1. SquezeeNet
论文地址:
SQUEEZENET: ALEXNET-LEVEL ACCURACY WITH 50X FEWER PARAMETERS AND <0.5MB MODEL SIZE
1.1 论文导读
小型网络模型的优点:
- 有利于分布式训练,减少数据交换量
- 模型变小,对客户端的更新更便捷
- 更容易在FPGA上进行部署
相关工作:
模型压缩:SVD,Network Pruning,quantization,huffman encoding
CNN 微架构:LeCun(5x5),VGG(3x3),NIN(1X1),Inception module,ResNet Module
CNN宏观架构:Deeper(VGG),ResNet,bypass connections
三条设计准则
- 将3x3的filters替换成1x1
- 减少3x3滤波器的输入通道数
- 延迟和减少下采样以获得更多激活map,即网络前期尽量使stride为1
SquezeeNet
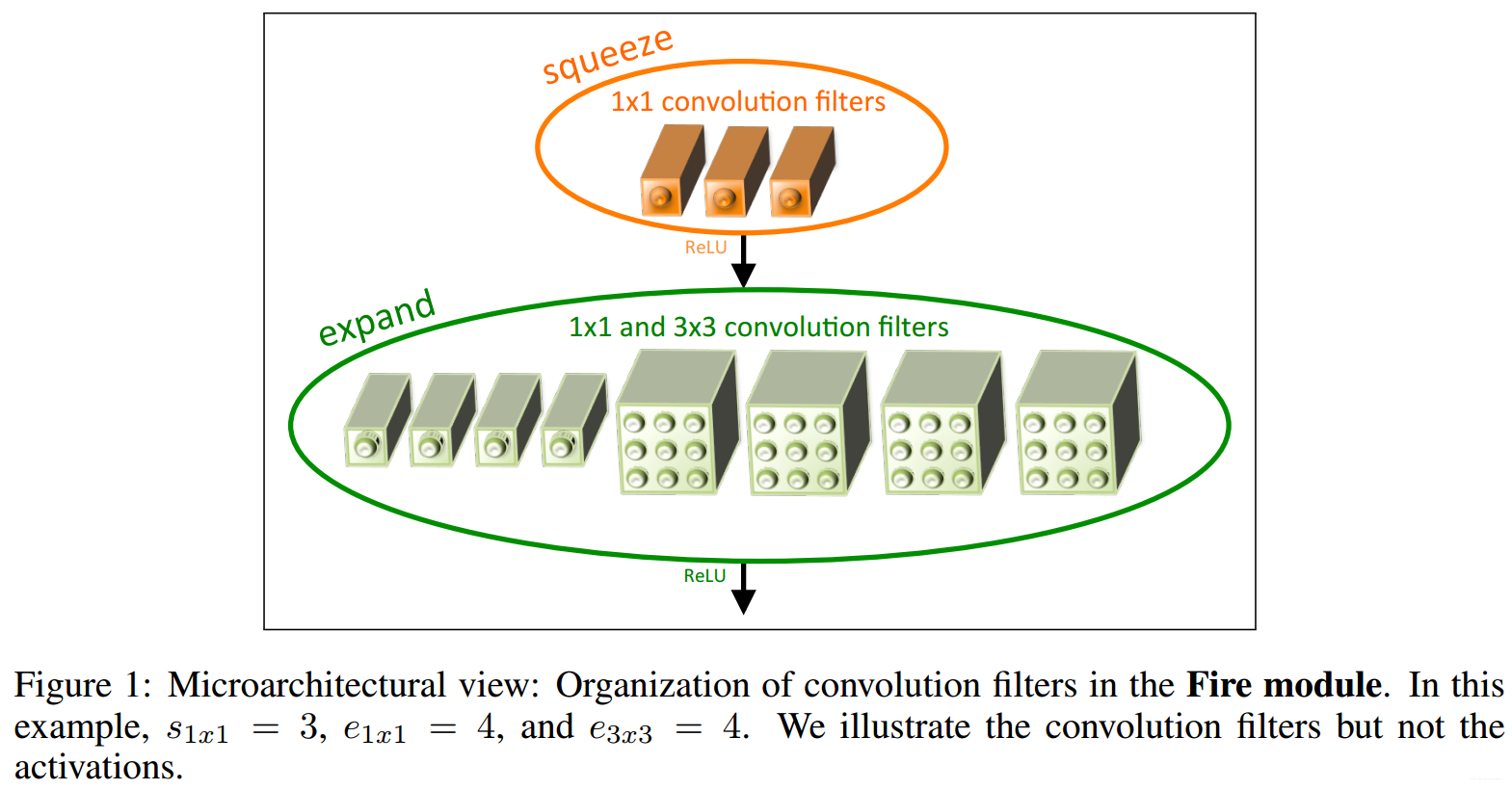
如上图所示,Fire module分为两个模块,squeeze模块由S1x1个1x1大小的滤波器组成,呼应设计准则1,expand层由e1x1个1x1大小的滤波器和e3x3个3x3大小的滤波器构成,同时保证S1x1 < e1x1+e3x3,呼应设计准则2。
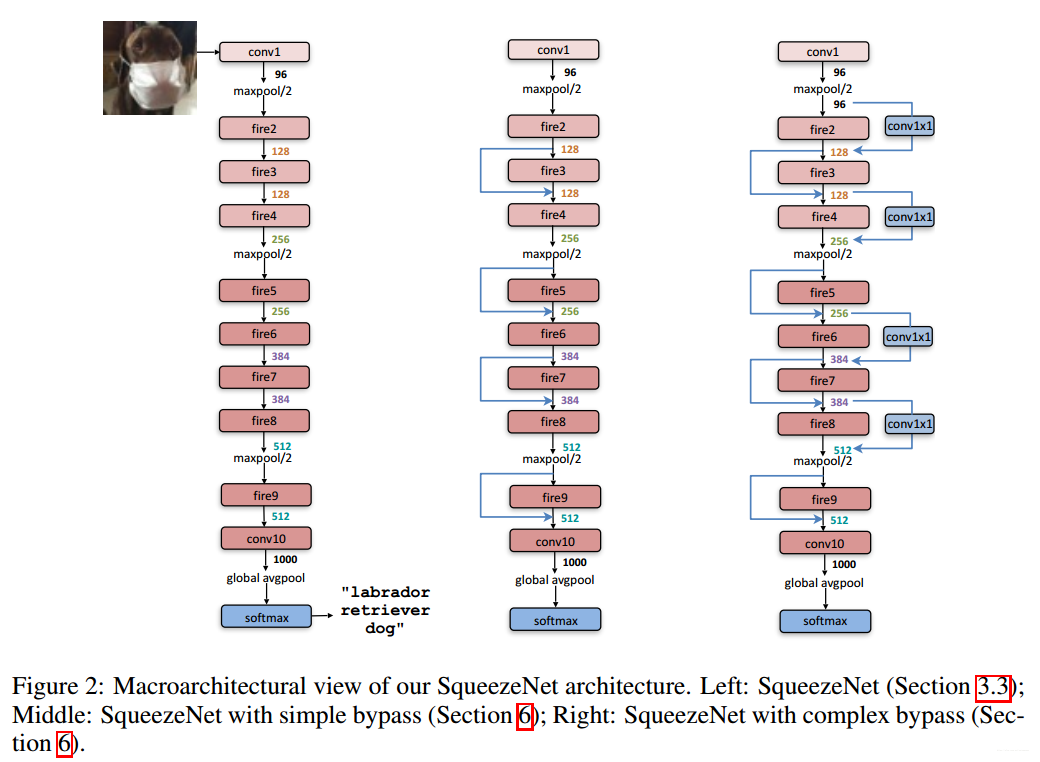
具体网络设计如上图(左边的模型),模型间很少采用pooling层,呼应设计准则3
在fire9之后有dropout为0.5,补零padding为1,初始学习率为0.04
SquezeeNet的压缩
使用韩松的Deep Compression 算法,采用6-bit的参数量化和33%的稀疏,最终模型大小为0.47MB (510×
smaller than 32-bit AlexNet),并且算法准确度并没有损失。
SquezeeNet宏观模型调优
如figure2所示,有三种模型,普通SquezeeNet,加入简单的bypass的SquezeeNet,加入复杂的bypass的SquezeeNet,简单的bypass是将值进行直接相加,并没有增加通道数,而复杂的bypass则通过加入若干个1x1的卷积核实现通道数的增加,增加了信息量,在一定程度上可以弥补S1x1模块造成的信息减少,但是结果证明,简单的bypass的SquezeeNet反而效果最好,这一点作者估计也是懵逼吧!
SquezeeNet微观模型调优
超参数SR(S1x1/(e1x1+e3x3)), pct (e3x3/(e1x1+e3x3) , base_e为第一个fire module的
数值
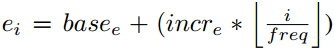
最终实验选择:
= 128,
= 128, pct = 0.5, freq = 2, and SR = 0.125
2. MobileNet
2.1 论文导读
deepwise分离卷积层
将传统的卷积层N个DxDxM分解为两个卷积:M个DxDx1,N个1x1xM,减少了参数量,并减少了八到九倍的计算量!
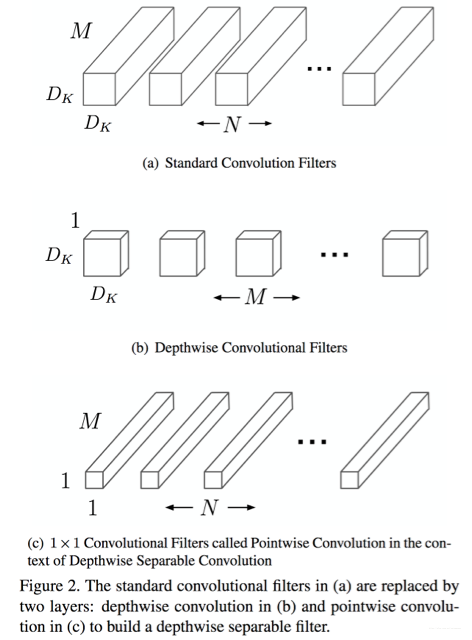
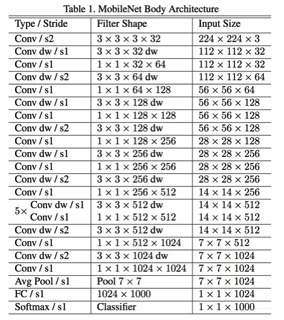
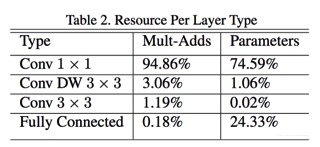
网络架构
每个deepwise分离卷积层间都有relu和BN计算

Width Multiplier : 更瘦的网络
定义一个超参数卷积宽度乘法因子a,参数取值为0.25,0.5,0.75,1,减少卷积的个数,这样做能减少
的参数量与计算量:
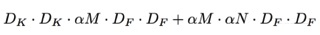
Resolution Multiplier : 通过缩小图片减少特征
定义一个超参数分辨率乘法因子p,p取值为0~1,具体输入图像分辨率为128,160,192,224。
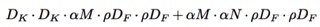
Fine Grained Recognition:
**训练技巧:
1. 用噪声较大的大数据库进行pretrain,然后用精确的小数据库进行finetune!
2. 利用较大规模精确度较高的模型网络的结果数据进行训练,这样的好处在于数据量可以无限大,且训练时不太需要考虑正则化!