
RocksDB 是基于 Google LevelDB 研发的高性能 Key-Value 持久化存储引擎,以库组件形式嵌入程序中,为大规模分布式应用在 SSD 上运行提供优化。RocksDB 重点是提供工具支持,具体实现将交给上层应用。
正是这种高度可定制化能力,使得 RocksDB 可涵盖包括工作负载等众多场景的应用,今天我们将逐一为大家介绍:
"为什么需要内存管理器? 为什么不使用现有的内存管理器? RocksDB 究竟是如何实现的?"
01 为什么需要内存管理器?
RocksDB 有很多核心场景需要分配内存的,包括但不限于 Memtable、 Cache、Iterator 等,高效优质的内存分配器就显得尤为重要。一个优秀的通用内存分配器需要具备以下特性:
- 尽量避免内存碎片;并发分配性能好;
- 额外的空间损耗尽量少;
- 兼具通用性、兼容性、可移植性且易调试。
内存管理可以分为 3 个层次,自下而上分别是:
- 操作系统内核的内存管理;
- glibc 层使用系统调用维护的内存管理;
- 应用程序从 glibc 层动态分配内存后,根据应用程序本身的程序特性进行优化, 比如使用引用计数、std::shared_ptr、apache 等内存池方式的内存管理。
目前大部分服务端程序使用 glibc 提供的 malloc/free 系列函数,而 glibc 使用的 ptmalloc2 在性能上远远落后于 Google 的 Tcmalloc 和 Facebook 的 Jemalloc 。 后两者只需使用 LD_PRELOAD 环境变量启动程序即可,甚至并不需要重新编译。
02 为什么不使用现有内存管理器?
RocksDB 使用内存的场景集中在 Memtable、Cache、Iterator 等核心链路上,在保证高性能的同时,还需要实现对内存分配器内部控制(包括监控等)。
当前现有的内存分配器不具有主动上报内存监控细节,所以从长远看,依旧需要自己实现 RocksDB 专有的内存管理器。内存管理器设计思路如下:
- 小内存的申请通过 Thread-cache 或者 Per-cpu cache,保证了 CPU 不会频繁的 cache-miss;
- 若支持 MAP_HUGETLB,则会直接 mmap;
- 若大页内存则直接从底层的分配器去申请。
03 RocksDB 是如何实现的?
如图所示,RocksDB 的内存管理器是支持并发的,接下来让我们一起从源码入手,看看具体如何实现的。


Allocator
// Abstract interface for allocating memory in blocks. This memory is freed
// When the allocator object is destroyed. See the Arena class for more info.
class Allocator {
public:
virtual ~Allocator() {}
// 分配内存
virtual char* Allocate(size_t bytes) = 0;
// 对齐分配内存
virtual char* AllocateAligned(size_t bytes, size_t huge_page_size = 0,
Logger* logger = nullptr) = 0;
// 块大小
virtual size_t BlockSize() const = 0;
};
Arena
Arena 负责实现 RocksDB 的内存分配,我们从中可以看到其针对不同大小的内存分配请求,采取不同的分配策略,从而减少内存碎片。
class Arena : public Allocator {
static const size_t kInlineSize = 2048;
static const size_t kMinBlockSize; // 4K
static const size_t kMaxBlockSize; // 2G
private:
char inline_block_[kInlineSize] __attribute__((__aligned__(alignof(max_align_t))));
const size_t kBlockSize; // 每个 Block 的大小
using Blocks = std::vector<char*>;
Blocks blocks_; // 分配的新 Block 地址(不够了就从新分配)
struct MmapInfo {
void* addr_;
size_t length_;
MmapInfo(void* addr, size_t length) : addr_(addr), length_(length) {}
};
std::vector<MmapInfo> huge_blocks_; // 大块使用 mmap
size_t irregular_block_num = 0; // 不整齐的块分配次数(块大于 kBlockSize/4)
char* unaligned_alloc_ptr_ = nullptr; // 未对齐的一端指针(高地址开始)
char* aligned_alloc_ptr_ = nullptr; // 对齐一端指针(低地址开始)
size_t alloc_bytes_remaining_ = 0; // 内存剩余
size_t blocks_memory_ = 0; // 已经分配的内存大小
#ifdef MAP_HUGETLB
size_t hugetlb_size_ = 0;
#endif // MAP_HUGETLB
char* AllocateFromHugePage(size_t bytes);
char* AllocateFallback(size_t bytes, bool aligned);
char* AllocateNewBlock(size_t block_bytes);
AllocTracker* tracker_;
}
针对 Allocate 和 AllocateAligned,我们采用对同一块 Block 的两端进行分配。AllocateAligned 从内存块的低地址开始分配,Allocate 从高地址开始分配。分配流程图如下:
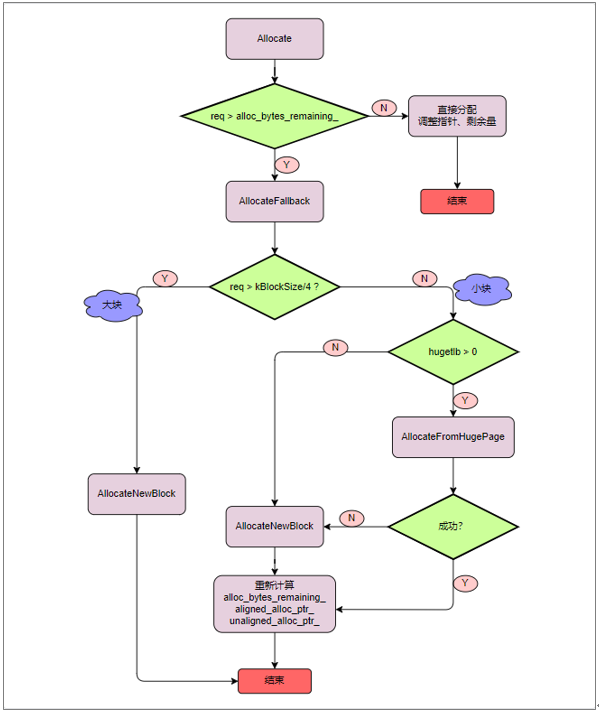
ConcurrentArena
内存分配器不仅需要减少内存碎片,同样需要保证并发分配的性能,那么 RocksDB 是如何实现 ConcurrentArena 的呢?
从内存管理架构图可以看出,RocksDB 维护了 CoreLocal 内存数组,每个线程从所在 CPU 对应的本地 Shard 上分配内存,若不足再去主内存 Arena 进行分配。我们从几个核心类开始逐一介绍:
1、ConcurrentArena
class ConcurrentArena : public Allocator {
public:
// block_size and huge_page_size are the same as for Arena (and are
// in fact just passed to the constructor of arena_. The core-local
// shards compute their shard_block_size as a fraction of block_size
// that varies according to the hardware concurrency level.
explicit ConcurrentArena(size_t block_size = Arena::kMinBlockSize,
AllocTracker* tracker = nullptr,
size_t huge_page_size = 0);
char* Allocate(size_t bytes) override {
return AllocateImpl(bytes, false /*force_arena*/,
[this, bytes]() { return arena_.Allocate(bytes); });
}
private:
...
CoreLocalArray<Shard> shards_; // 维护了一个 CoreLocal 内存数组
Arena arena_; // 主内存
...
};
2、CoreLocalArray
// An array of core-local values. Ideally the value type, T, is cache aligned to
// prevent false sharing.
template <typename T>
class CoreLocalArray {
public:
...
// returns pointer to element for the specified core index. This can be used,
// e.g., for aggregation, or if the client caches core index.
T* AccessAtCore(size_t core_idx) const;
private:
std::unique_ptr<T[]> data_;
int size_shift_;
};
3、并发分配流程
template <typename Func>
char* AllocateImpl(size_t bytes, bool force_arena, const Func& func) {
size_t cpu;
// 1:大块则直接从 Arena 上分配,需要加锁
std::unique_lock<SpinMutex> arena_lock(arena_mutex_, std::defer_lock);
if (bytes > shard_block_size_ / 4 || force_arena ||
((cpu = tls_cpuid) == 0 &&
!shards_.AccessAtCore(0)->allocated_and_unused_.load(
std::memory_order_relaxed) &&
arena_lock.try_lock())) {
if (!arena_lock.owns_lock()) {
arena_lock.lock();
}
auto rv = func();
Fixup();
return rv;
}
// 2:挑选 CPU 对应的 Shard
Shard* s = shards_.AccessAtCore(cpu & (shards_.Size() - 1));
if (!s->mutex.try_lock()) {
s = Repick();
s->mutex.lock();
}
std::unique_lock<SpinMutex> lock(s->mutex, std::adopt_lock);
size_t avail = s->allocated_and_unused_.load(std::memory_order_relaxed);
// 2.1:若当前 Shard 可用内存不够时,去 Arena 分配存入 Shard
if (avail < bytes) {
// reload
std::lock_guard<SpinMutex> reload_lock(arena_mutex_);
// If the arena's current block is within a factor of 2 of the right
// size, we adjust our request to avoid arena waste.
auto exact = arena_allocated_and_unused_.load(std::memory_order_relaxed);
assert(exact == arena_.AllocatedAndUnused());
if (exact >= bytes && arena_.IsInInlineBlock()) {
// If we haven't exhausted arena's inline block yet, allocate from arena
// directly. This ensures that we'll do the first few small allocations
// without allocating any blocks.
// In particular this prevents empty memtables from using
// disproportionately large amount of memory: a memtable allocates on
// the order of 1 KB of memory when created; we wouldn't want to
// allocate a full arena block (typically a few megabytes) for that,
// especially if there are thousands of empty memtables.
auto rv = func();
Fixup();
return rv;
}
avail = exact >= shard_block_size_ / 2 && exact < shard_block_size_ * 2
? exact
: shard_block_size_;
s->free_begin_ = arena_.AllocateAligned(avail);
Fixup();
}
s->allocated_and_unused_.store(avail - bytes, std::memory_order_relaxed);
// 3:根据是否对齐,判断是从高地址/低地址分配
char* rv;
if ((bytes % sizeof(void*)) == 0) {
// aligned allocation from the beginning
rv = s->free_begin_;
s->free_begin_ += bytes;
} else {
// unaligned from the end
rv = s->free_begin_ + avail - bytes;
}
return rv;
}
总结
- 入参 Func 就是上面传入的 Lambda 表达式:this, bytes { returnarena_.Allocate(bytes) ;
- 当请求内存块较大时,直接从 Arena 分配且需要加锁;否则直接从当前 CPU 对应的 Shard 分配;
- 若当前 Shard 可用内存不够,需要从 Arena 再次请求;4、根据是否对齐,判断从高/低地址分配。