资源下载地址:https://download.csdn.net/download/sheziqiong/85773047
资源下载地址:https://download.csdn.net/download/sheziqiong/85773047
基于决策树的下雪预测
注:本项目算法部分仅使用numpy,pandas,random,pickle库,为了对决策树加深理解所以并未使用其他机器学习库。
1.文件结构
本项目由三个部分组成,分别是数据部分,决策树训练部分,界面设计部分,其组成如下
└─决策树训练
CART.py //CART算法实现及模型训练
config.py //参数设置
data_read.py //数据预处理以及数据集划分
main.py //主执行函数
vail_and_test.py //验证和预测
└─数据及模型
BTree.pickle //决策树模型
data.csv
rate.csv
test_data.csv //测试数据集
test_kunming.csv //原始数据集
└─界面设计
Ui_design.py //各控件实现
WidgetMain.py //主界面
2.数据处理
2.1 数据预处理
原始的数据集为test_kunming.csv,使用的是昆明市2004年到2017年的数据。
首先为避免数据集中出现nan,需要对nan数据进行排查,由于该数据集是基于时间排序的,相近的几天天气情况都差不多,所以我们碰到nan数据是可以使它等于前两行该属性数据的平均值。
再解决数据集中正负样本不均匀的情况,由于昆明市地处较南,虽然海拔较高,但下雪仍不频繁,4869条数据中仅有17条下雪数据,我们把下雪看作是正样本,不下雪看作是负样本,根据正负样本严重不均衡的情况我在这里采用了正样本扩大的方法,具体如下:
1.将正样本叠加,直到其数量等于负样本的1/3,数量表达式为 正 样 本 数 = 负 样 本 数 正 样 本 数 × 3 正样本数=\frac{负样本数}{正样本数\times 3} 正样本数=正样本数×3负样本数。
2.将此时的正样本全部特征分别乘0.9和1.1,再将这三个正样本集合叠加,得到的正样本集数量就几乎等于负样本集数量。
然后再去掉数据集中对最后影响不大的特征,首先我们直接排除年月日,因为年月日并不具有泛用性,一天是否下雪应该取决于一天具体的天气情况。然后在剩下的特征中,我们采用主成分分析(PCA)的方法,选出7个特征(我在这里选择了7个特征,具体调整config.py的choose_feature参数),做法如下:
1.分割下雪标签和其他特征,下雪标签是我们的结果,不应比较它的特征值。
2.数据标准化,这里采用了最大最小标准化。如果不进行标准化,数据值较大的特征其特征值就越大。
3.构建协方差方程,获得特征值及其对应的特征,并将其存储到rate.csv中。
4.基于特征值进行排序,选择前七大特征值的特征,并从上面处理好的数据集中选出这七个标签所对应的所有数据并且加上下雪标签组成新的数据集,并存放在data.csv中。
现在,我们得到了一组可以直接使用的数据。
2.2 划分数据集
从data.csv中直接读取数据,并采用随机抽取的方法获得训练集,验证集,测试集。其比例大致为31:4:5
并将测试集数据存储为test_data.csv留作备用。
3.模型训练
本项目中我们使用了cart算法递归地构建了决策树模型,并将训练后的决策树模型用列表保存了下来。其中,算法的具体流程如下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-W7miUAZz-1656141851405)(graph/流程图.png)]
通过训练,得到的模型如下:
[812.5, [7.15, [0.8, [7.4, 左, [12.5, [1.2, [2.2, [‘YES’], [‘YES’]], [1.5, [‘YES’], [‘YES’]]], [‘YES’]]], [8.6, [0.0, [1.6, [1.9, [‘YES’], [‘YES’]], [1.9, [‘YES’], [‘YES’]]], [3.65, [1.95, [‘YES’], [‘YES’]], [‘YES’]]], [0.001, [2.1, [1.9, [‘YES’], [‘YES’]], [‘YES’]], [2.1, [2.2, [‘YES’], [‘YES’]], [‘YES’]]]]], [5.75, [8.8, [‘NO’], [‘YES’]], [‘NO’]]], [4.6, [0.9900000000000001, [9.2, [9.45, [2.7, [2.5, [‘YES’], [‘YES’]], [2.75, [‘YES’], [‘YES’]]], [‘YES’]], [‘YES’]], [8.14, [4.6, [2.3, [1.7, [‘YES’], [‘YES’]], [1.87, [‘YES’], [‘YES’]]], [‘YES’]], [14.1, [2.3100000000000005, [1.6500000000000001, [‘YES’], [‘YES’]], [‘YES’]], [1.6, [1.5, [‘YES’], [‘YES’]], [‘YES’]]]]], [3.5, [8.14, [0.66, [4.3, [3.2, [‘YES’], [‘YES’]], [‘YES’]], [4.73, [2.4200000000000004, [‘YES’], [‘YES’]], [‘YES’]]], [7.040000000000001, [1.7600000000000002, [2.09, [‘YES’], [‘YES’]], [1.7, [‘YES’], [‘YES’]]], [0.9900000000000001, [‘YES’], [‘YES’]]]], [8.905000000000001, [5.4, [‘NO’], [0.9, [‘YES’], [2.3, [‘YES’], [‘YES’]]]], [5.940000000000001, [1.2100000000000002, [1.87, [‘YES’], [‘YES’]], [1.87, [‘YES’], [‘YES’]]], [0.9900000000000001, [2.53, [‘YES’], [‘YES’]], [1.87, [‘YES’], [‘YES’]]]]]]]]
并且,在验证集上跑该模型,得到的各参数如下图所示:
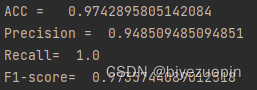
在测试集上跑该模型,得到的各参数如下图所示:
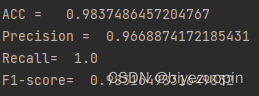
我们发现,该模型在测试集和验证集上均运行较好,精度较高。
4.界面设计
在界面设计中,我们主要设计了两个QPushButton控件用来执行操作和三个QTableWidget控件用来显示输入输出。两个按钮分别连接了predict和load函数,用来使用模型和导入数据,如下:
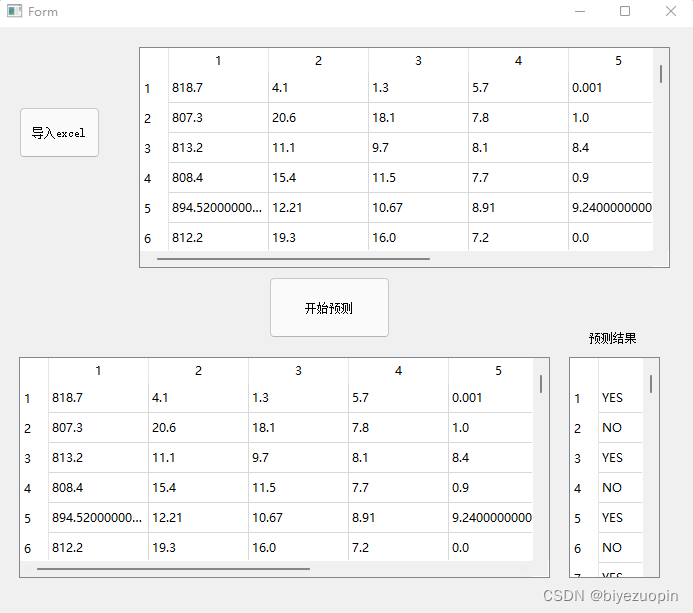
资源下载地址:https://download.csdn.net/download/sheziqiong/85773047
资源下载地址:https://download.csdn.net/download/sheziqiong/85773047