awk
- 一、AWK工具介绍
- 二.awk常用的内置变量
-
- 2.1经典案例
- 三. 其他内置变量
- 四.awk 的 if语句 单分支 多分支 双分支
一、AWK工具介绍
-
AWK 是一种处理文本文件的语言,它是一个强大的文本分析工具,它是专门为文本处理设计的编程语言,也是行处理软件,通常用于扫描、过滤、统计汇总工作。
-
可以在无交互的模式下实现复杂的文本操作;数据可以来自标准输入也可以是管道或文件
-
相较于sed常作用于一整个行的处理,awk则比较倾向于一行当中分成数个字段来处理,因为awk相当适合小型的文本数据。
1.1AWK命令的基本格式
1.awk [选项] ‘模式条件{操作}’ 文件1 文件2…
2.awk -f 脚本文件 文件1 文件2…
格式:awk关键字 选项 命令部分 ‘{xxx}’ 文件名
1.2AWK工作原理
-
前面提到
sed命令常用于一整行的处理,而awk比较倾向于将一行分成多个"字段"然后再进行处理,且默认情况下字段的分隔符为空格或tab键。awk 执行结果可以通过print的功能将字段数据打印显示。 -
在使用awk命令的过程中,可以使用逻辑操作符
"&&“表示"与”、"||“表示"或”、"!“表示"非”;还可以进行简单的数学运算,如+、-、*、/、%、^分别表示加、减、乘、除、取余和乘方。 -
awk后面
接两个单引号并加上大括号{ }来设置想要对数据进行的处理操作,awk可以处理后续接的文件,也可以读取来自前个命令的标准输。
1.3常见的内建变量(可直接用)
| 变量 | 含义 |
|---|---|
| FS | 列分割符。指定每行文本的字段分隔符,默认为空格或制表位。与"-F"作用相同 |
| NF | 当前处理的行的字段个数。 |
| NR | 当前处理的行的行号(序数)。 |
| $0 | 当前处理的行的整行内容。 |
| $1 | 代表第一列的内容 |
| $2 | 代表第二列的内容 |
| $n | 当前处理行的第n个字段(第n列)。 |
| FILENAME | 被处理的文件名。 |
| RS | 行分隔符 |
awk从文件上读取资料时,将根据RS的定义把资料切割成许多条记录,而awk一次仅读入一条记录,以进行处理。预设值是’\n’
简说:数据记录分隔,默认为\n,即每行为一条记录。
1.4 实例
1.4.1打印文本内容
-
awk可以将自动将多个空格压缩成一个空格
-
打印字符串需要加双引号
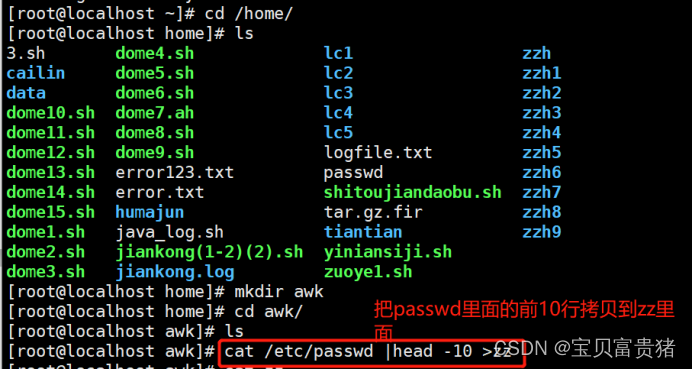
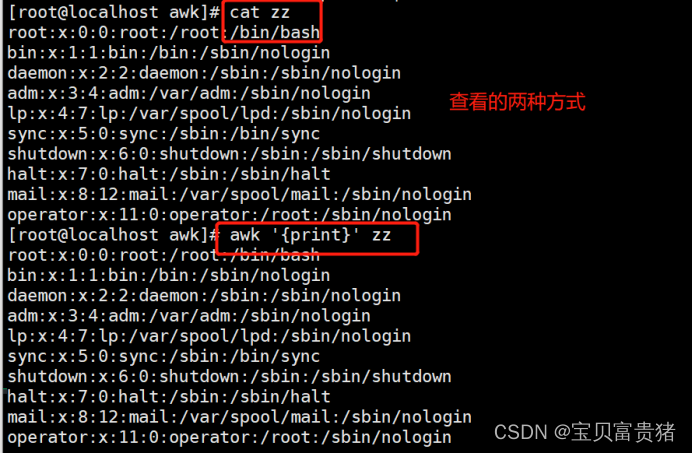
1.4.1.1 查看里面的所有内容
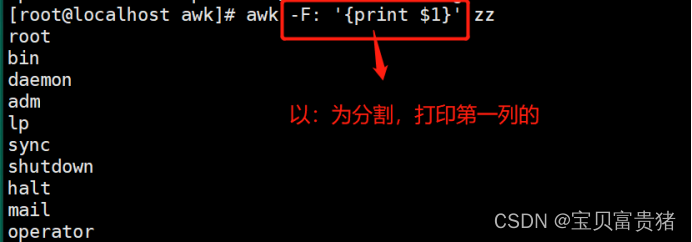
1.4.1.2 以冒号为分割,打印第一列
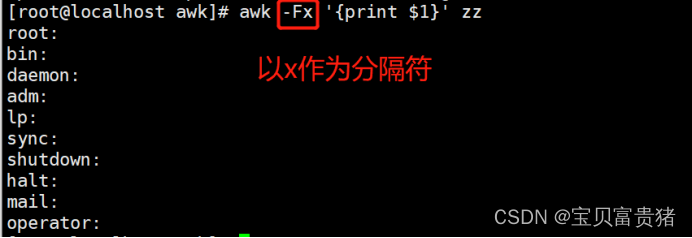
1.4.1.3 以x作为分隔符
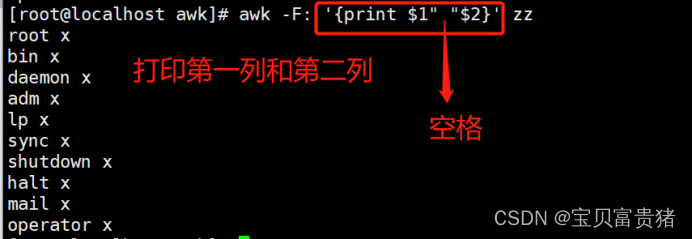
1.4.1.4 同时打印第一列和第二列内容
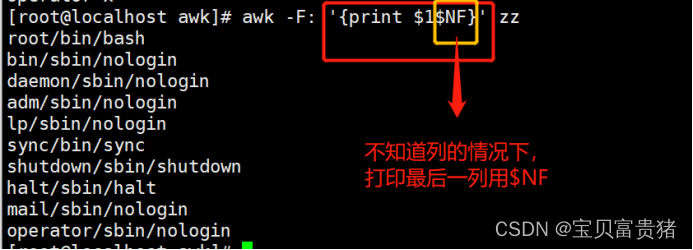
1.4.1.5 打印第一列和最后一列的内容
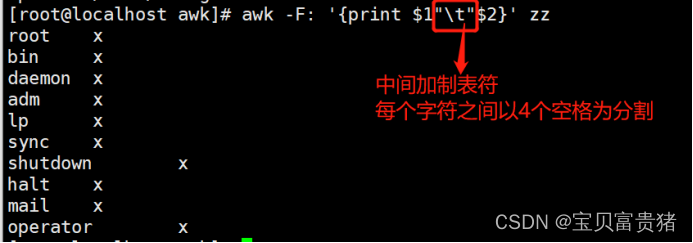
1.4.1.6 以制表符为分割
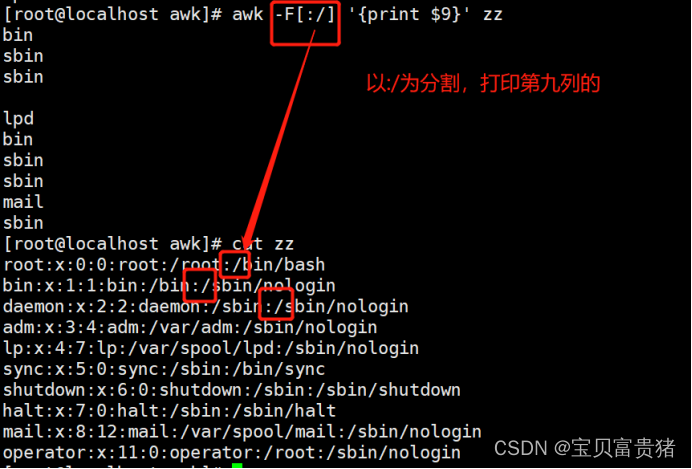
1.4.1.7 以:/为分割,打印第九列
1.4.1.8 打印磁盘已经使用情况
[root@localhost awk]# df
文件系统 1K-块 已用 可用 已用% 挂载点
/dev/sda2 44010500 5437904 38572596 13% /
devtmpfs 1914972 0 1914972 0% /dev
tmpfs 1930756 0 1930756 0% /dev/shm
tmpfs 1930756 12268 1918488 1% /run
tmpfs 1930756 0 1930756 0% /sys/fs/cgroup
/dev/sda1 508580 170724 337856 34% /boot
tmpfs 386152 0 386152 0% /run/user/0
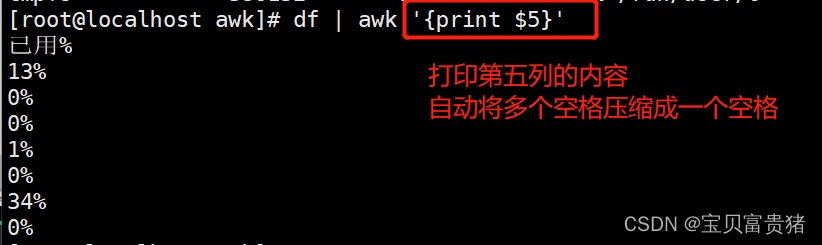
1.4.1.9 打印字符串
双引号与没有单引号的区别
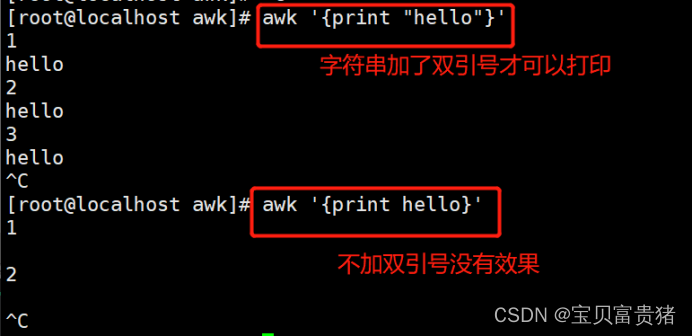
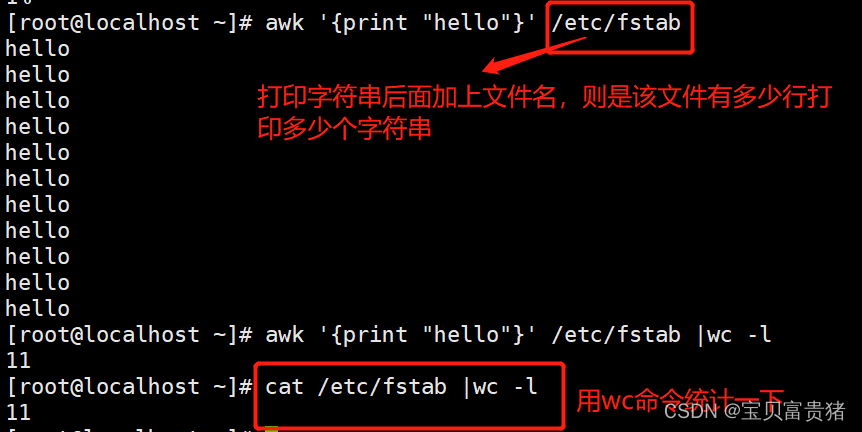
1.4.1.10打印字符串确定文件有多少行
[root@localhost ~]# awk '{print "hello"}' /etc/fstab
hello
hello
hello
hello
hello
hello
hello
hello
hello
hello
hello
[root@localhost ~]# awk '{print "hello"}' /etc/fstab |wc -l
11
[root@localhost ~]# cat /etc/fstab |wc -l
11
二.awk常用的内置变量
| 命令 | 含义 |
|---|---|
| $1 | 代表第一列 |
| $2 | 代表第二列以此类推 |
| $0 | 代表整行 |
| NF | 一行的列数 |
| NR | 行数 |
2.1经典案例
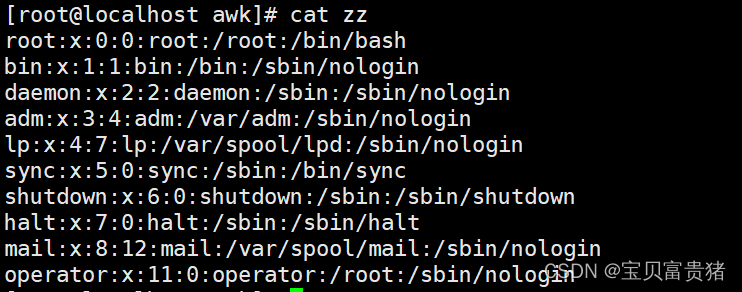
2.1.1 打印包含root的整行内容
[root@localhost awk]# awk -F: ‘/root/{print $0}’ zz
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin

2.1.2 打印包含root的行的第一列
[root@localhost awk]# awk -F: ‘/root/{print $1}’ zz
root
operator

2.1.3 打印包含root行的第一列和第六列
[root@localhost ~]# awk -F: ‘/root/{print $1,$6}’ pass.txt //打印包含root的行的第一列和第六列

2.1.4 显示root那一行的总列数

2.1.5 以:/为分割,打印包含root的行数

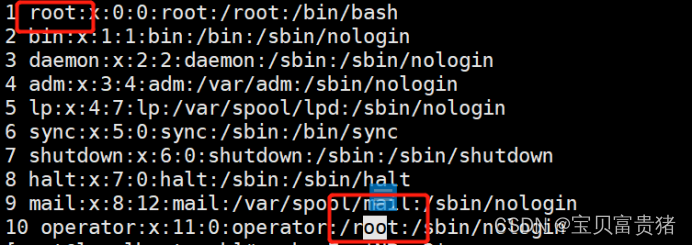
2.1.6 打印总行数

2.1.7 打印第几行的第几列
[root@localhost ~]# awk -F: ‘NR==2{print $1}’ /etc/passwd //打印第二行的第一列
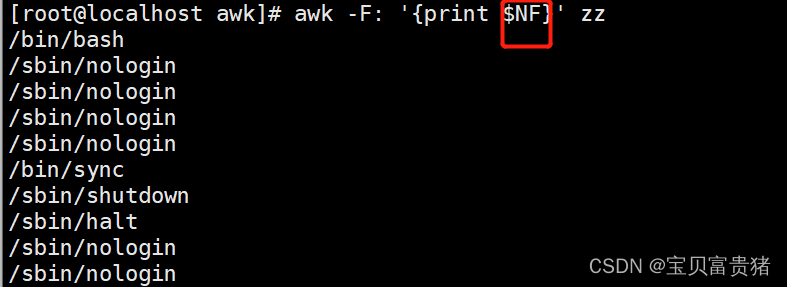
2.1.8 打印最后一列
2.1.9 打印文件最后一行
[root@localhost ~]# awk ‘END{print $0}’ /etc/passwd //打印文件最后一行

2.1.10 打印每一行的列数
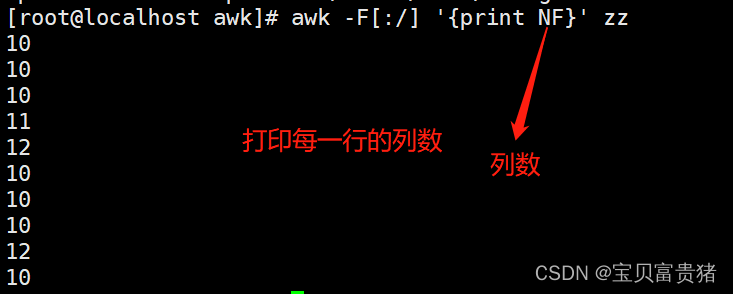
2.1.11 显示行号
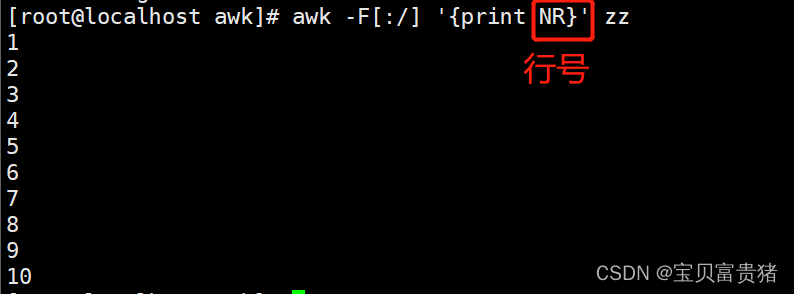
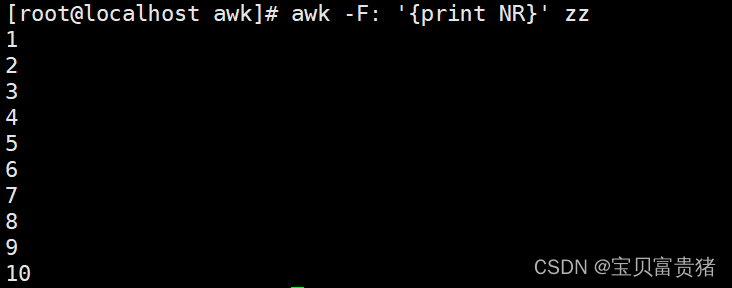
2.1.12 打印第二行
[root@localhost ~]# awk ‘NR==2’ /etc/passwd
//打印第二行,不加print也一样,默认就是打印 bin:x:1:1:bin:/bin:/sbin/nologin[root@localhost ~]# awk ‘NR==2{print}’ /etc/passwd //同上效果
bin:x:1:1:bin:/bin:/sbin/nologin

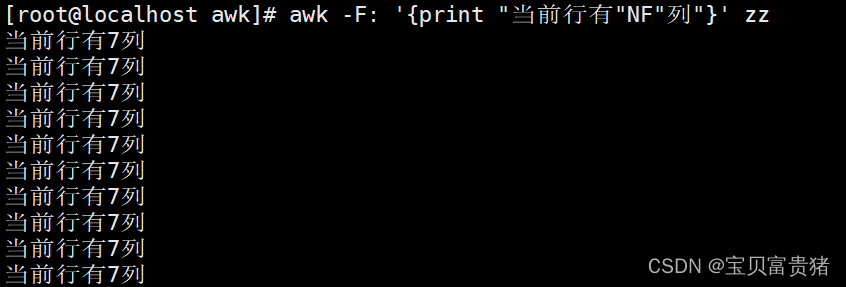
2.1.13 打印当前行有多少列
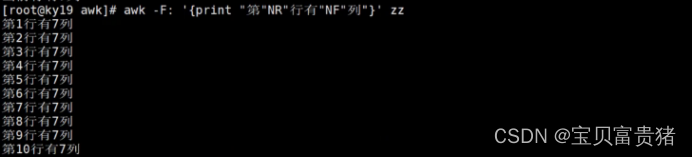
[root@localhost ~]# awk -F: '{print "当前行有"NF"列"}' zz
当前行有7列
当前行有7列
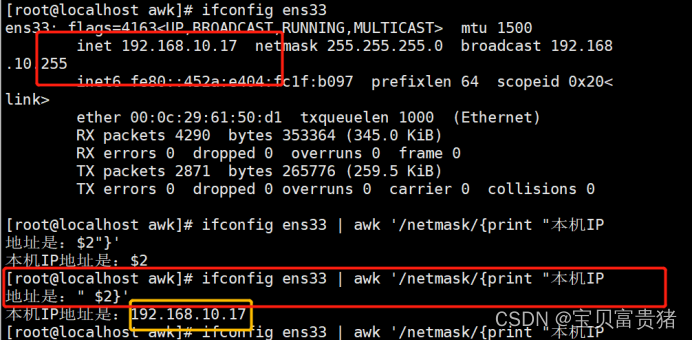
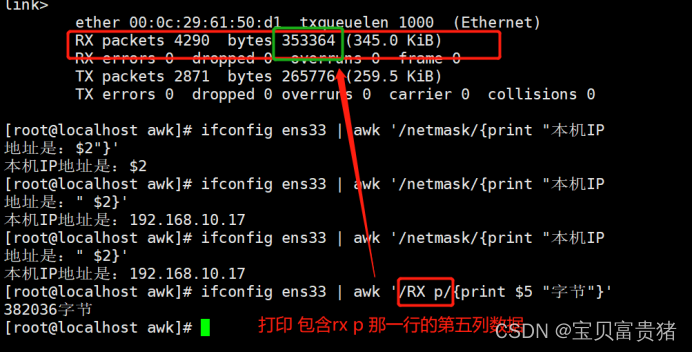
2.1.14 扩展生产:网卡的ip、流量
[root@localhost ~]# ifconfig ens33 | awk '/netmask/{print "本机的ip地址是"$2}'
本机的ip地址是192.168.245.211
[root@localhost ~]# ifconfig ens33 | awk '/RX p/{print $5"字节"}'
8341053字节
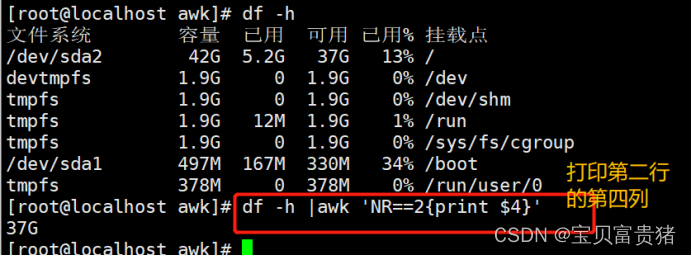
根分区的可用量
[root@localhost ~]# df -h | awk 'NR==2{print $4}'
45G
- 逐行执行开始之前执行什么任务,结束之后再执行什么任务,用
BEGIN、END - BEGIN一般用来做初始化操作,仅在读取数据记录之前执行一次
- END一般用来做汇总操作,仅在读取完数据记录之后执行一次
2.1.15 awk的运算
awk的运算案例:
[root@localhost ~]# awk 'BEGIN{x=10;print x}' //如果不用引号awk就当作一个变量来输出了,所以不需要加$了
10
[root@localhost ~]# awk 'BEGIN{x=10;print x+1}' //BEGIN在处理文件之前,所以后面不跟文件名也不影响
11
[root@localhost ~]# awk 'BEGIN{x=10;x++;print x}'
11
[root@localhost ~]# awk 'BEGIN{print x+1}' //不指定初始值,初始值就为0,如果是字符串,则默认为空
1
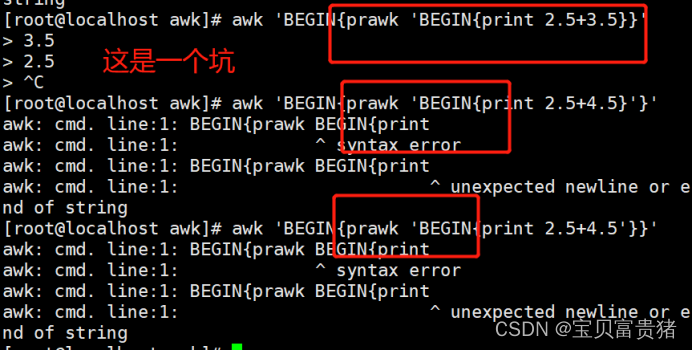
[root@localhost ~]# awk 'BEGIN{print 2.5+3.5}' //小数也可以运算
6
[root@localhost ~]# awk 'BEGIN{prawk 'BEGIN{
print 2.5+3.5}'
1
[root@localhost ~]# awk 'BEGIN{print 3*4}'
12
[root@localhost ~]# awk 'BEGIN{print 3**2}'
9
[root@localhost ~]# awk 'BEGIN{print 2^3}' //^和**都是幂运算
8
[root@localhost ~]# awk 'BEGIN{print 1/2}'
0.5
[root@localhost ~]# awk -F: '/root/' /etc/passwd //如果后面有具体打印多少列就没法省略print了
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
模糊匹配,用~表示包含,!~表示不包含
[root@localhost ~]# awk -F: '$1~/root/' /etc/passwd
root:x:0:0:root:/root:/bin/bash
[root@localhost ~]# awk -F: '$1~/ro/' /etc/passwd //模糊匹配,只要有ro就匹配上
root:x:0:0:root:/root:/bin/bash
chrony:x:993:988::/var/lib/chrony:/sbin/nologin
setroubleshoot:x:990:984::/var/lib/setroubleshoot:/sbin/nologin
[root@localhost ~]# awk -F: '$7!~/nologin$/{print $1,$7}' /etc/passwd






2.1.16 数值与字符串的比较
关于数值与字符串的比较
比较符号:== != <= >= <
1.打印第五行内容
[root@localhost ~]# awk ‘NR== 5{print}’ /etc/passwd
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
[root@localhost ~]# awk
‘NR==5’ /etc/passwd lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin

2.打印行数 <5的内容
[root@localhost ~]# awk 'NR<5' /etc/passwd
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin

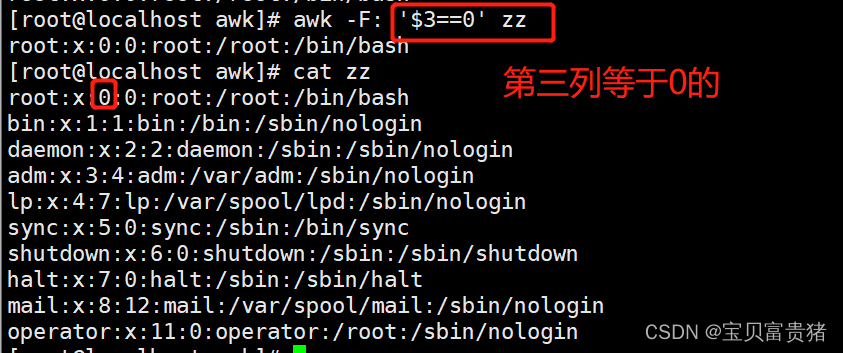
3.精确匹配与模糊匹配第一列是root的
[root@localhost ~]# awk -F: '$3==0' /etc/passwd //第三列等于0的
root:x:0:0:root:/root:/bin/bash
[root@localhost ~]# awk -F: '$1==root' /etc/passwd //第一列是root的
[root@localhost ~]# awk -F: '$1=="root"' /etc/passwd //精确匹配一定是root
root:x:0:0:root:/root:/bin/bash
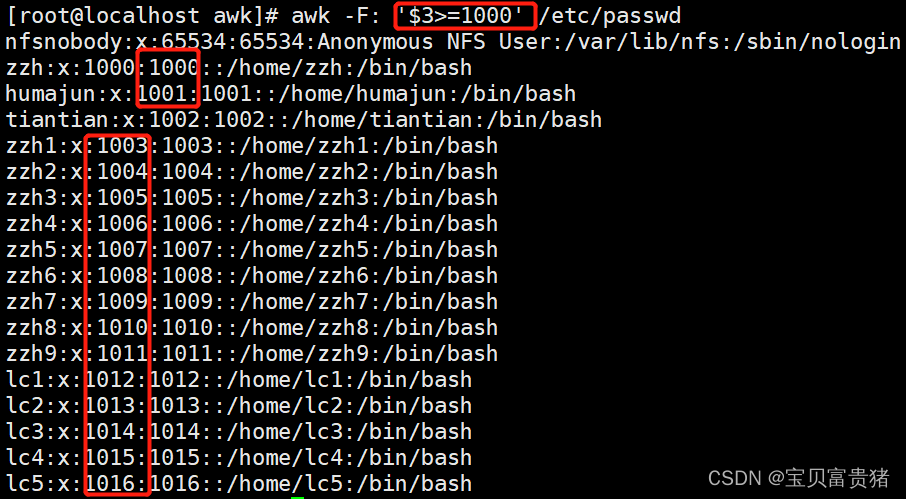
4.第三列>=1000的
[root@localhost ~]# awk -F: '$3>=1000' /etc/passwd
nfsnobody:x:65534:65534:Anonymous NFS User:/var/lib/nfs:/sbin/nologin
shengjie:x:1000:1000:shengjie:/home/shengjie:/bin/bash
2.1.17 逻辑运算 && ||
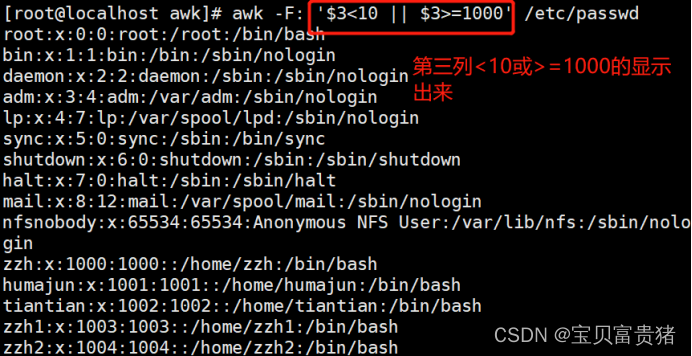
逻辑运算 && ||
[root@localhost ~]# awk -F: '$3<10 || $3>=1000' /etc/passwd
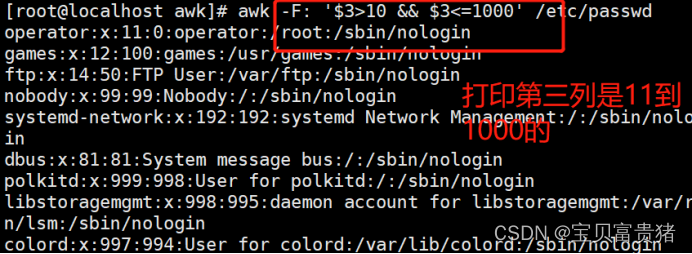
[root@localhost ~]# awk -F: '$3>10 && $3<1000' /etc/passwd
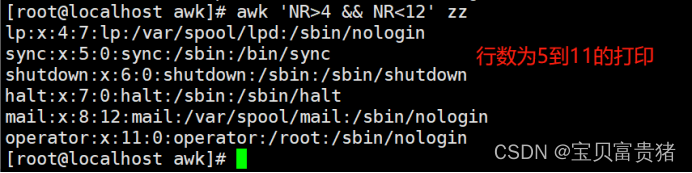
[root@localhost ~]# awk -F: 'NR>4 && NR<10' /etc/passwd
案列1:
打印1-200之间所有能被7整除并且包含数字7的整数数字
[root@localhost ~]# seq 200 | awk '$1%7==0 && $1~/7/'
7
70
77
147
175

三. 其他内置变量
其他内置变量的用法FS(输入)、OFS、NR、FNR、RS、ORS
FS:输入字段的分隔符 默认是空格
OFS:输出字段的分隔符 默认也是空格
FNR:读取文件的记录数(行号),从1开始,新的文件重新重1开始计数
RS:输入行分隔符 默认为换行符
ORS:输出行分隔符 默认也是为换行符
3.1 在打印之前定义字段分隔符为冒号
[root@localhost ~]# awk 'BEGIN{FS=":"}{print $1}' pass.txt //在打印之前定义字段分隔符为冒号
root
bin
daemon
adm
lp
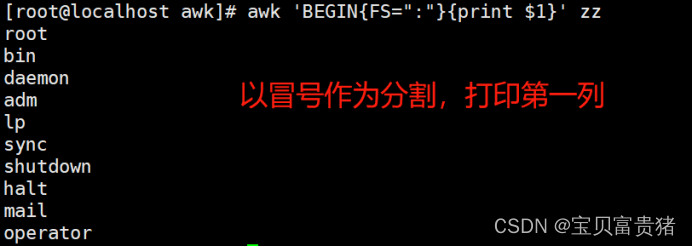
3.2 //OFS定义了输出时以什么分隔
[root@localhost ~]# awk 'BEGIN{
FS=":";OFS="---"}{
print $1,$2}' pass.txt //OFS定义了输出时以什么分隔,$1$2中间要用逗号分隔,因为逗号默认被映射为OFS变量,而这个变量默认是空格
root---x
bin---x
daemon---x
adm---x
lp---x
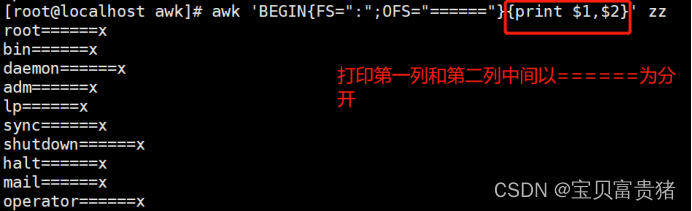
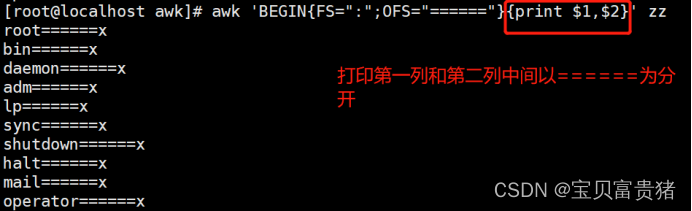
3.3 FNR的行号在追加当有多个文件时
[root@localhost ~]# awk '{print FNR,$0}' /etc/resolv.conf /etc/hosts //可以看出FNR的行号在追加当有多个文件时
1
2 nameserver 114.114.114.114
3 search localdomain
1 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
2 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
[root@localhost ~]# awk '{print NR,$0}' /etc/resolv.conf /etc/hosts
1
2 nameserver 114.114.114.114
3 search localdomain
4 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
5 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6

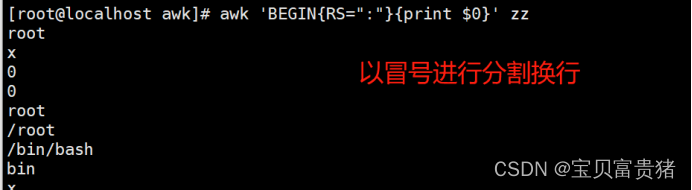
3.4 RS:指定以什么为换行符,这里指定是冒号,你指定的肯定是原文里存在的字符
[root@localhost ~]# awk 'BEGIN{RS=":"}{print $0}' /etc/passwd //RS:指定以什么为换行符,这里指定是冒号,你指定的肯定是原文里存在的字符
root
x
0
0
root
3.5 把多行合并成一行输出
[root@localhost ~]# awk 'BEGIN{ORS=" "}{print $0}' /etc/passwd
//把多行合并成一行输出,输出的时候自定义以空格分隔每行,本来默认的是回车键

3.6 awk高级用法
3.6.1 定义引用变量
[root@localhost ~]# a=100
[root@localhost ~]# awk -v b="$a" 'BEGIN{print b}' //将系统的变量a,在awk里赋值为变量b,然后调用变量b
100
[root@localhost ~]# awk 'BEGIN{print "'$a'"}' //直接调用的话需要先用双引号再用单引号
100

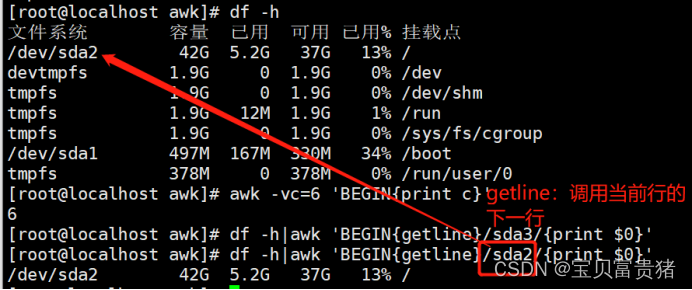
3.6.2 调用函数getline,读取一行数据的时候并不是得到当前行而是当前行的下一行
[root@localhost ~]# df -h | awk 'BEGIN{getline}/root/{print $0}'
/dev/mapper/centos-root 50G 5.2G 45G 11% /
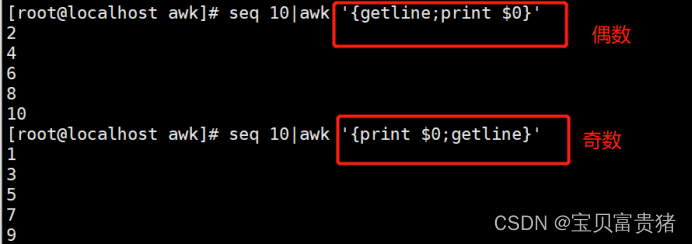
3.6.3 显示偶数行
[root@localhost ~]# seq 10 | awk '{getline;print $0}' //显示偶数行
2
4
6
8
10
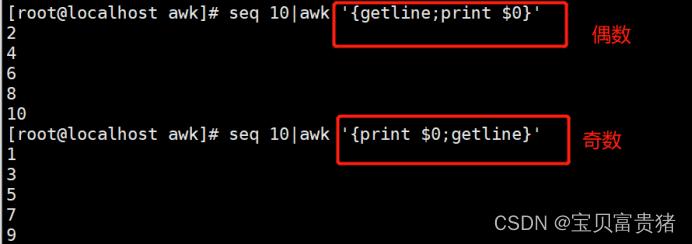
3.6.4 显示奇数行
[root@localhost ~]# seq 10 | awk '{print $0;getline}' //显示奇数行
1
3
5
7
9
四.awk 的 if语句 单分支 多分支 双分支
if语句:awk的if语句也分为单分支、双分支和多分支
单分支为if(){}
双分支为if(){}else{}
多分支为if(){}else if(){}else{}
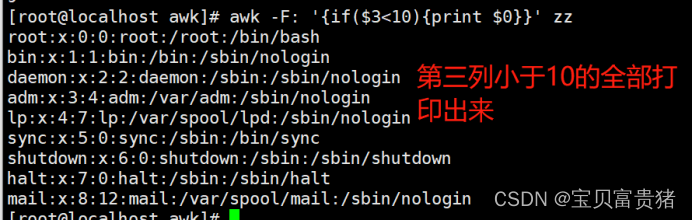
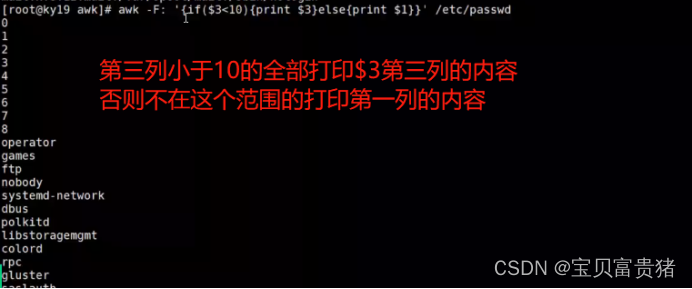
[root@localhost ~]# awk -F: '{if($3<10){print $0}}' /etc/passwd //第三列小于10的打印整行
[root@localhost ~]# awk -F: '{
if($3<10){
print $3}else{
print $1}}' /etc/passwd //第三列小于10的打印第三列,否则打印第一列
这就是awk!
喜欢请记得点个小星星哦!