编译器LLVM-MLIR-Intrinics-llvm backend-instruction
参考文献链接
https://mp.weixin.qq.com/s/G36IllLOTXXbc4LagbNH9Q
https://mp.weixin.qq.com/s/5LW3TQFsEEnWiGF5lXZV5A
https://mp.weixin.qq.com/s/WcRRy4qJE8n_DFYf8a5INA
LLVM IR,SPIR-V到MLIR
机器学习编译器(ML Compiler)的实践刚开始不久。经过几年的探索和演进,ML Compiler已经成为ML System中最重要的一环。ML Compiler既有其自身的特点,又和传统编译器有着密切的联系;既有新的挑战,又有很多前人的经验可以借鉴,是个有趣且有高价值的话题。
编译器 (Compiler) 通常是各种提高开发效率的软件工具链中不可或缺的部分。编译器一般被认为是黑箱,吃进高抽象层次的源程序,产生语义不变,可在目标硬件上运行的低层次机器码。当然,编译器也有其内部结构,中间表示 (IR: Intermediate Representation) 串联起编译器内各层级和模块。
中间表示对编译器至关重要,也如编译器一样百花齐放。在日常工作中有幸能够涉及三种主流编译器中间表示或者基础设施——LLVM IR, SPIR-V, 以及 MLIR, 尤其对于后两种,都参与了早期的开发。
编译器与中间表示
在讨论各种具体中间表示之前,先让总体看一下编译器和中间表示。
抽象与语义(Abstractions and Semantics)
自人类文明产生至今,虽然科技演进的速度飞快,人脑却没有多少变化。理解不断爆炸式提升的复杂度的方式是抽象 (abstraction)。抽象帮助忽略细枝末节,着眼于主要矛盾。抽象减少了人脑需要处理的变量数量,减轻了人脑的处理负担,这对于求解复杂问题至关重要。自抽象而产生的问题描述被称为模型 (model),例如,在编程语言中,有机器模型 (machine model) 用以描述底层计算架构;在数据系统中,有数据模型 (data model) 用以描述数据关系结构;在分布式系统中,有系统模型 (system model) 用以描述时序和容错假设。模型通常是原体的理想化描述。有时模型会离现实情况非常远,例如,估计没人能够设计准确的股市模型。但无论如何,模型始终是保持复杂度可控不可或缺的工具——模型能够给清晰明确的语义 (semantics), 即因定义而一定成立的原理。有了这些,才能对模型所描述的原体进行逻辑甚至数学层次的严谨推理 (reasoning)。人脑本质性喜欢逻辑与解释(神话、科学、甚至迷信都是人类试图解释世界的方式)。此处似乎离题了,实际上只是在用广义的方式引入一些常见的编译器开发术语——抽象、模型、语义、推理。当然,计算机可行的其它领域也会关注这些方面,比如,希望面向对象的“类”有良好的抽象,但这些领域通常多是“设计艺术”。相对而言,编译器更多关注理论科学的方面;编译器需要明确的语义用来证明 (prove) 代码转换的正确性。这就引入了——
正确性与优化(Correctness and Optimization)
编译器的首要任务是保证转换的正确性 (correctness);优化 (optimization) 是次要的考虑。产生不符合源程序意图的非常“优化”的代码没有任何意义。在整个编译流程中正确性都需要得到保障。离开清晰的语义,正确性就无法得到定义和保证。因此编译器对语义未知的操作 (operation) 无法进行任何转换。当然,这并不包括每一个微小转换,编译器内部也有不同层次的“边界”。每个转换遍历 (pass) 保持原子性;在其内部,可能会临时违反源程序语义,但在每个转换遍历之后,中间表示应该是正确的。编译器极度依赖每个遍历之后的中间表示验证 (validation) 来保证正确性。在正确性得到保障之后,才可以考虑优化。生成高性能代码似乎是无可争议的目标,但实际上也充满了微妙的细节。不同的源程序有着不同的模式,不同的硬件喜欢不同的指令流。编译器处于源程序和目标硬件之间,实际上能够动用来提升性能的手段是非常有限的。编译器需要在大量的限制因素下做抉择,并且保证这些抉择对大多数场景适用,特别是针对 C++ 这种通用编程语言。这其实是非常高的要求,导致最后只有少数一些转换(像是不可达代码消除DCE、常量折叠constant folding、指令标准化canonicalization等等)可以全局默认开启,很多其他转换只能在之后的第二阶段,针对目标硬件优化时使用。在编译器一步步转换程序的过程中,越来越多的高层次的简明的信息被打散,转换成低层次的细碎的指令,这个过程被称为代码表示的递降 (lowering)(不知道公认的中文翻译是啥,只能自己来了。);与之相反的过程被称为代码表示递升 (raising)。后者通常远比前者困难,因为后者需要在芜杂的细节中找出宏观脉络。代码表示递降是编译器的通常转换方式。不难理解,越晚执行的转换越有结构性劣势,原因是缺乏高层次信息。这限制了目标硬件相关优化所能解决的问题也决定了实现的复杂程度。其实这里的本质性问题是强耦合 (coupling)。这种强耦合绑定了不同应用领域(尤其是使用通用编程语言的情况)和编译器中不同垂直转换路径(尤其是编译器使用统一IR的情况)。解耦 (decoupling) 是在各种领域中实现更加复杂系统和支持更加高级场景的一般方式。可以预见,领域专用语言以及编译器内部解耦能够更好地释放编译器的优化能力。在接下来的 MLIR 章节会进一步展开这一点。总而言之,成熟的编译器可能会帮助其支持的各种场景挖掘出大部分的性能,比如说是 80%,但期待编译器对所有应用达到最优性能是不切实际的。编译器的真正优势是帮助节省达到前 80% 性能所需的工程投入,让可以集中资源在剩下的 20% 或者其他核心问题上。
效率工具
尽管已经近乎陈词滥调,还是再一次强调,编译器只是提升开发效率的工具。写汇编码或者机器码也许会显得特别酷,却很难是高效的开发方式(不过,对于某些适合的场景,通过手写汇编来获取极限性能却是非常合理和常见的方式)。 能够使用高层次抽象的语言可以让开发者忽略底层芯片上具体的寄存器和指令,从而避免陷入耗时易错的繁杂细节之中,是对开发效率的极大提升。这就涉及管理不断提升的复杂度的方式——有了针对不同层次的抽象,只需要创建工具来对这些抽象进行自动转换。当然,并非所有的转换都可以自动化。对于可行的,都可以把这种工具看作广义上的编译器。比如,在数据处理系统中,Apache Beam 提供了统一的语言来描述任务。Beam 会把这些任务转换到具体的执行引擎 (Spark, Flink, 或者其他) 的描述。这些执行引擎再进一步把这些任务编译成运行在具体机器上的操作并负责调度。这里的整个流程也可以看做是一种编译。类编译器的工具通过隐藏底层细节、提供高层次抽象而极大地提升了开发者的效率。编译器通过对中间表示进行一系列变换 (transformation) 来链接不同层次的抽象。
IR的形态和兼容性
中间表示只是程序的一种表示,其设计注重支持变换操作,使其正确和高效。当然,后面也会发现中间表示也会实现一些其他目标。在早期,编译器通常有单一中间表示,但随着编译器的演进,情况变得更加复杂。现代编译器通常会有多层级的内部表示。比如,用 Clang 来编译 C++ 程序通常要经过 Clang AST, LLVM IR, MachineInstr, MC 等等多个层级[1]。针对 GPU,也会发现完整编译器被拆分成离线 (offline) 和在线 (online) 两部分。两部分之间的程序表示,像是 SPIR-V,也会被称为中间表示,但其实已经不再局限于编译器内部了。中间表示可以有三种形态:用以高效分析和变换的内存表示 (in-memory form),用以存储和交换的字节码 (bytecode form),以及用以阅读和纠错的文本表示 (textural form)。基于使用场景,通常会见到不同的设计折中来侧重不同的形态和提供不同程度的兼容性。比如,LLVM IR 更侧重于编译器内部使用,所以核心是高效的内存表示并提供相对较弱的兼容性以便于迭代改进。而 SPIR-V 则设计为硬件驱动的输入程序表示,所以更注重于字节码的高效处理并提供强兼容性。此处无所谓对与错,只是满足不同的需求而已。但这些设计折衷依然对整个上层的生态系统产生深远影响。
IR的设计理念
现实中并不存在中间表示的普适设计规则。大部分情况下,中间表示的设计都是在各种限制条件下权衡各种利弊然后做出折中选择。这些选择会考虑具体问题的普遍性或者特殊性、给整个编译器栈带来的组合复杂性、对各种变换的影响等等。总体上,希望:
- 中间表示中的操作 (operation) 能够具有清晰明确的语义。这是一切的根基。
- 在这之上希望操作能够相互正交 (orthogonal),这有助于定义标准 (canonical) 形态以减少变换需要考虑的情况。
- 另外也会希望在同一中间表示的不同部分中避免出现重复信息。重复信息在各种变换后有很大概率会导致中间表示的不一致,从而导致错误编译。
- 尽可能地保持高层次信息也是非常有好处的,因为在代码表示递降后想重新找回丢失的信息很难。
- 以及其他种种。
听起来似乎都是非常有道理的指导哈?其实对上面的大部分理念都可以举出反例: - 如果硬件实现了某特殊的功能模块,希望能够提供相应的软件和中间表示抽象, 即便这会“破坏”中间表示的正交性。举个栗子,在 GPU 中间表示中,除了基础的乘和加指令,都有 FMA 指令。
- 在 SPIR-V 中,一个编译单元 (module) 会提前声明所需要的硬件能力 (capability)。这些信息完全是可以通过对中间表示的主体进行分析来得到的,所以是重复的信息。但是存在减少了硬件驱动所需做的工作,从而加速了实际运行。
- 如果输入语言已经足够低层次,比如 C,那么没有任何办法,只能想办法提升抽象的层次来产生更好的代码,像是对标量代码的自动向量化 (vectorization)。
以上其实只是试图说明中间表示的设计真的充满了依据领域和场景的折衷。如之前所述,如果同一个编译器试图支持多种应用,或者同一中间表示试图支持多个垂直转换路径,非常容易面临相互冲突的目标,使在讨论中达成一致变得很困难。这也意味着丧失了迅速迭代和演进的能力,在有些情况下代价很高。对编译器进行解绑 (unbundling)——面向特定领域、不同层级和模块化的中间表示——非常有用。这样每个领域可以以最符合其领域特征的方式来设计编译器,不同层级和模块化的中间表示也可以只关注场景来做最合适的取舍。
LLVM IR
LLVM 最初发布于 2003 年。在经过了接近二十年的开发之后,LLVM 技术栈已经非常成熟,并有一个极好的生态系统。LLVM 支持许多前端语言和后端硬件,许多软硬件厂商有衍生版 LLVM 来针对自己产品的提供各种附加功能。想 LLVM 对于整个业界的重要性无需再赘言。
解绑和模块化编译器(Decoupling and modularizing compilers)
LLVM 带来的最重要的东西是对编译器解绑和模块化的实践,由此诞生了大量优秀的编译器库和工具。在前 LLVM 时代,编译器通常是特殊设计并高度耦合。这些编译器虽然也分为三段——前端 (frontend) 用来对源语言进行解析,中端用来进行优化,后端 (backend) 用来产生机器码,但一般只针对某一特定语言(含衍生语言)或者目标硬件,编译器内部各个模块也没有明确界限。不同的编译器栈基本不共用代码,无法组合不同编译器栈中的现存的前端或者后端,从而无法真正发挥三段式编译器的优势。LLVM 依靠解绑带来巨大变革。LLVM IR [2]显而易见地处于 LLVM 生态的核心地位。LLVM IR 使用控制流 (control flow)、基础块 (basic block)、以及静态单赋值 (SSA) 形式来表示程序。这种表示是完备的,LLVM 从而可以独立于其他表示形态,实现作为前后端之间的单一桥梁。这就完全地解绑了编译器的前后端。[3]这之后所需的只是遵循模块化的最佳实践。LLVM 的代码是组织成一系列库 (library) 的。库的组织形式当然有其问题,但确实是经过实践检验的系统级模块化方式。库定义了不同模块之间的分界。通过合适的编程接口 (API),可以选择并且组合不同的编译器功能来完成不同的任务, 像是通过调用 Clang 功能库实现静态分析以及代码格式化。这些都是非常有用的。
文本IR形式(Textural IR forms)
除却解绑和模块化,LLVM IR 还带来了许多其他易用性和开发效率上的提升。在内存表示之外,对文本表示的原生支持将传统的 UNIX 哲学带入了编译器。UNIX 哲学讲求每个工具负责一个简单任务,然后利用文件 (file) 以及管道 (pipe) 串联不同工具来实现复杂功能。在 UNIX 系统中,文件是对资源的统一抽象。尤其是文本文件,基本是大多数工具的信息交换媒介。文本文件足够灵活强大,能够支持不同的需求,同时又直观易用。在一个处理流程中(例如cat | cut -f2 | sort | uniq -c)打印中间状态是非常自然的查看和纠错手段。长远来看,简单易用无可匹敌。当然,编译器的组件即便是模块化后也很难说是“简单”的工具。但 LLVM IR 的文本表示实现了 UNIX 文件一样的用途,能够串联起各个转换遍历 (pass),方便查看中间状态。这自然延伸到使用 FileCheck 来测试编译器本身,因为现在可以输入可读的文本表示并检查其输出。
一体两面
LLVM 是编译器开发的大幅跃进。其良好的设计和活跃的社区带来了许多提升效率的工具。但凡事都有一体两面。基于现有的 LLVM 生态,可以越来越明显地看到有些设计折中带来的影响。
中心化和各种衍生
LLVM IR 在整个 LLVM 生态中处于中心地位,这是编译器前后端解绑的基础,但这也意味着完整的编译路径必须通过 LLVM IR。因为 LLVM IR 的核心地位,对其进行修改需要满足极高的条件。各种工具都基于 LLVM IR,各种公司或者组织的内部流程都会通过实现。即便无需频繁地打通整个路径,对 LLVM IR 的局部小修改也会带来意想不到的间接效应。自然而然,这就意味着改动缓慢,需要长时间高强度的讨论,以及各利益相关者的同意。这对于保持 LLVM IR 本身的质量是必须的,但如果只是有一个非常特殊的需求, 就很难劝服整个生态做出相应的修改。一种常见的方式是分裂 LLVM,把修改保持在本地,创建衍生版。这依然会有很高的工程代价。LLVM IR 的中心地位对把所有改动贡献回上游更加友好。LLVM 的代码库每天有将近一百次提交,这些提交添加各种新功能或者修复各种问题。如果不及时追踪上游的提交,衍生版会偏离的越来越严重,最后可能无法再合并。另一方面,持续不断地追踪则意味着专门的人力和资源投入,很多小机构无法一直负担。总而言之,后果就是在现实中有各式各样的 LLVM 衍生代码,这些代码追踪着不同的上游版本, 有着不同的新鲜度。如果把全球作为一个整体来看,维持和更新这些衍生代码消耗了大量的人力和资源。当然这并不能说是 LLVM 独有的问题。以开源模式开发的大规模复杂系统在被各种组织商业化的时候都有类似问题。但类似项目通常会在设计时就考虑本地定制化的需求。相较而言,LLVM IR 的绝对中心地位使得其很难被本地定制化。某种意义上讲,这就是一种强耦合;MLIR 就在解耦上再进一步。
演进与兼容性
LLVM IR 的另一设计是能够协同演进中间表示和各种编译器分析以及变换。这对于工具链本身质量的提升是至关重要的,但同时带来了相对较弱的兼容性保证[4]。当然社区不会无缘无故引入不兼容的变动,只是这一可能性确实存在。
编译器存在于近乎操作系统的层级,所以很容易理解人们为什么使用 LLVM IR 来作为程序的表示形式传送给硬件驱动,特别是考虑到 LLVM IR 极好的生态系统以及原生的字节码支持。但是 LLVM IR 真正的使用场景是作为不同软件模块之间的程序表示;涉及硬件和驱动则完全是另一个故事。硬件设备会存在于像是手机之类的终端产品之中,这些终端产品被产品制造商和最终消费者所掌控。驱动的升级是无法得到保障的,因此驱动依赖的 LLVM 库也可能永远无法得到升级。
实际上已经有许多如此使用 LLVM IR 的尝试,有成功,也有失败。一个比较突出的例子是 Standard Portable Intermediate Representation (SPIR)。SPIR 是为表示 OpenCL 设备程序 (kernel) 而设计的,锁定了某一版本的 LLVM IR,使用 LLVM 内联函数 (intrinsic) 和元数据 (metadata) 来定义 OpenCL 的计算原语以及定义。但 Khronos Group 逐渐意识到 LLVM IR 实在不适合这种任务,遂转向了设计与开发 SPIR-V。
SPIR-V
SPIR-V 最初发布于 2015 年。SPIR-V 是多个 Khronos API 共用的中间语言,包括 Vulkan, OpenGL, 以及 OpenCL。定义全新的中间表示并且开发整套工具链需要大量的工作,但对 SPIR-V 的投入依然被认为是值得的。
标准规范的扩展性和兼容性
Khronos Group 的标语是“连接软件与硬件”,简明扼要地总结了任务。这种连接是通过标准规范 (standard) 和编程接口。Khronos Group 定义标准规范以及编程接口;硬件厂商提供硬件实现,软件厂商则可以让软件在所有支持的平台与设备上运行。Khronos Group 定义维护了很多标准规范,比较著名的有 Vulkan, OpenGL, 以及 OpenCL。标准规范的主要目的是抽象不同的硬件实现,并提供对上层软件的统一接口。但同时,标准规范也需要能够支持硬件特有的功能。这是对现实中存在各式各样硬件的一种承认,也让软件能够深度挖掘某些具体硬件的性能。这两个看似相互冲突的目标通过分等级的特性 (feature) 体系 (hierarchy) 得以支持。Khronos Group 内部有清晰的流程来管理各种特性,包括提议新的特性,提升某厂商专有的特性为通用特性等等。SPIR-V 也是一种标准,所以具有相同的设置。除了核心特性之外,SPIR-V 支持通过多种机制来扩展其功能,包括添加新的枚举值, 引入新的扩展 (extension),或者通过某个命名空间引入一整套指令 (extended instruction set)。其扩展也分为不同等级——厂商自有扩展 (vendor specific)、多厂商联合支持的扩展 (EXT)、 以及 Khronos 级别的扩展 (KHR)。任意厂商都可以提议新的扩展,但扩展越接近核心级别,就需要越多的厂商复议,并且要经过愈发严格的审核和批准流程。总体上 SPIR-V 和其工作组 (working group) 分别从技术和组织上提供了框架来支持标准的演进和扩展。[5]LLVM IR 也提供一些方式来扩展其中间表示,尤其是内联函数 (intrinsic) 和元数据 (metadata),但难以想象其支持所有厂商的各种自有内联函数,更不用说引入各种厂商自有的类型以及指令模式到核心 LLVM IR 指令中。除此之外,连接软硬件的标准规范也非常注重稳定性和兼容性,因为硬件驱动的更新频度远低于软件工具链。驱动在设备的生命周期内即便是永远得不到更新也并不稀奇。比如,许多在低端 Android 手机上的 Vulkan 驱动停留在发布于 7 年前的1.0 版本。如果使用 LLVM IR 作为设备程序表示 (kernel),则有很大的可能程序会由近期 LLVM 版本的工具链产生,但是驱动却依然停留在很早期的版本。这种版本错配会造成各种各样的麻烦问题。相对而言,SPIR-V 则通过版本和扩展机制以及稳定的字节码提供了必须的稳定性和兼容性。
稳定的字节码(Stable binary form)
完整的 GPU 编译器被分为两部分——首先通过离线工具链从高层次源代码生成 SPIR-V,然后通过驱动内部编译器将 SPIR-V 在线编译成机器码。虽然像 LLVM IR 一样在整个编译流程中处于“中间”位置,SPIR-V 更侧重于驱动内部二次编译的高效,因为这一步在运行时进行。所以 SPIR-V 的核心是其字节码。其编码有很多简化驱动二次编译的考量,像是用各种提前的显示声明来避免运行时复杂的分析。SPIR-V 并没有在规范中指定内存表示或者文本表示,这些都是实现 SPIR-V 标准规范的工具链自行定义的。比如 SPIRV-Tools 有其自己的内存表示和文本表示, 同样 MLIR 中的 SPIR-V dialect 也是。
GPU 领域专用
至此解释了 SPIR-V 的 standard 和 portable,却还并未涉及其中 IR 的部分。其实 SPIR-V 的 IR 部分和 LLVM IR 相差并不太大。SPIR-V 借鉴了很多 LLVM IR 的设计——同样是由控制流、基本块、以及静态单赋值来表示程序。指令的粒度和 LLVM IR 也相差不大。SPIR-V 中独特的部分在于对很多 GPU 概念的原生支持。这种支持通过很多 SPIR-V 独有的机制来实现,比如 decorations, builtins, 以及特殊的指令(像是导数计算、图像取样)。另外为了支持图形图像和高性能计算的两种使用场景, SPIR-V 中有许多执行模型和模式。当然,对图形图像也有 structured control flow 的特殊需求。[6]一个 GPU 为主的标准规范需要原生支持各种 GPU 概念,能够提供不同等级的扩展需求, 以及提供稳定和兼容的字节码。这些需求并不符合 LLVM IR 的设计理念,所以 Khronos Group 推出了 SPIR-V。但是设计一套中间表示只是个开始,围绕其开发和维护整套工具链需要持续不断的工程投入。SPIR-V 与 LLVM IR 完全无关,SPIR-V 的编译器栈无法利用现有的 LLVM 库。所以 SPIR-V 的整个栈是从头开始独立开发的,从汇编、反汇编,一步步到各种语言的编译器和优化。如果当时能够有一套帮助开发编译器的基础设施——
MLIR
MLIR 在 2019 年底合并到了 LLVM 代码库,所以才开源开发了两年左右。个人感觉一个生态至少需要五年才能相对完善。从这个角度,MLIR 尚处于非常早期,许多开发尚待进行。但从目前的发展来看,MLIR给编译器开发带来了许多新颖的想法和深远的改变,比如通过基础设施化来进一步解耦编译器的中间表示。
基础设施化
基础设施化 (infrastructurization) 其实是技术演进的自然终点 (endpoint)。成为基础设施意味着一项技术已经足够成熟并且得到广泛部署。变成基础设施后,新的技术变革在其之上产生。电力、网络、公共云等等,都符合这个潮流。上述都是超大规模的基础设施化。基础设施化同样适用于影响规模小的技术,因为能够通过共用来降低开发成本, 并让每个人只关注其核心商业逻辑的实现。
很多人通过机器学习编译器了解到 MLIR。这确实是 MLIR 最初关注的领域,但 MLIR 其实有着更加广泛的应用范围。MLIR 是用来开发编译器基础设施。提供一系列可复用的易扩展的基础组件,用来搭建领域专用编译器。在 LLVM IR 和 SPIR-V 中,有唯一的中间表示,其中含有完备的指令集来编译所有的 CPU 和 GPU 程序。MLIR 中则没有完全处于中心地位的中间表示。MLIR 提供基础设施来帮助定义 operation 以及将逻辑相关的 operation 组合成 dialect。另外,MLIR 也提供一些普适的 pattern 或者 pass,这些 pattern 或者 pass 并不与具体的 operation 绑定,能够自适应。[7]
无论是对 operation 还是 pattern/pass 的支持都要求 MLIR 以更加细的粒度看待编译器。在 MLIR 中,operation 不再是最基础的部件,粒度进一步细化到类型, 值, attribute, region, 以及 interface (例如 attribute/type/operation interface).[8]
Operation 可以有任意数量的输入、输出、attribute,并包含任意数量的 region。其中 region 能够表示 operation 之间的嵌套关系,从而简化编译器的分析和转换。Operation 可以实现 operation interface,pattern 和 pass 绑定的是 operation interface,由此而实现与具体 operation 的解绑并做到自适应。
MLIR 里面的概念都设计的比较抽象,目的是能比较好地映射到不同的领域和场景。
Dialects, dialects, dialects
当然,这套基础设施存在的目的是帮助搭建最终编译器。在写 C++ 程序的的时候会调用 STL 或者更加高层次的库,很少会从头开始实现所有的细节。另外,基础设施也需要与其支持的领域协同发展,因为使用场景中会提供很多需求。因此,MLIR 代码库中自带很多用来给各种层级概念建模的 dialect。[9]
MLIR 的 dialect 生态目前还在扩张演进阶段,但 dialect 之间的组织结构以及有些 dialect 已经相对稳定了。比如有 LLVM 和 SPIR-V dialect 作为与其他系统转换的边界 dialect。(其实 MLIR 可以同时表示 LLVM IR 和 SPIR-V 这一点也表明了 MLIR 的基础设施角色。) 抽象层次居中的有 Linalg, Tensor, Vector, SCF dialect,协同合作用来生成代码。另外,MLIR 中还有 Affine, Math, Arithmetic dialect 用来描述底层计算。在 AI 框架层面,有 TensorFlow, TFLite, MHLO, Torch, TOSA 进行对接和导入模型。除此之外,还有很多其他用途的 dialect,像是 PDL 用来定义编译器转换等等。
Alex 之前在 MLIR 论坛上分享的各 dialect 之间的关系[10]非常值得一读,之后也会写下理解。这些各式各样的 dialect 和以后包装而产生的局部或者完整的转换流程将极大简化领域相关编译器的开发。
进一步解耦编译器和中间表示
其实基础设施化以及由此产生的大量 dialect 都是进一步解耦和模块化编译器以及中间表示的一种自然结果。唯一的中间表示被许多以 dialect 形态存在的部分的中间表示取代。没有某个部分中间表示再处于中心地位,都是按需组合。如果现有的 dialect 不能满足需求,定义新的 dialect 非常简单。再过几年待 MLIR 更加完善后,可以预见,开发领域专用编译器只需要新加自己的边界 dialect 来定义项目相关的 operation,之后就是选取和组合现有 dialect 来形成整体的流程。如果这个构想实现,那肯定会极大缩减开发所需工程投入。
另外,进一步解耦中间表示也让可以灵活地根据领域进行设计和折中。只需选取所需的部分中间表示来组合成完整编译器,不再需要全盘接收像 LLVM IR 一样的一套完整中间表示。因为 interface 的存在,扩展模块的更能也变得更加简单——既可以定义新的 operation 来实现已有的 interface,也可以定义新的 interface 然后支持现有 operation。
换言之,LLVM IR 天然中心化并且偏好统一的编译流程,MLIR 的基础设施和 dialect 生态则天然是去中心化并且偏好离散的编译流程。
技术的一般发展趋势是从单一的强耦合整体到适用不同场景的多种多样的选择。对于技术栈的上层而言,这尤其明显,因为越往上越接近用户和商业需求,而用户和商业需求本身就各式各样,由层出不穷的前端框架可见一斑。
技术栈的底层一般相对稳定。少数几种硬件架构、编译器和操作系统统治很多年。但半导体进展的变慢和计算需求的爆炸式增长也在驱动着底层技术的变革。现在依然依靠通用架构和普适优化很难再满足各种需求,开发领域专用的整体的解决方案是一条出路。RISC-V 在芯片指令集层次探索模块化和定制化,MLIR 则是在编译器以及中间表示层面做类似探索。两者联手会给底层技术栈带来何种革新是一个值得拭目以待的事情。
跨系统边界的渐进式代码表示递降
在结束本章之前,再啰嗦最后一点。其实可以从两个维度看待 MLIR 带来的解耦:
水平方向上,dialect 把完整中间表示打散成许多局部中间表示;垂直方向上,MLIR 让可以对处于不同层级的概念进行建模。这对领域专用编译器是非常有用的,因为领域专用语言一般是高度抽象的声明式语言,只描述任务,需要编译器将其转换成具体的命令式机器指令。一步跨越这个巨大的抽象差距是非常难的,利用多级抽象和建模来进行渐进式 lowering 是更加适合的方式。可以分离各个层次关注的问题,整个系统也更加的易开发和维护。
当然这并不是什么全新的概念,在不同的项目中已然看到各种类中间表示的设置,像是 Clang AST 或者各种机器学习框架中的计算图。MLIR 的优势是使用同样的基础设施将这些不同层次的表示连接起来,让之间的信息流通变得更加顺畅。其实现代复杂系统的开发多是选取各种子系统然后将其组合。将来自前一个子系统的数据进行验证、转化然后传递给下一个子系统消耗掉很多工程资源。如果所有子系统使用相同的内部基础设施,这些资源投入就都可以节省下来,另外,使用相同工具也会使得跨组跨项目的沟通协调变得更加简单。
结语:
本篇试图记录对编译器以及中间表示发展的历史和趋势的理解,比较抽象,另外也有点东拉西扯。不过希望本篇能为以后探讨具体的编译器以及中间表示机制奠定基础。总结一下:人类通过抽象来应对复杂性。编译器是能够自动转换抽象级别的效率工具。编译器首要考虑正确性,其次产生高效代码。正确性需要明确的语义以及各种验证来保障。编译器产生的代码可以给绝大部分的性能, 这可以让把工程力量集中到真正核心的对性能影响最大的部分。LLVM 通过其 LLVM IR 和库解耦并模块化了编译器。LLVM 同时用文本表示将 UNIX 哲学带入了编译器。但 LLVM 的设计折中意味着其并不适合所有的领域,比如 LLVM 并不对稳定性和兼容性提供强保障,LLVM IR 本身也是不可分割的中心化中间表示。SPIR-V 是着眼于 GPU 领域的行业标准规范。SPIR-V 通过技术上的机制和组织上的流程来维持其可扩展性。SPIR-V 有着稳定的字节码和兼容性保障。MLIR 进一步解耦了中间表示;完整的中间表示被分割成可以按需选取的 dialect;其基础设施极大地简化定义各种层级 operation 和转换。这符合技术发展的趋势——技术一般都是从单一的强耦合的解决方案渐渐演进到多种多样的可定制化的解决方案。将来开发领域专用编译器可能真的只是选取、定制、以及混合各种 dialect 这般简单。
参考资料
[1] “clang c++ compilation涉及的步骤 ”,https://eli.thegreenplace.net/2012/11/24/life-of-an-instruction-in-llvm
[2] “LLVM语言参考”,https://llvm.org/docs/LangRef.html
[3] “LLVM解耦的部分”,https://www.aosabook.org/en/llvm.html
[4] “LLVM兼容性的部分”,https://llvm.org/docs/DeveloperPolicy.html#ir-backwards-compatibility
[5] “SPIR Ecosystem”,https://www.khronos.org/spir/
[6] “SPIR-V的机制”,https://www.khronos.org/registry/SPIR-V/specs/unified1/SPIRV.html
[7] “MLIR语言参考”,https://mlir.llvm.org/docs/LangRef
[8] “MLIR Interface”,https://mlir.llvm.org/docs/Interfaces/
[9] “MLIR Dialects”,https://mlir.llvm.org/docs/Dialects/
[10] “MLIR dialect overview”,https://discourse.llvm.org/t/codegen-dialect-overview/2723
LLVM的Intrinsics函数及其实现
1 什么是 Intrinsic 函数
Intrinsic 函数是编译器内建的函数,由编译器提供,类似于内联函数。但与内联函数不同的是,因为 Intrinsic 函数是编译器提供,而编译器与硬件架构联系紧密,因此编译器知道如何利用硬件能力以最优的方式实现这些功能。通常函数的代码是 inline 插入,避免函数调用开销。LLVM 支持 Intrinsic 函数的概念。这些函数的名称和语义可以是预先定义,也可以自定义,要求遵守特定的约定。 在有些情况下,可能会调用库函数。例如,在参考文献[2] 中列出的函数,都是调用 libc。总的来说,这些 Intrinsic 函数代表了 LLVM 语言的一种扩展机制,当添加到语言中时,不要求改变 LLVM 的任何转化过程。对其它编译器,Intrinsic 函数也称为内建函数。
• 在 LLVM 中,Intrinsic 函数一般是在 IR 级代码优化时引入的,也就是由前端产生。
• 也可以在程序代码中写 Intrinsic 函数,并通过前端直接发射。
这些函数名的前缀一般是保留字 “llvm.”。LLVM 后端选择用最高效的形式将 Intrinsic 函数转换给硬件执行,可以将 Intrinsic 函数拆分为一系列机器指令,也可以映射为单独一条机器指令,并直接调用相应的硬件功能。下文中会针对这两种情况给出实例。
Intrinsic 函数一般是外部函数,开发者不能在自己的代码中实现函数体,而只能调用这些 Intrinsic 函数。获得 Intrinsic 函数的地址是非法的。
2 输出 Intrinsic 函数
以下举例说明 LLVM 如何通过其 Intrinsic 函数优化特定部分代码。
#include<string.h>
int foo(void){
char str[10] = “str”;
return 0;
}
由 Clang 生产的 LLVM IR 如下:
define i32 @foo() #0 {
entry:
%str = alloca [10 x i8], align 1
%0 = bitcast [10 x i8]* %str to i8*
call void @llvm.memcpy.p0i8.p0i8.i64(i8* %0, i8* getelementptr inbounds ([10 x i8]* @foo.str, i32 0, i32 0), i64 10, i32 1, i1 false)
ret i32 0
}
其中,llvm.memcpy 就是 clang 输出的 Intrinsic 函数。如果 LLVM 没有定义 llvm.memcpy,相应的内存操作 LLVM IR 代码就应该是一系列 store constant into str[0…3] 内存访问指令,而这些指令通常都是极耗时的。LLVM 后端可将 llvm.memcpy 拆分为一系列高效机器指令,也可以映射为一条特定的机器指令,直接调用硬件的内存操作功能。
再举一例。
int func()
{
int a[5];
for (int i = 0; i != 5; ++i)
a[i] = 0;
return a[0];
}
使用 Clang 生成未经优化的 IR 代码,其中不包括任何 Intrinsic 函数。
define dso_local i32 @_Z4funcv() #0 {
entry:
%a = alloca [5 x i32], align 16
%i = alloca i32, align 4
store i32 0, i32* %i, align 4
br label %for.cond
for.cond: ; preds = %for.inc, %entry
%0 = load i32, i32* %i, align 4
%cmp = icmp ne i32 %0, 5
br i1 %cmp, label %for.body, label %for.end
for.body: ; preds = %for.cond
%1 = load i32, i32* %i, align 4
%idxprom = sext i32 %1 to i64
%arrayidx = getelementptr inbounds [5 x i32], [5 x i32]* %a, i64 0, i64 %idxprom
store i32 0, i32* %arrayidx, align 4
br label %for.inc
for.inc: ; preds = %for.body
%2 = load i32, i32* %i, align 4
%inc = add nsw i32 %2, 1
store i32 %inc, i32* %i, align 4
br label %for.cond
for.end: ; preds = %for.cond
%arrayidx1 = getelementptr inbounds [5 x i32], [5 x i32]* %a, i64 0, i64 0
%3 = load i32, i32* %arrayidx1, align 16
ret i32 %3
}
然后使用 opt 工具对 IR 做 O1 级别优化,得到 IR 如下:
define i32 @_Z4funcv() #0 {
…
call void @llvm.memset.p0i8.i64(i8* %a2, i8 0, i64 20, i32 16, i1 false)
其中重要的优化是调用 Intrinsic 函数 llvm.memset.p0i8.i64 为数组填 0。Intrinsic 函数也能用来实现代码的向量化和并行化,从而生成更优化的代码。比如,可以调用 libc 中最优化版本的 memset。
有些 Intrinsic 函数可以重载,比如表示相同操作,但数据类型不同的一族函数。重载通常用来使 Intrinsic 函数可以在任何整数类型上操作。一个或多个参数类型或结果类型可以被重载以接受任何整数类型。
被重载的 Intrinsic 函数名中会包括重载的参数类型,函数名中的每一个参数类型前会有一个句点。只有被重载的类型才会有名称后缀。例如,llvm.ctpop 函数参数是任意宽度的整数,并且返回相同整型宽度的整数。这会引出一族函数,例如 i8 @llvm.ctpop.i8(i8 %val) and i29 @llvm.ctpop.i29(i29 %val). 其中都只有一种类型被重载,函数名中也只有一种类型后缀,如. i8 和. i29。以为参数类型和返回值类型匹配,二者在函数名中共用一个名称后缀。
3 如何定义新 Intrinsic 函数
在使用 LLVM 过程中,开发者也许需要对 LLVM 做定制。这时需要在 LLVM 中添加代码,可能是一个基础类型,可能是一个新 Intrinsic 函数,或者是新的指令。对 LLVM 做扩展需要很大的工作量,涉及更新扩展时要用到的所有 pass。而增加一个 Intrinsic 函数远比增加指令容易,并且对优化 pass 是透明的。如果开发者要增加的功能可以表示成函数调用,Intrinsic 函数是一个不错的可选方法。
要增加 intrinsic 函数,首先要在 LLVM 框架中定义该函数,还有可能要在 clang 中注册该函数,这样前端才能支持在 c 代码中使用这个 intrinsic 函数。这样就可能修改从前端到后端各个不同层次的代码。下例是在自定义后端中实现用自定义 Intrinsic 函数取代 NVVM Intrinsic 函数。
已知有如下 NVVM Intrinsic 函数,这些 Intrinsic 函数是用于支持读 PTX 特殊寄存器:
i32 @llvm.nvvm.read.ptx.sreg.tid.x()
i32 @llvm.nvvm.read.ptx.sreg.tid.y()
i32 @llvm.nvvm.read.ptx.sreg.tid.z()
i32 @llvm.nvvm.read.ptx.sreg.ntid.x()
i32 @llvm.nvvm.read.ptx.sreg.ntid.y()
i32 @llvm.nvvm.read.ptx.sreg.ntid.z()
i32 @llvm.nvvm.read.ptx.sreg.ctaid.x()
i32 @llvm.nvvm.read.ptx.sreg.ctaid.y()
i32 @llvm.nvvm.read.ptx.sreg.ctaid.z()
i32 @llvm.nvvm.read.ptx.sreg.nctaid.x()
i32 @llvm.nvvm.read.ptx.sreg.nctaid.y()
i32 @llvm.nvvm.read.ptx.sreg.nctaid.z()
i32 @llvm.nvvm.read.ptx.sreg.warpsize()
这些 Intrinsic 函数在 .ll 中的调用形式如下:
define kernel void @nvvm_read_ptx_sreg_tid_x() #0 {
…
%tid.x = call i32 @llvm.nvvm.read.ptx.sreg.tid.x()
…
ret void
}
declare i32 @llvm.nvvm.read.ptx.sreg.tid.x()
.ll 文件中的函数可以调用这类 Intrinsic,但要在 .ll 文件中用 declare 声明。这时,Intrinsic 函数的实现可以在另一个 .ll 文件中。或者在某个 lib 中。
如果希望用自定义 Intrinsic 函数取代 NVVM Intrinsic 函数,则需要先定义自定义 Intrinsic 函数。假设希望用 Intrinsic intworkitem_id 取代 llvm.nvvm.read.ptx.sreg.tid,Intrinsic int_workitem_id 定义如下:
a. llvm/include/llvm/IR/Intrinsics.td:
如果在 llvm/include/llvm/IR/ 路径下没有与自定义 backend 对应的 Intrinsics.td 文件,可以拷贝已有 backend 的 td 文件,然后在其上修改,这是一个比较快捷的方法。增加对应的 td 文件后,不要忘记在 Intrinsics.td 中包含自定义 backend 的 td 文件,以便框架知道 td 文件的存在。
include “llvm/IR/Intrinsics.td”
在 td 文件中增加自定义 Intrinsic 函数入口,描述 Intrinsic 函数的内存访问优化特性(这控制 Intrinsic 函数是否会被死代码消除、公共子表达式消除等)。任何使用 llvm_any*_ty 类型的 Intrinsic 函数会被 tblgen 认为重载,并在 Intrinsic 函数名中增加后缀。
下例中,Intrinsic<…> 中的内容是对函数签名,描述该 intrinsic 应该如何被调用。签名包括三个部分:返回类型、参数类型和一组标志。这组标志提示了在优化时应该如何处理这个 intrinsic。
class ReadPreloadRegisterIntrinsic
: Intrinsic<[llvm_i32_ty], [], [IntrNoMem, IntrSpeculatable]>;
multiclass ReadPreloadRegisterIntrinsic_xyz {
def _x : ReadPreloadRegisterIntrinsic;
def _y : ReadPreloadRegisterIntrinsic;
def z : ReadPreloadRegisterIntrinsic;
}
let TargetPrefix = “” in {
…
defm int_workitem_id : ReadPreloadRegisterIntrinsic_xyz;
class AtomicIncIntrin : Intrinsic<[llvm_anyint_ty],
[llvm_anyptr_ty,
LLVMMatchType<0>,
llvm_i32_ty, // ordering
llvm_i32_ty, // scope
llvm_i1_ty], // isVolatile
[IntrArgMemOnly, NoCapture<0>], “”,
[SDNPMemOperand]
;
def int__atomic_load_add_f32 : AtomicIncIntrin;
LLVM 定义 Intrinsic 函数借用了 GCC builtin,如下例中的 GCCBuiltin<“nvvm_read_ptx sreg” # regname # “_x”>;。
b. llvm/include/llvm/IR/IntrinsicsNVVM.td
// Accessing special registers.
multiclass PTXReadSRegIntrinsic_v4i32 {
// def _r64 : Intrinsic<[llvm_i128_ty], [], [IntrNoMem]>;
// def _v4i16 : Intrinsic<[llvm_v4i32_ty], [], [IntrNoMem]>;
def _x : Intrinsic<[llvm_i32_ty], [], [IntrNoMem]>,
GCCBuiltin<“_nvvm_read_ptx_sreg” # regname # “_x”>;
def _y : Intrinsic<[llvm_i32_ty], [], [IntrNoMem]>,
GCCBuiltin<“_nvvm_read_ptx_sreg” # regname # “_y”>;
def _z : Intrinsic<[llvm_i32_ty], [], [IntrNoMem]>,
GCCBuiltin<“_nvvm_read_ptx_sreg” # regname # “_z”>;
def _w : Intrinsic<[llvm_i32_ty], [], [IntrNoMem]>,
GCCBuiltin<“_nvvm_read_ptx_sreg” # regname # “_w”>;
}
…
defm int_nvvm_read_ptx_sreg_tid : PTXReadSRegIntrinsic_v4i32<“tid”>;
def int_nvvm_atomic_load_add_f32 : Intrinsic<[llvm_float_ty],
[LLVMAnyPointerType<llvm_float_ty>, llvm_float_ty],
[IntrArgMemOnly, NoCapture<0>]>;
c. 在. ll 文件 llvm/test/CodeGen//*intrinsics.ll 中增加测试用例:
; Check that nvvm intrinsics are replaced with intrinsics
; RUN: opt --lower-intrinsics -S < %s | FileCheck %s --check-prefix=CHECK
; CHECK-LABEL: @nvvm_read_ptx_sreg_tid_x
define _kernel void @nvvm_read_ptx_sreg_tid_x() #0 {
; CHECK: @llvm..workitem.id.x()
%tid.x = call i32 @llvm.nvvm.read.ptx.sreg.tid.x()
ret void
}
declare i32 @llvm.nvvm.read.ptx.sreg.tid.x()
d. 在 LowerIntrinsics pass 中替换 intrinsics 函数,实现代码位于文件 llvm/lib/Target//LowerIntrinsics.cpp 中:
bool lowerNVVMIntrinsics(CallInst *CI);
/// This function is used to replace NVVM intrinsics with instrinsics
bool LowerIntrinsics::lowerNVVMIntrinsics(CallInst *CI) {
IRBuilder<> Builder(CI);
const Function *Callee = CI->getCalledFunction();
if (!Callee) {
return false;
}
CallSite CS(CI);
switch (Callee->getIntrinsicID()) {
case Intrinsic::nvvm_read_ptx_sreg_tid_x:
replaceCallWithIntrinsic(Intrinsic::_workitem_id_x, CI, CS.arg_begin(),
CS.arg_end());
return true;
…
default:
return false;
}
}
/// 在此函数中将 NVVM intrinsic 函数转为自定义 intrinsic 函数 :
template
static CallInst *replaceCallWithIntrinsic(Intrinsic::ID Intrinsic, CallInst *CI,
ArgIt ArgBegin, ArgIt ArgEnd) {
IRBuilder<> Builder(CI->getParent(), CI->getIterator());
SmallVector<Value , 8> Args(ArgBegin, ArgEnd);
CallInst NewCI = NULL;
if (Args.empty()) {
NewCI = Builder.CreateIntrinsic(Intrinsic);
} else {
NewCI = Builder.CreateIntrinsic(Intrinsic, Args);
}
NewCI->setName(CI->getName());
if (!CI->use_empty())
CI->replaceAllUsesWith(NewCI);
CI->eraseFromParent();
return NewCI;
}
调用 opt 工具,执行如下命令:
bin/opt --lower-intrinsics -S …/test/CodeGen//nvvmintrinsics.ll
输出如下:
; ModuleID = ‘…/test/CodeGen//nvvmintrinsics.ll’
source_filename = “…/test/CodeGen//nvvmintrinsics.ll”
; Function Attrs: nounwind
define _kernel void @nvvm_read_ptx_sreg_tid_x() #0 {
%tid.x1 = call i32 @llvm..workitem.id.x()
ret void
}
可见,函数体中的 %tid.x = call i32 @llvm.nvvm.read.ptx.sreg.tid.x() 已经替换为 %tid.x1 = call i32 @llvm..workitem.id.x()。
e. 在 llvm/lib/Target//ISelLowering.cpp
将 PTX Intrinsic 函数转换成自定义 Intrinsic 函数后,还要实现自定义 Intrinsic 函数的具体功能。在这个例子中,就是要实现 @llvm..workitem.id.x()。
SDValue TargetLowering::LowerOperation(SDValue Op, SelectionDAG &DAG) {
…
case ISD::INTRINSIC_WO_CHAIN:
return LowerINTRINSIC_WO_CHAIN(Op, DAG);
…
}
SDValue TargetLowering::LowerINTRINSIC_WO_CHAIN(…){
…
switch (IntrinsicID) {
…
case Intrinsic::workitem_id_x: {
return loadInputValue(DAG, &::VGPR_32RegClass, MVT::i32,
SDLoc(DAG.getEntryNode()),
MFI->getArgInfo().WorkItemIDX);
}
…
4 Add relu as LLVM intrinsic
下例说明为了支持 AI 模型中的 relu 激活函数,需要在 LLVM 中做的修改。首先要在 ISA 定义中增加向量 relu 指令,并在编译器中提供相应的 Intrinsic 函数支持。这个例子说明了 Intrinsic 函数重载的用法,实现过程如下:
a. 在 llvm/include/llvm/IR/Intrinsics.td 中添加 Intrinsic 函数定义,其中支持 i32、i16、f32、f16 四种不同数据类型的 relu 操作:
def int_m_relu_i32 : GCCBuiltin<“_builtinm_relu_i32">,
Intrinsic<[llvm_i32_ty], [llvm_i32_ty], [IntrConvergent]>;
def int_m_relu_i16 : GCCBuiltin<”_builtinm_relu_i16">,
Intrinsic<[llvm_i16_ty], [llvm_i16_ty], [IntrConvergent]>;
def int_m_relu_f32 : GCCBuiltin<“_builtinm_relu_f32">,
Intrinsic<[llvm_float_ty], [llvm_float_ty], [IntrConvergent]>;
def int_m_relu_f16 : GCCBuiltin<”_builtin_m_relu_f16">,
Intrinsic<[llvm_half_ty], [llvm_half_ty], [IntrConvergent]>;
b. 在目标平台的指令定义文件 Instruction.td 中增加向量 relu 指令定义:
let hasSideEffects = 1, mayStore = 1, mayLoad = 1 in {
def V_RELU_I32 : MLOP1p_i32<“v_relu_i32”,
[(set i32:KaTeX parse error: Double subscript at position 22: …(int_<target>_m_̲relu_i32 i32:src0))]
;
def V_RELU_I16 :MLOP1p_i16<“v_relu_i16”,
[(set i16:KaTeX parse error: Double subscript at position 22: …(int_<target>_m_̲relu_i16 i16:src0))]
;
def V_RELU_F32 : MLOP1p_f32<“v_relu_f32”,
[(set f32:KaTeX parse error: Double subscript at position 22: …(int_<target>_m_̲relu_f32 f32:src0))]
;
def V_RELU_F16 : MLOP1p_f16<“v_relu_f16”,
[(set f16:KaTeX parse error: Double subscript at position 22: …(int_<target>_m_̲relu_f16 f16:src0))]
;
}
与 Intrinsic 函数定义相应,ISA 指令定义也支持 i32、i16、f32、f16 四种不同数据类型的 relu 操作。
c. 在测试用例 test/Codegen//relu.ll 中实现调用 relu Intrinsic 函数的代码(仅以 i32 数据类型为例):
declare i32 @llvm..m.relu.i32(i32)
…
define void @test(i32 addrspace(1) %out, i32 %in) {
%res = call i32 @llvm..m.relu.i32(i32 %in)
store i32 %res, i32 addrspace(1) %out, align 4
ret void
}
参考资料
[1]
LLVM的Intrinsics函数及其实现 - 知乎 (zhihu.com): https://zhuanlan.zhihu.com/p/53659330
[2]
参考文献: https://llvm.org/docs/ExtendingLLVM.html#intrinsic-function
LLVM后端流程简介
1 Program Work Flow
如果要编译 OpenCL/CUDA 代码,并已经有了一些 OpenCLl/CUDA kernel,以及在主机端运行的代码。主机端代码调用 kernel。如下图所示:
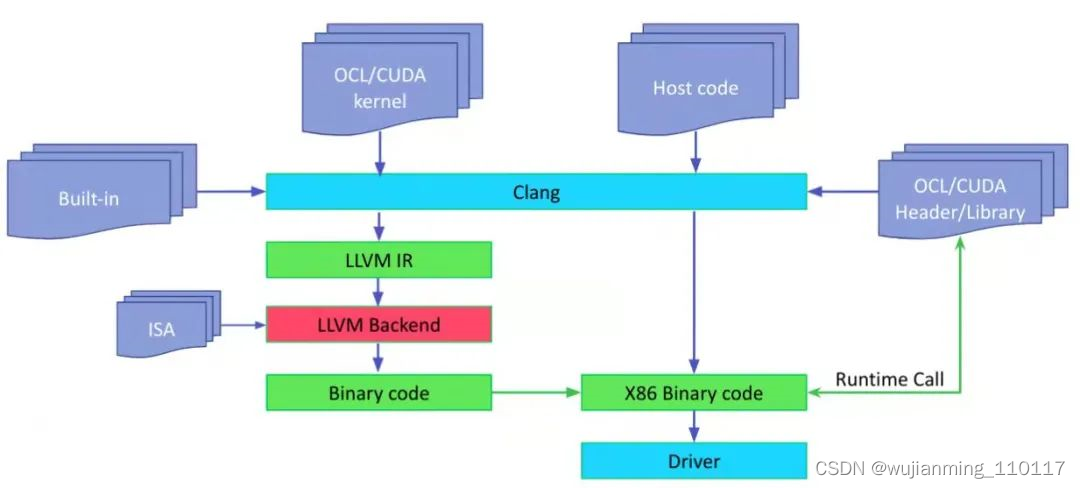
图 1
在主机端,执行 Clang 编译主机代码,这和正常编译类似,但是要链接 openCL/CUDA runtime。对 kernel 代码,也会执行 Clang 编译 kernel 代码,生成 LLVM IR。为了支持 kernel built-in function,这里使用 built-in lib,比如对 OpenCL,一般使用的 built-in lib 是 libclc。
主机代码调用 runtime api,比如 OpenCL 的 clCreateProgramWithBinary,生成 kernel。主机端代码也可以调用其它 runtime call 来为相应设备创建 comandQueue,或者得到设备或平台信息。
2 Pipeline
LLVM backend 的主要功能是 code gen,也就是代码生成,其中包括若干个 code gen 分析换转化 pass 将 LLVM IR 转换成特定目标架构的机器代码。当然希望这个机器代码是最优化的机器代码。LLVM backend 具有流水线结构,如下图所示。指令经过各个阶段,从 LLVM IR 到 SelectionDAG,再到 MachineDAG,再到 MachineInstr,最后到 MCInst。有些资料中不将 MachineDAG 不做为单独的一种指令格式,因为其基本格式仍然是 SelectionDAG,只不过其中的指令是目标相关指令。这其中经过的各个阶段实际是不同的 pass,包括 Instruction selection(指令选择)、Register Allocation(寄存器分配),Instruction Scheduling 以及 Code Emission。不同的 target 的 backend 根据需要对不同 pass 做 customization。
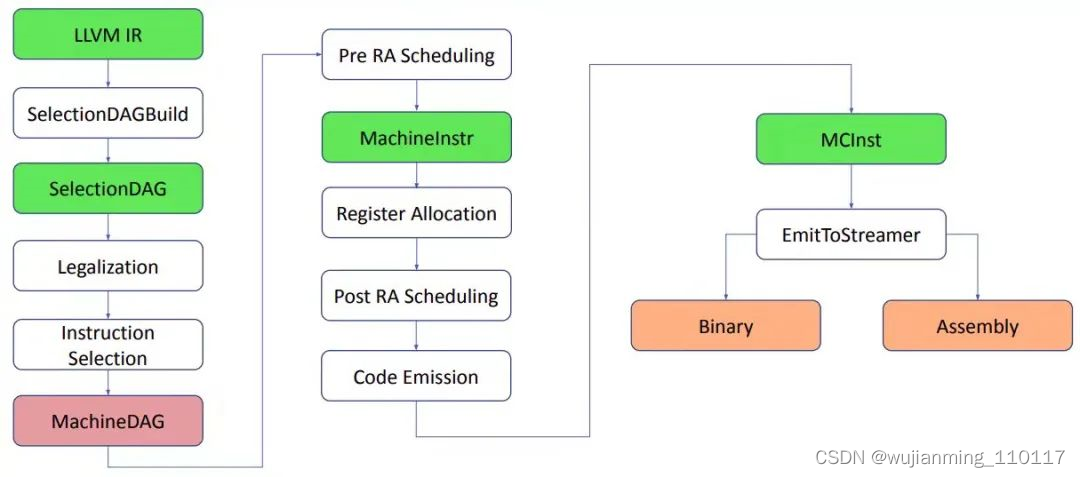
图 2
下面来具体看看每个 pass 和步骤的功能。
1 首先,SelectionDAGBuilder 遍历 LLVM IR 中的每一个 function 以及 function 中的每一个 basic block,将其中的指令转成 SDNode,整个 function 或 basic block 转成 SelectionDAG。这时 DAG 中每个 node 的内容仍是 LLVM IR 指令。
2 SelectionDAG 经过 legalization 和其它 optimizations,DAG 节点被映射到目标指令。这个映射过程是指令选择。这时的 DAG 中的 LLVM IR 节点转换成了目标架构节点,也就是将 LLVM IR 指令转换成了机器指令。所以这时候的 DAG 又称为 MachineDAG。
3 在 MachineDAG 已经是机器指令,可以用来执行 basic block 中的运算。所以可以在 MachineDAG 上做 Instruction Scheduling 确定 basic block 中指令的执行顺序。指令调度分为寄存器分配前的指令调度,和寄存器分配后的指令调度。寄存器分配前的指令调度器实际有 2 个,作用于 SelectionDAG,发射线性序列指令。主要考虑指令级的平行性。经过这个 scheduling 后的指令转换成了 MachineInstr 三地址表示。指令调度器有三种类型:list scheduling algo, fast algo, vliew。
4 寄存器分配,为 virtual Register 分配 physical Register 并优化 Register 分配过程使溢出最小化。
virtual Register 到 physical Register 的映射有两种方式:直接映射和间接映射。直接映射利用 TargetRegisterInfo 和 MachineOperand 类获取 load/store 指令插入位置,以及从内容去除和存入的值。间接映射利用 VirtRegMap 类处理 load/store 指令。寄存器分配算法有 4 种:Basic Register Allocator、Fast Register Allocator、PBQP Register Allocato、Greedy Register Allocator。
5 寄存器分配后的指令调度器作用于机器指令,也就是 MachineInstr。这时能得到 physical Register 信息,可以结合 physical Register 的安全性和执行效率,对指令顺序做调整。
6 Code emission 阶段将机器指令转成 MCInstr,并发射汇编或二进制代码。
3 Initial Selection Construction
SelectionDAG 类用一个 DAG 表示一个 basic block。SelectionDAG 的创建是个基本的窥孔算法。LLVM IR 经过 SelectionDAGBuilder 的处理后转换成 SelectionDAG。下图是 C 代码实现除法,只有一个 function,一个 basic block。
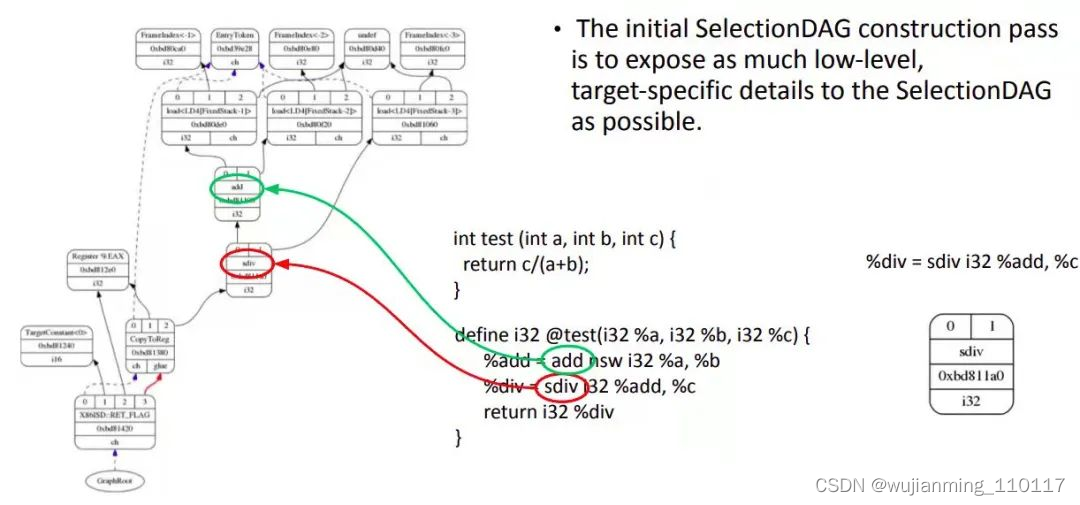
图 3
IR 经过多个优化 pass 做进一步优化后由 SelectionDAGBuilder 类产生 Selection DAG 节点。当 SelectionDAGBuilder 遇到 IR 指令,调用相应的 visit() 方法,比如,如果是 SDIV 操作,就调用 visitSDiv() 方法将两个操作数保存到 SDValue,从 DAG 中得到一个 SDNode 节点并以 ISD::SDIV 作为其操作符。在该 IR 中,操作数 0 为 %add,操作数 1 为 %c。其它计算也做类似处理。处理完所有 IR 指令后,IR 被转为如图所示的 SelectionDAG。每一个 DAG 表示一个基本块中的计算,不同的基本块与不同的 DAG 关联。节点表示计算,边有不同含义。将 IR 转化为 DAG 很重要,因为这可以让代码生成器使用基于树的模式匹配指令选择算法。此时的 SelectionDAG 还与目标设备无关,但对于具体目标设备来说,有些指令可能不合法,因为不同目标设备支持的指令集不同,指令集中的指令与 IR 指令可能没有对应关系。例如,x86 不支持 SDIV 而支持 SDIVREM。
下面详细介绍 DAG 图中不同符号的含义。DAG 中的每个节点 SDNode 会维护一个记录,其中记录了本节点对其它节点的各种依赖关系,这些依赖关系可能是数据依赖(本节点使用了被其它节点定义的值),也可能是控制流依赖(本节点的指令必须在其它节点的指令执行后才能执行,或称为 chain)。这种依赖关系通过 SDValue 对象表示,对象中封装了指向关联节点的指针和被影响结果的序列号。也可以说,DAG 中的操作顺序通过 DAG 边的 use-def 关系确定。如果图中的 SDIV 节点有一个输出的边连到 add 节点,这意味着 add 节点定义了一个值,这个值会被 SDIV 节点使用。因此,add 操作必须在 SDIV 节点之前执行。
• 黑色箭头表示数据流依赖。数据流依赖表示当前节点依赖前一节点的结果。
• 虚线蓝色箭头表示非数据流链依赖。链依赖防止副作用节点,确定两个不相关指令的顺序。比如,load 和 store 指令如果访问相同的内存位置,就必须和在原程序中的顺序保持一致。从图中的蓝色箭头可知,CopyToReg 操作必须在 ret_flag 之前发生,因为之间是链依赖。
• 红色箭头表示 glue 依赖。Glue 是用来防止两个指令在 scheduling 时分开,即中间不能插入其它指令。
每个节点的类型,可以是实际的数据类型,如 i32,i64 等,也可以是 chain 类型,表示 chain values,或者是 glue 类型,表示 glue。
SelectionDAG 对象有一个特殊的 EntryToken 来标记 basic block 的入口。EntryToken 的类型是 ch,允许被链接的节点以这个第一个 token 作为起始。
在这张图中,目标无关和目标相关的节点共存。CopyFromReg、CopyToReg、add 等是目标无关节点;Register %EAX、TargetConstant 和 ret_flag 是目标相关节点。
• CopyFromReg:copy 当前 basic block 外的 register,用在当前环境,这里用于 copy 函数参数。
• CopyToReg:copy 一个值给特定寄存器而不提供任何实际值给其它节点消费。然而,这个节点产生一个 chain value 被其它节点链接,这些其它节点不产生实际值。比如为了使用写到 EAX 的值,ret_flag 节点使用 EAX 寄存器提供的 i32 结果,并消费 CopyToReg 节点产生的 chain,这样保证 EAX 随着 CopyToReg 更新,因为 chain 会使得 CopyToReg 在 ret_flag 之前被调度。
4 Legalization
从 SelectionDAGBuilder 输出的 SelectionDAG 还不能做指令选择,在 SelectionDAG 机制从 DAG 节点产生机器指令之前,DAG 节点还要经过几个转化阶段,其中合法化是最重要的阶段,如下图所示。做合法化的原因是 SelectionDAGBuilder 构造的 SDNode 中的指令操作数类型和操作不一定能被目标平台支持。
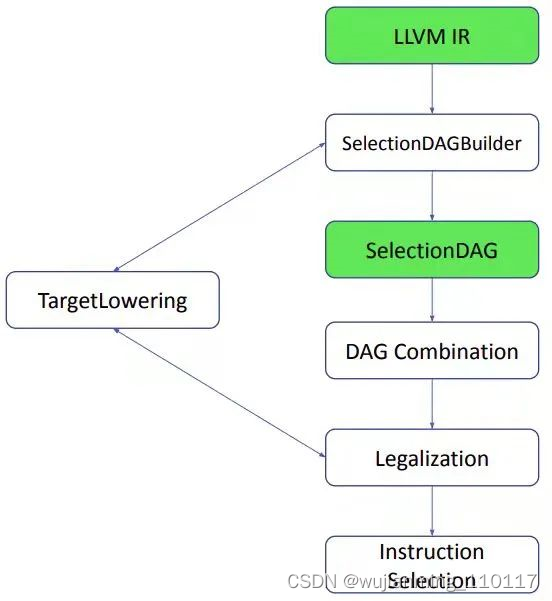
图 4
SDNode 的合法化涉及类型和操作的合法化。首先介绍操作的合法化。
目标平台一般不可能为所有支持的数据提供 IR 中所具有的全部指令,x86 上没有条件赋值(conditional moves) 指令,PowerPC 也不支持从一个 16-bit 的内存上以符号扩展的方式读取整数。因此,合法化阶段要将这些不支持的指令按三种方式转换成平台支持的操作:
• 扩展(Expansion),用一组操作来模拟一条操作;
• 提升(promotion),将数据转换成更大的类型来支持操作;
• 定制(Custom),通过目标平台相关的 Hook 实现合法化。
下图以 x86 除法指令为例说明操作的合法化。LLVM IR 的 SDIV 只计算商,而 x86 除法指令计算得到商和余数,分别保存在两个寄存器中。因为指令选择会区分 SDIVREM 和 SDIV,因此当目标平台不支持 SDIV 时需要在合法化阶段将 SDIV 扩展到 SDIVREM 指令。
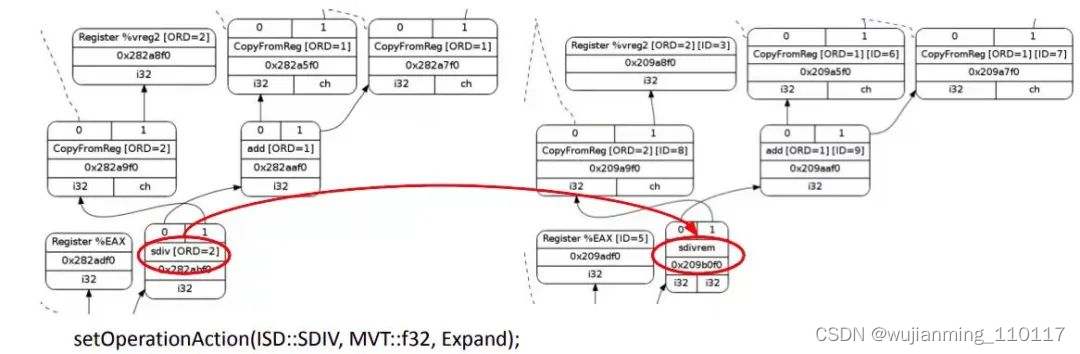
图 5
目标平台相关的信息通过 TargetLowering 接口传递给 SelectionDAG。目标设备会实现这个接口以描述如何将 LLVM IR 指令用合法的 SelectionDAG 操作实现。在 x86 的 TargetLowering 构造函数中会通过 “expanded” 这个 label 来标识。当 SelectionDAGLegalize::LegalizeOp 看到 SDIV 节点的 Expand 标志会用 SDIVREM 替换。类似的,目标平台相关的合并方法会识别一组节点组合的模式,并决定是否合并某些节点组合以提高指令选择质量。
类型合法化 pass 保证后续的指令选择只需要处理合法数据类型。合法数据类型是目标平台原生支持的数据类型,例如,目标平台的 td 文件中会定义每一种数据类型关联的寄存器类。例如,
def FPRegs : RegisterClass<“SP”, [f32], 32, (sequence “F%u”, 0, 31)>;
这里定义了一组 32 个从 F0-F31 单精度浮点类型的寄存器。
def DFPRegs : RegisterClass<“SP”, [f64], 64, (add D0, D1, D2, D3, D4, D5, D6, D7, D8, D9, D10, D11, D12, D13, D14, D15)>;
定义了一组 16 个从 D0-D15 双精度浮点类型的寄存器。
如果平台的 td 文件的寄存器类定义没有相应的数据类型,那对平台来说就是非法数据类型。非法的类型必须被删除或做相应处理。根据非法数据类型不同,处理方式分为两种情况:
第一种是标量。标量可以被 promoted(将较小的类型转成较大的类型,比如平台只支持 i32,那么 i1/i8/i16 都要提升到 i32), expanded(将较大的类型拆分成多个小的类型,如果目标只支持 i32,加法的 i64 操作数就是非法的。这种情况下,类型合法化通过 integer expansion 将一个 i64 操作数分解成 2 个 i32 操作数,并产生相应的节点);
第二种是矢量。LLVM IR 中有目标平台无法支持的矢量,LLVM 也会有两种转换方案, 加宽(widening) ,即将大 vector 拆分成多个可以被平台支持的小 vector,不足一个 vector 的部分补齐成一个 vector;以及 标量化(scalarizing),即在不支持 SIMD 指令的平台上,将矢量拆成多个标量进行运算。
目标平台也可以实现自己的类型合法化方法。类型合法化方法会运行两次,一次是在第一次 DAG Combine 之后,另一次是在矢量合法化之后。无论怎样,最终都要保证转换后的指令与原始的 IR 在行为上完全一致。
在做合法化时,还有其它可能的情况要考虑。比如,某种目标平台寄存器类支持某种向量类型,但某个特定的操作不支持这个向量类型。举个例子,x86 支持 v4i32 类型,但没有 x86 指令支持 v4i32 类型的 ISD::OR 操作,只支持 v2i64。这样,向量合法化 pass 就要 promote 使用 v2i64 类型。
DAG Combine pass 是将一组节点用更简单结构的节点代替。比如一组节点表示 (add (Register X), (constant 0)) 将寄存器 X 中的值和常数 0 相加,这种情况可以简化成 (Register X),和常数 0 相加无效,被优化掉了。
setTargetDAGCombine() 方法表示哪些节点可以被组合,例如:
setTargetDAGCombine(ISD::ADD);
setTargetDAGCombine(ISD::AND);
setTargetDAGCombine(ISD::FADD);
Combine pass 在 legalization 后执行,可以最小化 SelectionDAG 的冗余节点。
5 Instruction Lowering
SelectionDAG 中已经有和目标相关的节点。为什么会这样?为了理解这个问题,首先看图 1。这里面包括了 Instruction Selection 之前的所有步骤,以 LLVM IR 起始。首先,SelectionDAGBuilder 遍历 LLVM IR 中的每一个 basic block,生成 SelectionDAG。在这个过程中,某些指令,如 call 和 ret 已经需要目标相关信息。比如如何传递调用参数,如何从函数返回。
为了解决这个问题,TargetLowering 类中的算法会在这里被首次使用。不同目标的 backend 要实现 TargetLowering 抽象接口。只有一小部分节点会在这里转成目标相关节点,大部分节点都在 Instruction Selection 中在 pattern match 后被替换成机器指令。
6 Instruction Selection
指令选择是 backend 中的一个重要阶段。从耗时方面来说,指令选择占用了 backend 总耗时的一半。指令选择通过节点模式匹配完成 DAG 到 DAG 的转换,将 SelectionDAG 节点转换成表示目标指令的节点。这一阶段的输入是经过合法化的 SelectionDAG,如下图所示。
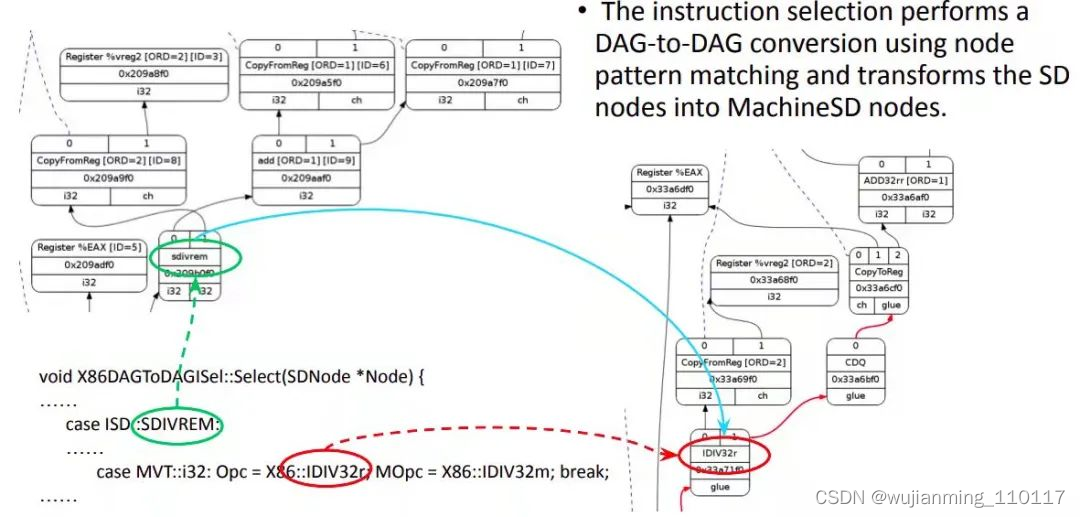
图 6
LLVM 的指令选择需要 tablegen 辅助来产生一种基于表的指令选择机制。目标平台的 backend 可以在 SelectionDAGISel::Select 方法中实现定制代码手工处理某些指令。其它指令通过 SelectCode 由默认的指令选择过程处理。例如在 x86 backend 中,对于经过合法化的 SDIVREM 操作就是手动方法做指令选择的。Select 方法的输入 SDNode 节点如果是 SDIVREM,会选择对应的 x86 指令 opcode,也就是 IDIV32r,并生成一个 MachineSD 节点。MachineSD 节点是 SDNode 的子集,其中的内容是平台机器指令,但仍然以 DAG node 的形式表示。其中 CopyToReg, CopyFromReg 和 Register 节点在寄存器分配阶段之前保持不变。有三种类型的指令表达会在同一个 DAG 中共存:一般 LLVM ISD 节点,如 ISD::ADD;平台相关 ISD 节点,如 X86ISD::RET_FLAG;和平台指令,如 X86::ADD32ri8.
在 Select 方法最后会调用 Selectcode 方法,如下图所示。这个方法是 tablegen 为目标平台生成的。主要的作用就是将 ISD 和平台 ISD 映射到机器指令节点。这种映射通过 Matcher table 实现。

图 7
7 Instruction Scheduling
指令选择完成后的 MachineDAG 内容虽然是机器指令,但仍然是以 DAG 形式存在,CPU/GPU 不能执行 DAG,只能执行指令的线性序列。寄存器分配前的指令调度的目的就是通过给 DAG 节点指定执行顺序将 DAG 线性化。最简单的办法就是将 DAG 按拓扑结构排序,但 LLVM backend 用更智能的方法调度指令使其运行效率更高。
调度器会调用 InstrEmitter::EmitMachineNode 发射一系列指令到 MachineBasicBlock,指令的形式是 MachineInstr(MI),DAG 表示形式不再使用,可以销毁。指令调度会根据性能需要做优化,特别是考虑寄存器 footprint。

图 8
8 Register Allocation
经过指令选择阶段产生的代码是 SSA 形式的,即静态单赋值。这些代码假定可以使用无限多的虚拟寄存器。这当然是不可能的。因此接下来要执行寄存器分配,将无限的虚拟寄存器替换成有限的物理寄存器。如果物理寄存器数量不够用,虚拟寄存器就会被 assing 到内存,也就是 spill slot。但也有例外,比如在 x86 的除法指令中,输入要保存在 EDX 和 EAX 寄存器中。指令选择阶段就已经知道这个限制,因此在那个时候,也就是 select 方法中就会为除法指令分配物理寄存器而不必等到寄存器分配阶段。
寄存器分配过程依赖几个 pass 的分析结果,包括 Register coalescer 和 virtual register rewrite,如下图所示。

图 9
由于二地址转换过程中生成了 copy 指令,从而引入了新的虚拟寄存器,这对后续的物理寄存器分配带来了压力。由于 copy 指令连接的两个虚拟寄存器的值相同,因此,在某些情况下可以合并 这些虚拟寄存器的生命期(live range),这个过程叫做合并(coalesce)。
Coalescer 的目的主要是消除冗余的 copy 指令,在 RegisterCoalescer 类中实现,这是一个 machine function pass。Machine function pass 是按 function 为单位作用在机器指令而不是 IR 指令上。
在 coalescing 时,joinAllIntervals 方法遍历 copy 操作列表,joinCopy 方法从 copy 机器指令中生成 Coalescerpair,并将 copy 合并。
Interval 是程序的一对起点和终点。从起点开始,某个值被产生并在被某个临时位置持有,一直到这个值被使用和销毁。下面分析在 bc 程序上运行 Coalescer 情况,如下图所示。

图 10
其中的序号 0B,16B… 是每条 MI 的序号,也称为 slot index,每个序号对应一个 live range slot。字母 B 对应 Block,用于 live range 的进入 / 离开一个 basic block 的边界。在这个例子中,index 都带 B,因为这是默认的 slot。不同的 slot,字母 r,会出现在 interval 中,表示寄存器,用于标号一个普通的寄存器 use/def slot。
从示例中的指令可以看出,%vreg0,%vreg1,%vreg2,%vreg3 是需要分配物理寄存器的虚拟寄存器。因此在这段代码中会用掉 4 个物理寄存器,另外还有两个 & I0 和 & I1。这两个是已经使用的物理寄存器,因为有遵守 ABI 调用规则。需要这些物理寄存器传递函数参数。
在 coalescing 之前会运行活动变量(live variable)分析 pass,因此实例代码中会有活动变量信息,显示每个寄存器在哪个时刻被定义和销毁。INTERVALS 之后的信息就是活动变量分析结果,MACHINEINSTRS 之后的信息是机器指令。活动变量信息对分析寄存器的相互影响很有用,如果在同一时间有几个虚拟寄存器存活,就需要分配不同的物理寄存器。
前面提到,coalescing 只是寻找寄存器 copy。在寄存器到寄存器的 copy 中,Coalescer 会尝试将源寄存器的 interval 和目的寄存器的 interval 连起来,使源和目的寄存器公用一个物理寄存器,这样就可以减少一个 copy 指令,16B-32B 就是这种情况。Coalescer 需要知道每个虚拟寄存器存活的 interval 以便知道应该将哪些 interval 合并。例如,从示例中可以看到,虚拟寄存器 %vreg0 的 interval 是 [32r:48r:0)。这表示 %vreg0 在 32 定义,在 64 被销毁。48 后的 0 是一个代码,表示第一次定义这个 interval 的地方。0 的含义在 0@32r 中表示,说明 0 就在 32r,其实已经知道这个含义了。但如果 interval 在后面被分裂了,这个定义可以用来跟踪 interval 的原始定义。
从示例中的 interval 可以发现,%I0 的 interval 是 [0B, 32r : 0],%vreg0 的 interval 是[32r , 48r : 0]。在 32 处有一个 copy 指令将 %I0 copy 到 %vreg0。这是就可以做 coalesce,将[0B, 32r : 0] [32r , 48r : 0] 这两个 interval 合并,并为 %I0 和 %vreg0 分配同一个物理寄存器,过程如下图所示。但遗憾的是,物理寄存器(例如 %I0)的 interval 必须被保留,也就是物理寄存器不能被分配到其 live range 存活范围。所以 Coalescer 会放弃这个机会,因为担心将 %I0 分配给整个 range 可能会对整体运行性能有影响,所以让后续的寄存器分配阶段来决定。
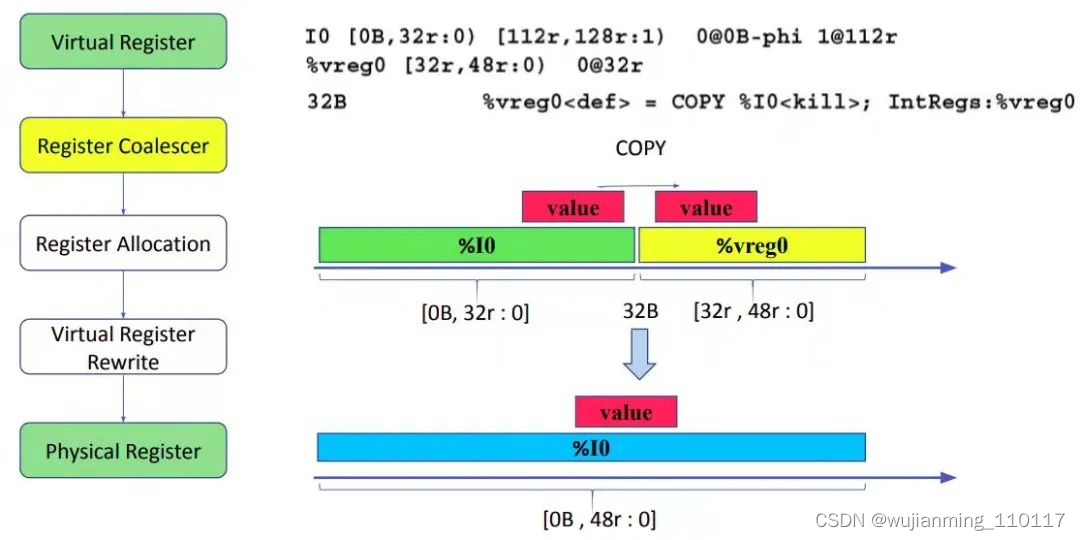
图 11
寄存器分配 pass 为每个虚拟寄存器分配物理寄存器后,VirtRegMap 会保存寄存器分配结果,实际是一张从虚拟到物理寄存器的映射表,如下图所示。接下来,虚拟寄存器 rewrite pass 要清除代码。理论上,rewrite pass 只需要把 MIR 中的虚拟寄存器替换成分配到的物理寄存器即可。虚拟寄存器 rewrite pass 会根据映射表将指令中的虚拟寄存器替换成物理寄存器,并删除相同寄存器之间的 copy 操作。所以,coalesce 不能删除的 copy 指令,寄存器分配可以通过给两段 live range 分配相同的物理寄存器,将冗余 copy 操作删除。

图 12
9 调用约定
调用约定定义描述了怎样向函数传值,以及如何从函数返回值。参数传递方式和目标平台高度相关。td 格式文件中定义的调用约定由一系列条件和预定义 action 组成。为了支持平台特定的调用约定,在 CallingConv.td 定义了目标平台返回值调用约定和基本 C 调用约定,文件中使用 CCIfType 和 CCAssignToReg 等接口指定:
• - 函数参数分配顺序
• 函数参数和返回值是放在寄存器中还是放在 stack
• 使用哪个寄存器
• caller 或 callee 是否对栈回溯
从下图的例子可以看出 CCIfType 和 CCAssignToReg 接口的用法。如果 CCIfType 预测为真,也就是说,如果当前参数类型是 f32 或 i32,就会执行 CCAssignToReg 这个动作 action,也就是将参数值赋值给 I0-I5 的第一个可用寄存器。

图 13
其中,RetCC_Sparc32 指明了对某种标量返回类型应该用哪个寄存器。例如,单精度浮点返回到 F0,双精度浮点返回到 D0,32 位整型返回到 I0/I1。CC_Sparc32 还用到了 CCAssignToStack,这个 action 会以指定的大小和对齐方式将值赋给 stack slot。在这个例子中,第一个参数 4 表示 slot 的大小为 4byte,第二个参数 4 表示 stack 是 4 字节对齐。如果参数为 0,则沿用 ABI 中的定义。
函数参数会首先尝试放入 I0-I5 中的可用寄存器。如果 I0-I5 全都被之前的函数调用占用,就会采用 stack model 的调用约定。将函数参数值放入一个 4 字节大小、4 字节对齐的 slot。
还有一种比较常用的接口是 CCDelegateTo,该接口用于查找特定的子调用约定。例子中,当前函数参数值赋值给 ST0/1 后,就会执行 RetCC_X86Common。CCDelegateTo 经过 tblgen 处理后会变成函数调用。CCIfCC 接口用于将参数 1 中给定的名称与当前调用约定匹配。如果参数 1 的名称与当前调用约定相同,参数 2 指定的 action 会被执行。例子中,如果正在使用 Fast CallingConv( “CallingConv::Fast”),RetCC_X86_32_Fast 这个 action 就会被执行。
def RetCC_X86_32_C : CallingConv<[
CCIfType<[f32],
CCAssignToReg<[ST0, ST1]>>,
CCIfType<[f64],
CCAssignToReg<[ST0, ST1]>>,
CCDelegateTo<RetCC_X86Common>
]>;
def RetCC_X86_32 : CallingConv<[
CCIfCC<“CallingConv::Fast”,
CCDelegateTo<RetCC_X86_32_Fast>>,
CCIfCC<“CallingConv::X86_SSECall”,
CCDelegateTo<RetCC_X86_32_SSE>>,
CCDelegateTo<RetCC_X86_32_C>
]>;
10 Code Emission
在介绍 code emission 之前首先介绍 MC framework。MC framework 的主要作用是对 function 和指令做底层处理。和其它后端模块相比,MC framework 设计的目的是用来辅助产生基于 LLVM 的汇编器和反汇编器。之前的 NVPTX backend 没有集成的汇编器,编译过程只能进行到发射 PTX 为止,产生 PTX 作为输出,然后依赖外部工具,比如 PTXAS 完成其余的编译步骤,如 Register Allocation 和 Code Emission。在 Code Emission 的早期阶段会用机器码指令(MCInstr)取代机器指令(MachineInstr)。和 MI 相比,MCInst 携带的程序信息较少。
Code Emission 阶段发生在所有 post-register allocation 之后。Code Emission 在 Asmprinter 这个 pass 中开始。下图是从 MI 指令到 MCInstr,再到汇编或二进制指令要经过的步骤:
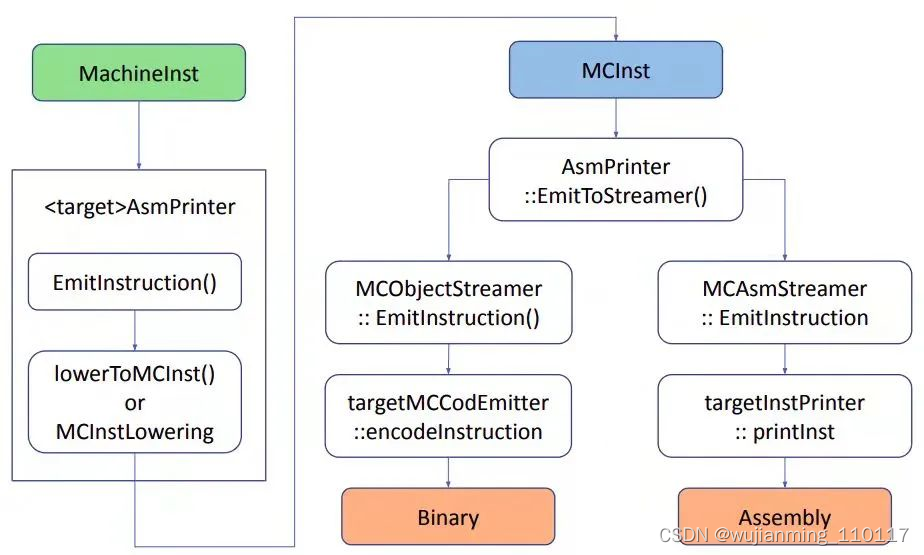
图 14
- AsmPrinter 是一个 machine function pass。
AsmPrinter 首先发射 function header,然后遍历所有基本块,一次分发一条 MI 指令到 EmitInstruction() 方法做后续处理。自定义 backend 都会提供一个 AsmPrinter 子类重载这个方法。 - 目标设备的 EmitInstruction() 收到 MI 指令输入后通过 MCInstLowering 接口将其转换为 MCInst 实例。自定义 backend 会提供 MCInstLowering 接口子类,并由其中的定制代码产生 MCInst 实例。
- 此时有两个选项:发射汇编或二进制指令。MCStreamer 类处理 MCInst 指令流,通过两种类 MCAsmStreamer 和 MCObjectStreamer 将其发射到选定的输出。MCAsmStreamer 子类将 MCInst 转换为汇编指令,MCObjectStreamer 子类将 MCInst 转换为二进制指令。
- 如果生成汇编代码,MCAsmStreamer::EmitInstruction() 被调用,并使用自定义 backend 提供的 MCInstPrinter subclass 将汇编指令打印到文件中。
- 如果生成二进制指令,MCObjectStreamer::EmitInstruction() 被调用 LLVM object code assembler,并使用自定义 backend 提供的 MCCodeEmitter::EncodeInstruction() 函数,生成二进制代码。
参考文献
【1】https://www.ibm.com/developerworks/cn/linux/l-powasm4.html
【2】LLVM Essentials
【3】LLVM Cookbook
参考文献链接
https://mp.weixin.qq.com/s/G36IllLOTXXbc4LagbNH9Q
https://mp.weixin.qq.com/s/5LW3TQFsEEnWiGF5lXZV5A
https://mp.weixin.qq.com/s/WcRRy4qJE8n_DFYf8a5INA