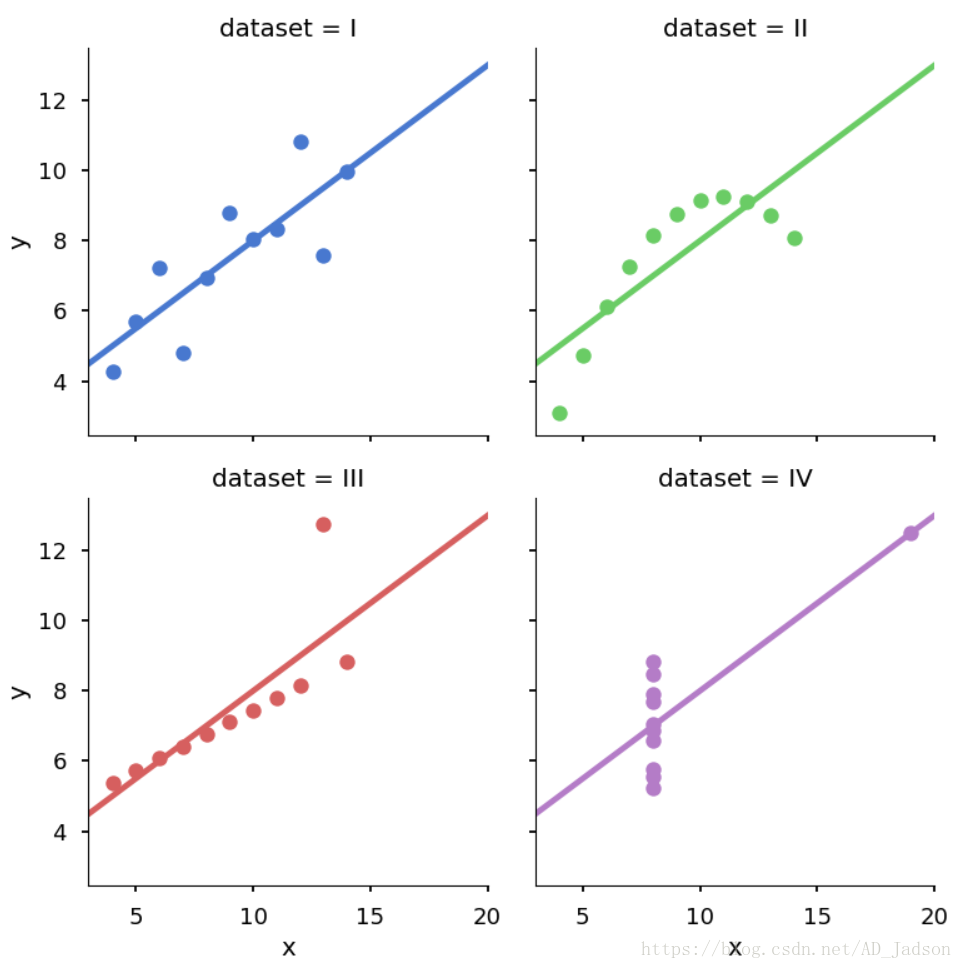
Anscombe's quartet
Anscombe's quartet comprises of four datasets, and is rather famous. Why? You'll find out in this exercise.
模块:
import random
import numpy as np
import scipy as sp
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import statsmodels.api as sm
import statsmodels.formula.api as smf
sns.set_context("talk")
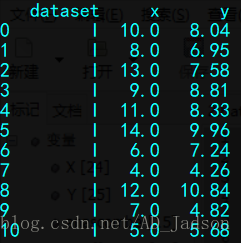
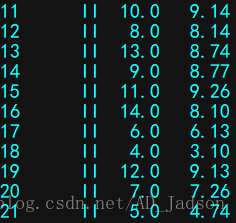
数据:
anascombe = sns.load_dataset("anscombe")
print(anascombe)
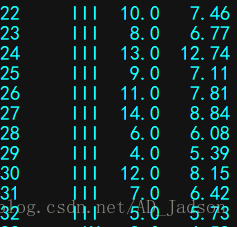
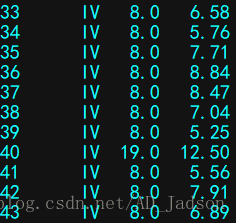
Part1
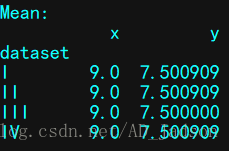
计算均值、方差:
print("\nMean:")
print(anascombe.groupby("dataset").mean())
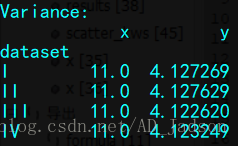
print("\nVariance:")
print(anascombe.groupby("dataset").var())
结果:
扫描二维码关注公众号,回复:
1573818 查看本文章

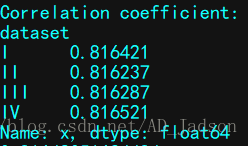
计算相关系数:
print("\nCorrelation coefficient:")
print(anascombe.groupby("dataset").x.corr(anascombe.y))
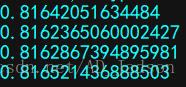
或
X = []
Y = []
coefficients = []
for i in range(0, 4):
X.append(anascombe.x[i*11:i*11+11].values)
Y.append(anascombe.y[i*11:i*11+11].values)
coefficients.append(sp.stats.pearsonr(X[i], Y[i])[0])
print(coefficients[i])
结果:
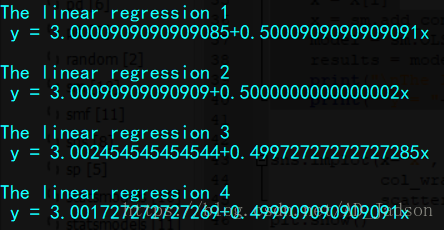
计算线性回归方程:
for i in range(0,4):
x = X[i]
x = sm.add_constant(x)
model = sm.OLS(Y[i], x)
results = model.fit()
print("\nThe linear regression " + str(i+1))
print(" y = "+str(results.params[0])+"+"+str(results.params[1])+"x")
结果:
Part2
散点图及回归直线:
sns.lmplot(x="x", y="y", col="dataset", hue="dataset", data=anascombe,
col_wrap=2, ci=None, palette="muted", size=4,
scatter_kws={"s": 80, "alpha": 1})
plt.show()