已解决SyntaxError: (unicode error) ‘unicodeescape’ codec can’t decode bytes in position 2-3: truncated
报错代码
一个粉丝群里的小伙伴提出的问题(xlrd库读取Excel表格报错):
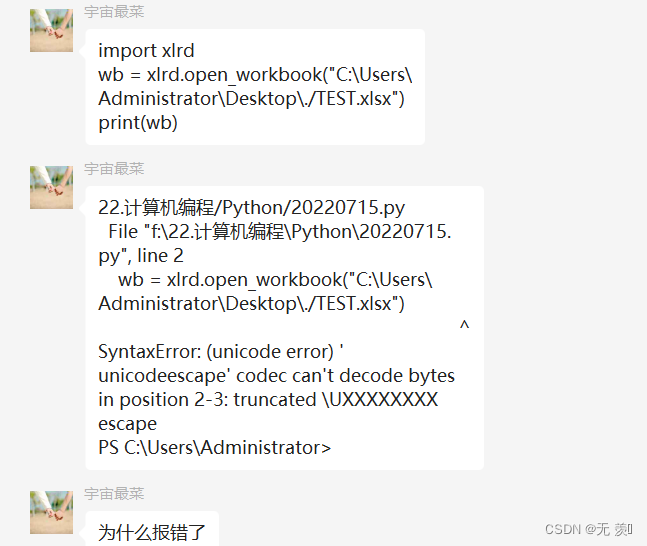
然后我把他的代码复制过来看了一下就明白为啥了:
import xlrd
wb = xlrd.open_workbook("C:\Users\Administrator\Desktop\./TEST.xlsx")
print(wb)
报错信息:

File "E:/Python学习/2.py", line 2
wb = xlrd.open_workbook("C:\Users\Administrator\Desktop\./TEST.xlsx")
^
SyntaxError: (unicode error) 'unicodeescape' codec can't decode bytes in position 2-3: truncated \UXXXXXXXX escape
报错翻译
报错内容翻译:
语法错误:(unicode错误)“UnicodeScape”编解码器无法解码位置2-3中的字节:截断\uxxxxxxx转义
报错原因
报错原因:在Python中 \ 是转义符,\u表示其后是UNICODE编码,因此\User在这里会报错。
解决方法
解决方法1:在字符串前面加个 r(rawstring 原生字符串),可以避免python与正则表达式语法的冲突!
import xlrd
wb = xlrd.open_workbook(r"C:\Users\Administrator\Desktop\./TEST.xlsx")
print(wb)
解决方法2:每个\前面再加个\表示转义,斜杠就能正常表示了
import xlrd
wb = xlrd.open_workbook("C:\\Users\\Administrator\\Desktop\\./TEST.xlsx")
print(wb)