Delta Lake 2.0.0 现已发布,该版本发布正值 Delta Lake 的 3 岁生日之际。“我们很高兴地宣布在 Apache Spark 3.2 上发布 Delta Lake 2.0 (pypi, maven, release notes)......Delta Lake 2.0 的意义不仅仅是一个数字,它重申了我们对 Delta Lake 开源的集体承诺”。
Delta Lake 是一个存储层,为 Apache Spark 和大数据 workloads 提供 ACID 事务能力,其通过写和快照隔离之间的乐观并发控制(optimistic concurrency control),在写入数据期间提供一致性的读取,从而为构建在 HDFS 和云存储上的数据湖(data lakes)带来可靠性。
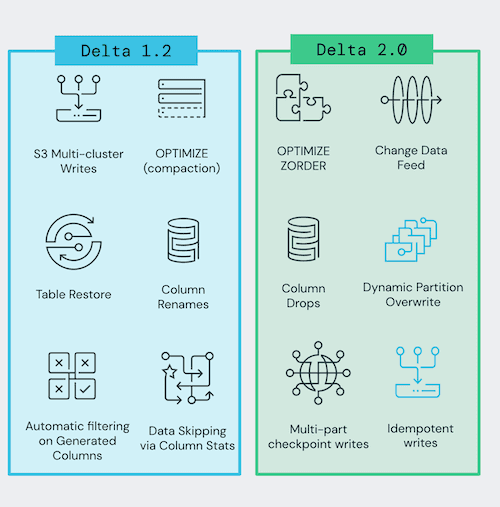
此版本的一些主要功能包括:
-
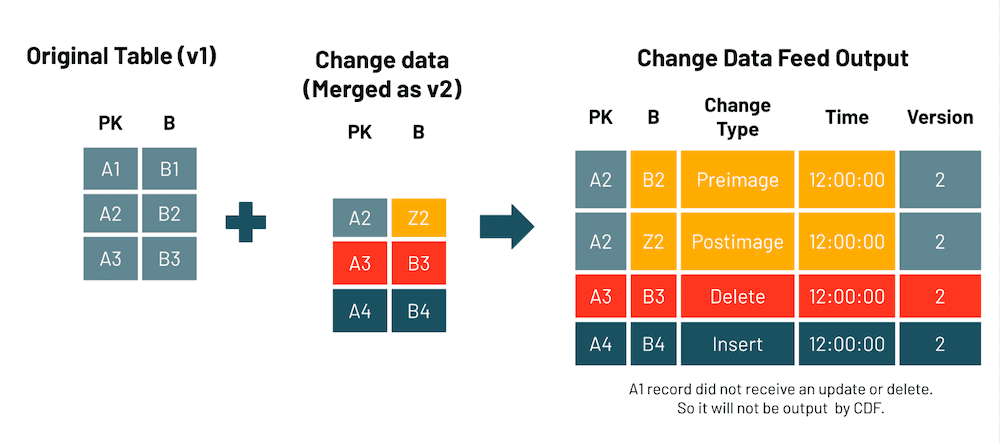
支持 Delta 表上的 Change Data Feed。Change Data Feed 表示不同版本的表之间的行级更改。启用后,将记录有关表上每个写入操作的行级别更改的附加信息。有关更多详细信息,可参阅文档。
-
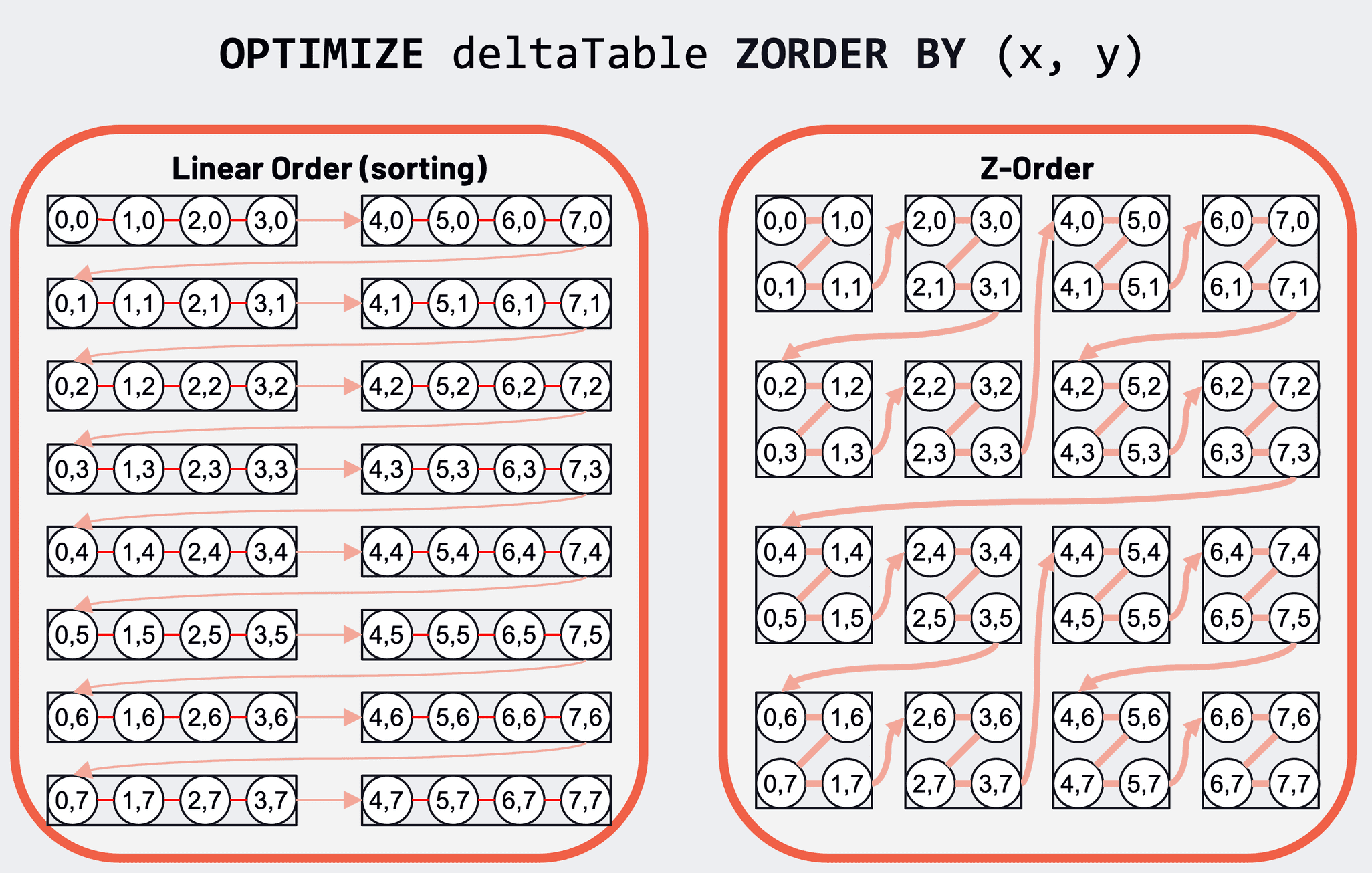
支持数据的 Z-Order 聚类,减少读取的数据量。Z-Ordering 是一种将相关信息放在同一组文件中的技术。这种数据聚类允许列统计信息(在 Delta 1.2 中发布)更有效地跳过查询中基于过滤器的数据。有关更多详细信息,可参阅文档。
-
支持对 Delta 表的幂等写入,以启用 Delta 表写入作业的容错重试,而无需多次将数据写入表。有关更多详细信息,可参阅文档。
app_id = ... # A unique string that is used as an application ID. def writeToDeltaLakeTableIdempotent(batch_df, batch_id): batch_df.write.format(...).option("txnVersion", batch_id).option("txnAppId", app_id).save(...) # location 1 batch_df.write.format(...).option("txnVersion", batch_id).option("txnAppId", app_id).save(...) # location 2
-
支持将 Delta 表中的列作为元数据变更操作来删除。此命令从元数据中删除列,而不是从底层文件中删除列数据。有关更多详细信息,可参阅文档。
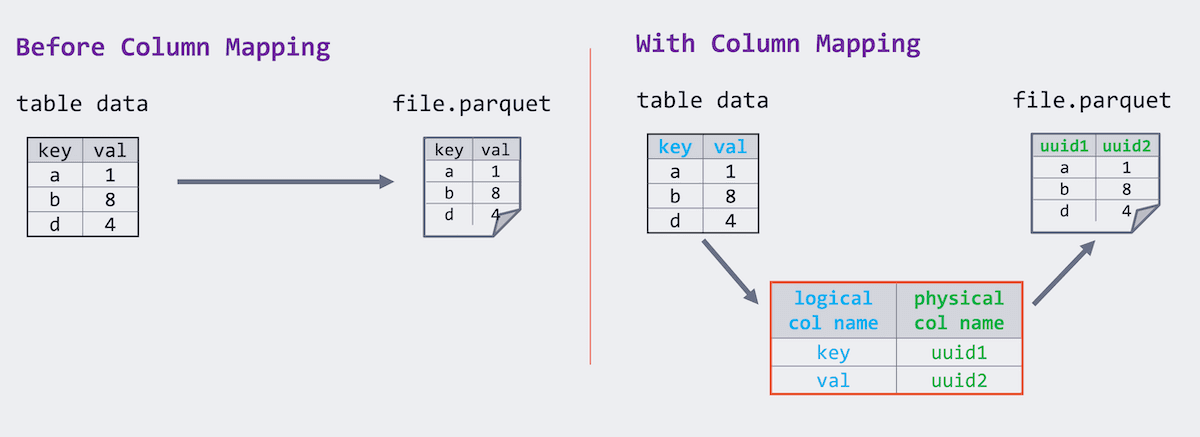
-
支持动态分区覆盖。仅覆盖在运行时写入数据的分区。值得注意的是,动态分区覆盖与分区表的
replaceWhere选项冲突。有关详细信息,可参阅文档。
SET spark.sql.sources.partitionOverwriteMode=dynamic; INSERT OVERWRITE TABLE default.people10m SELECT * FROM morePeople;
-
对 multi-part checkpoints 的实验性支持,将 Delta Lake checkpoint 拆分为多个部分,以加快 checkpoint 的写入和读取速度。有关更多详细信息,可参阅文档。
-
其他显着变化
- 通过添加对嵌套列生成列跳过的支持,改进生成列数据跳过
- 通过阻止 Delta Lake 中不受支持的数据类型来改进表架构验证。
- 支持创建具有空模式的 Delta Lake 表。
- 更改 DROP CONSTRAINT 在约束不存在时引发错误的行为。在此版本之前,该命令用于静默返回。
- 当分区值中包含 space 时,修复符号链接清单生成问题。
- 修复了收集不正确的提交统计信息的问题。
- 支持 S3 多集群写入支持的 LogStore 中的 SimpleAWSCredentialsProvider 或 TemporaryAWSCredentialsProvider。
- 修复了生成的列中的一个问题,即使列是空的,也不允许在插入的 DataFrame 中写入空列。
Benchmark Framework Update
独立于此版本,开发团队改进了编写大型 scala 性能基准测试的框架(在 1.2.0 版本中添加了初始版本),添加了对使用 Google Dataproc 在 Google Compute Platform 上运行基准测试的支持(除了现有的对 AWS 上 EMR 的支持之外)。
社区扩展和增长的更新
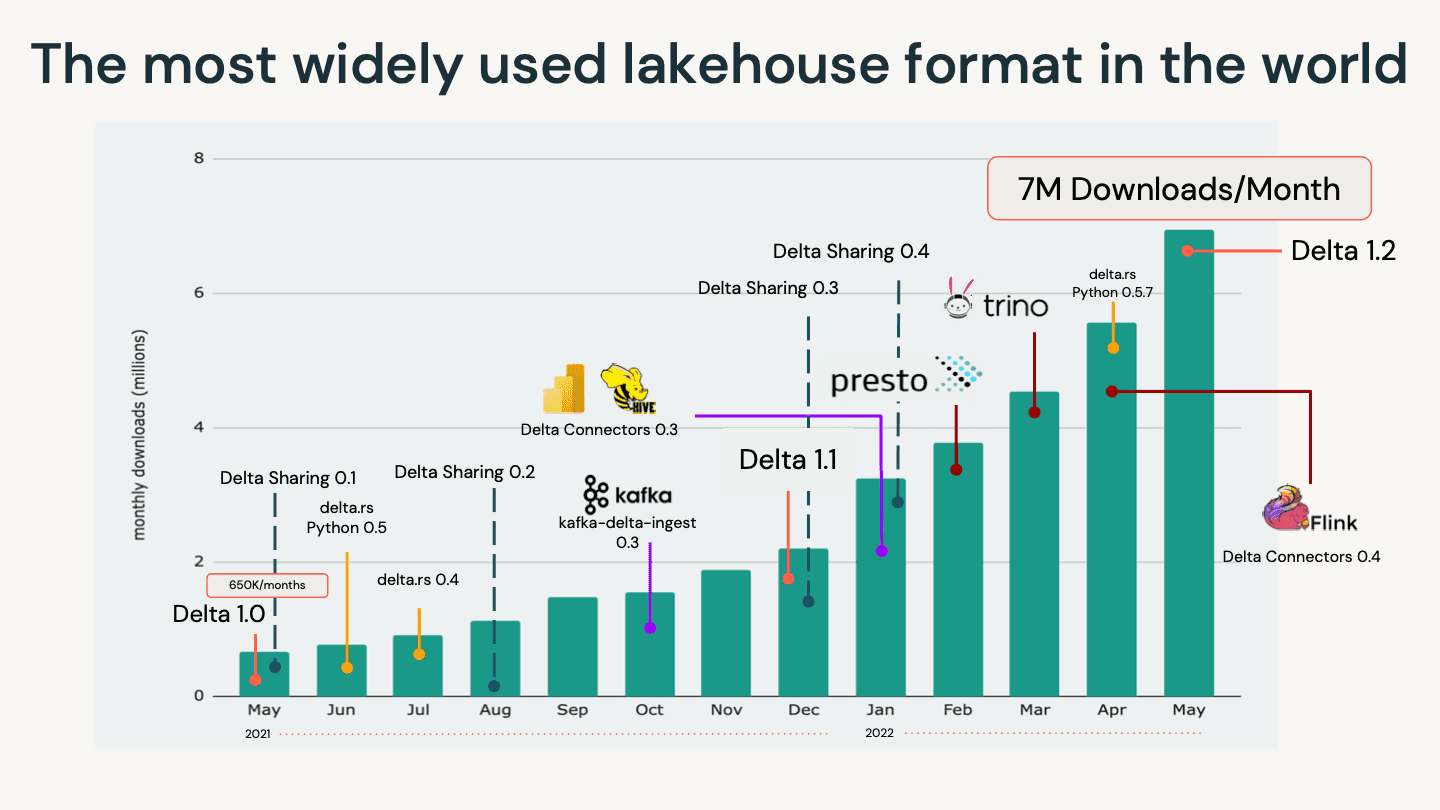
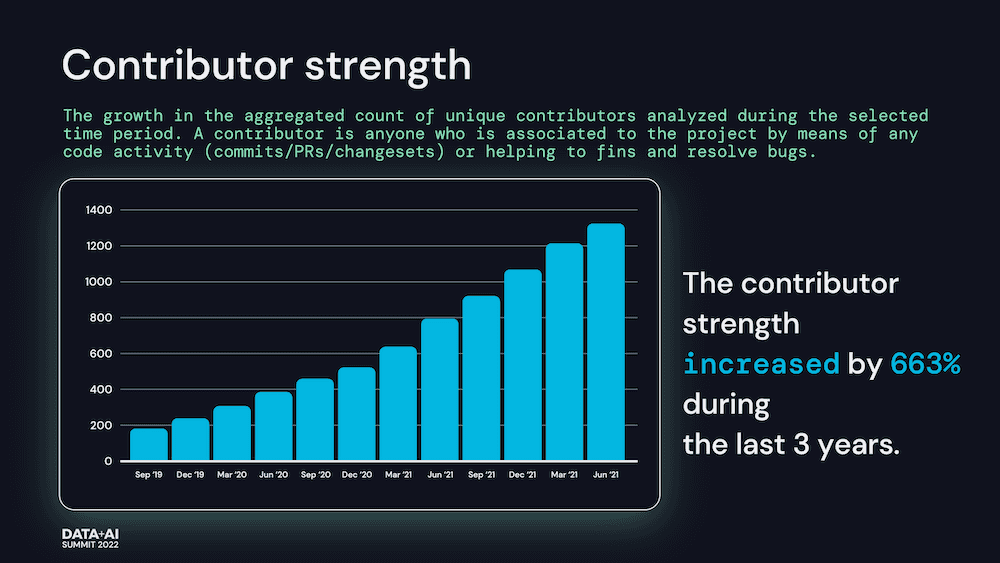
公告称,Delta Lake 将更加依赖于通过提供 ACID 事务以及在现有云数据存储之上统一流和批处理事务来为数据湖带来可靠性和改进的性能。通过使用最流行的计算引擎和技术构建连接器,Delta Lake 的吸引力将继续增加 —— 推动社区的更多增长,并在全球最具创新性和最大的企业中快速采用该技术。
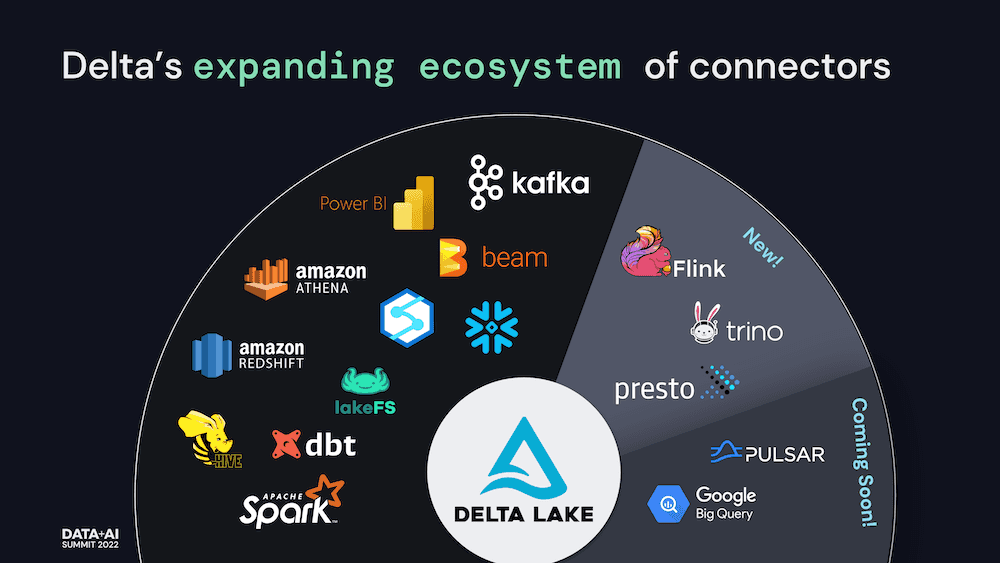
更多详情可查看官方公告。