目前在paddle中基于该基类,已经实现了12种策略,分别为:CosineAnnealingDecay, ExponentialDecay, InverseTimeDecay, LambdaDecay, LinearWarmup, MultiStepDecay, NaturalExpDecay, NoamDecay, PiecewiseDecay, PolynomialDecay, ReduceOnPlateau, StepDecay。除此之外,博主根据网上的代码整理出了OneCycleLR。基于此,博主对13种学习率调度器的进行了可视化绘图
1、13种调度器的可视化绘图
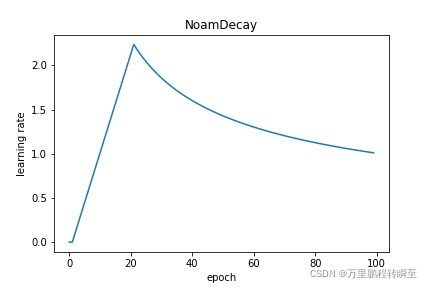
NoamDecay: 诺姆衰减,相关算法请参考 《Attention Is All You Need》 。请参考 NoamDecay
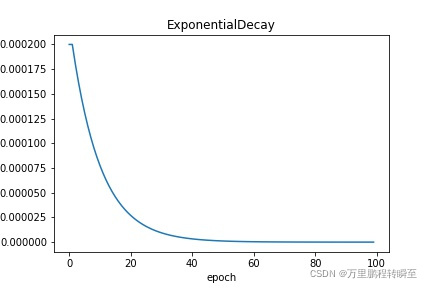
ExponentialDecay: 指数衰减,即每次将当前学习率乘以给定的衰减率得到下一个学习率。请参考 ExponentialDecay
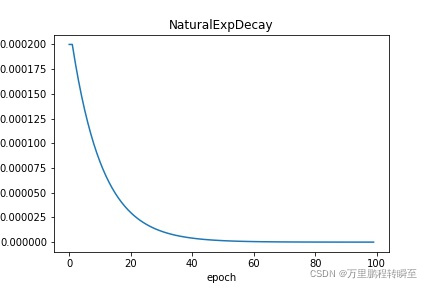
NaturalExpDecay: 自然指数衰减,即每次将当前学习率乘以给定的衰减率的自然指数得到下一个学习率。请参考 NaturalExpDecay
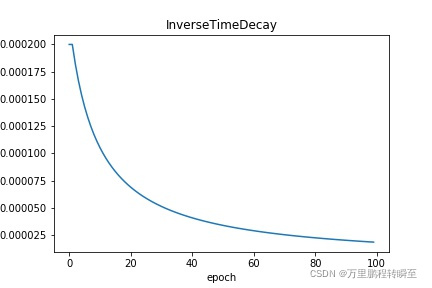
InverseTimeDecay: 逆时间衰减,即得到的学习率与当前衰减次数成反比。请参考 InverseTimeDecay
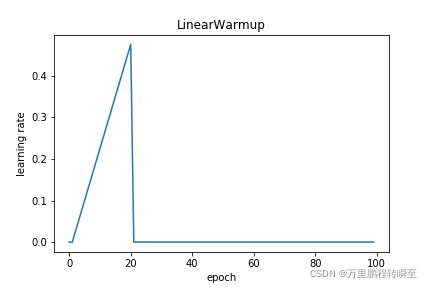
PolynomialDecay: 多项式衰减,即得到的学习率为初始学习率和给定最终学习之间由多项式计算权重定比分点的插值。请参考 cn_api_paddle_optimizer_lr_PolynomialDecay。
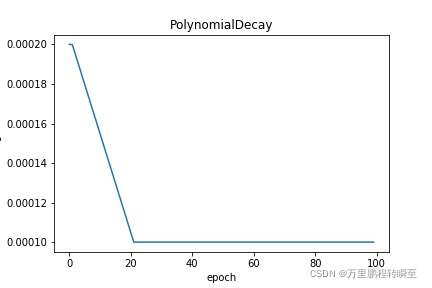
PiecewiseDecay: 分段衰减,即由给定step数分段呈阶梯状衰减,每段内学习率相同。请参考 PiecewiseDecay
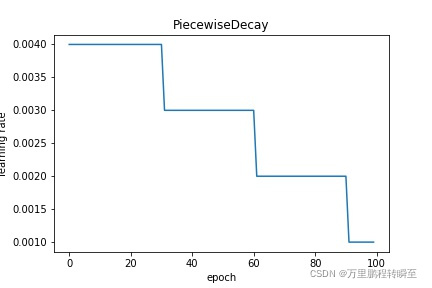
CosineAnnealingDecay: 余弦式衰减,即学习率随step数变化呈余弦函数周期变化。请参考 CosineAnnealingDecay
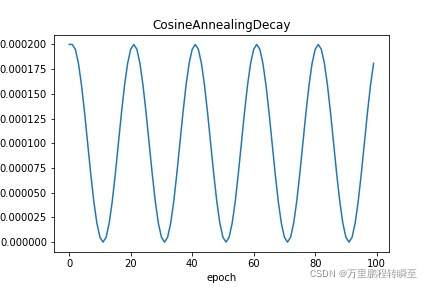
LinearWarmup: 学习率随step数线性增加到指定学习率。请参考 LinearWarmup
StepDecay: 学习率每隔固定间隔的step数进行衰减,需要指定step的间隔数。请参考 StepDecay 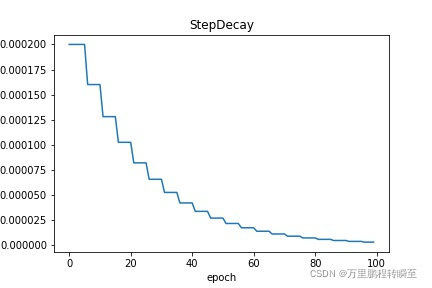
MultiStepDecay: 学习率在特定的step数时进行衰减,需要指定衰减时的节点位置。请参考 MultiStepDecay
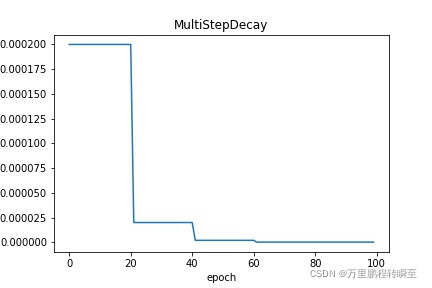
LambdaDecay: 学习率根据自定义的lambda函数进行衰减。请参考 LambdaDecay
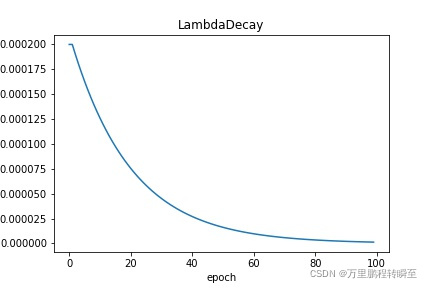
ReduceOnPlateau: 学习率根据当前监控指标(一般为loss)来进行自适应调整,当loss趋于稳定时衰减学习率。请参考 ReduceOnPlateau
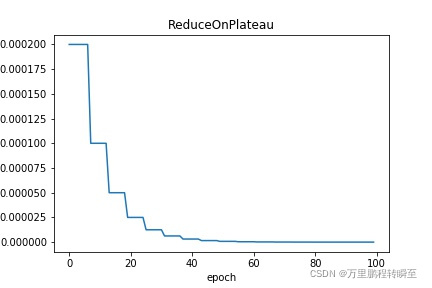
OneCysleLR:学习率先上升,达到最大值后再下降
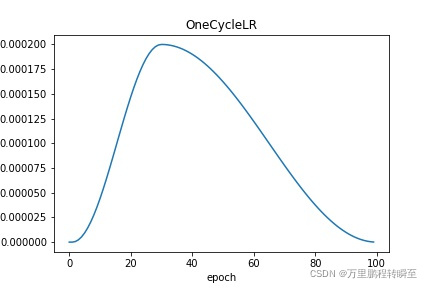
2、绘图代码及OneCysleLR的实现
通过继承paddle.optimizer.lr import LRScheduler , 重写该基类的 get_lr() 函数,实现自定义调度器。博主基于网上的公开代码进行调整,实现了OneCysleLR,并整理出代码对这13种学习率调度器曲线进行绘图。
%matplotlib inline
import paddle
import paddle.nn as nn
import matplotlib.pyplot as plt
import math
from paddle.optimizer import lr
class OneCycleLR(lr.LRScheduler):
def __init__(self,
learning_rate,
total_steps=None,
pct_start=0.3,
last_epoch=- 1,
verbose=False):
self.total_steps = total_steps
self.step_size_up = float(pct_start * self.total_steps) - 1
self.step_size_down = float(self.total_steps - self.step_size_up) - 1
self.last_epoch = last_epoch
self.learning_rate = learning_rate
super(OneCycleLR, self).__init__(learning_rate, last_epoch, verbose)
def _annealing_cos(self, start, end, pct):
"Cosine anneal from `start` to `end` as pct goes from 0.0 to 1.0."
cos_out = math.cos(math.pi * pct) + 1
return end + (start - end) / 2.0 * cos_out
def get_lr(self):
self.step_num=self.last_epoch
down_step_num = self.step_num - self.step_size_up
a = self._annealing_cos(self.learning_rate * 0.00001, self.learning_rate, self.step_num / self.step_size_up)
b = self._annealing_cos(self.learning_rate, self.learning_rate * 0.00001, down_step_num / self.step_size_down)
if self.step_num < self.step_size_up:
lr_value = a
else:
lr_value = b
return lr_value
def get_scheduler(strategy,learning_rate):
if strategy=='CosineAnnealingDecay':
#使用余弦退火算法调整学习率,其周期为T_max*2个step
scheduler = lr.CosineAnnealingDecay(learning_rate, T_max=10, verbose=False)
elif strategy=="ExponentialDecay":
#指数调度 gamma的范围要尽可能的接近1,参考范围[0.9,0.99]
scheduler=lr.ExponentialDecay(learning_rate, gamma=0.9, verbose=False)
elif strategy=='InverseTimeDecay':
#提供逆时间衰减学习率的策略,即学习率与当前衰减次数成反比
scheduler = lr.InverseTimeDecay(learning_rate, gamma=0.1, verbose=False)
elif strategy=="LambdaDecay":
#该接口提供 lambda 函数设置学习率的策略
scheduler = lr.LambdaDecay(learning_rate, lr_lambda=lambda x:0.95**x, verbose=False)
elif strategy=="LinearWarmup":
#提供一种学习率优化策略-线性学习率热身(warm up)对学习率进行初步调整。在正常调整学习率之前,先逐步增大学习率。
#warmup_steps (int) - 进行warm up过程的步数。此后的epoch中的lr将一直为learning_rate
#start_lr (float) - warm up的起始学习率。
#end_lr (float) - warm up的最终学习率。
scheduler = lr.LinearWarmup(
learning_rate, warmup_steps=20, start_lr=0, end_lr=0.5, verbose=False)
elif strategy == "MultiStepDecay":
#提供一种学习率按 指定轮数 进行衰减的策略。每达到一个milestones,lr=lr*gamma
scheduler = lr.MultiStepDecay(learning_rate, milestones=[20, 40, 60], gamma=0.1, last_epoch=- 1, verbose=False)
elif strategy == "NaturalExpDecay":
#提供按自然指数衰减学习率的策略。 lr=lr*e^-gamma*epoch
scheduler = lr.NaturalExpDecay(learning_rate, gamma=0.1, verbose=False)
elif strategy == "NoamDecay":
#源自于论文:attention is all you need [2017-12-6] https://arxiv.org/pdf/1706.03762.pdf
scheduler = lr.NoamDecay(d_model=0.01, warmup_steps=20, verbose=False)
elif strategy == "PiecewiseDecay":
#提供分段设置学习率的策略
scheduler = lr.PiecewiseDecay(boundaries=[30, 60, 90], values=[0.004, 0.003, 0.002, 0.001], verbose=False)
elif strategy == "PolynomialDecay":
#提供学习率按多项式衰减的策略。通过多项式衰减函数,使得学习率值逐步从初始的 learning_rate,衰减到 end_lr 。
scheduler = lr.PolynomialDecay(learning_rate, decay_steps=20, verbose=False)
elif strategy == "ReduceOnPlateau":
#提供按性能下降的学习率策略
#一旦模型在patience个epoch内表现不再提升,将学习率降低2-10倍对模型的训练往往有益
scheduler = lr.ReduceOnPlateau(learning_rate, factor=0.5, patience=5, verbose=False)
elif strategy == "StepDecay":
#提供一种学习率按指定 间隔 轮数衰减的策略。
scheduler = paddle.optimizer.lr.StepDecay(learning_rate, step_size=5, gamma=0.8, verbose=False)
elif strategy == "OneCycleLR":
#提供一种学习率按指定 间隔 轮数衰减的策略。
scheduler = OneCycleLR(learning_rate, total_steps=60,verbose=False)
else:
scheduler=learning_rate
print(strategy)
return scheduler
#其中LRScheduler为学习率策略的基类,定义了所有学习率调整策略的公共接口。
lr_schedulers=[x for x in dir(lr) if not x.islower() and x!="LRScheduler" and x!="Tensor"]+["OneCycleLR"]
print("内置的lr_scheduler",lr_schedulers)
model = paddle.nn.Linear(10, 10)
learning_rate=0.0002
strategy='ExponentialLR'
verbose=False
#https://www.paddlepaddle.org.cn/documentation/docs/zh/api/paddle/optimizer/lr/CosineAnnealingDecay_cn.html
max_epoch=100
data_iters=5
for strategy in lr_schedulers:
scheduler=get_scheduler(strategy,learning_rate)
#optimizer = paddle.optimizer.SGD(learning_rate=scheduler, parameters=model.parameters())
optimizer = paddle.optimizer.AdamW(learning_rate=scheduler,parameters=model.parameters(),weight_decay=0.001)
cur_lr_list = []
plt.figure()
for epoch in range(max_epoch):
for batch in range(data_iters):
optimizer.step()
#scheduler.step()
cur_lr=optimizer.get_lr()
cur_lr_list.append(cur_lr)
#print('cur_lr:',cur_lr,epoch ,batch,iters)
if "ReduceOnPlateau" in str(type(scheduler)):
loss=epoch
scheduler.step(metrics=loss) #ReduceOnPlateau
else:
scheduler.step(epoch)
x_list = list(range(len(cur_lr_list)))
plt.plot(x_list, cur_lr_list)
plt.title(strategy)
plt.xlabel("epoch")
plt.ylabel('learning rate')
plt.savefig("pltfig/%s.jpg"%strategy)
plt.show()