面试官:今天想跟你聊聊Java内存模型,这块你了解过吗?
候选者:嗯,我简单说下我的理解吧。那我就从为什么要有Java内存模型开始讲起吧
面试官:开始你的表演吧。
候选者:那我先说下背景吧
候选者:1. 现有计算机往往是多核的,每个核心下会有高速缓存。高速缓存的诞生是由于「CPU与内存(主存)的速度存在差异」,L1和L2缓存一般是「每个核心独占」一份的。
候选者:2. 为了让CPU提高运算效率,处理器可能会对输入的代码进行「乱序执行」,也就是所谓的「指令重排序」
候选者:3. 一次对数值的修改操作往往是非原子性的(比如i++实际上在计算机执行时就会分成多个指令)
候选者:在永远单线程下,上面所讲的均不会存在什么问题,因为单线程意味着无并发。并且在单线程下,编译器/runtime/处理器都必须遵守as-if-serial语义,遵守as-if-serial意味着它们不会对「数据依赖关系的操作」做重排序。

候选者:CPU为了效率,有了高速缓存、有了指令重排序等等,整块架构都变得复杂了。我们写的程序肯定也想要「充分」利用CPU的资源啊!于是乎,我们使用起了多线程
候选者:多线程在意味着并发,并发就意味着我们需要考虑线程安全问题
候选者:1. 缓存数据不一致:多个线程同时修改「共享变量」,CPU核心下的高速缓存是「不共享」的,那多个cache与内存之间的数据同步该怎么做?
候选者:2. CPU指令重排序在多线程下会导致代码在非预期下执行,最终会导致结果存在错误的情况。
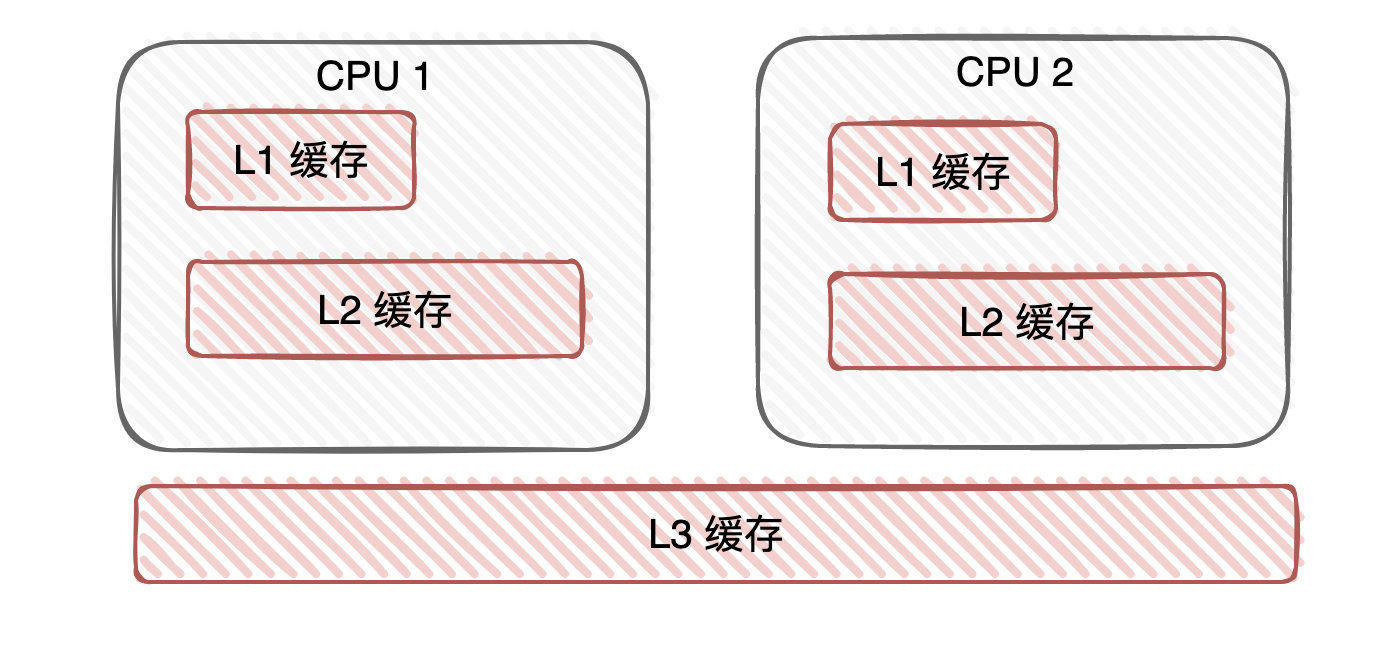
候选者:针对于「缓存不一致」问题,CPU也有其解决办法,常被大家所认识的有两种:
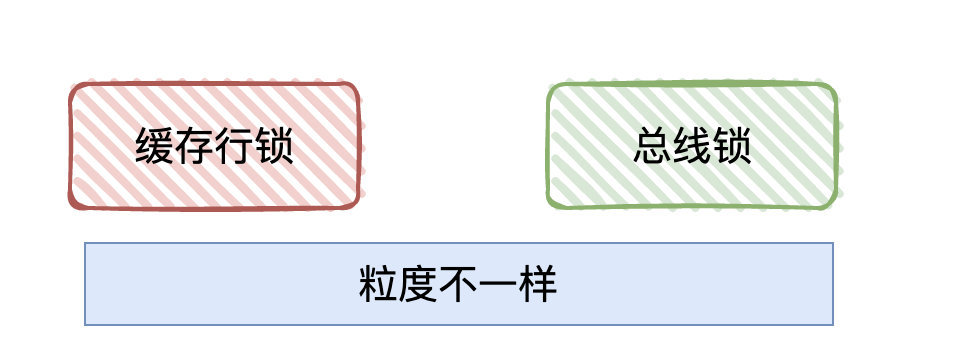
候选者:1.使用「总线锁」:某个核心在修改数据的过程中,其他核心均无法修改内存中的数据。(类似于独占内存的概念,只要有CPU在修改,那别的CPU就得等待当前CPU释放)
候选者:2.缓存一致性协议(MESI协议,其实协议有很多,只是举个大家都可能见过的)。MESI拆开英文是(Modified (修改状态)、Exclusive (独占状态)、Share(共享状态)、Invalid(无效状态))
候选者:缓存一致性协议我认为可以理解为「缓存锁」,它针对的是「缓存行」(Cache line) 进行”加锁”,所谓「缓存行」其实就是 高速缓存 存储的最小单位。
面试官:嗯…
候选者:MESI协议的原理大概就是:当每个CPU读取共享变量之前,会先识别数据的「对象状态」(是修改、还是共享、还是独占、还是无效)。
候选者:如果是独占,说明当前CPU将要得到的变量数据是最新的,没有被其他CPU所同时读取
候选者:如果是共享,说明当前CPU将要得到的变量数据还是最新的,有其他的CPU在同时读取,但还没被修改
候选者:如果是修改,说明当前CPU正在修改该变量的值,同时会向其他CPU发送该数据状态为invalid(无效)的通知,得到其他CPU响应后(其他CPU将数据状态从共享(share)变成invalid(无效)),会当前CPU将高速缓存的数据写到主存,并把自己的状态从modify(修改)变成exclusive(独占)
候选者:如果是无效,说明当前数据是被改过了,需要从主存重新读取最新的数据。

候选者:其实MESI协议做的就是判断「对象状态」,根据「对象状态」做不同的策略。关键就在于某个CPU在对数据进行修改时,需要「同步」通知其他CPU,表示这个数据被我修改了,你们不能用了。
候选者:比较于「总线锁」,MESI协议的”锁粒度”更小了,性能那肯定会更高咯
面试官:但据我了解,CPU还有优化,你还知道吗?
候选者:嗯,还是了解那么一点点的。
候选者:从前面讲到的,可以发现的是:当CPU修改数据时,需要「同步」告诉其他的CPU,等待其他CPU响应接收到invalid(无效)后,它才能将高速缓存数据写到主存。
候选者:同步,意味着等待,等待意味着什么都干不了。CPU肯定不乐意啊,所以又优化了一把。
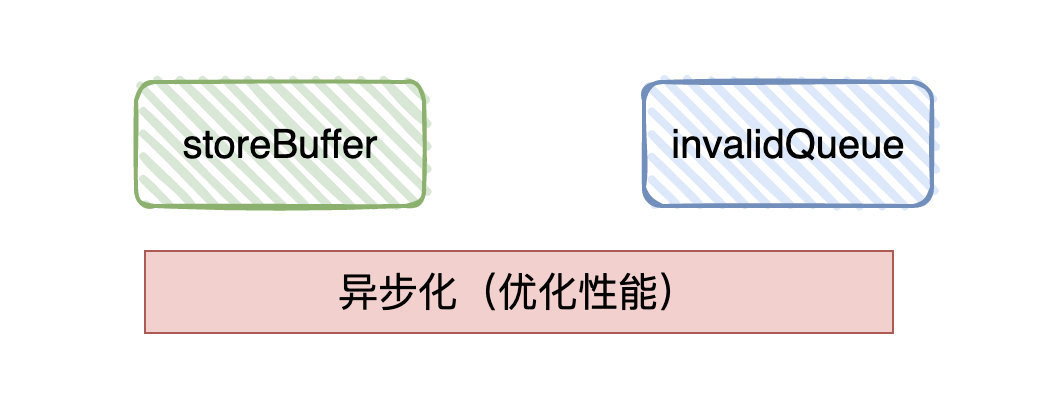
候选者:优化思路就是从「同步」变成「异步」。
候选者:在修改时会「同步」告诉其他CPU,而现在则把最新修改的值写到「store buffer」中,并通知其他CPU记得要改状态,随后CPU就直接返回干其他事了。等到收到其它CPU发过来的响应消息,再将数据更新到高速缓存中。
候选者:其他CPU接收到invalid(无效)通知时,也会把接收到的消息放入「invalid queue」中,只要写到「invalid queue」就会直接返回告诉修改数据的CPU已经将状态置为「invalid」
候选者:而异步又会带来新问题:那我现在CPU修改完A值,写到「store buffer」了,CPU就可以干其他事了。那如果该CPU又接收指令需要修改A值,但上一次修改的值还在「store buffer」中呢,没修改至高速缓存呢。
候选者:所以CPU在读取的时候,需要去「store buffer」看看存不存在,存在则直接取,不存在才读主存的数据。【Store Forwarding】
候选者:好了,解决掉第一个异步带来的问题了。(相同的核心对数据进行读写,由于异步,很可能会导致第二次读取的还是旧值,所以首先读「store buffer」。
面试官:还有其他?
候选者:那当然啊,那「异步化」会导致相同核心读写共享变量有问题,那当然也会导致「不同」核心读写共享变量有问题啊
候选者:CPU1修改了A值,已把修改后值写到「store buffer」并通知CPU2对该值进行invalid(无效)操作,而CPU2可能还没收到invalid(无效)通知,就去做了其他的操作,导致CPU2读到的还是旧值。
候选者:即便CPU2收到了invalid(无效)通知,但CPU1的值还没写到主存,那CPU2再次向主存读取的时候,还是旧值…
候选者:变量之间很多时候是具有「相关性」(a=1;b=0;b=a),这对于CPU又是无感知的…
候选者:总体而言,由于CPU对「缓存一致性协议」进行的异步优化「store buffer」「invalid queue」,很可能导致后面的指令很可能查不到前面指令的执行结果(各个指令的执行顺序非代码执行顺序),这种现象很多时候被称作「CPU乱序执行」
候选者:为了解决乱序问题(也可以理解为可见性问题,修改完没有及时同步到其他的CPU),又引出了「内存屏障」的概念。

面试官:嗯…
候选者:「内存屏障」其实就是为了解决「异步优化」导致「CPU乱序执行」/「缓存不及时可见」的问题,那怎么解决的呢?嗯,就是把「异步优化」给”禁用“掉(:
候选者:内存屏障可以分为三种类型:写屏障,读屏障以及全能屏障(包含了读写屏障),屏障可以简单理解为:在操作数据的时候,往数据插入一条”特殊的指令”。只要遇到这条指令,那前面的操作都得「完成」。
候选者:那写屏障就可以这样理解:CPU当发现写屏障的指令时,会把该指令「之前」存在于「store Buffer」所有写指令刷入高速缓存。
候选者:通过这种方式就可以让CPU修改的数据可以马上暴露给其他CPU,达到「写操作」可见性的效果。
候选者:那读屏障也是类似的:CPU当发现读屏障的指令时,会把该指令「之前」存在于「invalid queue」所有的指令都处理掉
候选者:通过这种方式就可以确保当前CPU的缓存状态是准确的,达到「读操作」一定是读取最新的效果。

候选者:由于不同CPU架构的缓存体系不一样、缓存一致性协议不一样、重排序的策略不一样、所提供的内存屏障指令也有差异,为了简化Java开发人员的工作。Java封装了一套规范,这套规范就是「Java内存模型」
候选者:再详细地说,「Java内存模型」希望 屏蔽各种硬件和操作系统的访问差异,保证了Java程序在各种平台下对内存的访问都能得到一致效果。目的是解决多线程存在的原子性、可见性(缓存一致性)以及有序性问题。

面试官:那要不简单聊聊Java内存模型的规范和内容吧?
候选者:不了,怕一聊就是一个下午,下次吧?
本文总结:
- 并发问题产生的三大根源是「可见性」「有序性」「原子性」
- 可见性:CPU架构下存在高速缓存,每个核心下的L1/L2高速缓存不共享(不可见)
- 有序性:主要有三方面可能导致打破
- 编译器优化导致重排序(编译器可以在不改变单线程程序语义的情况下,可以对代码语句顺序进行调整重新排序)
- 指令集并行重排序(CPU原生就有可能将指令进行重排)
- 内存系统重排序(CPU架构下很可能有store buffer /invalid queue 缓冲区,这种「异步」很可能会导致指令重排)
- 原子性:Java的一条语句往往需要多条 CPU 指令完成(i++),由于操作系统的线程切换很可能导致 i++ 操作未完成,其他线程“中途”操作了共享变量 i ,导致最终结果并非我们所期待的。
- 在CPU层级下,为了解决「缓存一致性」问题,有相关的“锁”来保证,比如“总线锁”和“缓存锁”。
- 总线锁是锁总线,对共享变量的修改在相同的时刻只允许一个CPU操作。
- 缓存锁是锁缓存行(cache line),其中比较出名的是MESI协议,对缓存行标记状态,通过“同步通知”的方式,来实现(缓存行)数据的可见性和有序性
- 但“同步通知”会影响性能,所以会有内存缓冲区(store buffer/invalid queue)来实现「异步」进而提高CPU的工作效率
- 引入了内存缓冲区后,又会存在「可见性」和「有序性」的问题,平日大多数情况下是可以享受「异步」带来的好处的,但少数情况下,需要强「可见性」和「有序性」,只能”禁用”缓存的优化。
- “禁用”缓存优化在CPU层面下有「内存屏障」,读屏障/写屏障/全能屏障,本质上是插入一条”屏障指令”,使得缓冲区(store buffer/invalid queue)在屏障指令之前的操作均已被处理,进而达到 读写 在CPU层面上是可见和有序的。
- 不同的CPU实现的架构和优化均不一样,Java为了屏蔽硬件和操作系统访问内存的各种差异,提出了「Java内存模型」的规范,保证了Java程序在各种平台下对内存的访问都能得到一致效果

面试官:我记得上一次已经问过了为什么要有Java内存模型
面试官:我记得你的最终答案是:Java为了屏蔽硬件和操作系统访问内存的各种差异,提出了「Java内存模型」的规范,保证了Java程序在各种平台下对内存的访问都能得到一致效果
候选者:嗯,对的
面试官:要不,你今天再来讲讲Java内存模型这里边的内容呗?
候选者:嗯,在讲之前还是得强调下:Java内存模型它是一种「规范」,Java虚拟机会实现这个规范。
候选者:Java内存模型主要的内容,我个人觉得有以下几块吧
候选者:1. Java内存模型的抽象结构
候选者:2. happen-before规则
候选者:3.对volatile内存语义的探讨(这块我后面再好好解释)
面试官:那要不你就从第一点开始呗?先聊下Java内存模型的抽象结构?
候选者:嗯。Java内存模型定义了:Java线程对内存数据进行交互的规范。
候选者:线程之间的「共享变量」存储在「主内存」中,每个线程都有自己私有的「本地内存」,「本地内存」存储了该线程以读/写共享变量的副本。
候选者:本地内存是Java内存模型的抽象概念,并不是真实存在的。
候选者:顺便画个图吧,看完图就懂了。
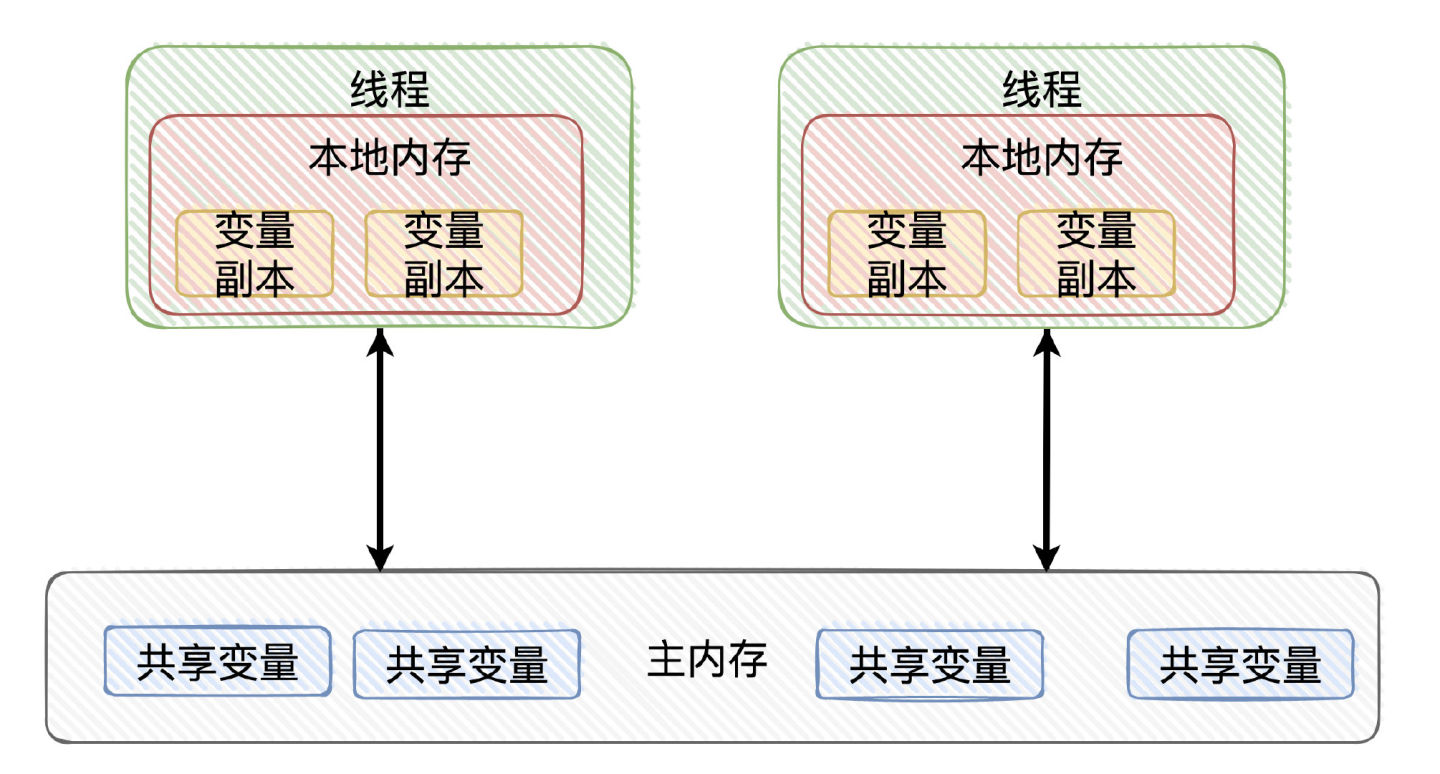
候选者:Java内存模型规定了:线程对变量的所有操作都必须在「本地内存」进行,「不能直接读写主内存」的变量
候选者:Java内存模型定义了8种操作来完成「变量如何从主内存到本地内存,以及变量如何从本地内存到主内存」
候选者:分别是read/load/use/assign/store/write/lock/unlock操作
候选者:看着8个操作很多,对变量的一次读写就涵盖了这些操作了,我再画个图给你讲讲
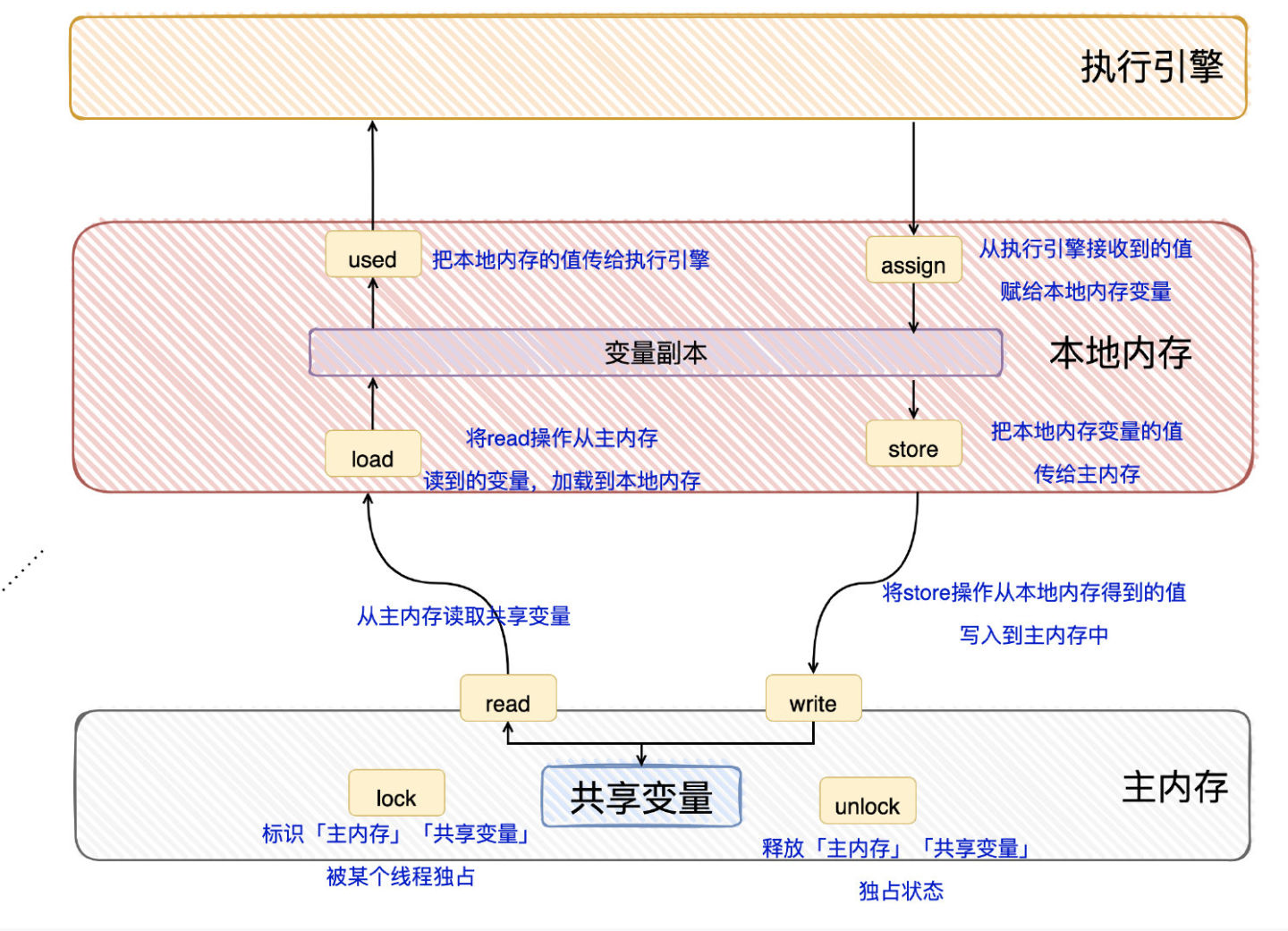
候选者:懂了吧?无非就是读写用到了各个操作(:
面试官:懂了,很简单,接下来说什么是happen-before吧?
候选者:嗯,好的(:
候选者:按我的理解下,happen-before实际上也是一套「规则」。Java内存模型定义了这套规则,目的是为了阐述「操作之间」的内存「可见性」
候选者:从上次讲述「指令重排」就提到了,在CPU和编译器层面上都有指令重排的问题。
候选者:指令重排虽然是能提高运行的效率,但在并发编程中,我们在兼顾「效率」的前提下,还希望「程序结果」能由我们掌控的。
候选者:说白了就是:在某些重要的场景下,这一组操作都不能进行重排序,「前面一个操作的结果对后续操作必须是可见的」。

面试官:嗯…
候选者:于是,Java内存模型就提出了happen-before这套规则,规则总共有8条
候选者:比如传递性、volatile变量规则、程序顺序规则、监视器锁的规则…(具体看规则的含义就好了,这块不难)
候选者:只要记住,有了happen-before这些规则。我们写的代码只要在这些规则下,前一个操作的结果对后续操作是可见的,是不会发生重排序的。
面试官:我明白你的意思了
面试官:那最后说下volatile?
候选者:嗯,volatile是Java的一个关键字
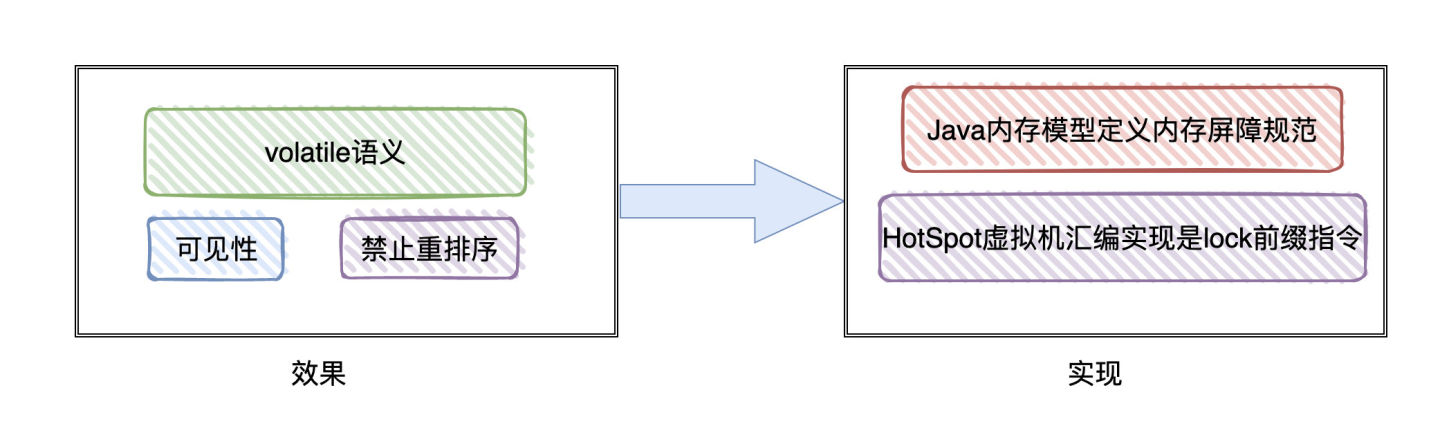
候选者:为什么讲Java内存模型往往就会讲到volatile这个关键字呢,我觉得主要是它的特性:可见性和有序性(禁止重排序)
候选者:Java内存模型这个规范,很大程度下就是为了解决可见性和有序性的问题。
面试官:那你来讲讲它的原理吧,volatile这个关键字是怎么做到可见性和有序性的
候选者:Java内存模型为了实现volatile有序性和可见性,定义了4种内存屏障的「规范」,分别是LoadLoad/LoadStore/StoreLoad/StoreStore
候选者:回到volatile上,说白了,就是在volatile「前后」加上「内存屏障」,使得编译器和CPU无法进行重排序,致使有序,并且写volatile变量对其他线程可见。
候选者:Java内存模型定义了规范,那Java虚拟机就得实现啊,是不是?
面试官:嗯…
候选者:之前看过Hotspot虚拟机的实现,在「汇编」层面上实际是通过Lock前缀指令来实现的,而不是各种fence指令(主要原因就是简便。因为大部分平台都支持lock指令,而fence指令是x86平台的)。
候选者:lock指令能保证:禁止CPU和编译器的重排序(保证了有序性)、保证CPU写核心的指令可以立即生效且其他核心的缓存数据失效(保证了可见性)。
面试官:那你提到这了,我想问问volatile和MESI协议是啥关系?
候选者:它们没有直接的关联。
候选者:Java内存模型关注的是编程语言层面上,它是高维度的抽象。MESI是CPU缓存一致性协议,不同的CPU架构都不一样,可能有的CPU压根就没用MESI协议…
候选者:只不过MESI名声大,大家就都拿他来举例子了。而MESI可能只是在「特定的场景下」为实现volatile的可见性/有序性而使用到的一部分罢了(:
面试官:嗯…
候选者:为了让Java程序员屏蔽上面这些底层知识,快速地入门使用volatile变量
候选者:Java内存模型的happen-before规则中就有对volatile变量规则的定义
候选者:这条规则的内容其实就是:对一个 volatile 变量的写操作相对于后续对这个 volatile 变量的读操作可见
候选者:它通过happen-before规则来规定:只要变量声明了volatile 关键字,写后再读,读必须可见写的值。(可见性、有序性)
面试官:嗯…了解了
本文总结:
- 为什么存在Java内存模型:Java为了屏蔽硬件和操作系统访问内存的各种差异,提出了「Java内存模型」的规范,保证了Java程序在各种平台下对内存的访问都能得到一致效果
- Java内存模型抽象结构:线程之间的「共享变量」存储在「主内存」中,每个线程都有自己私有的「本地内存」,「本地内存」存储了该线程以读/写共享变量的副本。线程对变量的所有操作都必须在「本地内存」进行,而「不能直接读写主内存」的变量
- happen-before规则:Java内存模型规定在某些场景下(一共8条),前面一个操作的结果对后续操作必须是可见的。这8条规则成为happen-before规则
- volatile:volatile是Java的关键字,修饰的变量是可见性且有序的(不会被重排序)。可见性由happen-before规则完成,有序性由Java内存模型定义的「内存屏障」完成,实际HotSpot虚拟机实现Java内存模型规范,汇编底层通过Lock指令来实现。

【Java开源】消息推送平台
我推荐一个拥有从零开始的文档的项目,既能用于毕设又可以在面试的时候大放异彩。
该项目业务极容易理解,代码结构还算是比较清晰,最可怕的是几乎每个方法和每个类都带有中文注释
拥有非常全的文档,作者从零搭建的过程一一都有记录,项目使用了蛮多的可靠和稳定的中间件的,包括并不限于SpringBoot、SpringDataJPA、MySQL、Docker、docker-compose、Kafka、Redis、Apollo、prometheus、Grafana、GrayLog、xxl-job等等。在使用每一个技术栈之前都讲述了为什么要使用,以及它的业务背景。我看过,他所说的场景是完全贴合线上环境的。
跟着README文档的部署使用姿势就能跑起来,一步一步debug挺有意思的,作者还搞了个前端后台管理系统就让整个系统变得更好理解了。并且在GitHub或者Gitee提的Issue几乎都会有回复,也非常乐于合并开发者们的pull request,会让人参与感贼强。
我相信在校、工作一年左右或常年做内网CRUD后台的同学去看看肯定会有所启发,作者会经常在群里回答该项目相关的问题和代码设计思路。
B站也在开始更新消息推送平台的视频哟!
https://space.bilibili.com/477906216?spm_id_from=333.1007.0.0
目前这个项目GitHub和Gitee加起来已经4K stars了,我相信破万是迟早的事情。 嗯,没错。这个项目叫做austin,是我写的
消息推送平台-Austin就是奔着真实互联网线上项目去设计和实现的,将项目克隆下来把中间件换成目前公司在用的,完善下基础建设它就能成为线上项目

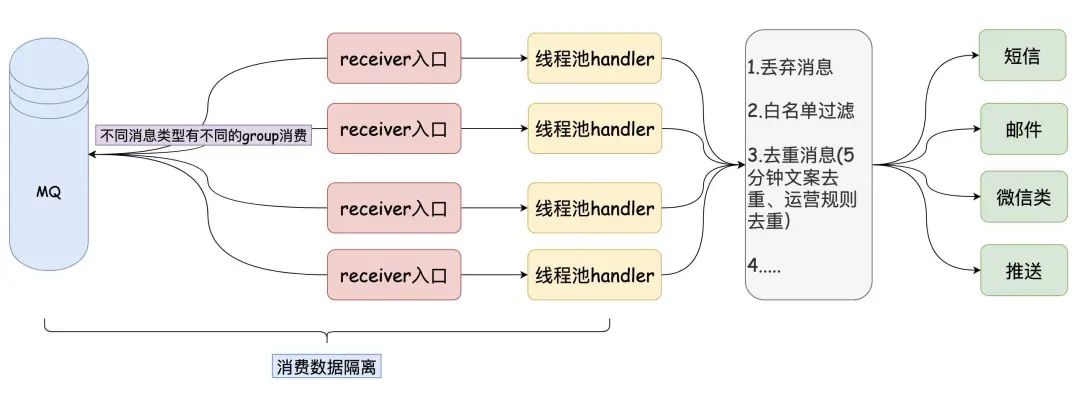
austin项目核心功能:统一的接口发送各种类型消息,对消息生命周期全链路追踪
项目出现意义:只要公司内有发送消息的需求,都应该要有类似austin的项目,对各类消息进行统一发送处理。这有利于对功能的收拢,以及提高业务需求开发的效率
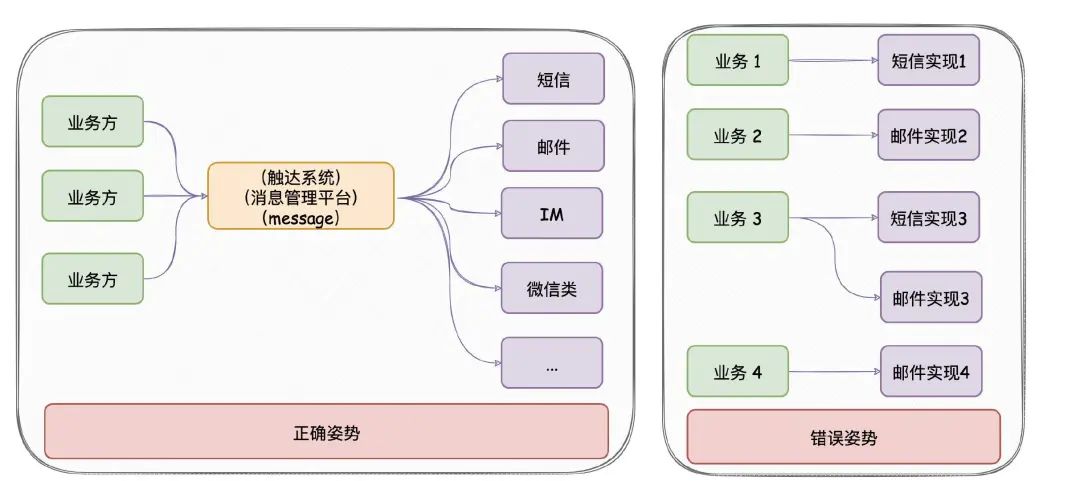
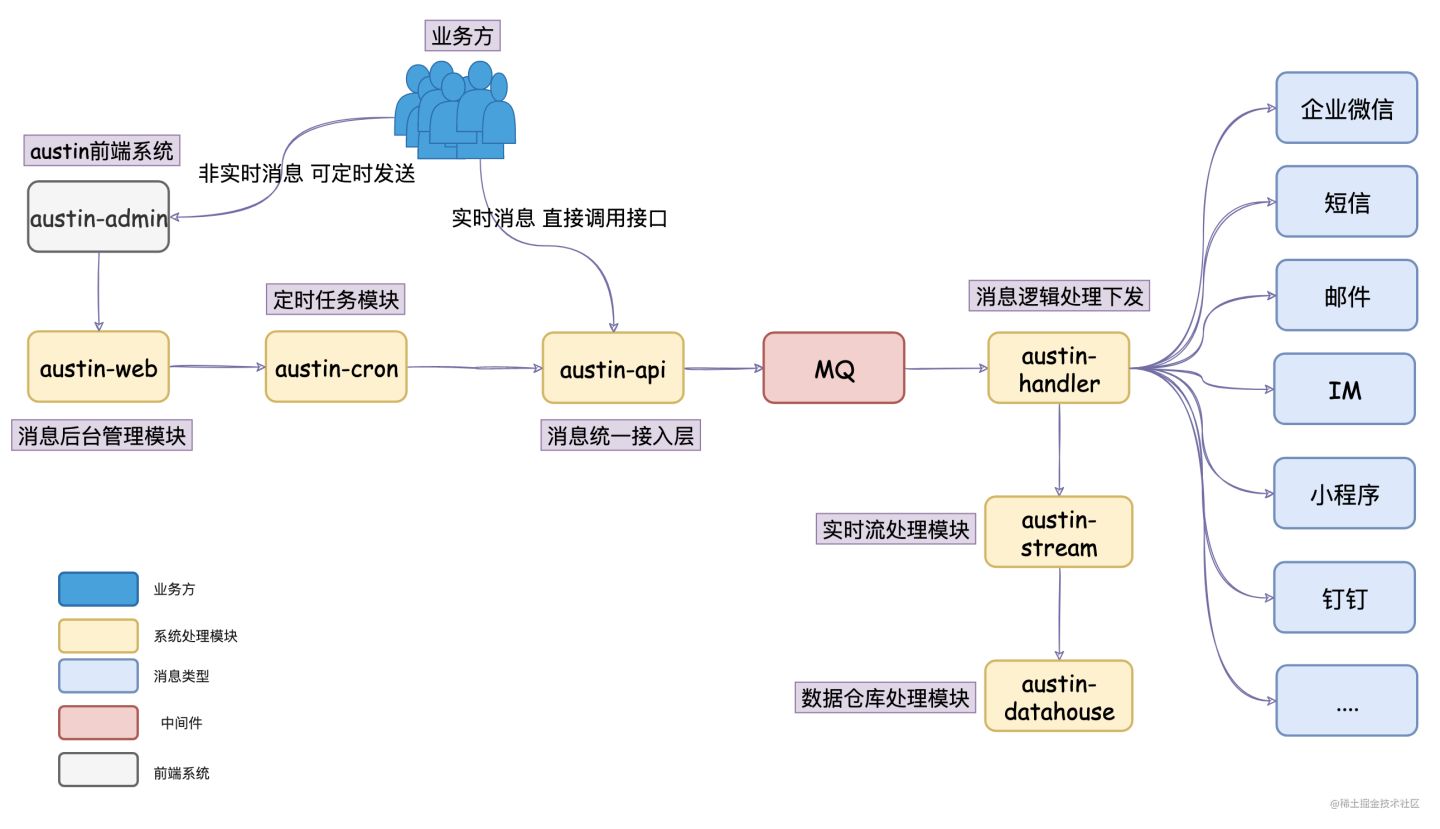
austin项目核心流程:austin-api接收到发送消息请求,直接将请求进MQ。austin-handler消费MQ消息后由各类消息的Handler进行发送处理

这不是秋招到了嘛!准备了一份Java面试宝典!工众号免费获取