基于LSTM的多变量温度预测(python)
——我保证他能够运行,而且结果能够让你满意(如果你和我一样都是一个新手的话)
这里写目录标题
一、我为什么要写这些?
因为让人抓狂的课程大作业,我小组选择了一个多变量预测方面的课题,在我这个大三基本上还没接触过Python数据处理,甚至对神经网络什么的都只是仅限于听过的情况下,这个东西简直难如登天。
然后值得高兴的是网上有很多现成的值得快速模拟入门的代码,但是令人痛苦的是:杂乱无章而且缺乏解释,最后得出的结果也不能说明问题(结果很糟糕,不知道是什么原因)。
因此,我集网上多变量实例代码,结合自己的浅薄之见,做出如下总结,同时也是方便提醒自己——毕竟一星期速成的东西…希望能够支持我完成课程作业。
二、具体做了什么?
结合了多方经验,主要有
- B站唐国梁老师的——TensoFlow2基于LSTM多变量共享单车使用预测(通过这个我快速入门了一些概念)
- 本文链接:https://blog.csdn.net/weixin_39653948/article/details/105927085(tf.keras 11: 时间序列预测之LSTM天气预测)网上大部分都是这个示例
- 以及该文章-本文链接:https://blog.csdn.net/weixin_38346042/article/details/119983658(基于LSTM温度时间序列预测,较于上面那个例子更深入,对特征进行了一些筛选)
然后我根据这些大佬的例子结合一些粗浅的理解——
- 学会使用Anaconda(下载python库的)和Jyputer(允许单步执行代码块)
- 通过python强大的绘图,肉眼扫描提取相关性特征(最有可能影响温度变化的东西)
- 实现了从零到有切分处理csv数据集
- 单手建立一个啥参数都不调的(或者叫照抄)的神经网络结构3层LSTM——单手是因为我使用cv大法的时候在吃东西
- 成功训练出了一个利用前3小时数据,精确预测下一小时温度的模型,精度达到了99%(可能是因为时间跨度短,我还不懂,不过确实能运行出结果了)
三、源代码切块加注释,恳请批评指正(●’’●)?
PS:代码是在Jyputer上运行的,使用的库是利用Anaconda下载的
如果有知道这个的小可爱,建议去知道一下,不要乱copy代码然后没有库然后在配置的时候因为tensorflow和python版本问题,相关库更新问题,还有莫名其妙的报错而愤怒摔键盘。
1. block1导入相关包
import tensorflow as tf
import matplotlib as mpl
import matplotlib.pyplot as plt
import numpy as np
import os
import pandas as pd
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import r2_score
from tensorflow.keras import utils,losses,layers,Sequential
from tensorflow.keras.callbacks import ModelCheckpoint,TensorBoard
2.读取csv数据集,搜索jena_climate_2009_2016数据集,需要的自己去下载
data_path="D:WorkSpacejena_climate_2009_2016.csv"
dataset=pd.read_csv(data_path,parse_dates=['Date Time'],index_col=['Date Time'])
dataset.shape#输出数组形状(420551, 14)(行,列)
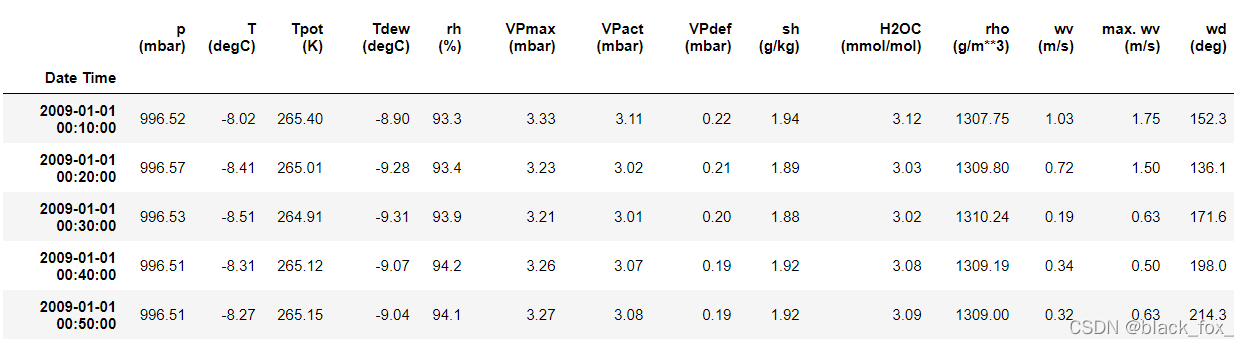
dataset.tail()#输出尾5个列
dataset.head()#数据结构如下,输出头5个列
dataset.info()
3.画图看相关性,提取有效特征集
#肉眼观察法————下面三块可以不要
plt.figure(figsize=(16,8))
#作图辅助库
sns.lineplot(x='p (mbar)',y='T (degC)',data=dataset[:10000])
plt.show()
plt.figure(figsize=(16,8))
sns.lineplot(x='Tdew (degC)',y='T (degC)',data=dataset[:10000])
plt.show()
plt.figure(figsize=(16,8))
sns.lineplot(x='max. wv (m/s)',y='T (degC)',data=dataset[:50000])
plt.show()
#以上是看T (degC)和p (mbar)、Tdew (degC)的关系
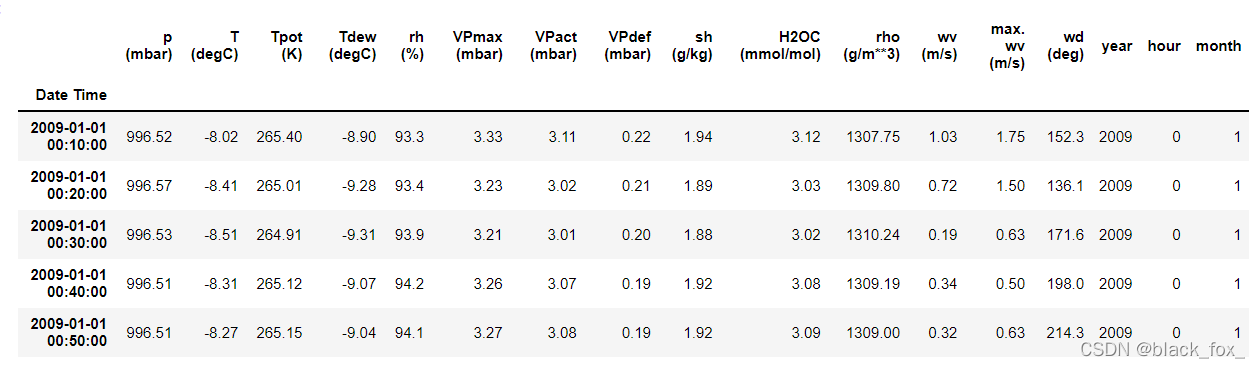
#给dataset插入新列,列为Data Time列的相应时间值
dataset['year']=dataset.index.year
dataset['hour']=dataset.index.hour
dataset['month']=dataset.index.month
dataset.head()
#时间与温度的关系图
plt.figure(figsize=(16,8))
sns.pointplot(x='hour',y='T (degC)',data=dataset[0:50000],hue='month')
plt.show()
这是实验里面最好看的一张图了
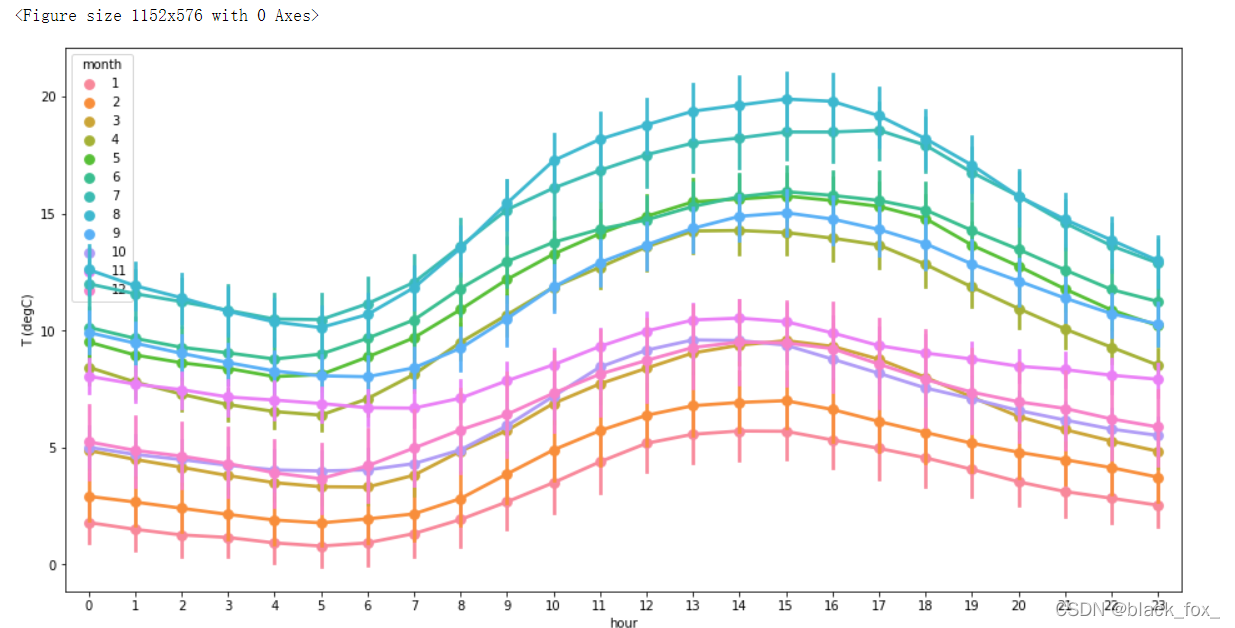
#由于温度与每日的小时变化有关系,而且0-23作为一个循环,所以用三角函数提取周期信息,sin和cos同时使用是因为确保24小时为一个周期——用就完了(建议参考相关资料)
dataset['sin(h)']=[np.sin((x) * (2 * np.pi / 24)) for x in dataset['hour']]
dataset['cos(h)']=[np.cos((x) * (2 * np.pi / 24)) for x in dataset['hour']]
4.切分数据集函数,弄成x[0].shape(i1,i2)->y[0].shape(1)的形式,表示i1条历史数据每条包含i2个特征元素-》对应1个目标检测值(也可以多个,取决于下面的设置)
#future=['sin(h)','cos(h)','month','max. wv (m/s)','p (mbar)','T (degC)']
#定义切分函数,x是选取的特征组成的例表,y是标签列(x=dataset[future=] ,y=dataset['T (degC)'])
#train_dataset,train_labels=multivariate_data(x_train,y_train,0,100000,3,1,1,True)
#上面的一个使用的意思就是:从0开始数到10万,按照3条x数据作为一个元素放入data-》1条y数据作为一个元素存入labels,step=1表示每一条数据就按照上面包装一次,比如data[0]=x[0,1,2]->labels[0]=y[3];data[1]=x[1,2,3]->labels[1]=y[4];
#single_step意思是只预测目标的一个未来状态,只预测后1小时,设置为false可以预测未来0到target_size小时内的温度。
def multivariate_data(x,y, start_index, end_index, history_size,
target_size, step, single_step):
data = []
labels = []
start_index = start_index + history_size
if end_index is None:
end_index = len(dataset) - target_size
for i in range(start_index, end_index):
indices = range(i-history_size, i, step) # step表示滑动步长
mid_data=x.iloc[indices]
data.append(mid_data)
if single_step:
mid_data=y.iloc[i+target_size]
labels.append(mid_data)
else:
labels.append(y.iloc[i:i+target_size])
return np.array(data), np.array(labels)
5.数据处理之归一化
future=['sin(h)','cos(h)','month','max. wv (m/s)','p (mbar)','T (degC)']
#数据归一化,由于sin和cos本来就是-1到1,不用归一化
for col in future:
scaler=MinMaxScaler()
if(col not in ['sin(h)','cos(h)']):
dataset[col]=scaler.fit_transform(dataset[col].values.reshape(-1,1))
# start_index=0
# end_index=100000
# history_size=3
# target_size=1
# step=1
# train_data,train_label=multivariate_data(dataset, start_index, end_index, history_size,target_size, step)
#获取训练特征和训练标签
x=dataset[future]
y=dataset['T (degC)']
#查看具体格式
x.shape
y.shape
#通过3-7划分训练集和测试集,70%为训练集
x_train,x_test,y_train,y_test=train_test_split(x,y,test_size=0.7,shuffle=False,random_state=13)
x_train.shape
#取得训练集,和测试集的格式——》(3,6)->(1,)通过3行历史数据7列目标特征预测1行1列的目标
train_dataset,train_labels=multivariate_data(x_train,y_train,0,100000,3,1,1,True)
test_dataset,test_labels=multivariate_data(x_test,y_test,0,100000,3,1,1,True)
6.格式转化与分组和打乱
#创建训练组,内部的batch_size,buffer_size,shuffle,batch建议百度
#该函数目标是把刚建好的训练集/测试集转化成tensorflow的数据集格式,打乱分组方便训练模型......
def create_batch_dataset(x,y,train=True,buffer_size=1000,batch_size=128):
batch_data=tf.data.Dataset.from_tensor_slices((tf.constant(x),tf.constant(y)))
if train:
return batch_data.cache().shuffle(buffer_size).batch(batch_size)
else:
return batch_data.batch(batch_size)
#使用上面函数
train_batch_dataset=create_batch_dataset(train_dataset,train_labels)
test_batch_dataset=create_batch_dataset(test_dataset,test_labels,train=False)
#拿一个测试集元素查看格式
list(test_batch_dataset.as_numpy_iterator())[0]
7.模型建立,相关参数的作用请百度
#建立神经网络模型-3层LSTM和一个输出层
model= tf.keras.models.Sequential([
tf.keras.layers.LSTM(256, input_shape=train_dataset.shape[-2:],return_sequences=True), # input_shape=(20,1) 不包含批处理维度
tf.keras.layers.Dropout(0.4),
tf.keras.layers.LSTM(128, return_sequences=True),
tf.keras.layers.Dropout(0.3),
tf.keras.layers.LSTM(32),
tf.keras.layers.Dense(1)
])
#优化器和损失函数设置
model.compile(optimizer='adam',loss='mse')
#模型保存的相关设置
utils.plot_model(model)
checkpoint_file='test_model.hdf5'
checkpoint_callback=ModelCheckpoint(filepath=checkpoint_file,monitor='loss',moode='min',save_best_only=True,save_weights_only=True)
#模型训练
history=model.fit(train_batch_dataset,epochs=30,validation_data=test_batch_dataset,callbacks=[checkpoint_callback])
8.成果检验——
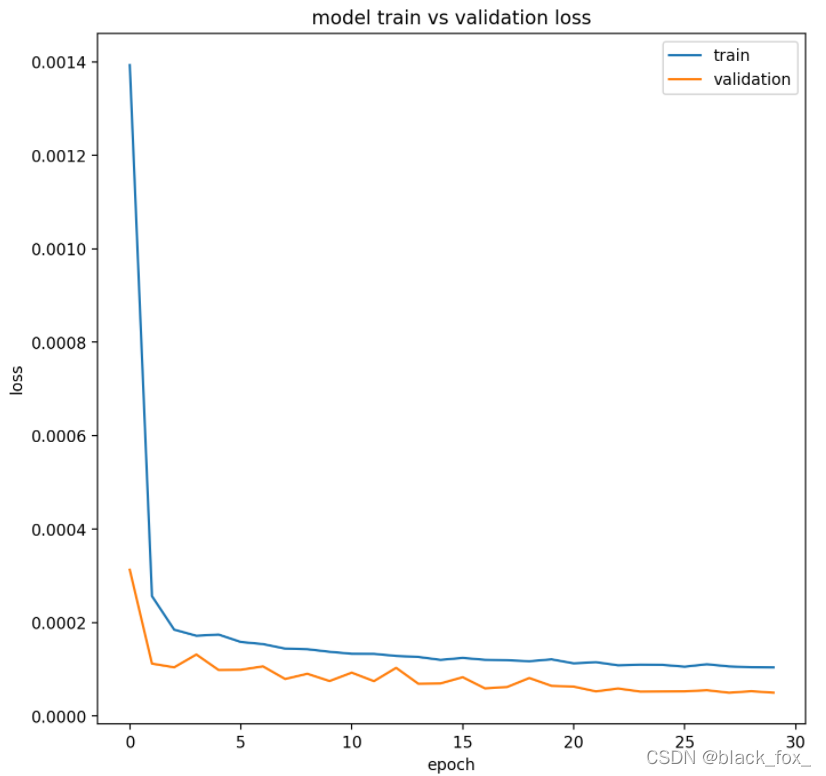
#最喜欢的绘图环节,通过history获取模型每步训练取得的结果loss和val_loss
plt.figure(figsize=(8,8),dpi=200)
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('model train vs validation loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train','validation'], loc='best')
plt.show()
test_dataset.shape
#通过输入一组数据预测
test_preds=model.predict(test_dataset,verbose=1)
test_preds[:10]
#将预测后的一组数据转化为1维方便比较
test_preds=test_preds[:,0]
test_preds[:10]
test_labels.shape
#r2检验,越接近1效果越好,负数表示完全没用......
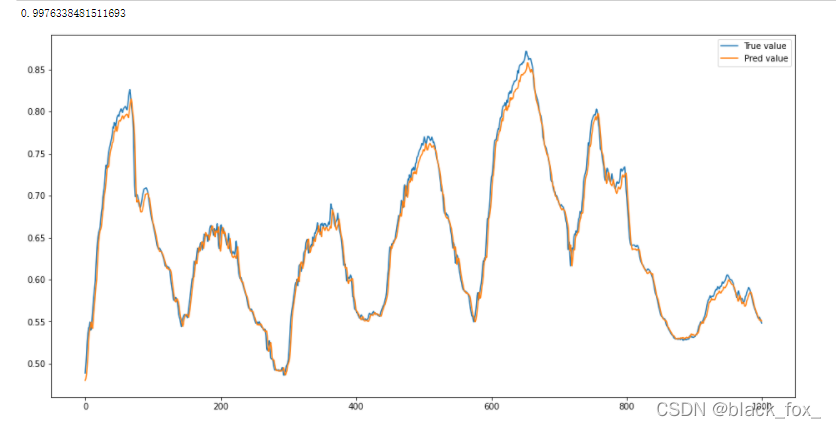
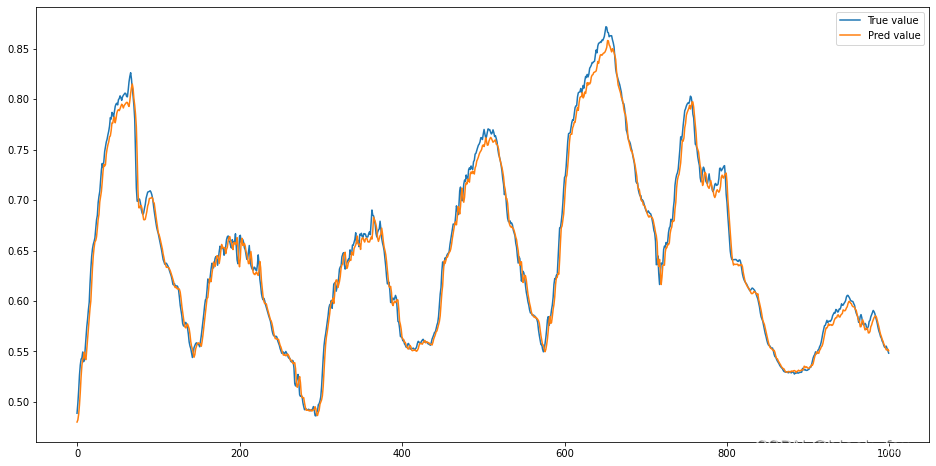
score=r2_score(test_labels,test_preds)
print(score)
#做出预测结果和实际结果的曲线对比,使用1000次结果对比
plt.figure(figsize=(16,8))
plt.plot(test_labels[:1000],label="True value")
plt.plot(test_preds[:1000],label="Pred value")
plt.legend(loc='best')
plt.show()