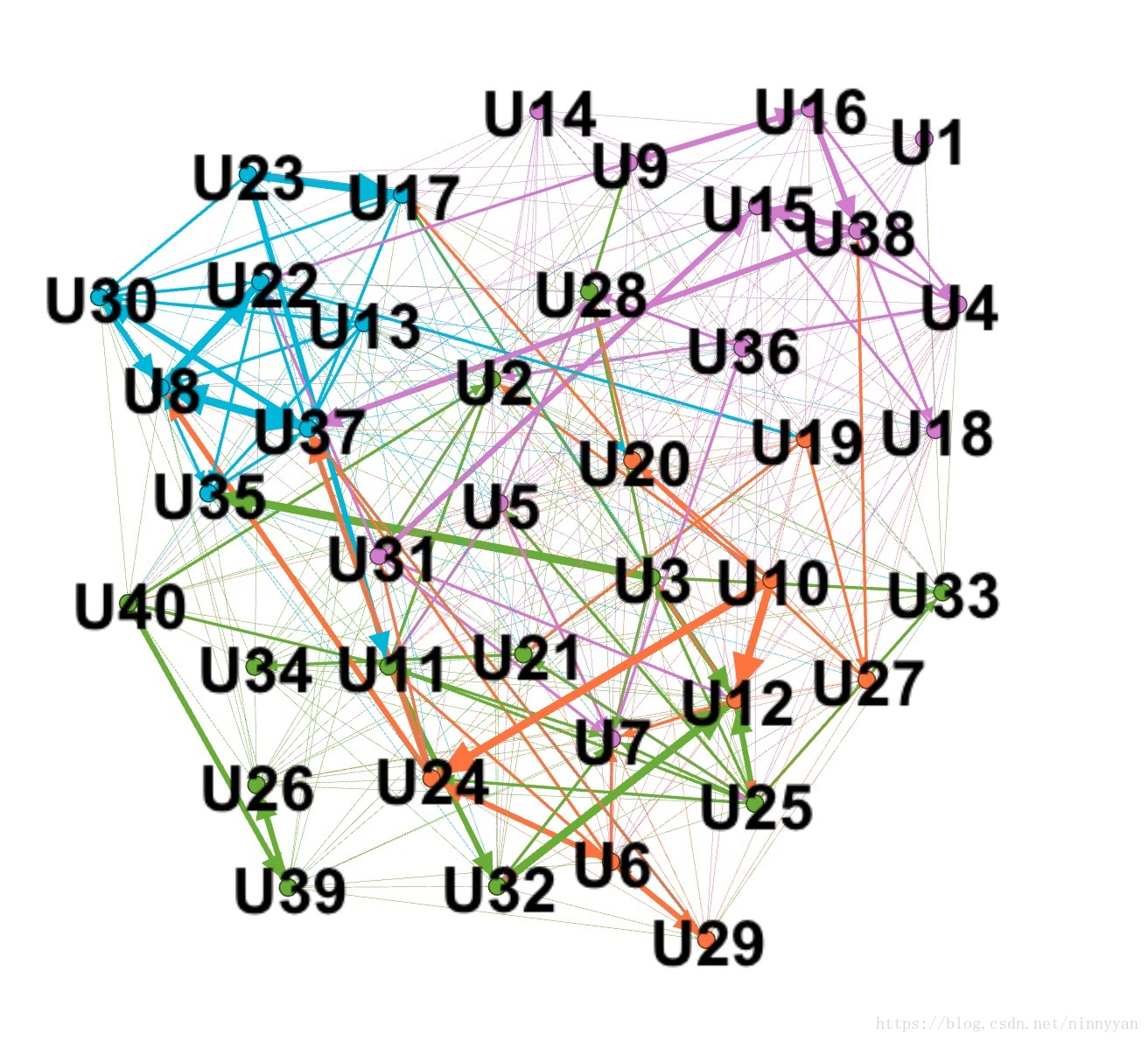
这部分使用node之间的关系,将40个人组成的小社团之间的社交关系进行了分析,生成node文件和edge文件,并导入到Gephi中,绘制出他们之间的社交关系网络图。
代码如下:
import networkx as nx
import csv
h = nx.DiGraph()
for i in range(1,41):
h.add_node(i)
blog = list(csv.reader(open('blogpost4.csv','r')))
for i in range(1,len(blog)):
line = blog[i]
for j in range(len(line)):
if line[j] !='0':
h.add_edge(i,j+1,weight=int(line[j]))
with open('edges.csv','w') as csvfile:
writer = csv.writer(csvfile)
writer.writerow(['Row','Column','Weight'])
for (u,v,d) in h.edges(data='weight'):
writer.writerow([u,v,d])
with open('N.csv','w') as csvfile:
writer = csv.writer(csvfile)
writer.writerow(['Id','Label'])
for node in h.nodes():
writer.writerow([int(node),'U'+str(node)])
with open('E.csv','w') as csvfile:
writer = csv.writer(csvfile)
writer.writerow(['Source','Target','Type','Weight'])
for (u,v,d) in h.edges(data='weight'):
writer.writerow([u,v,'Directed',d])
print 'density:',nx.density(h)
avg_indegree = 0
for key,value in nx.in_degree_centrality(h).items():
avg_indegree = avg_indegree + value
if key == 33:
print 'My own in-degree:',value
avg_indegree = float(avg_indegree/40)
print 'avg_indegree:',avg_indegree
#print 'outdegree centrality',nx.out_degree_centrality(h)
avg_outdegree = 0
for key,value in nx.out_degree_centrality(h).items():
avg_outdegree = avg_outdegree + value
if key == 33:
print 'My own out-degree:',value
avg_outdegree = float(avg_outdegree/40)
print 'avg_outdegree:',avg_outdegree
#print 'betweenness centrality',nx.betweenness_centrality(h)
avg_betweenness = 0
for key,value in nx.betweenness_centrality(h).items():
avg_betweenness = avg_betweenness + value
if key == 33:
print 'My own betweenness centrality:',value
avg_betweenness = avg_betweenness/40
print 'avg_betweenness:',avg_betweenness
#print 'closeness centrality:',nx.closeness_centrality(h)
avg_closeness = 0
for key,value in nx.closeness_centrality(h).items():
avg_closeness = avg_closeness + value
if key == 33:
print 'My own closeness centrality',value
avg_closeness = avg_closeness/40
print 'avg_closeness:',avg_closeness
社交关系图如下: