作者:闫彬彬
原文来源:https://tidb.net/blog/72df3228
1 前言
为了均衡资源使用TiDB初始化后默认会创建region-scheduler、leader-scheduler、hot-region-scheduler 三个调度器分别用于磁盘容量、计算和访问热点的均衡调度,TiDB会根据计算的分值,将region follower或leader从高分值tikv调度到低分值tikv,使各节点尽量达到均衡状态,以充分利用各节点资源。
2 region调度和限制
region的调度是由PD根据tikv上报的信息产生operator下发到tikv去执行,Operator是一组用于某个调度的操作集合,比如将region 2的leader 由store 5 转移到store 3。operator调度是针对region的,实际上就是对raft成员的管理。
Region调度的基本过程如下:
(1) tikv通过StoreHeartbeat 和 RegionHeartbeat 两种心跳消息周期性的向PD报告store和region状态信息。如容量、流量、region范围、副本状态等信息。
(2) scheduler每隔一定时间会根据tikv上报的信息生成operator,每种调度会考虑不同调度逻辑和限制约束等。
(3) scheduler产生operator会放到等待队列中,随机选择或根据优先级将等待队列中的operator加入到notifyqueue中等待下发,同时会将operator转移到运行队列中从等待队列中删除。
(4) 之后等到tikv发送心跳时,将相应的operator通过心跳处理信息发送给region leader去处理。
(5) leader根据operator step完成调度处理,处理完成后或超时后,pd从运行队列中移除相关operator。
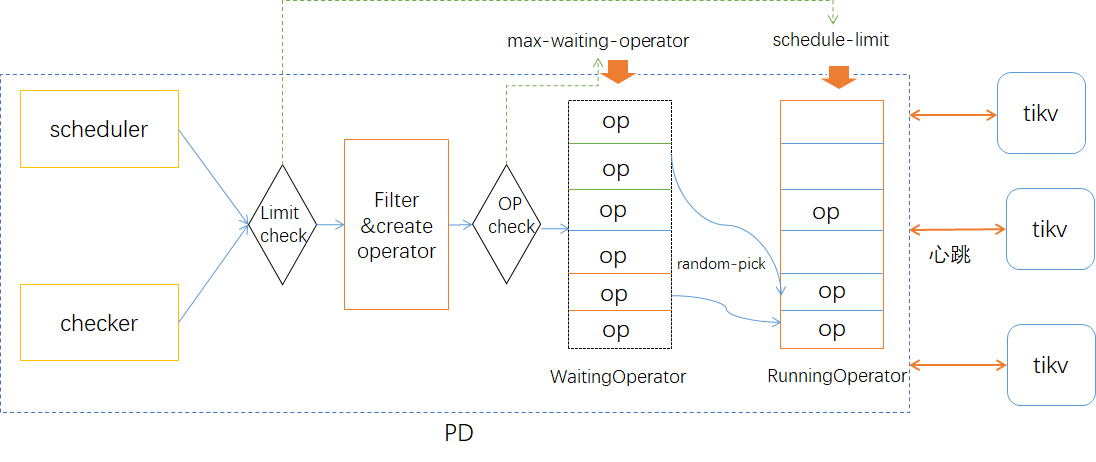
为控制调度速度,PD提供了相关参数进行限制,balance-leader的调度速度由leader-schedule-limit参数限制(默认值4),调度执行时会首先判断是否允创建operator,当前runningOperator队列中相应类型的operator数量小于limit参数限制时才允许调度产生operator,之后将产生的Operator加入到等待队列。
另外scheduler-max-waiting-operator参数限制waitingOperator队列中每类调度最大的operator数量(4.0版本后默认为5),当operator数量达到参数值时则也不允许添加operator,从而也会影响operator产生速度。在6.0版本中该参数被设置为了隐藏参数,通过pd-ctl config show all命令才能看到,可使用pd-ctl config set修改。
3 leader调度加速实现
leader的均衡由balance-leader-scheduler调度器控制,每隔一定时间会进行一次调度,间隔的最小时间是10ms(MinScheduleInterval),当调度失败次数达到10次后,会调整间隔时间,最大间隔时间不超5秒。
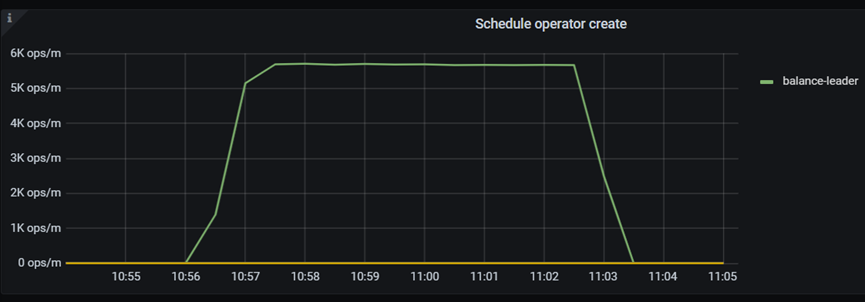
理想情况下balance-leader-scheduler每隔10ms完成一次调度,1秒内最多产100个operator,处理100个region leader的转移,当集群数据量很大时,当tikv重启后,由于operator产生速度的影响导致leader调度速度,较长时间的不均衡容易引发性能问题。比如当有10万个region leader需要调度时完成operator的创建就得需要17分钟。
一种优化方式就是在不减少调度间隔增加压力的情况下,通过每次调度产生多个operator以提升operator的产生速度,为此6.0版本中为balance-leader-scheduler添加了batch选项,通过pd-ctl工具修改,默认值为4(受leader-schedule-limit、scheduler-max-waiting-operator限制),可选范围值为1-10,这样在每次sheduler调度时产生多个operator,从而提升transfer leader速度。
| $ pd-ctl -u pd-address:pd_port scheduler config balance-leader-scheduler set batch 6$ pd-ctl -u pd-address:pd_port scheduler config balance-leader-scheduler{ "ranges": [ { "start-key": "", "end-key": "" } ], "batch": 6} |
4 测试
4.1 测试环境
3个tikv,每tikv 个约3.5万个region,总存储大小13.2TB。
4.2 测试方式
每次测试前stop tikv然后修改相关参数后启动tikv,观察tikv监控的leader均衡时间。
4.3 测试结果
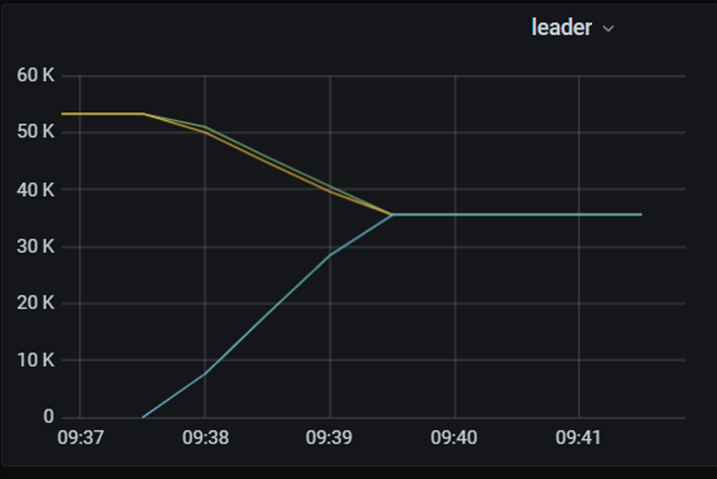
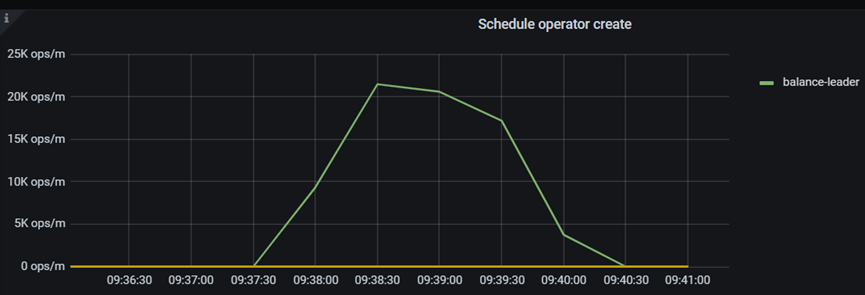
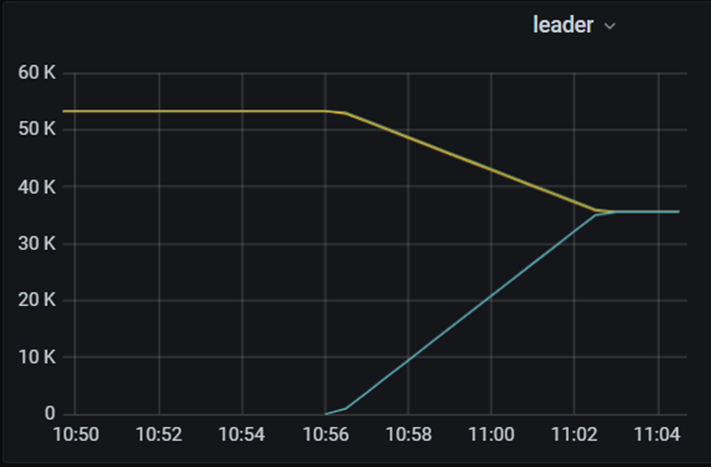
不同参数值下tikv重启后leader均衡时间
| schedule-limit | max-waiting-operator | batch | leader均衡时间 | |
| 默认值 | 4 | 5 | 4 | 2分钟 |
| 旧版本 | 4 | 5 | 1 | 7分钟 |
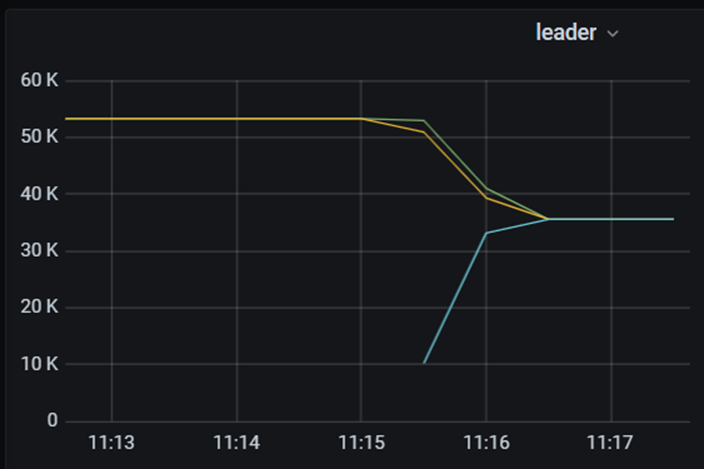
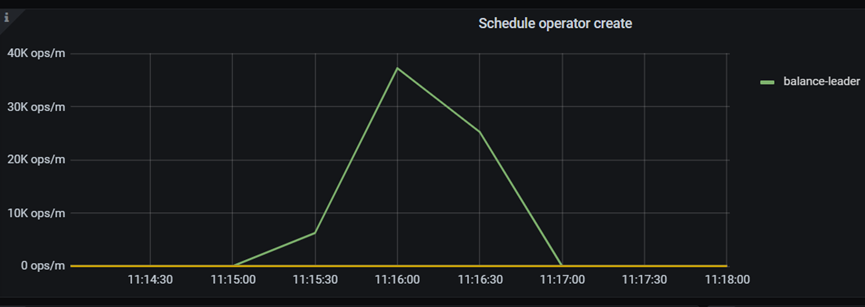
| 较高值 | 10 | 10 | 10 | 1分钟 |
| 最低值 | 1 | 1 | 1 | 无法均衡 |
不同参数值下tikv重启后leader监控
n 默认值
n 旧版本
6.0版本前leader-scheduler没有batch选项,通过设置选项值为1模拟。
n 较高值
n 最低值:
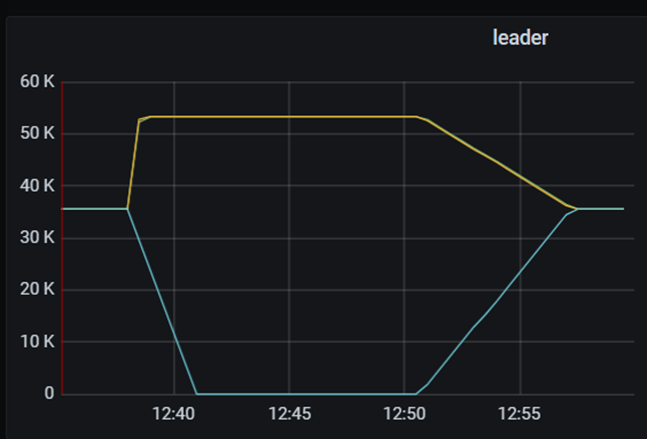
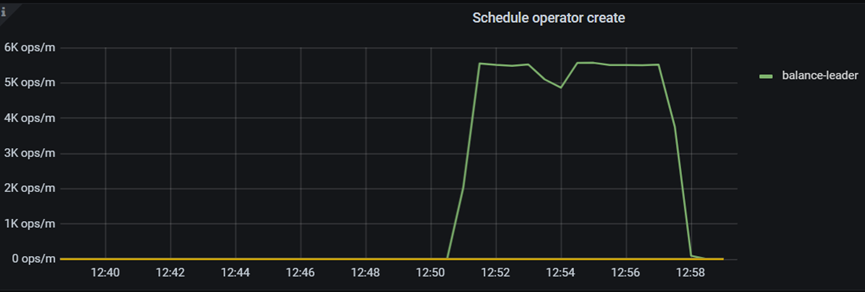
12:40 启动tikv后一直未发生调度,12:46 调整leader-schedule-limit=2仍未发生调度,12:50调整schedule-limit=1、max-waiting-operator=2后开始调度。
当max-waiting-operator=1时有大量的transfer leader请求被cancel而不能完成调度,经确认此为bug。
| [2022/05/12 12:45:38.419 +08:00] [INFO] [operator_controller.go:597] ["operator canceled"] [region-id=28977] [takes=0s] [operator="\"balance-leader {transfer leader: store 2 to 1} (kind:leader, region:28977(365, 35), createAt:2022-05-12 12:45:38.419949916 +0800 CST m=+418435.703819099, startAt:0001-01-01 00:00:00 +0000 UTC, currentStep:0, size:95, steps:[transfer leader from store 2 to store 1])\""] |
5 总结
由于早期版本中对balance-leader的operator产生速度有限制,而transfer leader操作本身比较快,造成了整体leader均衡速度较慢,通过增加balance-leader-scheduler每次调度时产生的operator数量,极大的缩短了tikv重启后leader的整体迁移速度,降低因为长时间不均衡带来的性能影响,对于大集群的快速恢复提供了保障。