
DSP芯片的出现,是为了解决大量的数字运算问题。通过集成专用的加法器、乘法器、地址产生器、复杂逻辑等硬件单元,DSP能实现比普通单片机更快速的数字运算,使处理器更适用于实时性高、复杂度强的处理场合。也正因为如此,DSP编程中非常重要的一环就是让代码尽可能高效地运行。
本文基于TI C6000硬件架构,针对C语言编程,介绍其中主要的代码优化方法。
指导方针
在做优化前,当建立以下几点信念:
-
循环最重要。显然,几乎所有耗时的运算都是在循环中进行,我们几乎可以说:代码的优化就是对循环的优化。
-
最坏原则。TI CCS编译器集成有优化器,能对C/C++代码以及汇编代码进行性能优化。但是过度的优化可能会导致程序运行错误,因此在缺少信息的情况下,编译器总是抱着最坏的打算进行优化,以优先保证程序的正确性
-
如果说TI提供的硬件架构和编译器优化工具是一把锤子,那编程者就应该让代码用起来像钉子。
-
高度优化的c/c++代码性能可以非常接近手写的汇编代码。由于汇编代码的复杂性,我们可以优先选择C/C++进行程序编写。图1为TI提供的各编程语言及其优化版本间的运算性能比较示意图。
图1 各语言优化前后的性能对比
-
优化并不是必须的,一般我们可以通过如图2所示的四个进阶的开发阶段,来判断对程序进行何种程度的优化。
图2 DSP 程序开发的一般过程
实用工具
如前面“锤子”与“钉子”的比喻,编程者的优化工作是尽可能地使代码能被处理器的功能单元、编译器等“锤子”充分运用,所以有必要先对它们建立基本的认识。
1. 高性能的C6000 DSP 架构
8个并行的功能单元,2组寄存器,分离的程序和数据存储;256bit取指包,能一次取指8个32bit的指令;2路64bit的数据加载/存储。这些都指向一个核心——并行处理。
图3 C6000 DSP 架构
2. C6000流水线
一个指令操作的完成实际上要经历取指、译码、执行三个阶段的多个过程才能实现,TI提供软件流水编排来让多个“工种”同时对多个操作进行流水式的处理,大大提高了运算的吞吐能力。
C64x+, C674x和 C66x系列内核还增加了软件流水循环缓存(SPLOOP buffer)单元,使得软件流水能更快速地加载数据,并可以被暂时打断。
However, the SPLOOP buffer cannot be used to handle loops that exceed 14 execute packets
For complex loops, such as nested loops, conditional branches inside loops, and function calls inside loops, the effectiveness of the compiler may be compromised.
3. SIMD(Single Instruction, Multiple Data)
C6000支持单指令多数据存取,仅一条指令,就能一次性操作64bit的数据,这64bit可以由多个双字/字/字节数据组成。
4. C6000 C Compiler
编译器是代码优化工作的最终执行者,它分析代码的相关信息,并做出优化的决策。但有时,编译器无法仅通过分析代码获得一些对于优化很重要的信息,这时编程者主动提供必要的信息给编译器就显得非常重要。
我们可以通过编译选项、关键词以及pragma编译指示来告知编译器和优化有关的信息。同时,还可以利用编译器的优化返回信息,进一步调整优化策略。
5. 其它
- 内嵌函数
TI提供一套内嵌函数供编程者调用,内嵌函数由一些特定的指令组成,配合DSP芯片的硬件函数功能单元,能高效地完成一些用C语言很难完成的复杂操作。
The intrinsic operations are not function calls (though they have the appearance of function calls), so no branching is needed.Instead, the use of intrinsic is a way to tell the compiler to issue one or more particular instructions of the C6000 instruction set.
- 优化的库函数
TI也将一些通用的运算模块封装成库函数,这些库函数都经过了深度的优化,能特别高效地完成相应的运算。
优化策略
1. 选择合适的编译选项(介绍部分)
- -o0/1/2/3:最重要的优化选项;如果选择了-o3,编译器将会尽可能尝试所有可行的优化手段,但有时也可能会使得优化后的程序出现错误。-o0和-o1将不会产生优化错误,但优化的性能则大大降低。
- -g:允许编译器插入符号调试信息,它在开发调试阶段是非常好的工具,但在最终产品代码编译中应避免使用,因为它会减少并行处理指令,并占用额外的代码空间,极大地影响代码性能。
- -mt:指示编译器,应用中所有的函数中的指针参数都不指向同一个地址,但它只作用于函数参数中的指针,对函数内部的本地指针无效。
- -k和-mw:这两个选项与最终代码性能无关,但利用他们可以获得编译器的优化反馈信息,帮助编程者调整优化策略。-k选项保留编译器的汇编输出;-mw输出软件流水的相关信息
2.“restrict”关键字
restrict的作用和-mt编译选项相似,它告诉编译器某个指针不会和函数中的其它指针指向同一个内存。
the restrict keyword can be applied to any pointers, regardless of whether it is a parameter, a local variable, or an element of a referenced dataobject. Moreover, because the restrict keyword is only effective in the function it is in, it can be used whenever needed

注意:“restrict”关键字也不能随便乱加,我们需要了解C6000的片上内存组成,只有当两个指针所指的内存在不同的block里时,restrict才是合法的。
3. 通过编译指示(pragma)提供信息
可以在代码中插入一些特定语法的编译指示指令,来告知编译器有关代码的一些信息。因为编译器在缺少信息的情况下,总是以最坏的打算来优化代码,如果编程者能提供一些关键信息,会大大帮助编译器做出好的决策。最常用的有MUST_ITERATE和UNROLL两种。
- MUST_ITERATE:提供关于循环次数的一些确切信息:最小可能循环次数、最大可能循环次数以及循环次数为某个factor的倍数。它的使用语法如下:
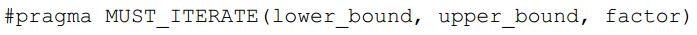
 当不能确定某些参数时,允许对其缺省:
当不能确定某些参数时,允许对其缺省:

- UNROLL:展开指示告诉编译器可以对循环代码进行适当的展开,其使用语法如下:
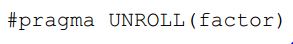
在展开指示之前,也最好用MUST_ITERATE指令告诉编译器循环次数为展开系数的倍数,这样可以避免产生额外的代码来处理异常情况,如:

展开的好处有两点:一是使得编译器可以更加均衡地利用各运算单元;二是编译器有更多的机会使用SIMD指令。但有一点需要注意的是:展开将会使得循环体增大。
4. 循环体优化的注意事项
循环的优化关键在于使得循环能够被编排成软件流水。
For complex loops, such as nested loops, conditional branches inside loops, and function calls inside loops, the effectiveness of the compiler may be compromised. When the situation becomes too complex, the compiler might not be able to pipeline at all.
-
编译器仅对内部循环执行软件流水。
-
软件流水循环可包含instrinsics,但不能包含函数调用。
-
循环结构中不可有break和goto语句,不可有条件中止,使循环提前退出的指令。
-
条件代码应尽量简单,在C64XX中,条件代码需要超过6个寄存器时,循环不可进行软件流水。
-
避免循环体内容过于复杂,造成寄存器组不够用。
-
如果要求一个寄存器的生命太长,这个代码不能进行软件流水。
-
循环结构中不要包含改变循环计数器数值的代码。
5. 使用SIMD并行处理多个数据的运算
TI 提供了多个支持SIMD的指令,如LDDW、STDW,分别用于并行64bit的数据加载和存储。
Assuming all the data used are actually 16-bit data, it would be ideal if the LDDW and STDW instructions can operate on 4 elements every time. However, if thedata is declared as 32-bit type, LDDW and STDW can only operate on 2 elements every time. Therefore,to fully utilize SIMD instructions, it is important to choose the smallest data size that works for the data.
尽管C64x+, C674x, C66x内核支持对非对齐的数据使用SIMD指令,但当数据量比较大时,还是应该尽量保证数据是边界对齐的,这样可以充分地进行并行存取。
6. 尽可能使用内嵌函数
内嵌函数来直接调用C6000的汇编操作,而这些操作往往用C语言实现很复杂。
The intrinsic operations are not function calls (though they have the appearance of function calls), so no branching is needed.Instead, the use of intrinsic is a way to tell the compiler to issue one or more particular instructions of the C6000 instruction set.
7. TI库函数
针对常见的运算,TI提供了高效的实现库函数,包含基础的通用模块如图4。当然,针对一些专用领域(如图像视频、通信等),也会有对应的库函数,这些库函数都经过了深度的优化,运行是非常高效率的。

图 4 TI基础库函数类别
8. 使用内联函数代替函数调用
内联函数(Inline Function)是C语言语法的一种,它的定义类似于普通的函数定义,但编译器在处理它的时候并不把它当函数对待,而是把它的函数体自动嵌入到被调用处。
由于在循环体中,函数调用将会影响到软件流水的编排,并且产生调用开销,用内联函数代替函数调用是个不错的选择。
但是注意:内联函数将可能增加代码的尺寸,应避免内联函数体过大或被频繁调用。
9. 尽可能使用逻辑运算代替乘除运算
乘除运算指令的执行时间要远远超过逻辑移位指令,尤其是除法指令,在设计的时候,可以根据实际情况,进行一些调整,尽量用逻辑移位运算来代替乘除运算,这样可以加快指令的运行时间。
参考文献/资料
【1】Introduction to TMS320C6000 DSP Optimization--SPRABF2,2011.
【2】TMS320C6000 Programmer's Guide--SPRU198K,2011.
【3】董言治, 娄树理, 刘松涛. TMS320C6000系列DSP系统结构原理与应用教程[M]. 清华大学出版社, 2014.
【4】TI C6000 优化 startup guide.
【5】Optimization Techniques for the TI C6000 Compiler.
【6】Optimizing Modems Using Code Composer Studio and TI Resources.
·END·
想进一步跟踪本博客动态,欢迎关注我的个人微信订阅号:信号君
信号君:寻求简单之道
技术成长 | 读书笔记 | 认知升级

扫描二维码关注信号君