注意:答案并不是标准答案,这个答案是基于我本人自己对相关知识点多理解,仅供参考!如果有错误,欢迎各位小伙伴指正。本篇博客是用于记录个人的学习的。
目录
问题:
写SQL
1.创建一张User表,字段为Id(自增主键),name(不能为空),createTime(创建时间),sex(性别),idCard(身份证,唯一),age(年龄),score(分数)
2.插入一张用户名为小明,性别为男,身份证为123465789012345678,年龄18,分数88,创建时间为服务器当前时间的数据
3.查询性别为男同时年龄大于18,根据id降序排序的第5到第10条记录(包含第五条和第十条)。
4.查询各个年龄的男生所获得的分大于80的人数,若其中某一性别所有人分数低于80则需要显示该年龄性别人数为0。
Java容器
1.描述你所了解的容器集合,它们的特性是什么?(例如,HashMap,是否线程安全,是否允许数据为NUll,是否允许数据重复,数据是否有序等等)
线程池
2.创建一个线程池需要传递哪些参数,各个参数的意义是什么?线程池的运行机制是怎样的?
spring
3.Spring框架的特性与功能有哪些?
单例模式
4.写出两种线程安全的单例模式。
web
1.Controller层、Service层Dao层各自的作用,数据在从页面到数据库这个过程中的传递流程。
2.分层领域模型里,DO 、AO、VO 各自存储了哪些东西,或者说分层的规则是什么?
3.讲一下拦截器和监听器
数据库中的varchae char text
1.Varchar和char和text的区别
2.Varchar(20) 与text(20)的区别
并发相关的知识
1.ConcurrentHashMap底层的锁机制
2.Synchronized的运行机理
3.Synchronized和Lock的区别
4.JVM底层字符编码是什么?
问题+答案
写SQL
1.创建一张User表,字段为Id(自增主键),name(不能为空),createTime(创建时间),sex(性别),idCard(身份证,唯一),age(年龄),score(分数)
create table User
(id int primary key auto_increment,-- 这个约束条件有两种书写方式,这里使用的是直接在字段后面进行约束
name varchar(20) not null , -- 注意这里没有is 不是 is not
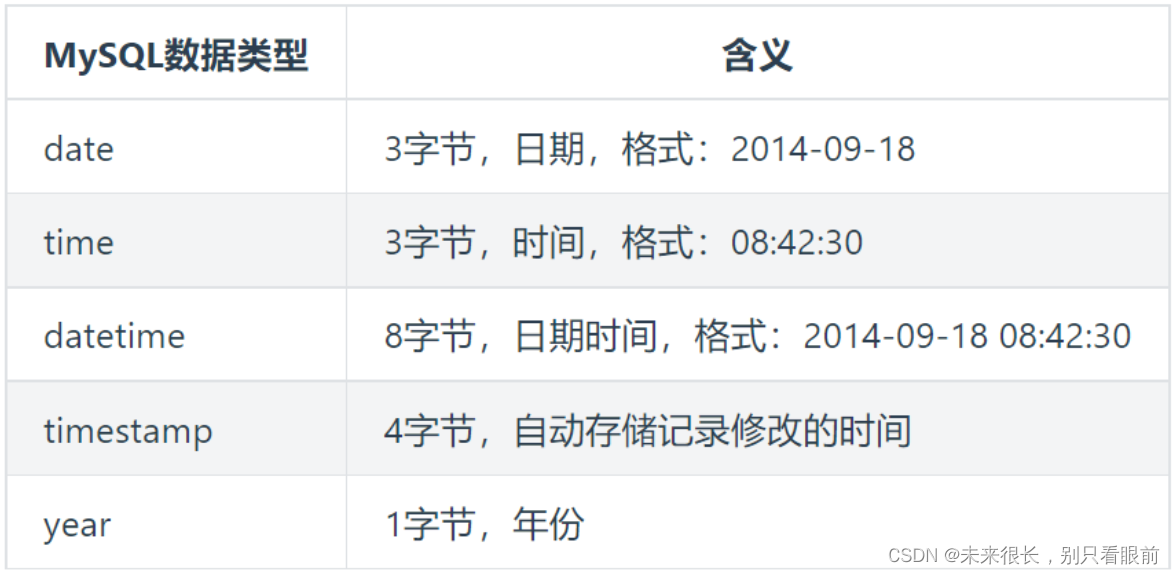
createTime datetime, -- 时间的格式要注意一下啊,你至少要知道MySQL中有哪些时间类型吧
sex varchar(1),
idCard varchar(30) unique, -- 创建表中的字段,是先写字段的名称 再写字段的数据类型,然后再写约束!!
age int,
score int -- 字段间使用逗号隔开,最后结尾的字段不需要再使用逗号了
)补充:
2.插入一张用户名为小明,性别为男,身份证为123465789012345678,年龄18,分数88,创建时间为服务器当前时间的数据
insert into user (name,sex,idCard,age,score,createTime) values ('小明','男','123465789012345678',18,88,now()); -- 注意:插入当地的系统时间使用的now() 函数!!!补充:在数据库中所有的字符串类型,必须使用单引号。
插入数据SQL语法:insert into 表名称 values (值1,值2,······)
修改SQL语句的语法:UPDATE 表名称 SET 列名称 = 新值 WHERE 列名称 = 某值
例子:update Student set name = 'lisi',sex='男' where id=1
3.查询性别为男同时年龄大于18,根据id降序排序的第5到第10条记录(包含第五条和第十条)。
select * from user where age > 18 and sex = '男' order by id desc limit 4,9
-- 注意:这个limit后面的分页【是不加括号的】!!! 4.查询各个年龄的男生所获得的分大于80的人数,若其中某一性别所有人分数低于80则需要显示该年龄性别人数为0。
select sum(if(sex = '男',1,0)) from user where sex = '男' and score > 80
-- 这里主要考察MYSQL中的if函数的使用 用到了sum求和,if函数的判断Java容器
1.描述你所了解的容器集合,它们的特性是什么?(例如,HashMap,是否线程安全,是否允许数据为NUll,是否允许数据重复,数据是否有序等等)
本人做答:
arrayList ,linkedList ,vector, hashMap ,hashSet,hashtable 等
上面只有vector,hashtable是线程安全的,其他都是线程不安全的,通过观察源码,发现 Vector 类中的大部分方法都是由 synchronized 关键字来修饰的,hashTable也是用synchronized关键字保证线程安全,对所有的读写操作都进行了锁保护,所以也是线程安全的;
arrayList 允许数据重复,数据都是有序的(arraylist底层是数组,数组存储是连续的,所以存储的是‘有序的’);
linkedList:有序且可重复;底层是链表,它的数组遍历速度慢,但增删速度很快
hashmap中是无序的,也是不能重复的,key和value可以为null ;
(HashMap在put的时候会调用hash()方法来计算key的hashcode值,可以从hash算法中看出当key==null时返回的值为0。因此key为null时,hash算法返回值为0,不会调用key的hashcode方法。)
hashset不允许数据重复,并且数据是无序的;(hashset的底层维护的就是一个hashMap)
hashTable的key和value都不可以为null;
(源码显示:Hashtable存入的value为null时,抛出NullPointerException异常。如果value不为null,而key为空,在执行到int hash = key.hashCode()时同样会抛出NullPointerException异常)
补充:

如上图所示,集合分为两大类(Collection与Map),其中List接口与Set接口是Collection众多子接口中的 两个。也可以说JAVA集合分为三大类---List、Set、Map。但是这几个接口各有特点:
-
Collection接口储存的数据无序且数据可重复
-
List接口存储的数据有序且数据可重复
-
Set接口储存的数据无序但数据不可重复
-
Map接口可以存储一组键值对象,提供key到value的映射。key唯一(不可重复)无序,value不唯一(可重复)无序
线程池
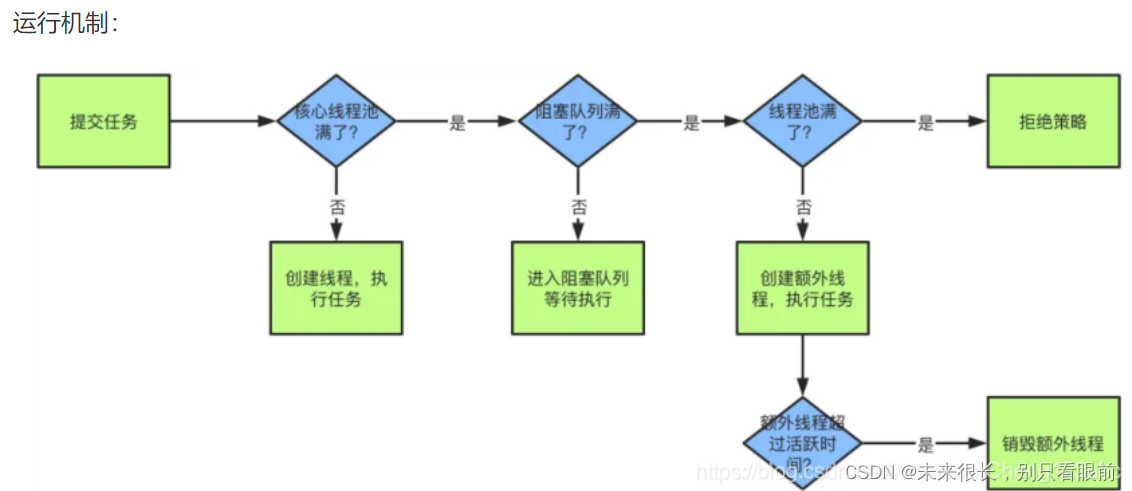
2.创建一个线程池需要传递哪些参数,各个参数的意义是什么?线程池的运行机制是怎样的?
如果是选择最多构造参数的构造方法来创建线程池的话,那么需要到的参数有:
最大线程数:就是线程池中允许存在的最大线程数量(为核心线程数加救急线程数);
核心线程数:正常工作的线程数;
救急线程的存活时间:救急线程产生后,阻塞队列的任务被执行得差不多了,此时不再需要救急线程也可以处理请求任务,那么这个救急线程的活跃存活时间就是这个参数,核心线程是没有这个参数的;
时间的单位:救急线程保持活跃时间的时间单位;
线程工厂:线程工厂,线程池中的线程的来源
阻塞队列:当核心线程的处理力度达到了最大,此时再来任务请求使用线程,那么此时这些请求任务就需要被阻塞在一个队列中,这个就是定义这个阻塞队列
拒绝策略:阻塞队列也满了,此时不再接受请求的任务,这个参数是提供了一个拒绝的策略;
spring
3.Spring框架的特性与功能有哪些?
spring的两大特性是:IOC,AOP
IOC:Inversion of Control,也叫控制反转,是把创建对象的控制权交给spring 容器来完成,开发人员只需要把要创建的对象的信息给配置好就行(以前是经常使用xml来配置bean的元信息,现在一般是通过注解加Java编程的形式来配置),这样做的好处是可以减少同一个类的对象大量存在内存中,可以减少内存开销;
IOC常见的方式是:依赖注入(DI), 就是 容器动态的将某种依赖关系注入到组件中;常见的两种方式是ByType 和ByName, 一般都是使用注解@autowire来实现自动注入的(这个是bytype)
AOP:是面向切面编程,是ioc的一种增强,是通过动态代理对功能进行增强;
AOP 主要用来解决:在不改变原有业务逻辑的情况下,增强横切逻辑代码,根本上解耦合,避免横切逻辑代码重复。
应用场景:
-
记录日志
-
自定义注解配合实现基础属性数据的初始化(比如:创建时间,修改时间等)
-
权限控制(类比一下spring security)
-
缓存优化 (第一次调用查询数据库,将查询结果放入【内存】对象, 第二次调用, 直接从内存对象返回,不需要查询数据库 )
-
事务管理 (调用方法前开启事务, 调用方法后提交关闭事务 )
补充:
IoC(Inverse of Control:控制反转)是一种设计思想 或者说是某种模式,IoC 容器是 Spring 用来实现 IoC 的载体, IoC 容器实际上就是个 Map(key,value),Map 中存放的是各种对象。
单例模式
4.写出两种线程安全的单例模式。
1.双重检索
public class Singleton {
public static volatile Singleton singleton;
public Singleton (){
}
public static Singleton getSingleton (){
if(singleton==null){
synchornized(Singleton.class){
if(singleton==null){
return new Singleton();
}
}
}
return singleton;
}
}理解:在创建第一个对象时候,可能会有线程1,线程2两个线程进入getInstance()方法,这时对象还未被创建,所以都通过第一层check。接下来的synchronized锁只有一个线程可以进入,假设线程1进入,线程2等待。线程1进入后,由于对象还未被创建,所以通过第二层check并创建好对象,由于对象singleton是被volatile修饰的,所以在对singleton修改后会立即将singleton的值从其工作内存刷回到主内存以保证其它线程的可见性。线程1结束后线程2进入synchronized代码块,由于线程1已经创建好对象并将对象值刷回到主内存,所以这时线程2看到的singleton对象不再为空,因此通过第二层check,最后获取到对象。这里volatile的作用是保证可见性,同时也禁止指令重排序;
2.使用静态内部类:
public class Singleton {
private Singleton() {
}
public static Singleton getInstance() {
return SingletonFactory.instance;
}
private static class SingletonFactory {
private static Singleton instance = new Singleton();
}静态内部类只有被主动调用的时候,JVM才会去加载这个静态内部类。外部类初次加载,会初始化静态变量、静态代码块、静态方法,但不会加载内部类和静态内部类。
静态内部类可能还存在反射攻击和反序列化攻击。
web
1.Controller层、Service层Dao层各自的作用,数据在从页面到数据库这个过程中的传递流程。
①Controller层:业务控制层,负责接收(接受前端传过来的数据)返回(把从数据库查询和经过service处理的数据返回给前端)数据和请求(可以通过url映射接受到浏览器的请求),并且调用Service层实现这个业务逻辑。
②Service层:又叫服务层或业务层,封装Dao层的操作,使一个方法对外表现为实现一种功能,例如:网购生成订单时,不仅要插入订单信息记录,还要查询商品库存是否充足,购买是否超过限制等等。
③Dao层:负责与数据库打交道具体到对某个表、某个实体的增删改查。
个人理解的过程:
浏览器在地址栏发送携带数据的请求或者是单纯的查询请求,此时通过MVC的URL映射可以在controller层接受到相关的请求,controller会对传递过来的数据在service层进行业务上的加工,service对数据的操作由是基于dao层,dao负责对数据库中的数据进行增删改查;
2.分层领域模型里,DO 、AO、VO 各自存储了哪些东西,或者说分层的规则是什么?
DO:(Data Object)阿里巴巴开发规范中对此介绍,此对象与数据库表结构一一对应,通过 DAO 层向上传输数据源对象。
AO:(ApplicationObject)应用对象,在Web层与Service层之间抽象的复用对象模型, 极为贴近展示层;
VO:(Value Object)值对象,VO就是展示用的数据,不管展示方式是网页,还是客户端,还是APP,只要是这个东西是让人看到的,这就叫VO,VO主要的存在形式就是js里面的对象(也可以简单理解成json);
想要了解更多可以查看此博客参考:阿里巴巴Java开发手册中的DO、DTO、BO、AO、VO、POJO定义_mildness丶的博客-CSDN博客_vo和po的区别
3.讲一下拦截器和监听器
拦截器是spring提供的一个组件,只有在spring项目中才可以使用拦截器,拦截器它是链式调用,一个应用中可以同时存在多个拦截器Interceptor, 一个请求也可以触发多个拦截器 ,而每个拦截器的调用会依据它的声明顺序依次执行。要使用拦截器,首先编写一个简单的拦截器处理类,请求的拦截是通过HandlerInterceptor 来实现,HandlerInterceptor 接口中也定义了三个方法:
-
preHandle() :这个方法将在请求处理之前进行调用。注意:如果该方法的返回值为false,将视为当前请求结束,不仅自身的拦截器会失效,还会导致其他的拦截器也不再执行。
-
postHandle():只有在 preHandle()方法返回值为true 时才会执行。会在Controller 中的方法调用之【后】,DispatcherServlet 返回渲染视图之前被调用。
-
afterCompletion():只有在 preHandle()方法返回值为true 时才会执行。在整个请求结束之后, DispatcherServlet 渲染了对应的视图之后执行。
监听器的作用是监听一些事件的发生从而进行一些操作,比如监听ServletContext,HttpSession的创建,销毁,从而执行一些初始化加载配置文件的操作,当Web容器启动后,Spring的监听器会启动监听,监听是否创建ServletContext的对象,如果发生了创建ServletContext对象这个事件(当web容器启动后一定会生成一个ServletContext对象,所以监听事件一定会发生),ContextLoaderListener类会实例化并且执行初始化方法,将spring的配置文件中配置的bean注册到Spring容器中;
数据库中的varchae char text
1.Varchar和char和text的区别
varchar(n) 是可变长度;
varchar(n)类型用于存储【可变长】的,长度最大为n个字符的可变长度字符数据。比如varchar(10), 然后输入abc三个字符,那么实际存储大小为3个字节。
char(n) 是定长度,最大为255 ;
char类型是【定长】的类型,即当定义的是char(10),输入的是"abc"这三个字符时,它们占的空间一样是10个字符,包括7个空字节
text也是可变长度,但是text不能设置默认值,varchar可以;
2.Varchar(20) 与text(20)的区别
相同点都是可变字符;
不同点:不太知道。。。。
并发相关的知识
1.ConcurrentHashMap底层的锁机制
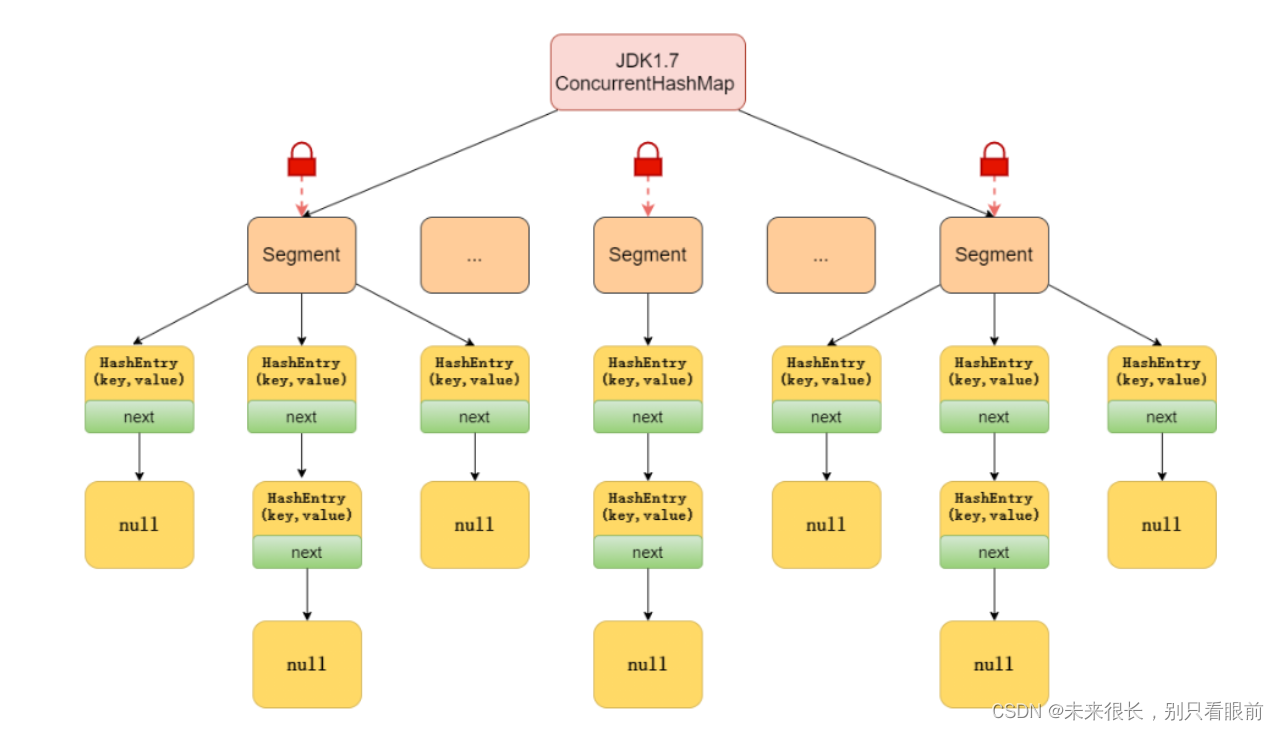
jdk1.7及之前:
-
对数据加了volatile关键字使所有数据在内存中都是可见的。
-
使用了分段锁结合重入锁ReentrantLock来保证线程安全, 数据结构:数组+链表(链表的遍历速度是o(n))。
会出现的问题:当并发执行扩容操作会出现环形链表和数据丢失的情况(因为此版本的hash表使用的是头插法);
即Segment(段)+HashEntry+ReentrantLock
jdk1.8及之后:
-
对数据加了volatile关键字使所有数据在内存中都是可见的。
-
主要利用Unsafe中的CAS操作和synchronized关键字来保证线程安全, 数据结构变成了数组+链表+红黑树(可以提高查询的速度,查询速度变成了olog(n))。
即Node(首节点) + CAS + Synchronized
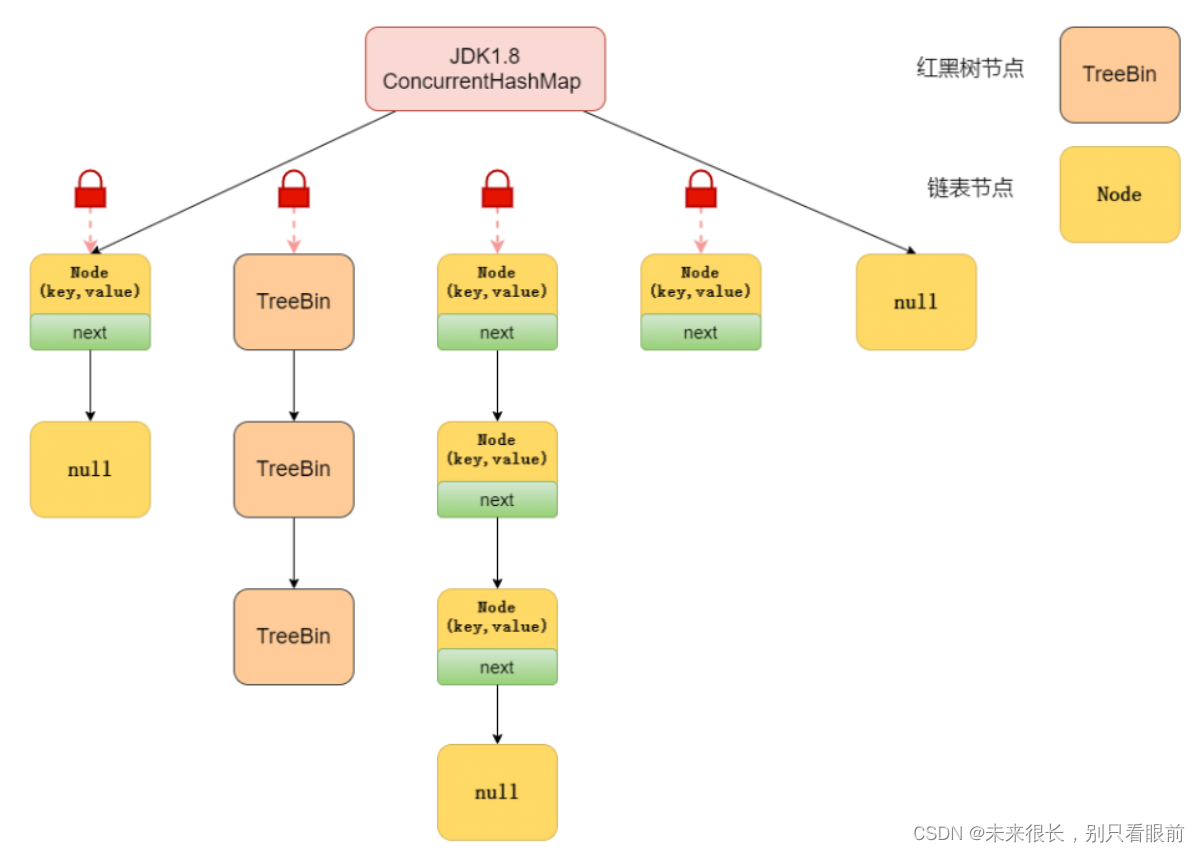 注意:
注意:
JDK1.8实现降低了锁的粒度,JDK1.7版本锁粒度是基于segment,segment下包含多个hashentry的,而JDK1.8的锁的粒度是HashEntry(首节点);
2.Synchronized的运行机理
synchronized,是使用c语言写的一个Java关键字,俗称的【对象锁】,它采用互斥的方式让同一时刻至多只有一个线程能持有【对象锁】,其它线程再想获取这个【对象锁】时就会阻塞住。这样就能保证拥有锁的线程可以安全的执行临界区内的代码,不用担心线程上下文切换。
synchronized的三个作用:
原子性:确保线程互斥的访问同步代码 可见性:保证共享变量的修改能够及时刷回主存 有序性:有效解决指令重排序问题
Synchronized在jdk1.6后完成优化后,使用Synchronized加锁jdk并不会一开始就直接使用重量级锁,而是拥有了锁膨胀的过程,根据具体的并发环境来完成锁膨胀,轻量级锁 , 偏向锁,重量级锁;锁的粒度更加细了;
想要更加深入学习,可以参考博客:Java并发编程(中上篇)从入门到深入 超详细笔记_未来很长,别只看眼前的博客-CSDN博客
3.Synchronized和Lock的区别
-
Synchronized是基于c语言开发的Java本地关键字,Lock是api层面的加锁;
-
Synchronized会在线程使用完锁后才会释放锁,或者是执行过程发生了异常,这个时候JVM会帮我们释放锁;
lock锁的释放是需要开发人员手动释放的(lock发生异常时候,不会主动释放占有的锁,必须手动unlock来释放锁,可能引起死锁的发生。),一般是在finally中释放,否则容易发生死锁;
-
Lock可以提高多个线程进行读操作的效率。(可以通过readwritelock实现读写分离)
-
lock等待锁过程中可以用interrupt来中断等待,而synchronized只能等待锁的释放,不能响应中断;
-
Lock可以通过trylock来知道有没有获取锁,而synchronized不能;
-
Synchronized和lock都是可重入,但是Synchronized只有非公平锁,lock实现了公平和非公平(默认是非公平锁);
-
在性能上来说,如果竞争资源不激烈,两者的性能是差不多的,而当竞争资源非常激烈时(即有大量线程同时竞争),此时Lock的性能要远远优于synchronized;这是因为:
-
synchronized采用的是CPU悲观锁机制,即线程获得的是独占锁。独占锁意味着其他线程只能依靠阻塞来等待线程释放锁。而在CPU转换线程阻塞时会引起线程上下文切换,当有很多线程竞争锁的时候,会引起CPU频繁的上下文切换导致效率很低。
-
而Lock用的是乐观锁方式。乐观锁实现的机制是CAS操作(Compare and Swap)。进一步研究ReentrantLock的源代码,会发现其中比较重要的获得锁的一个方法是compareAndSetState。这里其实就是调用的CPU提供的特殊指令。
-
4.JVM底层字符编码是什么?
暂时没学过...........