活动地址:CSDN21天学习挑战赛
前言
本周的任务有3个,预测股票,识别验证码,识别眼睛状态。因为任务不同,那么可能会使用到不同的预处理、网络等等。
本节主要学习识别眼睛任务。
一、拆解任务
首先需要了解这次需要处理的任务,这里贴一张老师的数据展示图。
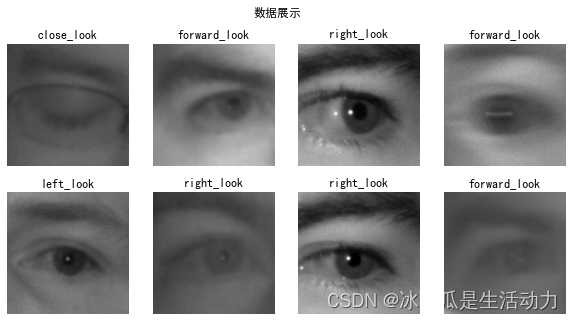
数据分为图片及其对应的标签,且这个标签是眼睛看的方向,这里需要将标签转为离散的数字。
二、学习内容
这次的任务其实跟之前做过的识别衣服、识别手写数字等等的类似,本章其实主要以复习以前学过的知识为主。
1. 数据处理
读数据(很常规的内容)
import matplotlib.pyplot as plt
# 支持中文
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
import os,PIL
# 设置随机种子尽可能使结果可以重现
import numpy as np
np.random.seed(1)
# 设置随机种子尽可能使结果可以重现
import tensorflow as tf
tf.random.set_seed(1)
import pathlib
data_dir = "D:/jupyter notebook/DL-100-days/datasets/017_Eye_dataset"
data_dir = pathlib.Path(data_dir)
batch_size = 64
img_height = 224
img_width = 224
"""
关于image_dataset_from_directory()的详细介绍可以参考文章:https://mtyjkh.blog.csdn.net/article/details/117018789
"""
train_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="training",
seed=12,
image_size=(img_height, img_width),
batch_size=batch_size)
"""
关于image_dataset_from_directory()的详细介绍可以参考文章:https://mtyjkh.blog.csdn.net/article/details/117018789
"""
val_ds = tf.keras.preprocessing.image_dataset_from_directory(
data_dir,
validation_split=0.2,
subset="validation",
seed=12,
image_size=(img_height, img_width),
batch_size=batch_size)
这里涉及到几个概念:
(1)shuffle:将数据打乱,让训练更加容易收敛;
(2)prefetch:将获取数据和训练分开,更加合理的分配gpu和cpu运行时间;
(3)cache:将数据缓存至内存,也可以提高
2. 建立神经网络
老师用了一个很出名的模型——VGG16。这个网络是14年提出的。这个模型最主要的贡献在于,证明提高网络的深度能提升性能。
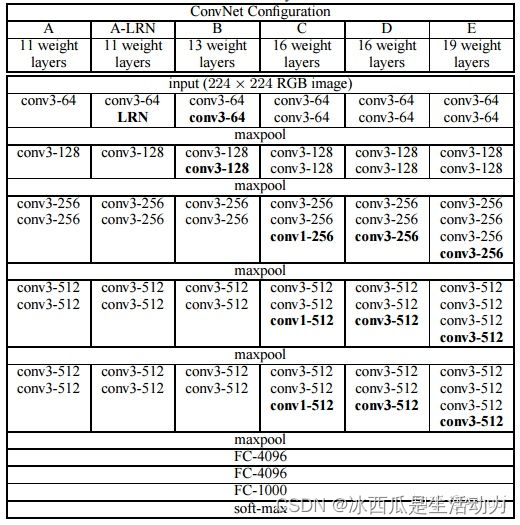
这是这个网络的结构,可以看到网络还是比较大的,训练起来其实比较困难,网上常见的做法其实会用一个预训练模型去训练。老师并没有手写这个网络(个人觉得手写的话,对卷积层、全联接层等有更深的了解)。
model = tf.keras.applications.VGG16()
# 打印模型信息
model.summary()
2.训练神经网络
训练过程,其实和之前做过的例子都没啥差别。
不过这里提到了几个内容:
(1)学习率:学习率大的话,学习速度快,但是容易导致模型不收敛;学习率小的话,有利于提高模型精度,但是训练时间久
(2)损失函数:用于衡量模型在训练时候的准确率;
(3)优化器:决定模型如何根据看到的数据和自身的损失函数进行下一步优化;
(4)评价函数:用于评价模型好坏。
# 设置初始学习率
initial_learning_rate = 1e-4
lr_schedule = tf.keras.optimizers.schedules.ExponentialDecay(
initial_learning_rate,
decay_steps=20, # 敲黑板!!!这里是指 steps,不是指epochs
decay_rate=0.96, # lr经过一次衰减就会变成 decay_rate*lr
staircase=True)
# 将指数衰减学习率送入优化器
optimizer = tf.keras.optimizers.Adam(learning_rate=lr_schedule)
model.compile(optimizer=optimizer,
loss ='sparse_categorical_crossentropy',
metrics =['accuracy'])
epochs = 10
history = model.fit(
train_ds,
validation_data=val_ds,
epochs=epochs
)
3.预测和模型评估
预测和评估也是和之前的练习相似。
acc = history.history['accuracy']
val_acc = history.history['val_accuracy']
loss = history.history['loss']
val_loss = history.history['val_loss']
epochs_range = range(epochs)
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, acc, label='Training Accuracy')
plt.plot(epochs_range, val_acc, label='Validation Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, loss, label='Training Loss')
plt.plot(epochs_range, val_loss, label='Validation Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()
# 采用加载的模型(new_model)来看预测结果
plt.figure(figsize=(10, 5)) # 图形的宽为10高为5
plt.suptitle("预测结果展示")
for images, labels in val_ds.take(1):
for i in range(8):
ax = plt.subplot(2, 4, i + 1)
# 显示图片
plt.imshow(images[i].numpy().astype("uint8"))
# 需要给图片增加一个维度
img_array = tf.expand_dims(images[i], 0)
# 使用模型预测图片中的人物
predictions = new_model.predict(img_array)
plt.title(class_names[np.argmax(predictions)])
plt.axis("off")
文章里其实还提到了混淆矩阵,但是我不是太清楚到底有啥用,后面再学习。
总结
本章从眼睛状态是不出发,复习了一下以前学过的概念,也学了一个经典的网络——VGG~