论文:Aggregated Residual Transformations for Deep Neural Networks
代码:https://github.com/miraclewkf/ResNeXt-PyTorch
出处:CVPR 2017
贡献:
- 提出了 cardinality 的概念,即一个 block 中的基的数量,或者分组的数量
- 实验证明提高模型 cardinality 比提高宽度或深度更能带来效果的提升,且不会增加额外的计算量
- 可以看做将 ResNet 中每个 block 的卷积替换成了分组卷积,并且带来了效果的提升
一、背景
一般方法如果要提高模型的准确率,都会选择加深或加宽网络,但是随着超参数数量的增加(比如 channels 数,filter size等等)网络设计的难度和计算开销也会增加。
VGG 和 ResNet 网络都是堆叠相同的模块来实现网络深度的增加,但可能会导致过度拟合于特定的数据集。
Inception 系列的模型证明如果设计得当,也能在可控的复杂度增加的情况下提升模型的效果。简单讲就是 split-transform-merge 的策略,Inception 会并行的使用多种不同尺度的卷积核,以达到捕捉不同分辨率特征的目的,然后将这些特征 concat 起来用于下游任务。
但是 Inception 系列网络有个问题:网络的超参数设定的针对性比较强,当应用在别的数据集上时需要修改许多参数,因此可扩展性一般。
因此本文提出的 ResNeXt 结构可以在不增加参数复杂度的前提下提高准确率,同时还减少了超参数的数量。
ResNeXt 是怎么做的:
- 套用 ResNet 的重复堆叠结构
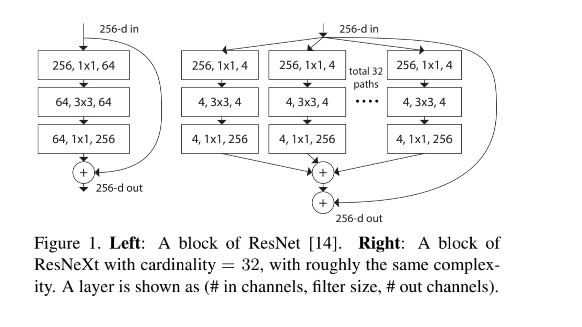
- 引入 Inception 的 split-tranform-merge 策略,但并行拆开的分支卷积核大小是相同的,然后相加(如图 1 右边)。此外,这种结构和图 3 的其他两种结构是等价的。可以看做将 ResNet 中每个 block 的卷积替换成了分组卷积。
Inception 的初始结构:
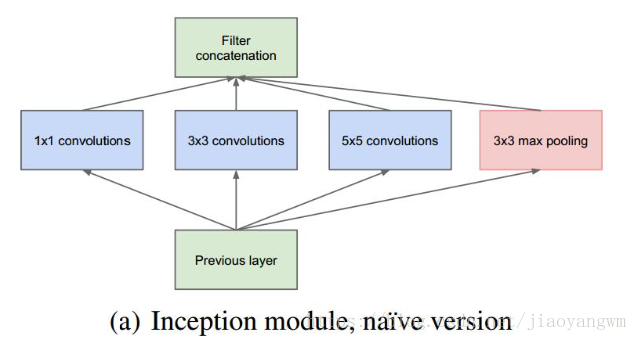
- 采用不同大小的卷积核意味着不同大小的感受野,最后拼接意味着不同尺度特征的融合
- 之所以卷积核采用1x1,3x3 和 5x5,主要是为了方便对齐,设定卷积步长 stride=1,只要分别设定 padding=0,1,2,那么卷积之后便可以得到相同维度的特征,然后将这些特征就可以直接拼接在一起了。
- 文章中说 pooling 被证明很有效,所以网络结构中也加入了
- 网络越到后面,特征越抽象,而且每个特征所涉及的感受野也变大了,因此随着层数的增加,3x3和5x5的比例也要增加。
由于 3x3 或 5x5 卷积核非常耗费计算资源,所以经过通道降维的改进后的 Inception 模型如下:
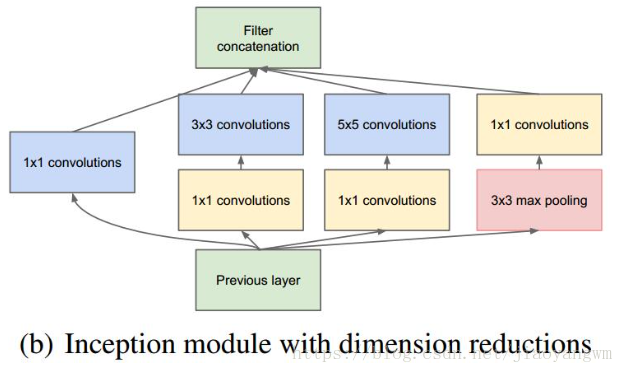
其中有4个分支:
-
第一个分支对输入进行1x1的卷积,这其实也是 NIN 中提出的一个重要结构。1x1 的卷积是一个非常优秀的结构,它可以跨通道组织信息,提高网络的表达能力,同时可以对输出通道升维和降维。Inception Module的4个分支都用到了1x1的卷积,来进行低成本(计算量比3x3小很多)的跨通道的特征变换
-
第二个分支,先使用了 1x1 卷积,然后连接 3x3 卷积,相当于进行了两次特征变换
-
第三个分支,先使用 1x1 卷积,然后连接 5x5 卷积
-
第四个分支,3x3 最大池化后直接使用 1x1 卷积
ResNet 的结构设计:
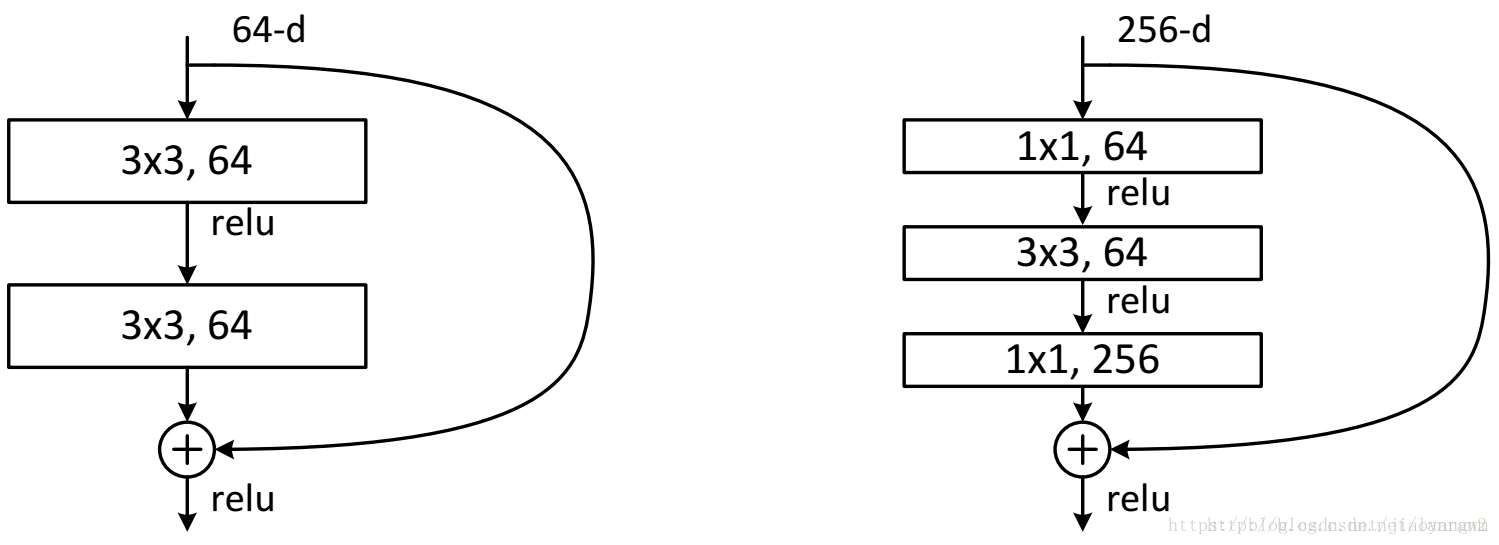
-
这两种结构分别针对 ResNet34(左)和ResNet50/101/152(右),一般称整个结构为一个 “building block”,其中右图为“bottleneck design”,目的就是为了降低参数数目,第一个 1x1 的卷积把 256 维的 channel 降到 64 维,然后在最后通过 1x1 卷积恢复,整体上用到参数数目 69632,而不使用 bottleneck 的话就是两个 3x3x256 的卷积,参数数目: 3x3x256x256x2 = 1179648,差了16.94倍。
-
对于常规ResNet,可以用于34层或者更少的网络中,对于 Bottleneck Design 的 ResNet 通常用于更深的如 101 这样的网络中,目的是减少计算和参数量。
二、方法
ResNeXt 提出了一个新的概念——cardinality,the size of the set of transformations,和网络深度以及宽度一起作为网络的设计量。
cardinality 也可以翻译为“基”或者“势”,表示一个 block 中,可以理解为特征被分为了几个基本单元,或者几组,如果被分为 32 组,则cardinality = 32。
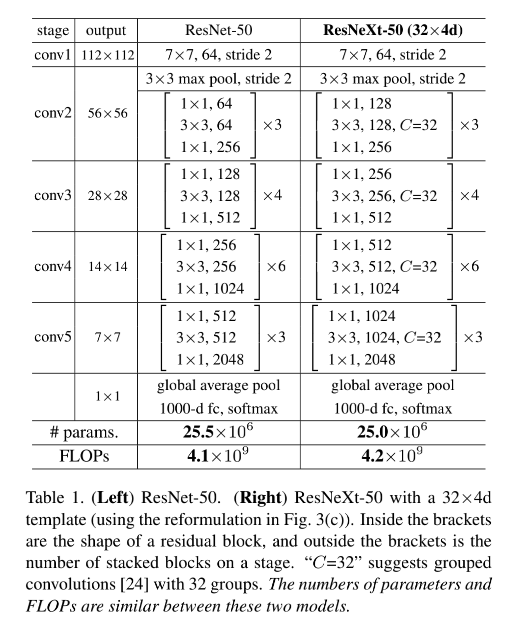
ResNeXt 的设计也是重复的堆叠,且设计遵循两个规则,设计的结构如表 1 所示:
- 如果使用相同大小的卷积核来处理特征图,则 blocks 之间共享参数
- 如果特征图下采样 2 倍,则 channels 宽度扩展 2 倍
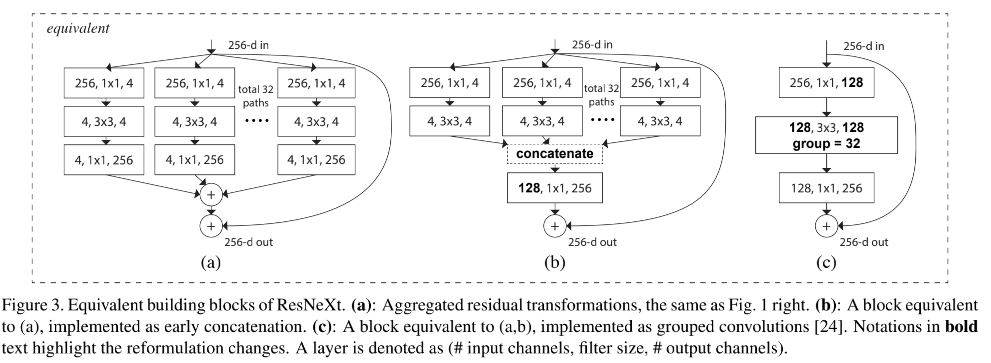
ResNeXt 的结构和下面两个结构是很类似的:
① Inception-ResNet
如图 1 右侧所示的结构(也就是下图 3a),其实和图 3b 的结构是等价的,只是和 Inception-ResNet 不同的是,ResNeXt 的并行通道的卷积核大小是相同的,在设计上更简单通用。
② Grouped Convolutions
如图 3c 所示,如果将图 3b 的第一层多个 1x1 卷积聚合起来,输出 128-d 特征向量,然后使用分组卷积(32组)来进行后续的特征提取,其实和图 3b 的并行分支是等价的,最后将分组卷积的每组卷积的输出 concat,就得到最后的输出。
三、效果
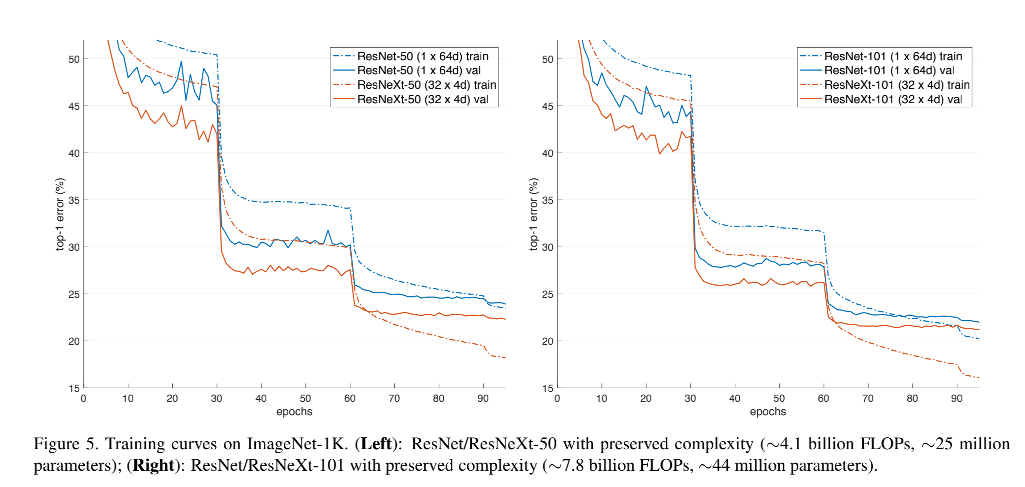
1、和 ResNet50 对比
如表 3 和图 5 左侧所示,32x4d 的 ResNeXt50 的验证集 error 为 22.7%,比 ResNet50(23.9%)低 1.7%
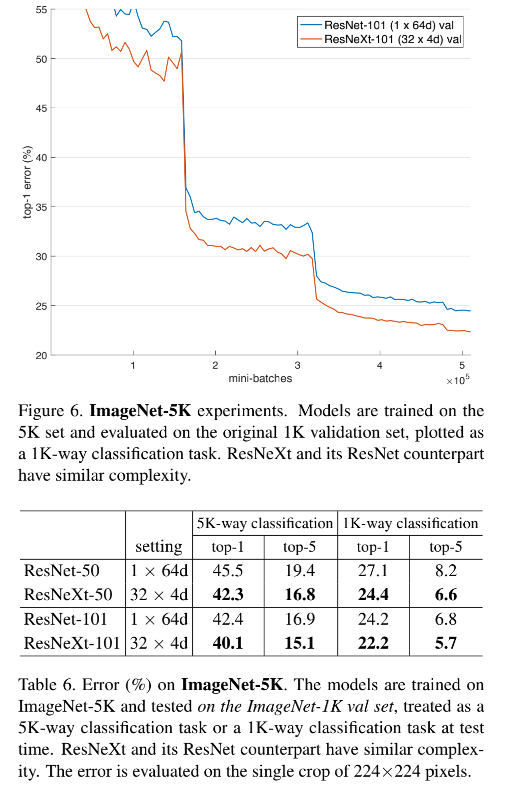
当 cardinality C C C 从 1→32,保持复杂度相同, error 会持续降低,且 ResNeXt50 的 error 会比 ResNet50 低,说明 ResNeXt50 学习能力更强。
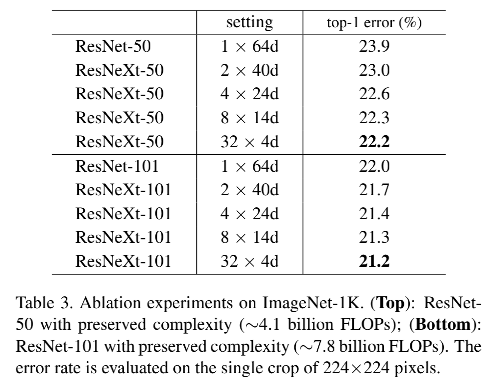
通过增加 C C C 或提升深度/宽度来提高复杂度,结果表明增加 C C C 效果更好
残差连接的效果:
- 移除 ResNeXt50 的残差,error 升了 3.9%,达到了 26.1%
- 移除 ResNet50 的残差,error 达到了31.2%
- 说明残差连接对参数优化很有效

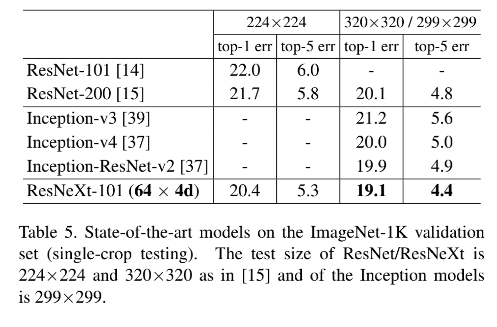
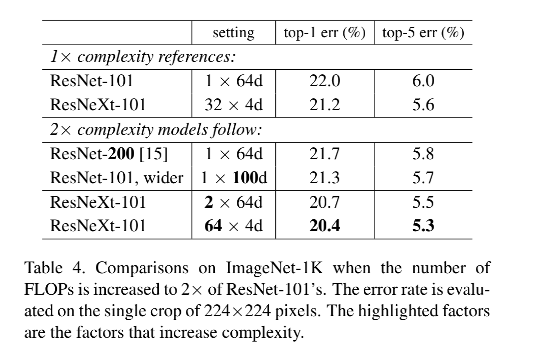
2、和 SOTA 对比