很多博友看了我的第一篇博客yolo类检测算法解析——yolo v3,对其有了一定的认识和了解,但是并没有贴出代码和运行效果,略显苍白。因此在把篇博客理论的基础上,造就了第一篇实践文章,也就是本文。只要读者有着强大的理论支撑,什么模型什么框架都是一样玩。所以老师又会跟你说哲学和科学、科学和技术存在如何的关联,尽管很抽象,但是没有人反驳过就像有这么多的编程语言,各有特色,最后也都干了相同或相似的事,那么多的框架,各有千秋,最后也都干了相同或相似的事。又或者说反了,是因为它们都想干相同或相似的事,而又有着不同的实现方法,最后形成了那么多的框架和语言,也许这就是All roads lead to Rome的道理。虽都是通往罗马的路,但是每条路的特征不一样,存在即合理......
yolov3的实践篇必须向读者介绍两个很好用的开源项目,面向Windows开发用户而设计,而它们都来源于同一个作者,也就是AlexeyAB,作者的奉献推动了yolo系列算法的研究和推进,在此仅以绵薄的文字表达对作者的敬仰之意。本篇博客主要是介绍、安装和使用这两个项目的入门介绍。
两个项目:
1. Yolo_mark
这是在yolo项目下作者创建的标注项目,就是把图片集标注成一个txt文件,如下:
0 0.498437 0.481499 0. 117188 0.175000
第一位是类ID,表示为0具体代表的是啥,请看相应的.names文件,然后接下来四个小数字代表的是bbox和图片分辨率的关系,具体说明一下:
yolo中用到的GT都是bbox中心点坐标,但是光有中心点坐标是不能准确定位一个框的,所以需要两个辅助的坐标,自然就是框的宽和高,并对其归一化处理;而在预测环节,如果用相对anchor box的绝对值坐标,同一目标相对anchor的位置受参数影响变化很大,模型收敛困难,因此论文通过相对网格点的偏移固定bbox中心点,并通过先验anchor box预测bbox的宽和高,这样的话,可以概括为:
#GT:假设bbox的中心点坐标为(x,y);bbox的宽和高分别为(w,h);图片分辨率为(u,v),本来的坐标是(x,y,w,h);归一化后的坐标是:(x/u, y/v, w/u, h/v) #Pr:(x,y,w,h)通过建立相对网格点和anchor box的位置关系获得。
#同理,上述推理也很容易求得bbox矩形框的坐标,画出最终的检测结果。
曾经我也试用了一下,感觉还是很不错的,感兴趣的可以写一个标注的工具分享给大家。
如何编译和使用,项目介绍里写得很清楚;需要将opencv的依赖配置到项目属性中,编译过程中可能会遇到如下错误:
- 找不到highgui.hpp:这个错误是由于头文件地址不对,把highgui.hpp的地址改为#include<opencv2/highgui/highgui.hpp>。
- snprintf()函数报错:在Windows系统中该函数其实是_snprintf,但是编译器提示最好用_snprintf_s()函数替代。
2. darknet
这个项目才是最重要的。首先第一步就是配置darknet。本文的环境是cuda8.0和cudnn7。首先需要打开darknet项目的vcxproj文件,修改cuda版本,否则会无法加载darknet项目。修改9.1 为8.0,如图:

紧接着打开darknet项目解决方案,配置项目属性。
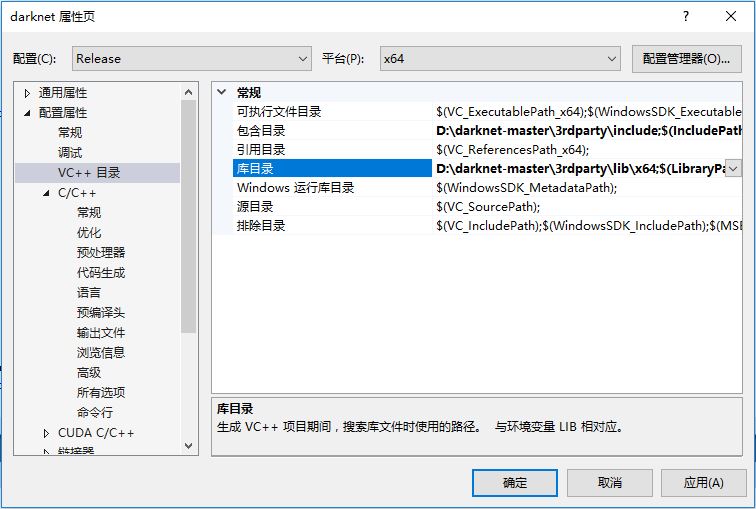
- 配置第三方库,如图所示。
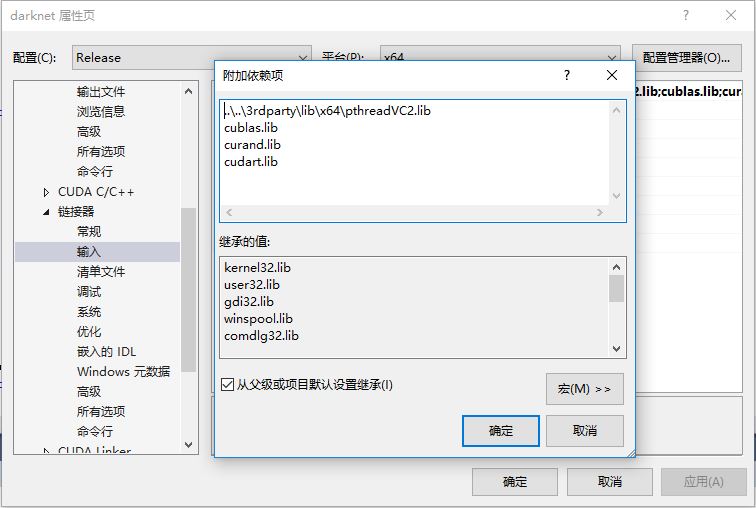
- 配置opencv,步骤同上,include,lib,如果配置好就不需要再配了,此处省略。
- 预编译器定义。

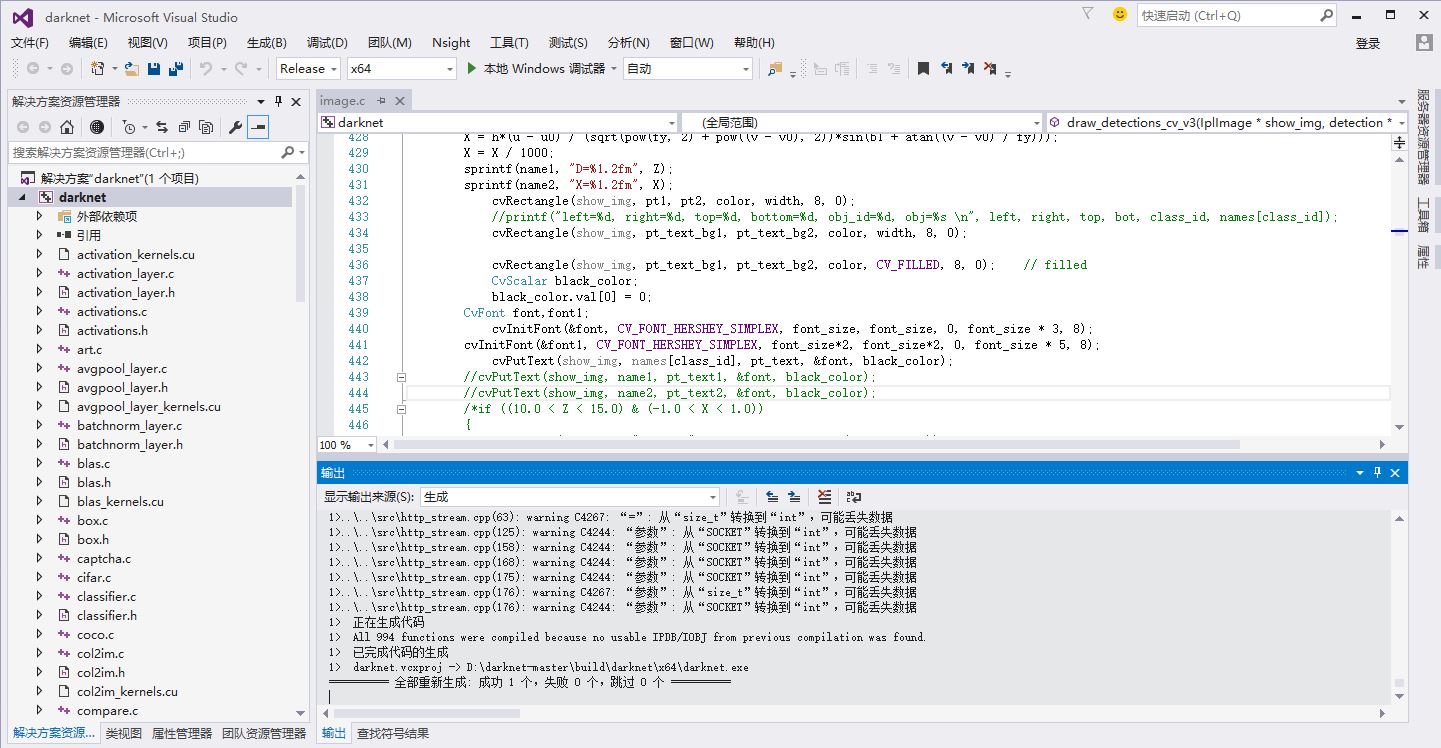
接下来就可以build该项目了,如图所示:
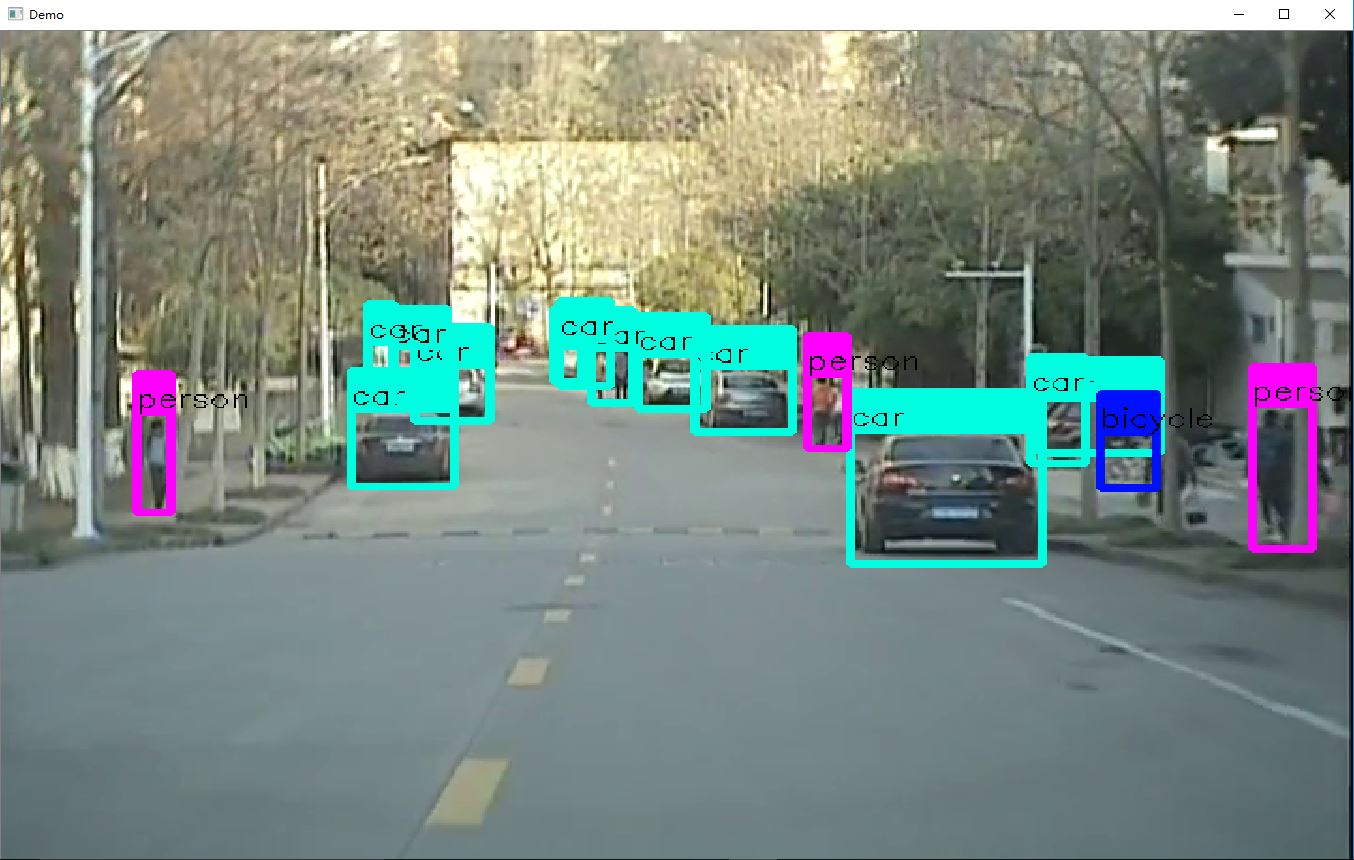
成功之后,就是和之前的yolo版本一样用了,Ubuntu的也是,代码也是差不多。下面测试一下其性能:
测试视频:darknet.exe detector demo data/coco.data yolov3.cfg yolov3.weights -i 0 -thresh 0.25 test.mp4

测试图片:darknet.exe detector test data/coco.data yolov3.cfg yolov3.weights -i 0 -thresh 0.25 test.jpg

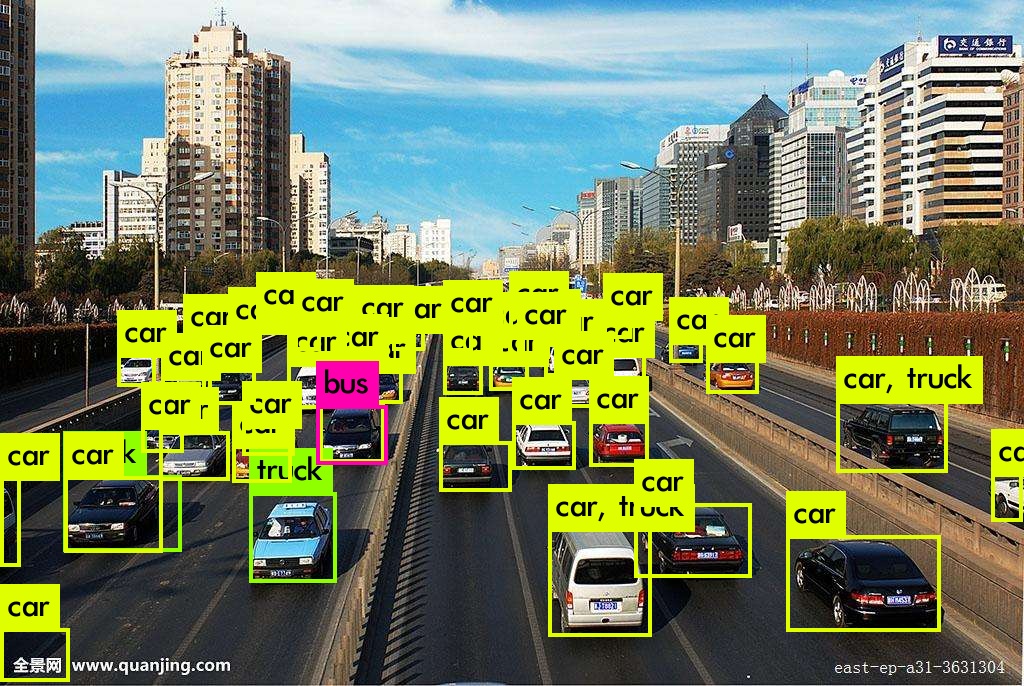
测试USB摄像头:darknet.exe detector demo data/coco.data yolov3.cfg yolov3.weights -i 0 -thresh 0.25 -c 0
忘截图了,如果USB摄像头无法调用,第一步确保电脑相机可以打开,第二步尝试更换-c 后面的编号,第三步参考USB摄像头无法正常读取问题。
最后,重要的部分,yolo里面有几个源代码文件对应于上面的测试,具体请看:darknet.c(主程序)解析第一个输入的关键字指令,比如上面的detector,然后执行run_detector(int argc, char **argv)这个函数,接着跳到detector.c,继续解析命令行关键指令,比如上面的demo和test和后面跟着的配置参数如cfg,data,weight等等,重点是demo跳到
demo(cfg, weights, thresh, hier_thresh, cam_index, filename, names, classes, frame_skip, prefix, out_filename, http_stream_port, dont_show);
就到了demo.c里面,test就跳到test_detector(datacfg, cfg, weights, filename, thresh, hier_thresh, dont_show)函数了。还有image.c,detection_layer.c,utils.c,data.c等等。