MAML 和 Reptile 是比较容易实现的Meta Learning 算法(Reptile是MAML的变形),它们不改变深度神经网络的结构,只改变网络的初始化参数。通过之前的学习我们知道,预训练的方法也是进行参数的初始化,那么预训练和MAML有什么不一样呢?这篇博客将对此进行总结。
1. 训练资料不同
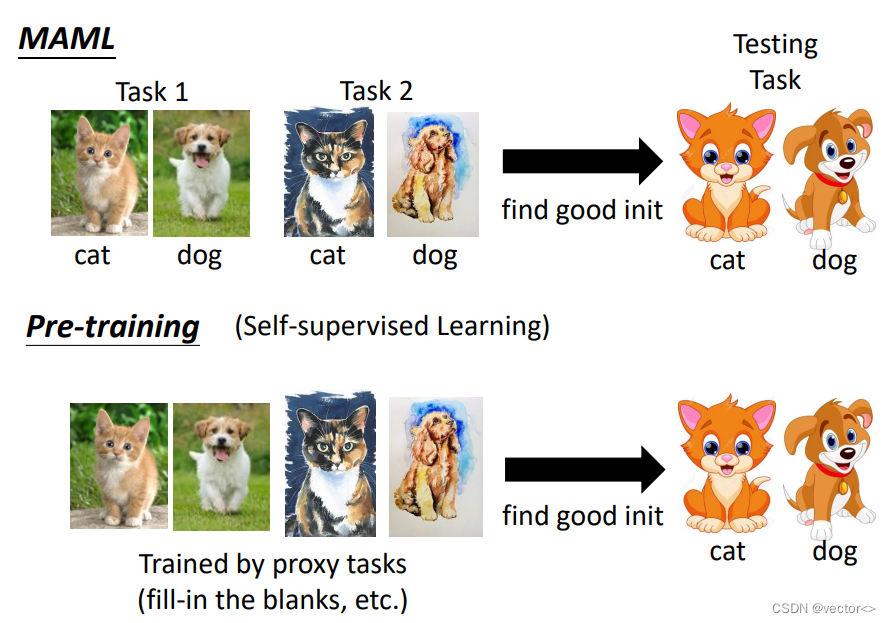
- MAML将训练资料分成不同的任务,这些任务中的训练资料都是带有标注信息的。
- Pre-training是一种自监督学习方法,所有的训练资料混在一起,并且不包含标注信息。
2. 损失函数不同
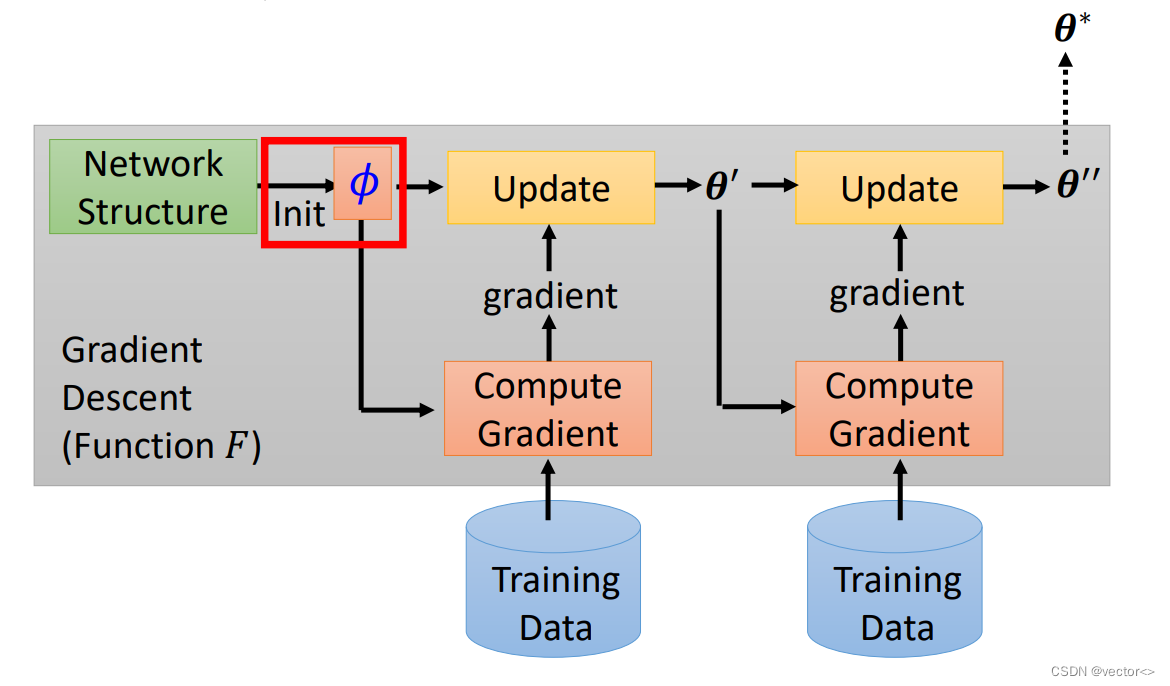
- MAML Loss Function: L ( ϕ ) = ∑ n = 1 N l n ( θ ^ n ) L(\phi)=\sum_{n=1}^{N} l^{n}\left(\hat{\theta}^{n}\right) L(ϕ)=∑n=1Nln(θ^n),损失函数是由训练过后的参数 θ ^ n \hat{\theta}^{n} θ^n计算出来的
- Pre-training Loss Function: L ( ϕ ) = ∑ n = 1 N l n ( ϕ ) L(\phi)=\sum_{n=1}^{N} l^{n}(\phi) L(ϕ)=∑n=1Nln(ϕ),损失函数是由当前正在训练的参数计算出来的。
下面来通过一个具体的例子来看一下有什么不一样:
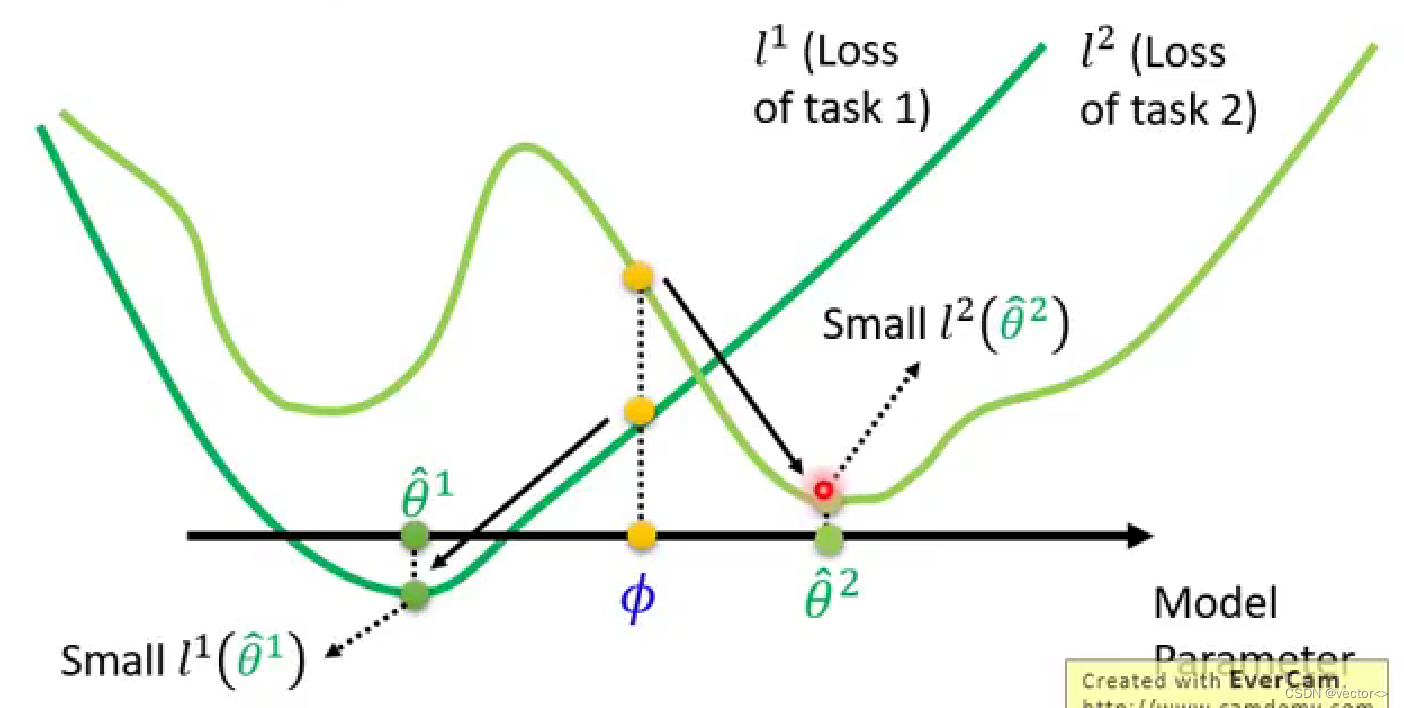
- MAML:并不在意学习到的初始参数分别在小任务上具体表现如何,在意的是初始化参数在训练之后得到的表现。比如说参数 ϕ \phi ϕ在task1和task2上都不是最佳表现,但是经过训练,沿着梯度下降的方向,很快就能找到两个任务上的最佳参数 θ ^ n \hat{\theta}^{n} θ^n
- Pre-training:找到的参数是同时在所有任务上都表现良好的 ϕ \phi ϕ,它没有把训练这件事情考虑进去,经过训练之后该参数并不一定表现得很好(比如说下图中task2的参数还有更好的选择)
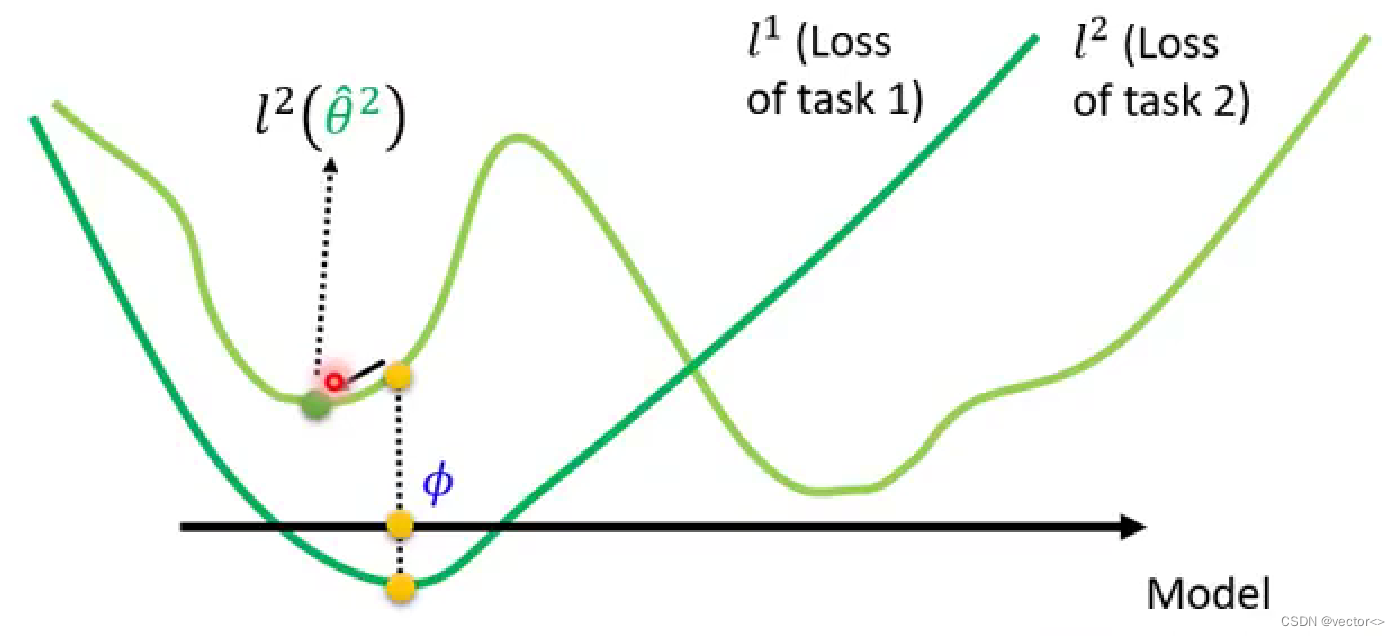
因此,MAML看的是一个model的潜力,经过训练以后它会表现得很好,而Pre-training考虑的是当前这个model的实力。
3. 参数更新方法不同
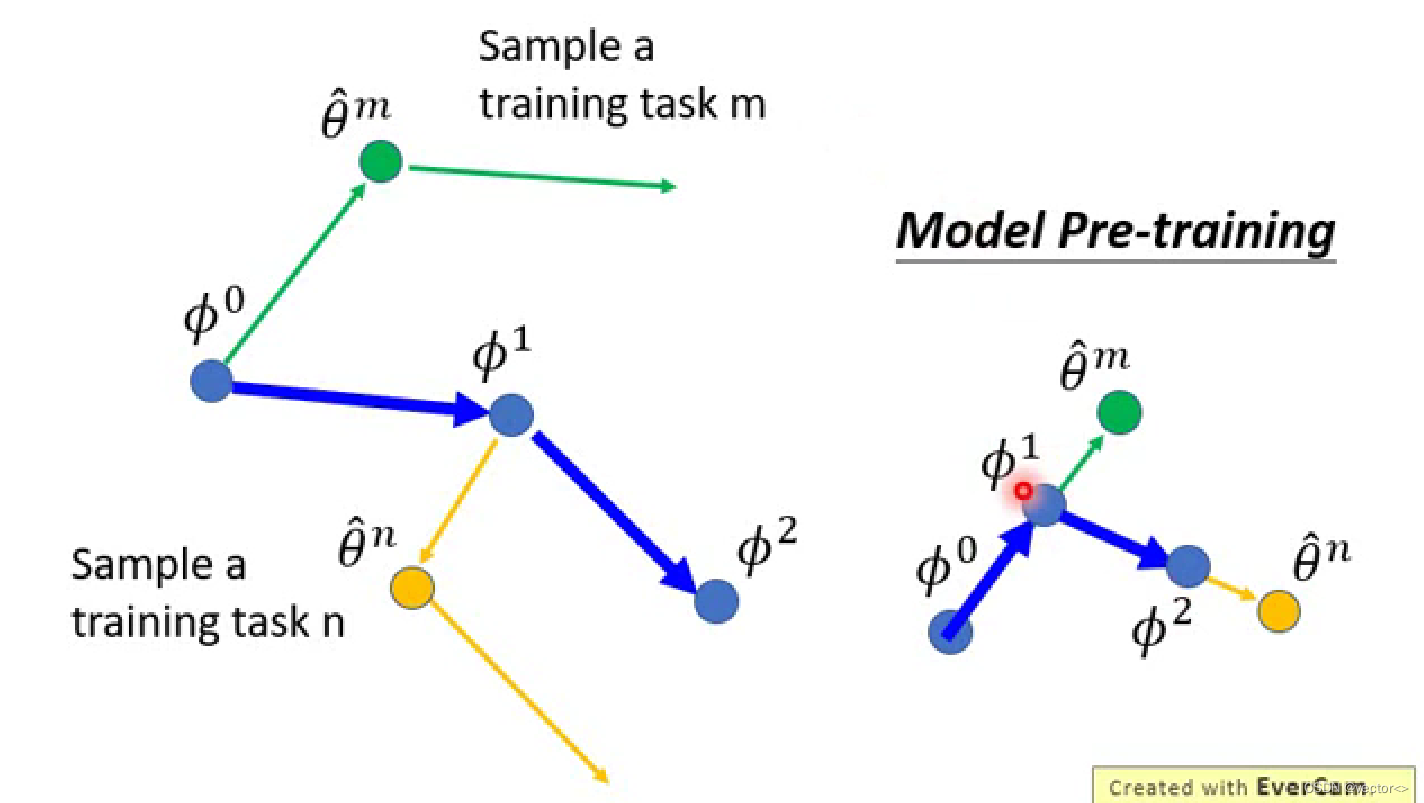
- MAML :想要寻找的这个初始参数 ϕ \phi ϕ它有一个自己的初始参数 ϕ 0 \phi^{0} ϕ0,每一个任务都会更新两次参数,第二次得到的参数用来更新 ϕ 0 \phi^{0} ϕ0得到 ϕ 1 \phi^{1} ϕ1,随后继续用另一个任务更新 ϕ 2 \phi^{2} ϕ2。
- Pre-training:每一个batch只更新一次参数, ϕ 0 \phi^{0} ϕ0沿着更新的方向改变。
其他:MAML为什么有效
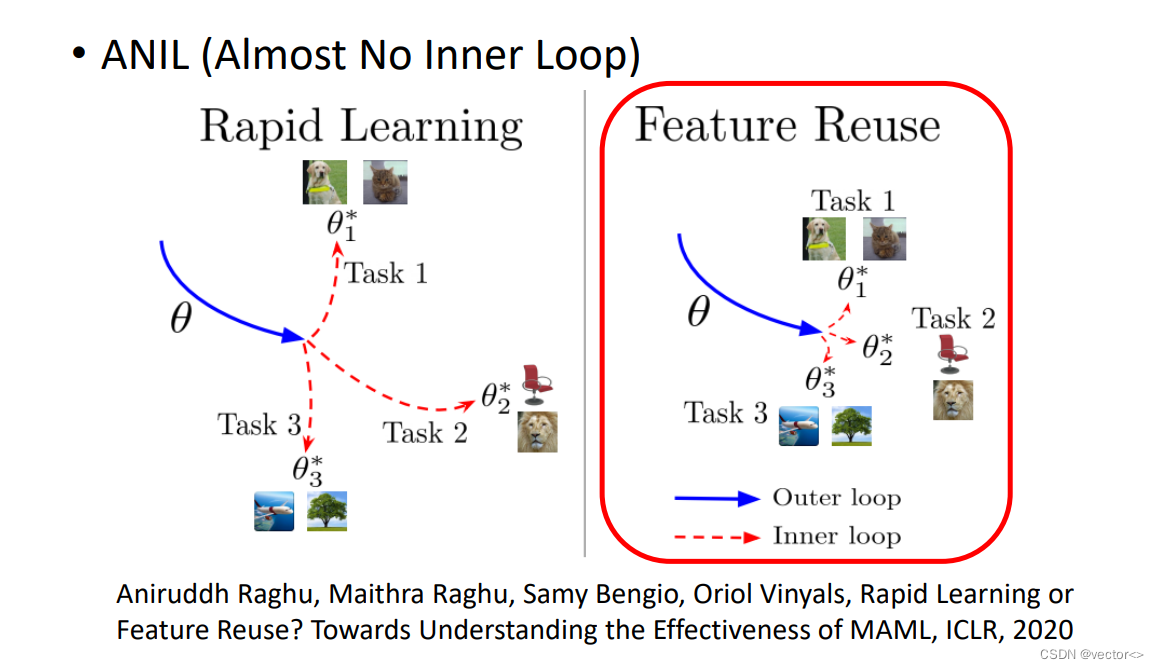
关于为什么MAML能够取得比较好的效果有两个假设:
- Rapid Learning:MAML找出来的初始化参数能够使得学习算法快速找到每一个任务上的最佳参数
- Feature Reuse:MAML找出来的初始化参数本身就与每一个任务上的最佳参数非常接近了
最终的结论是 Feature Reuse 才是MAML生效的关键原因
参考:李宏毅机器学习 https://www.bilibili.com/video/BV1KF41167VZ?p=10