目录
前言
MySQL 中的内部原理和机制非常多,前面的 sql 属于操作层面,后面的索引、事务就属于 MySQL 原理层面。如果之后要实现一个数据库,那么就必须懂得 MySQL 的运行机制和它的内部原理,所以索引、事务是面试这块必考的点。
1. 什么是索引
索引是一种特殊的文件,包含着对数据表里所有记录的引用指针。可以对表中的一列或多列创建索引,并指定索引的类型,各类索引有各自的数据结构实现。索引是一种数据结构,数据库索引是数据库管理系统中一个排序的数据结构,以协助快速查询、更新数据库表中的数据。
2. 索引的作用
数据库中的表、数据、索引之间的关系就像书架上的图书、书籍内容和书籍目录的关系。数据库中的数据存储在磁盘上,磁盘一条一条进行查找很慢,索引所起的作用类似于目录,可用于快速定位、检索数据。
3. 索引的影响
优点:提高数据库查询效率;
缺点:占用更多的存储空间,拖慢了增删改的速度;索引的维护成本很高,每次新增、删除数据都需要整理树结构,索引的底层实现使用的 B+ 树。
4. 索引的使用场景
数据量较大时,可以加索引;
如果是经常做查询的列适合使用索引,如果是经常做插入、修改操作的列不适合使用索引;
磁盘空间不足时,不考虑创建索引。
5. 索引的使用
5.1 查看索引
show index from 表名;5.2 创建索引
在创建主键、外键、唯一键时会自动创建索引,而其他索引就需要手动创建。
在建表时,给字段 k 加索引:
create table n(
id int primary key,
name varchar(20),
k int not null,
index(k)
)给一个表中的某个列创建索引:
create index 索引名字 on 表名(列名);ps:创建索引是一个非常低效的事情,尤其是表中有大量的数据,在生产中如果表中没有索引,不要贸然就创建。所以最好在创建表时就应该规划好索引。
5.3 删除索引
drop index 索引名字 on 表名;6. 索引的底层实现
索引的底层:索引的作用就是加快查找速度,而查找就需要遍历,所以索引的数据结构就不能是线性表,因为在线性表中的查找是“按照下标”访问元素,我们需要的是“按照值”查找。也不可以使用二叉树,因为当元素多了的时候,二叉树的高度就高了,高度高了比较多次数就多了,意味着磁盘 I/O次数增加。哈希表也不太适合,虽然它的查找速度很快,但是他只能进行相等判定,不能进行比较大于小于,以及范围查找。而堆只能找最大、最小值。所以最适合的是树形结构,优化二叉树,使用 B树,最后升级到 B+ 树。
数据库有多种,每个数据库又有多种引擎,不同的引擎实现了数据具体存储的结构。MySQL 最著名的引擎:InnoDB 和 MyISAM。不同的引擎存储数据的结构不同,索引的底层数据结构也可能不同。
6.1 二叉树
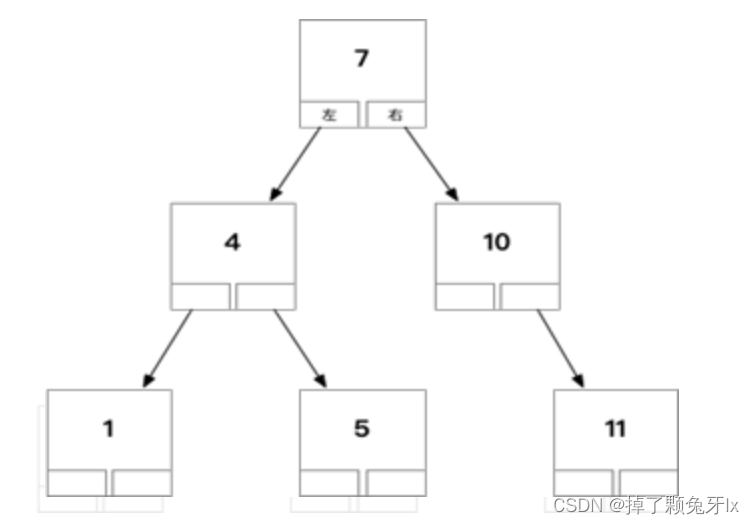
缺点:数据多之后,树的高度就高了,比较多次数就多了,意味着磁盘 I/O次数增加。维护和查询的性能不好。
6.2 B 树
B 树也称为 B - 树,是多叉搜索树的前身。B 树的每个节点上,都会存储 N 个 key 值,N 个 key 值就划分 N + 1 个空间,每个空间都对应一个子树。也就是每个节点维护 N 个数据,并最多指向 N + 1个子节点。在 B 树中查找元素,先从根节点出发,根据待比较的元素确定一个区间。比如查找 11 这个节点,先和根节点17,35比较,11比17小,在左子节点,找到左子节点,也就是第二层节点;然后对比8和12,11在它两中间,找到当前节点的中间子节点,也就是第三层节点;11再和9,11对比,11==11,找到当前节点的第二个数(11),就是结果。

优点:B树是在二叉树的基础上,增加单个节点的数据存储量,同时增加了树的子节点,缩小了查找范围。相比较二叉树高度减少,高度减少,每个节点的比较次数增加,但是磁盘的 I/O次数减少。
缺点:所有节点都保存了数据,加载时间增加。
6.3 B+ 树
B 树已经解决了磁盘 I/O 次数这个问题,但是每次查询获取的不一定都是有用数据。所以我们可以把存储的数据放在最后的节点上,也就是叶子节点上,其他非叶子节点只保存索引数据(key值),不存放存储数据,这样就使非叶子节点整体的空间变小。这样就有了 B+ 树。
B + 树就是为了将索引数据和存储数据拆分开的多叉搜索树。
B+ 树的重点在于:所有的查询最终都会落到叶子节点上;所有的存储数据都是放到叶子节点上的,非叶子节点只保存索引数据。
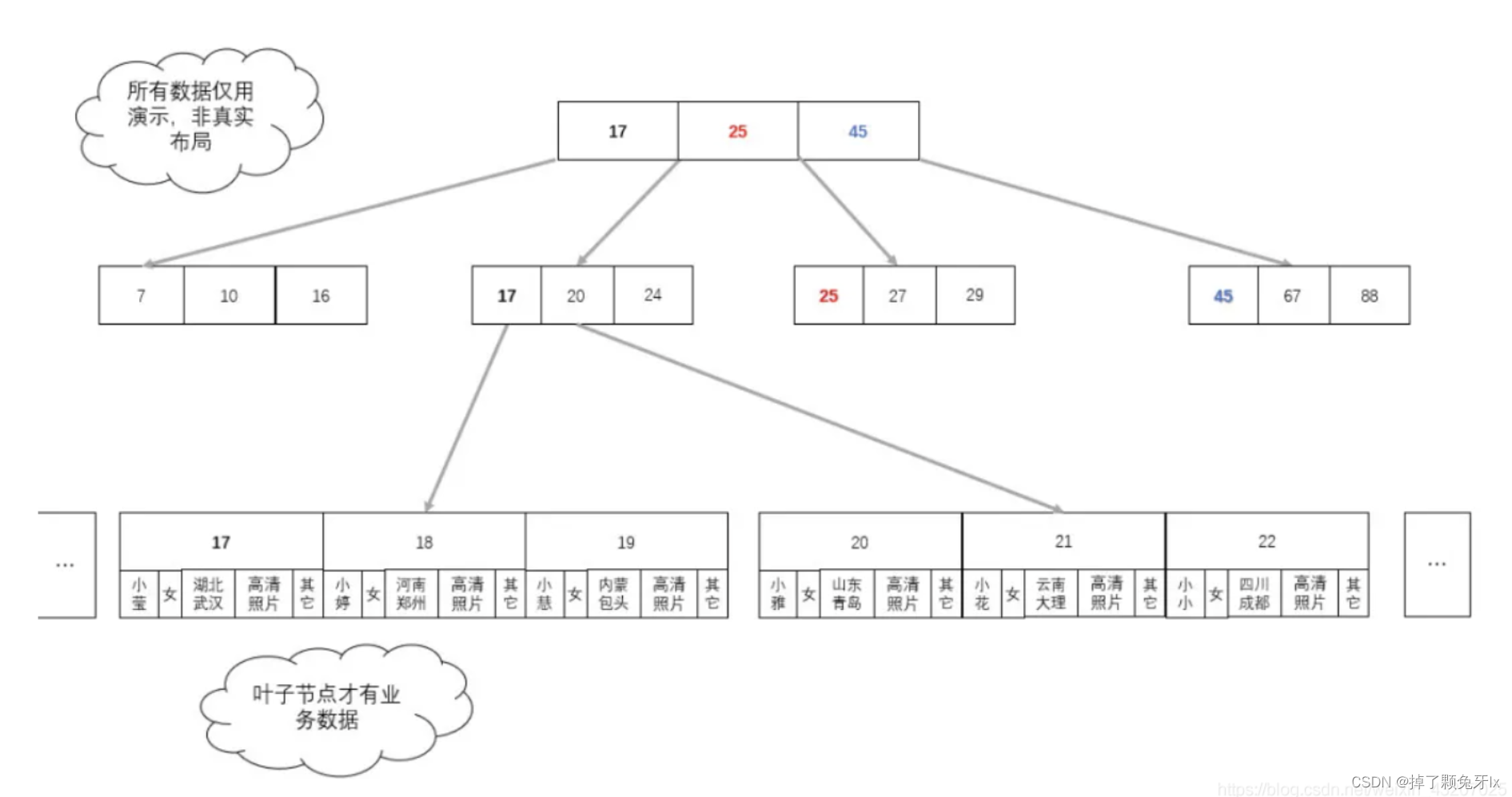
将所有的数据存储(载荷)都放在叶子节点上,因为数据中索引和数据是分离的,所以我们要把真实的存储数据换成所在地址。
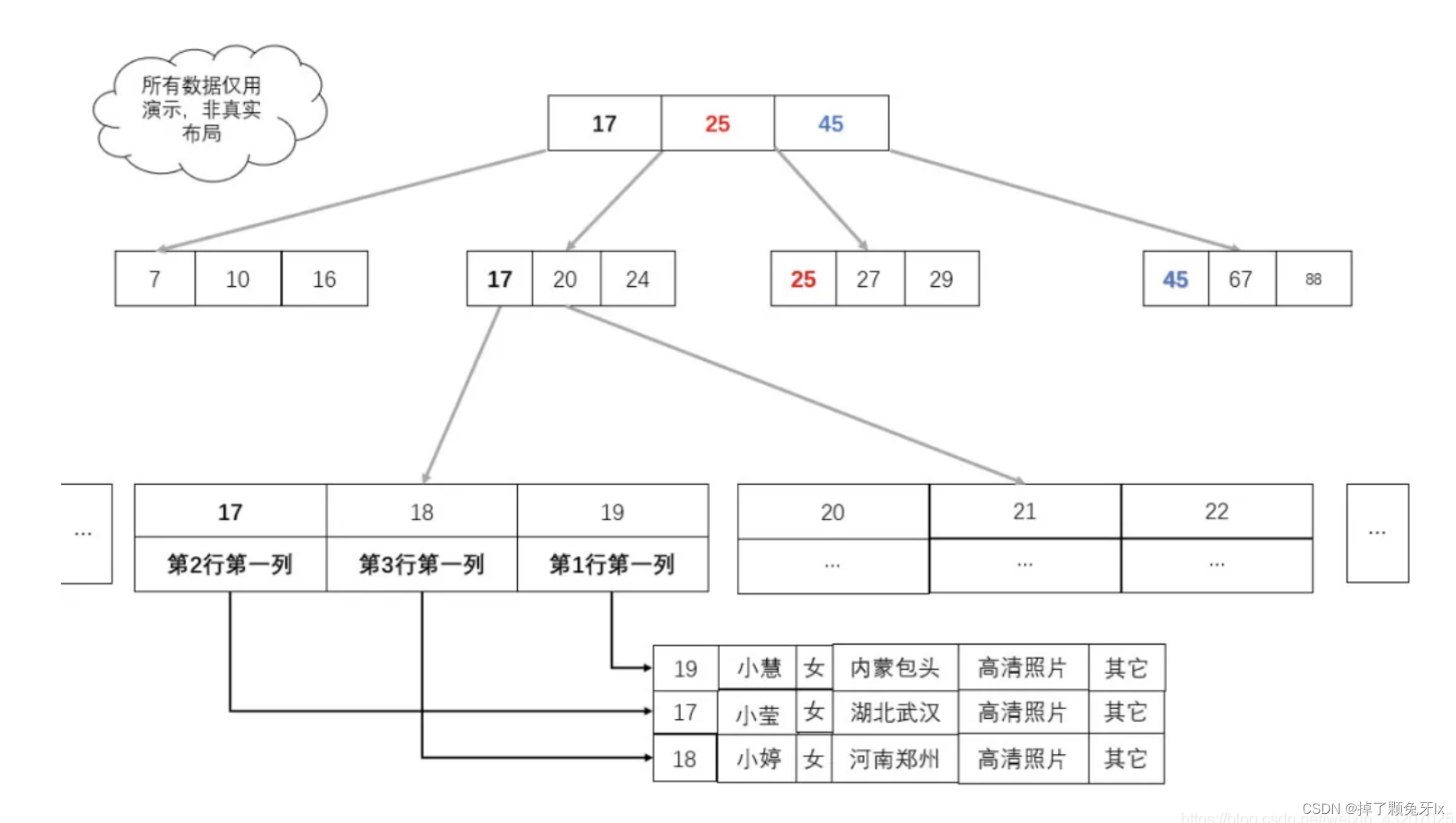
7. 索引的分类
索引的分类有以下⼏种:
主键索引:⼀种特殊的唯⼀索引,不允许有空值,⼀般是在建表的时候同时创建主键索引(通过 primary key)。
⾮主键索引(⼆级索引):除主键索引之外的其他索引。
唯⼀索引:不能重复的索引。
普通索引:可以重复也可以为 NULL 的索引。
联合索引:使⽤多个字段联合组成的索引。
活动地址:CSDN21天学习挑战赛