1。介绍


TensorFlow是一个多用途的机器学习框架。TensorFlow可用于在云中跨群集培训庞大模型的任何地方,以及在您的手机等嵌入式系统上本地运行模型。笔者: csdn -固本培元 交流邮箱: [email protected] 微信:leoluopy 。 本文机器翻译加人工矫正,可能有翻译不当之处,欢迎讨论,相互学习。 外文原文:https://codelabs.developers.google.com/codelabs/tensorflow-for-poets-2-tflite/index.html#0
注意:这个codelab使用新的移动优化的TensorFlow Lite。如果您正在寻找更加稳定和成熟的移动TensorFlow,请参阅此版本的codelab。
如果您不确定要使用哪个,请参阅此概述。
你会学到什么
- TensorFlow for Poets:如何训练自定义图像识别模型。
- 如何使用TFLite转换器优化您的模型。
- 如何使用TFLite解释器在预制的Android应用程序中运行它。
你会做些什么
一个简单的相机应用程序,运行TensorFlow图像识别程序来识别花朵。
注意:目前,此演示中使用的AAR与Android模拟器不兼容,您必须使用真正的Android设备才能运行该应用程序。

CC-BY by FelipeVenâncio
2。环境准备
这个codelab大部分将使用终端。现在打开它。
安装TensorFlow
在我们开始本教程之前,您需要安装tensorflow。
这个codelab还使用PILLOW软件包,您可以将它安装在:
pip install PILLOW
如果你有第一个codelab的git仓库
这个codelab使用TensorFlow for Poets 实验室生成的文件。如果你还没有完成那个codelab,我们建议你现在就去做。如果您不愿意,下一小节会提供下载缺失文件的说明。
在针对诗人1的TensorFlow中,您还克隆了此代码实验的相关文件。确保它是您当前的工作目录,签出分支并检查内容,如下所示:
cd tensorflow-for-poets-2 ls
这个目录应该包含其他三个子目录:
- 该
android/tflite目录包含构建简单Android应用程序所需的所有文件,这些应用程序使用TFLite在图像从相机读取图像时进行分类。您将用您的自定义版本替换模型文件。 - 该
scripts/目录包含您将在整个教程中使用的python脚本。这些包括准备,测试和评估模型的脚本。 - 该
tf_files/目录包含您应该在第一部分中生成的文件。至少你应该有以下文件包含重新培养的tensorflow程序:
ls tf_files /
retrained_graph.pb retrained_labels.txt
否则(如果您没有第一个Codelab的文件)
克隆Git存储库
以下命令将克隆包含此codelab所需文件的Git存储库:
git clone https://github.com/googlecodelabs/tensorflow-for-poets-2
现在进入你刚刚创建的克隆目录。这就是你将为这个codelab的其余部分工作的地方:
cd tensorflow-for-poets-2
repo包含三个目录:android/,scripts/, and tf_files/
检出end_of_first_codelab分支中的文件
git checkout end_of_first_codelab ls tf_files
3。测试模型
接下来,在开始修改模型之前,请验证该模型是否产生了理智的结果。
该scripts/目录包含一个简单的命令行脚本label_image.py,用于测试网络。现在我们将测试label_image.py这张雏菊的照片:

flower_photos/daisy/3475870145_685a19116d.jpg
图片CC-BY,由Fabrizio Sciami发布
现在测试模型。如果您使用不同的体系结构,则需要设置“--input_size”标志。
python -m scripts.label_image \ --graph = tf_files / retrained_graph.pb \ --image = tf_files / flower_photos / daisy / 3475870145_685a19116d.jpg
该脚本将打印模型分配给每种花型的概率。像这样的打印:
Evaluation time (1-image): 0.140s daisy 0.7361 dandelion 0.242222 tulips 0.0185161 roses 0.0031544 sunflowers 8.00981e-06
这应该有希望为您的示例生成一个明智的顶级标签。您将使用此命令确保您仍然可以获得明智的结果,因为您在模型文件上进一步处理以准备在移动应用程序中使用它。
4。优化模型
移动设备有很大的局限性,因此可以通过预处理来减少应用程序的占用空间。通过TFLite,TensorFlow安装中新增了一个图形转换器。这个程序被称为“ TensorFlow Lite优化转换器 ”或TOCO。
它以TensorFlow作为命令行脚本安装,因此您可以轻松访问它。要检查您的机器上是否正确安装了toco,请尝试使用以下命令打印TOCO帮助:
toco - help
我们将使用toco优化我们的模型,并将其转换为TFLite格式。toco可以在一个步骤中做到这一点,但我们会做到这一点,以便我们可以在两者之间尝试优化模型。
优化模型
虽然toco具有处理量化图的先进功能,但它也队我们正在使用的计算图做相应的优化(不使用量化)。其中包括删除未使用的图形节点,连接计算图中的操作器形成更高效的混合计算图
鉴于TFLite尚不支持训练操作,修剪尤其有用,因此这些不应包括在图表中。
在此模型上,性能优化可以在使用“scripts / label_image.py”进行测试时将单个图像的运行时间缩短一半以上。
以下命令将优化我们的模型。请注意,IMAGE_SIZE变量设置为默认值224.(如果在第一部分中选择了期望不同大小输入的网络,请更改此值)。
IMAGE_SIZE=224
toco --input_file=tf_files/retrained_graph.pb \
--output_file=tf_files/optimized_graph.pb \
--input_format=TENSORFLOW_GRAPHDEF \
--output_format=TENSORFLOW_GRAPHDEF \
--input_shape=1,${IMAGE_SIZE},${IMAGE_SIZE},3 \
--input_array=input \
--output_array=final_result
运行这个脚本将创建一个新文件tf_files/optimized_graph.pb。
验证优化的模型
要检查TOCO 没有改变网络label_image输出,请比较以下输出retrained_graph.pb:
python -m scripts.label_image \ --graph = tf_files / retrained_graph.pb \ --image = tf_files / flower_photos / daisy / 3475870145_685a19116d.jpg
Evaluation time (1-image): 0.281s daisy 0.725841 dandelion 0.200525 tulips 0.0411526 roses 0.0318613 sunflowers 0.000619742
随着optimized_graph.pb:
python -m scripts.label_image \ --graph = tf_files / optimized_graph.pb \ --image = tf_files / flower_photos / daisy / 3475870145_685a19116d.jpg
Evaluation time (1-image): 0.126s daisy 0.725845 dandelion 0.200523 tulips 0.0411517 roses 0.031861 sunflowers 0.000619737
当我运行这些命令时,输出概率没有变化到5位小数,但图像评估运行时间不到一半。
现在运行它来确认您看到类似的结果。
为了进行更彻底的评估,我们可以在整个验证集上运行模型并比较结果。在我们运行优化器之前,首先评估模型的性能。输出的最后两行显示了平均性能。可能需要一两分钟才能获得结果。
注意:如果您开始使用end_of_first_codelab分支,而不是使用 TensorFlow for Poets 主分支,则不会有全套照片。下面的模型评估将失败。您应该:
- 跳到下一节。
- 使用以下命令下载照片(200MB):
卷曲http://download.tensorflow.org/example_images/flower_photos.tgz \
| tar xz -C tf_files
python -m scripts.evaluate tf_files / retrained_graph.pb
对我来说,retrained_graph.pb得分为90.9%,交叉熵误差为0.270(越低越好)。
现在将其与以下模型的性能进行比较optimized_graph.pb:
python -m scripts.evaluate tf_files / optimized_graph.pb
您应该看到模型精度的变化不到1%,或者根本没有变化。
(可选)使用TensorBoard观察更改
如果你遵循第一个教程,你应该有一个tf_files/training_summaries/目录(否则,通过发出以下Linux命令来创建目录:)mkdir tf_files/training_summaries/。
以下两个命令将关闭任何正在运行的TensorBoard实例并启动一个新实例,并在后台观看该目录:
pkill -f tensorboard tensorboard --logdir tf_files/training_summaries &
在后台运行的TensorBoard可能会偶尔向终端发送以下警告,您可以放心忽略
WARNING:tensorflow:path ../external/data/plugin/text/runs not found, sending 404.
现在将您的两张图添加为TensorBoard日志:
python -m scripts.graph_pb2tb tf_files/training_summaries/retrained \ tf_files/retrained_graph.pb python -m scripts.graph_pb2tb tf_files/training_summaries/optimized \ tf_files/optimized_graph.pb
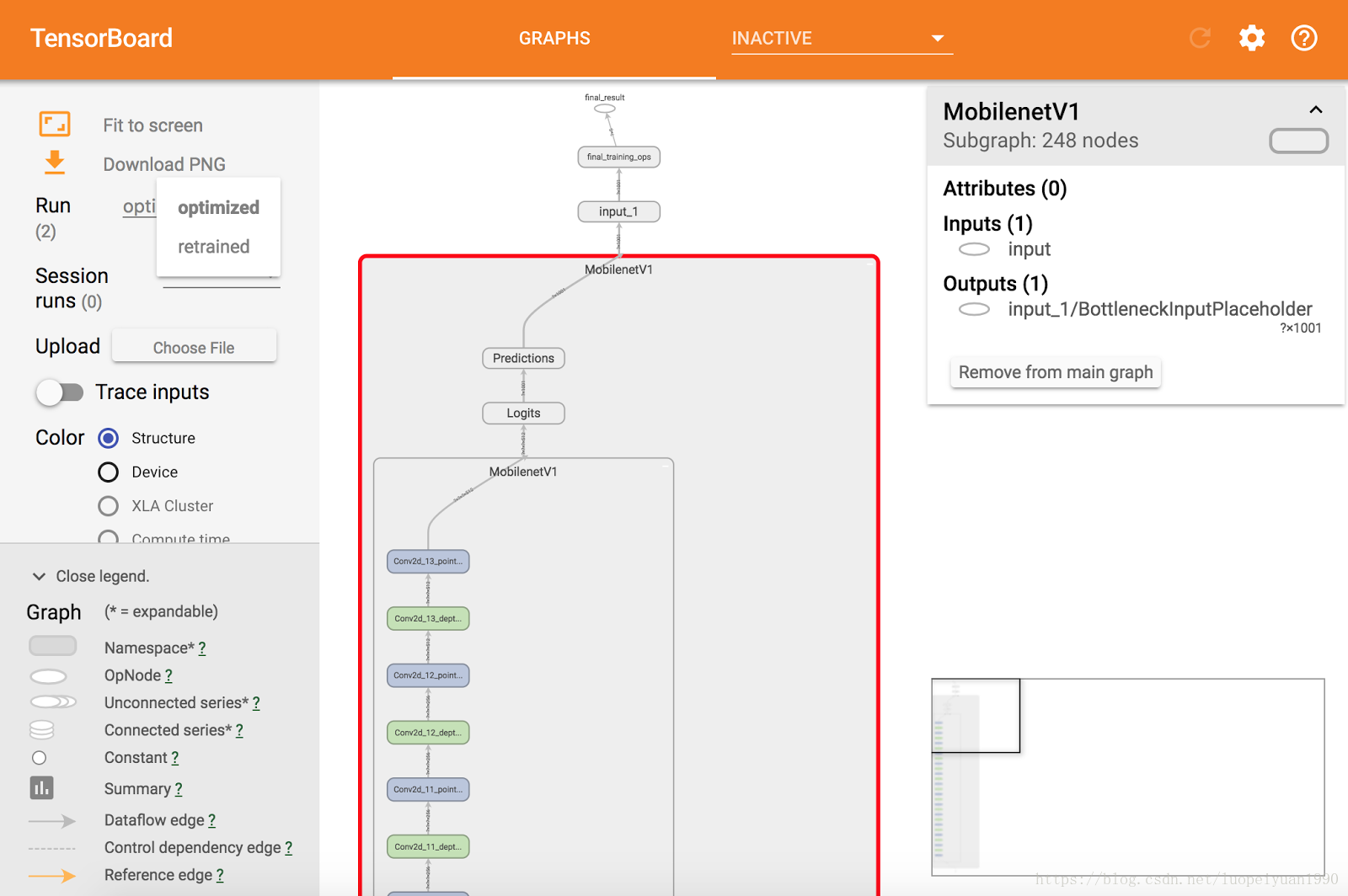
现在打开TensorBoard,默认打开“Graph”选项卡。
从左侧标有“运行”的选取列表中,选择“重新训练”。
稍微探索一下这个图表,你可以通过双击它们来展开各个块。
然后从“运行”菜单中选择“优化”。
从这里你可以确认已经合并了一些节点来简化图形,它应该看起来像这样:
将模型转换为TFLite格式
TFLite使用与常规TensorFlow不同的序列化格式。TensorFlow使用Protocol Buffers,而TFLite使用FlatBuffers。
FlatBuffers的主要优势来自于它们可以被内存映射,并且可以直接从磁盘使用而不需要加载和解析。这提供了更快的启动时间,并为操作系统提供了从模型文件加载和卸载所需页面的选项,而不是在内存不足时清除应用程序。
我们可以使用我们之前用于优化图形的相同命令创建TFLite FlatBuffer,但有两个更改:
- 以TFLite格式输出模型:
- 设置--output_format = TFLITE
- 将--output_file的扩展名设置为“.lite”。
- 告诉TFLite以浮点模式工作(TFLite有我们不使用的量化选项):
- 设置--inference_type = FLOAT
- 设置--input_type = FLOAT
IMAGE_SIZE = 224 toco \ --input_file = tf_files / retrained_graph.pb \ --output_file = tf_files / optimized_graph.lite \ --input_format = TENSORFLOW_GRAPHDEF \ --output_format = TFLITE \ --input_shape = 1,$ {IMAGE_SIZE},$ { IMAGE_SIZE},3 \ --input_array = input \ --output_array = final_result \ --inference_type = FLOAT \ --input_type = FLOAT
这应该在你的“tf_files”目录中输出“optimized_graph.lite”。
5。设置Android应用程序

安装AndroidStudio
如果您尚未安装,请安装AndroidStudio 3.0+。
使用AndroidStudio打开项目
按照以下步骤使用AndroidStudio打开一个项目:
- 打开AndroidStudio 打开一个现有的Android Studio项目”:

- 在文件选择器中,
tensorflow-for-poets-2/android/tflite从您的工作目录中选择。
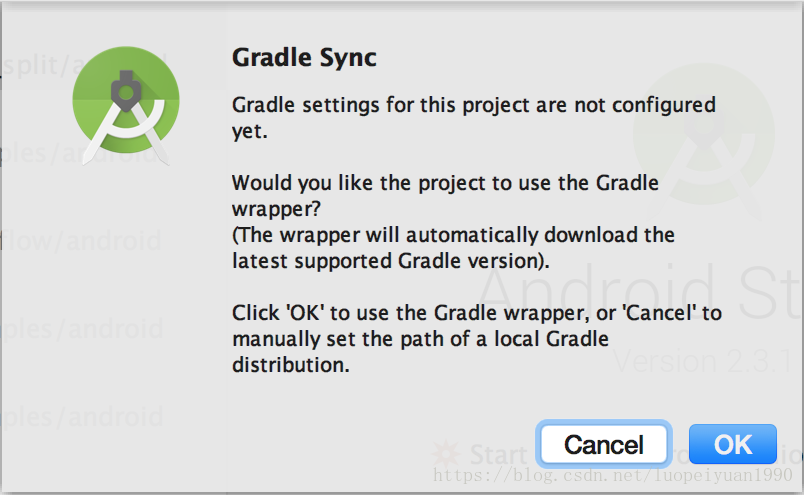
- 您将在第一次打开项目时收到“Gradle Sync”弹出窗口,询问使用Gradle包装器。点击“确定”。
6。测试运行应用程序
该应用程序可以在真实的Android设备上运行,也可以在Android Studio Emulator中运行。
设置一个Android设备
除非激活“开发人员模式”和“USB调试”,否则无法将应用从android studio加载到手机上。这里需要自己设置一下开发人员调试模式
注意:目前,此演示中使用的AAR与Android模拟器不兼容,您必须使用真正的Android设备才能运行该应用程序。
测试构建并安装应用程序
在对应用程序进行任何更改之前,让我们运行版本库附带的版本。
在Android Studio中运行Gradle同步,随后开始构建和安装过程。
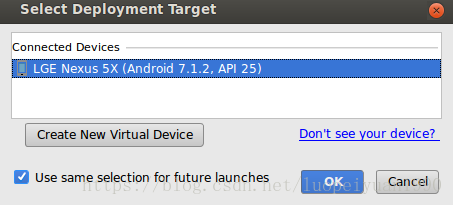
接下来,您需要从此弹出式菜单中选择您的手机:

现在允许Tensorflow演示程序访问您的相机和文件:

现在,该应用程序已安装,点击应用程序图标启动它。该版本的应用程序使用标准MobileNet,预先在1000个ImageNet类别上进行了培训。它应该看起来像这样(“Android”不是可用的类别之一):

7。运行定制的应用程序
默认的应用程序设置使用标准MobileNet将图像分类到1000个ImageNet类中的一个,而无需我们在第1部分中进行的再培训。
现在让我们修改应用程序,以便应用程序将我们的再培训羊肚菌用于我们的自定义图像类别。
将您的模型文件添加到项目中
演示项目配置为搜索目录中graph.pb的labels.txt文件和文件android/tflite/app/src/main/assets/。用你的版本替换这两个文件。以下命令完成此任务:
cp tf_files / optimized_graph.lite android / tflite / app / src / main / assets / graph.lite cp tf_files / retrained_labels.txt android / tflite / app / src / main / assets / labels.txt
运行你的应用
在Android Studio中运行Gradle同步,因此构建系统可以找到您的文件,然后像之前一样开始构建和安装过程。
Android工作室可能会要求您启用即时运行。这是不推荐的,因为它还不完全兼容用于构建TFLite库的Android NDK。
它应该看起来像这样
CC-BY by FelipeVenâncio
您可以将电源和音量减小按钮放在一起进行截图。
现在尝试网页搜索鲜花,将相机指向电脑屏幕,然后查看这些照片是否被正确分类。
或者让一个朋友拍下你的照片,并找出你是哪种TensorFlower 

 !
!
如果你得到像这样的Gradle同步错误:
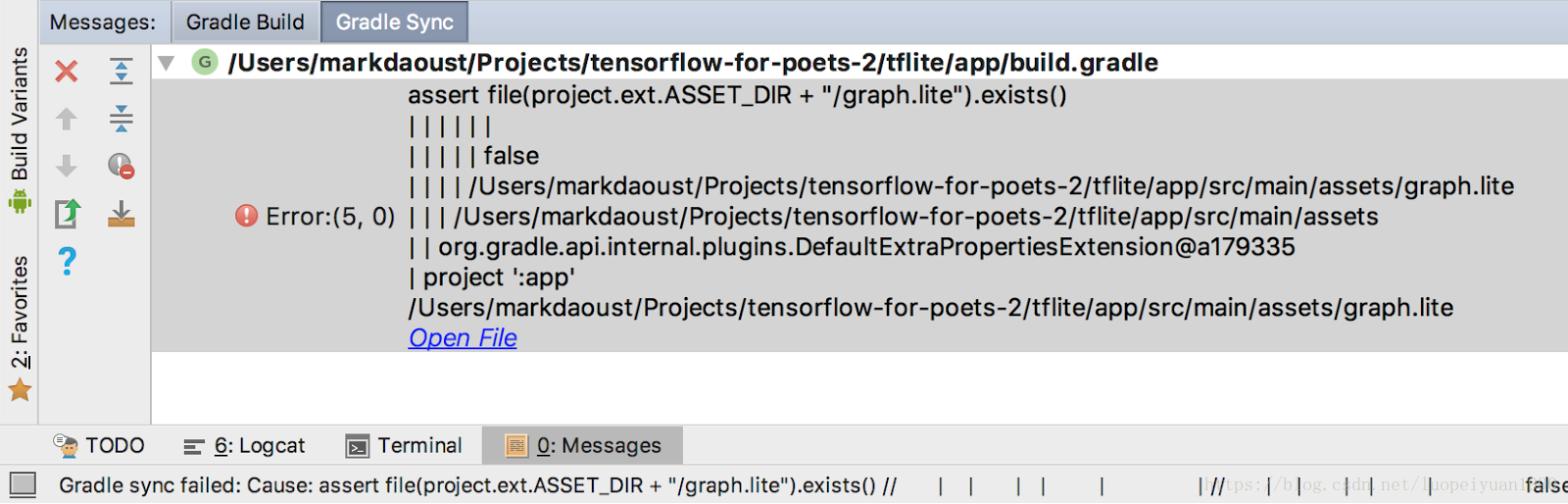
这是因为gradle无法找到graph.lite或labels.txt存档。验证这些文件的位置并通过单击工具栏上的“与Gradle文件同步项目”按钮重新运行Gradle同步:
8。它是如何工作的?
所以现在你已经运行了应用程序,让我们看看TensorFlow特定的代码。
TensorFlow-Android AAR
此应用程序使用预编译的TFLite Android存档(AAR)。此AAR托管在jcenter上。
模块build.gradle文件中的以下行包含项目中来自TensorFlow bintray maven存储库的最新AAR版本。
repositories {
maven {
url 'https://google.bintray.com/tensorflow'
}
}
dependencies {
// ...
compile 'org.tensorflow:tensorflow-lite:+'
}我们使用以下区块来指示Android资产打包工具.lite或.tflite资产不应被压缩。这是非常重要的,因为.lite文件将被内存映射,并且在压缩文件时不起作用。
android {
aaptOptions {
noCompress "tflite"
noCompress "lite"
}
}使用TFLite Java API
与TFLite接口的代码全部包含在ImageClassifier.java中。
建立
第一块感兴趣的是构造函数 ImageClassifier:
ImageClassifier(Activity activity) throws IOException {
tflite = new Interpreter(loadModelFile(activity));
labelList = loadLabelList(activity);
imgData =
ByteBuffer.allocateDirect(
4 * DIM_BATCH_SIZE * DIM_IMG_SIZE_X * DIM_IMG_SIZE_Y * DIM_PIXEL_SIZE);
imgData.order(ByteOrder.nativeOrder());
labelProbArray = new float[1][labelList.size()];
Log.d(TAG, "Created a Tensorflow Lite Image Classifier.");
}有几行应该更详细地讨论。
以下行创建TFLite解释器:
tflite = new Interpreter(loadModelFile(activity));这一行实例化一个TFLite解释器。解释器的工作是tf.Session(对于熟悉TFLite之外的TensorFlow的人员)。我们通过MappedByteBuffer包含模型的解释器。本地函数loadModelFile创建一个MappedByteBuffer包含活动的graph.lite资产文件。
以下几行创建输入数据缓冲区:
imgData = ByteBuffer.allocateDirect(
4 * DIM_BATCH_SIZE * DIM_IMG_SIZE_X * DIM_IMG_SIZE_Y * DIM_PIXEL_SIZE);该字节缓冲区的大小被设置为包含一旦转换为浮点的图像数据。解释器可以直接接受float数组作为输入,但ByteBuffer效率更高,因为它可以避免解释器中的额外副本。
以下行加载标签列表并创建输出缓冲区:
labelList = loadLabelList(activity);
//...
labelProbArray = new float[1][labelList.size()];输出缓冲区是一个浮点数组,每个标签都有一个元素,模型将写入输出概率。
运行模型
第二块利益是classifyFrame方法。它需要一个Bitmap输入,运行模型并返回要在应用程序中打印的文本。
String classifyFrame(Bitmap bitmap) {
// ...
convertBitmapToByteBuffer(bitmap);
// ...
tflite.run(imgData, labelProbArray);
// ...
String textToShow = printTopKLabels();
// ...
}这个方法有三件事。首先转换和复制的输入Bitmap到imgData ByteBuffer输入到模型。然后它调用解释器的run方法,将输入缓冲区和输出数组作为参数传递。解释器将输出数组中的值设置为为每个类计算的概率。输入和输出节点由先前toco创建.lite模型文件的转换步骤的参数定义。
9。接下来是什么?
以下是更多信息的链接:
- 了解更多关于TFLite从上Docs tensorflow.org和 repo。
- 试用这个演示应用程序的量化版本,以获得更小包装中更强大的模型。
- 尝试一些其他TFLite就绪型号,包括语音热门词汇检测器和设备上的智能答复版本。
- 通过我们的入门文档了解有关TensorFlow的更多信息。
转冻结图的参考命令:
python tensorflow/python/tools/freeze_graph.py --input_graph=/mnt/hgfs/E/exchange/mobilenet_v1_1.0_224_quant/mobilenet_v1_1.0_224_quant_eval.pbtxt --input_checkpoint=/mnt/hgfs/E/exchange/mobilenet_v1_1.0_224_quant/mobilenet_v1_1.0_224_quant.ckpt --input_binary=false --output_graph=./frozen_model.pb --output_node_names=MobilenetV1/Predictions/Reshape_1