
2022年5月8日,Taier 1.1版本正式发布!
本次版本更新对Flink的支持升级到Flink1.12,支持多种流类型任务,新版本的使用文档已在社区中推送,大家可以随时下载查阅。
github地址:
https://github.com/DTStack/Taier
gitee地址:
https://gitee.com/dtstack_dev_0/taier
Taier 1.1 版本介绍
Taier是一个分布式可视化的DAG任务调度系统,是数栈数据中台整体架构的重要枢纽,负责调度日常庞大的任务量。
它旨在降低ETL开发成本,提高大数据平台稳定性,让大数据开发人员可以在Taier直接进行业务逻辑的开发,而不用关心任务错综复杂的依赖关系与底层的大数据平台的架构实现,将工作的重心更多地聚焦在业务之中。
Taier1.0版本于2022年2月发布,在1.0版本发布的第二天,1.1版本的迭代就已提上日程,并于昨日正式发布。
本次版本更新,着重解决了Taier的适配性问题:对Flink的支持升级到1.12;Taier中的Spark SQL 和 Flink SQL两个组件也实现了支持用户在任务中自定义函数,明显让Taier的延展性有了更好的发挥;新增了许多例如Hive SQL类型任务、实时任务运维等强大功能。
这次版本更新对Taier的固有优势进行了巩固,同时也强化并改善了用户体验,进一步精细化提升产品性能。
Taier 1.1 功能详解
01 对Flink 版本支持升级到1.12
Taier作为一个分布式可视化的DAG任务调度系统,采用ChunJun作为分布式数据同步工具。1.1版本将Flink版本升级到1.12 ,支持ChunJun 1.12版本中新增的transformer算子等以及所有Flink原生语法及Function
02 数据同步支持脚本模式、增量同步
数据同步任务除向导模式外,1.1版本新增数据同步脚本模式。脚本模式通过json的方式配置,无需依赖datasourcex的支持的数据源,直接通过json配置的方式提交任务,脚本模式的json格式无缝兼容ChunJun的数据格式,用户可以通过脚本模式调试各类数据源的数据同步。
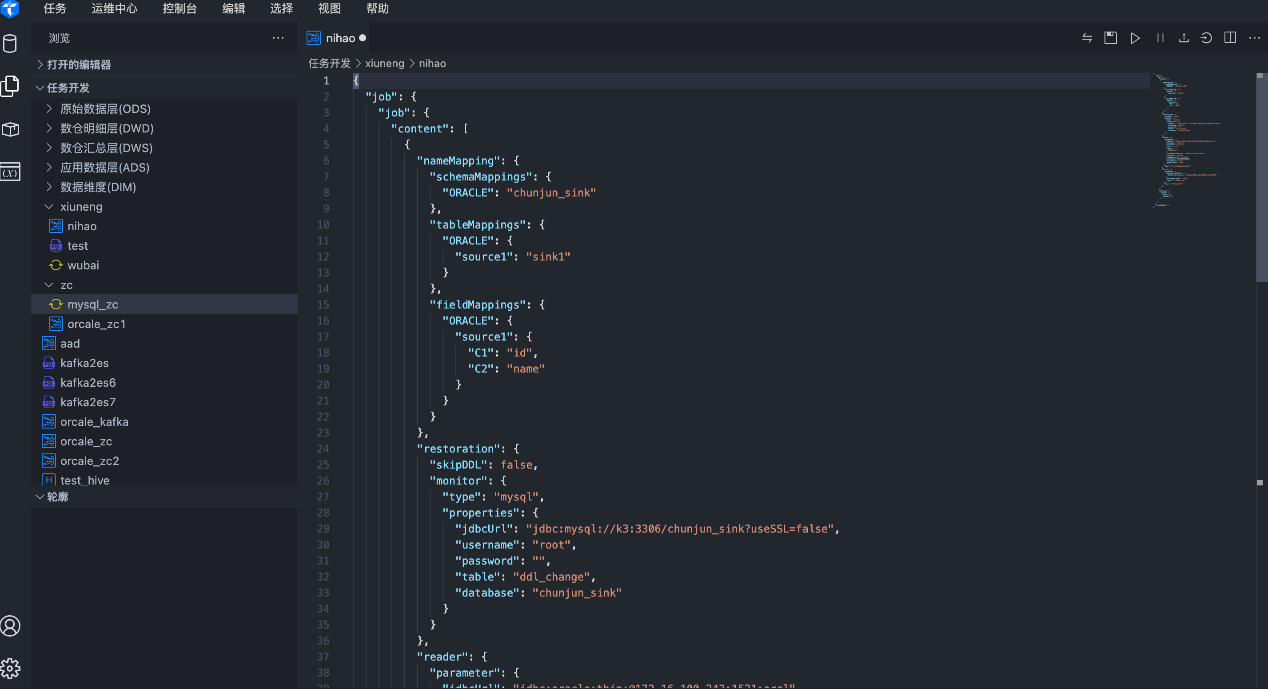
03 新增Hive SQL
Apache Hive是一个构建于Hadoop顶层的数据仓库,可以将结构化的数据文件映射为一张数据库表,并提供简单的SQL查询功能,可以将SQL语句转换为MapReduce任务进行运行。Taier1.1版本新增Hive SQL ,支持对接Hive的不同版本 。
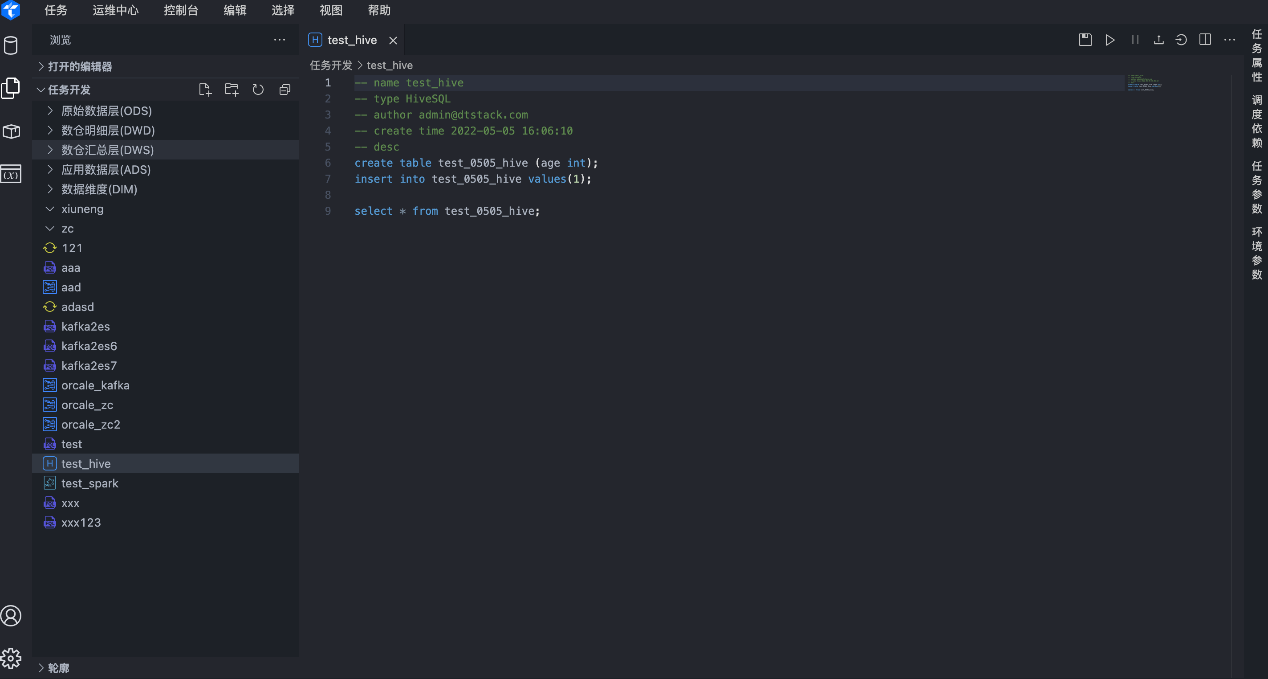
04 新增多种实时类型任务
新增实时采集任务,支持将MySQL、Oracle的数据同步至Kafka。
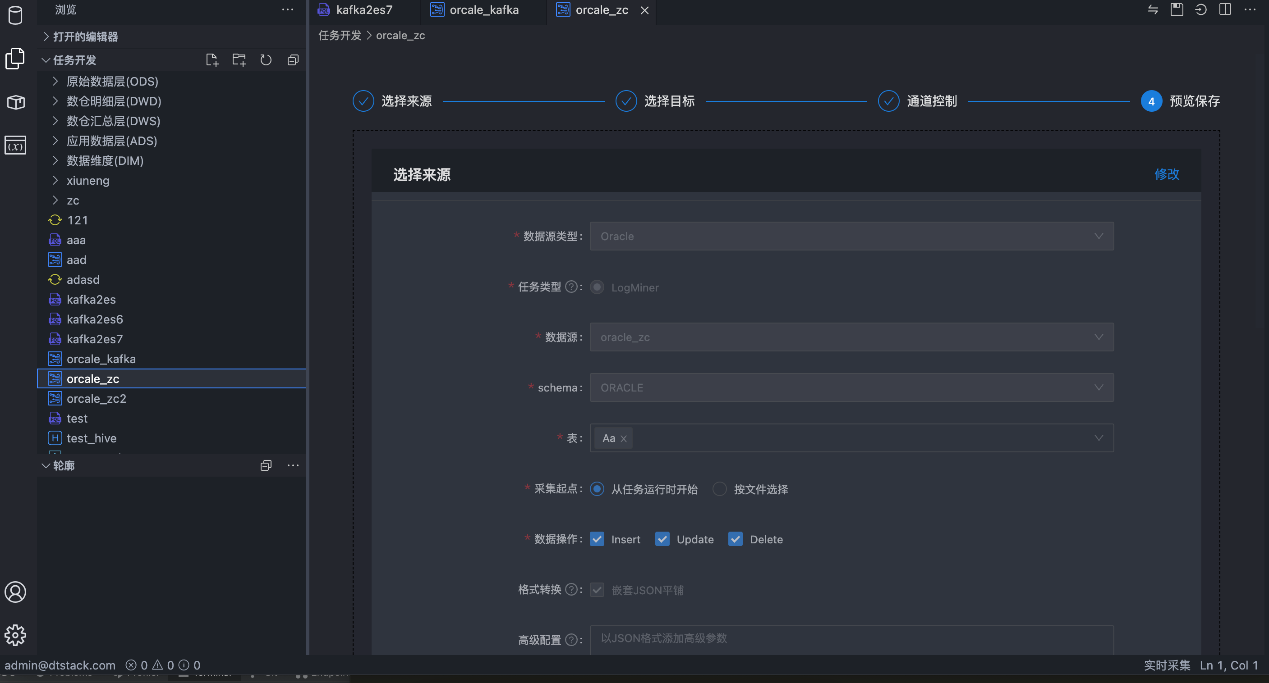
新增Flink SQL任务,通过标准SQL语义的开发帮助快速完成数据任务的配置工作。

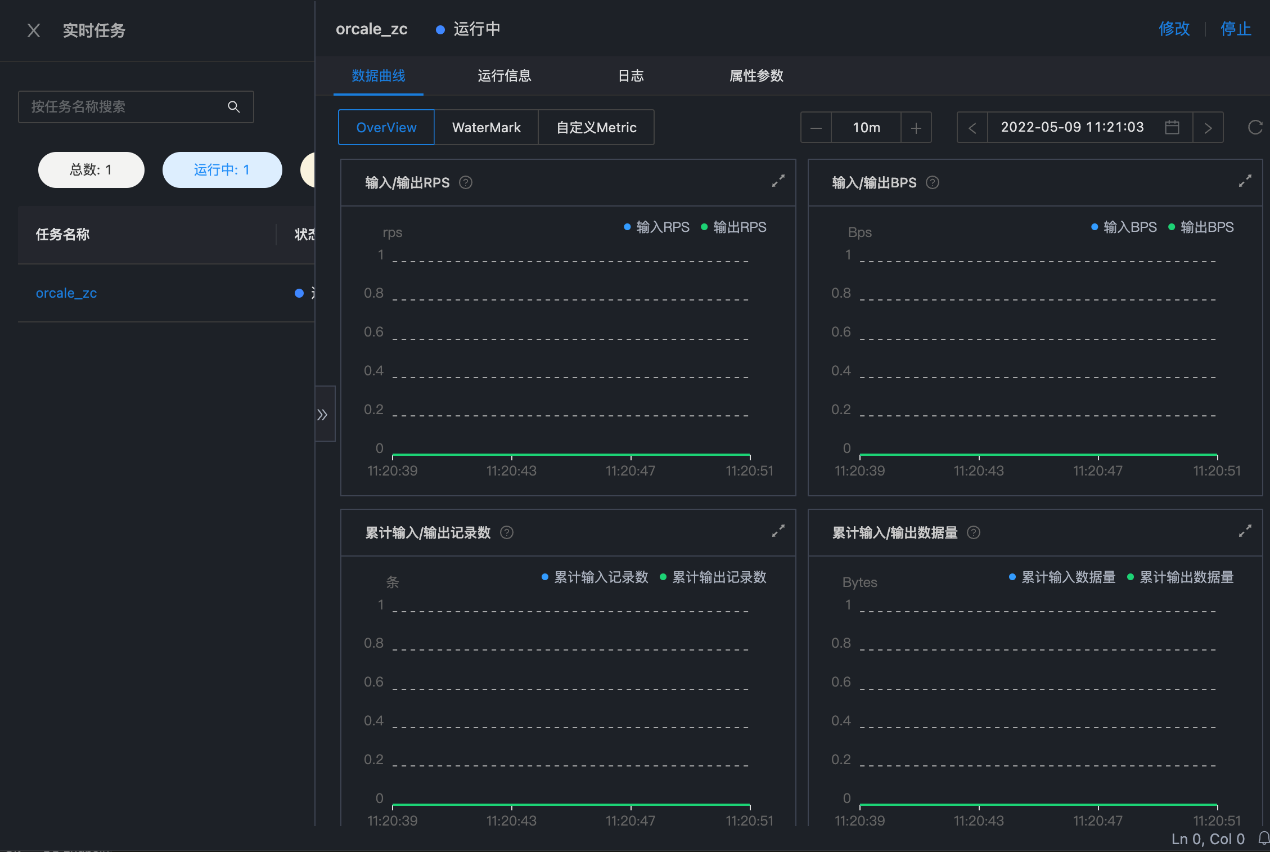
05 新增实时任务运维
可通过实时运维中心查看实时任务的相关指标信息以及任务的详细日志信息。
06 支持用户自定义函数
用户自定义函数(User Defined Function,简称 UDF),是用户除了使用系统函数外,自行创建的函数,用于满足个性化的计算需求。自定义函数在使用上与普通的系统函数类似。
目前Taier1.1版本 Spark SQL 和 Flink SQL 任务均支持自定义函数。
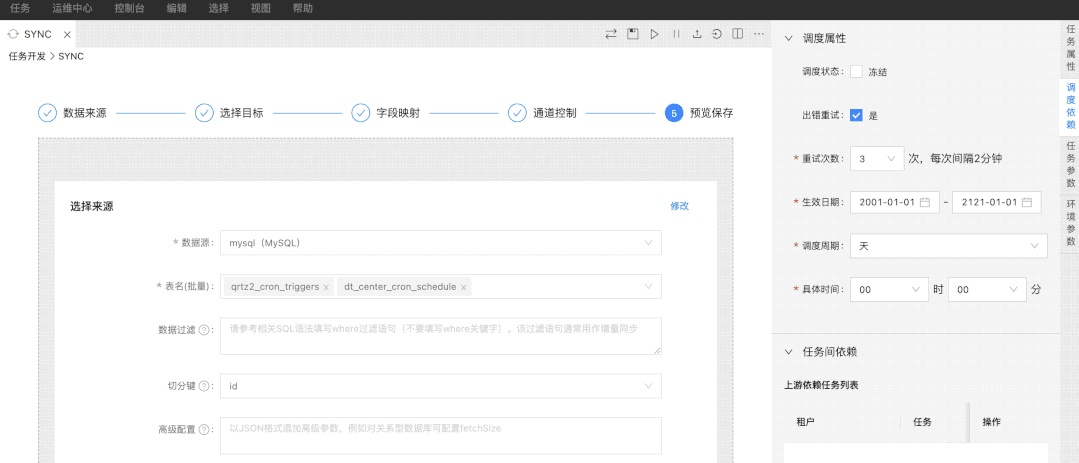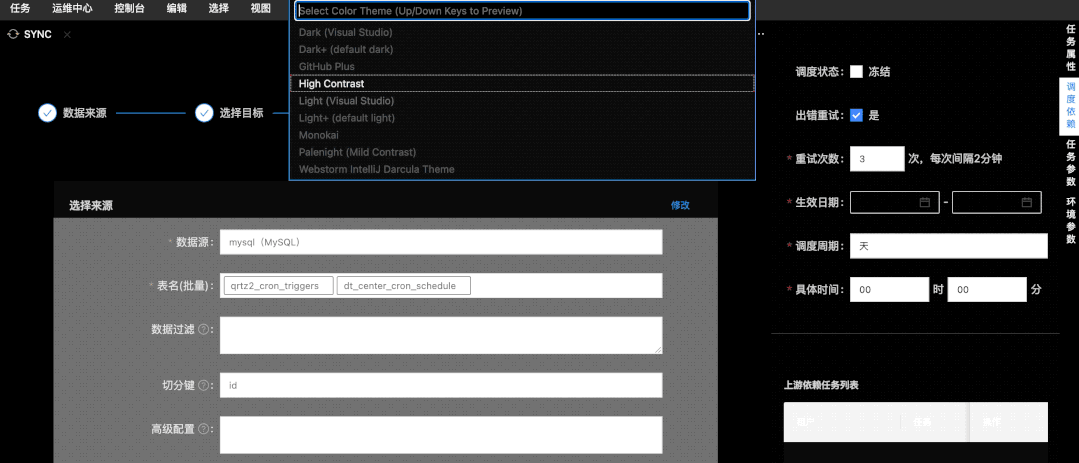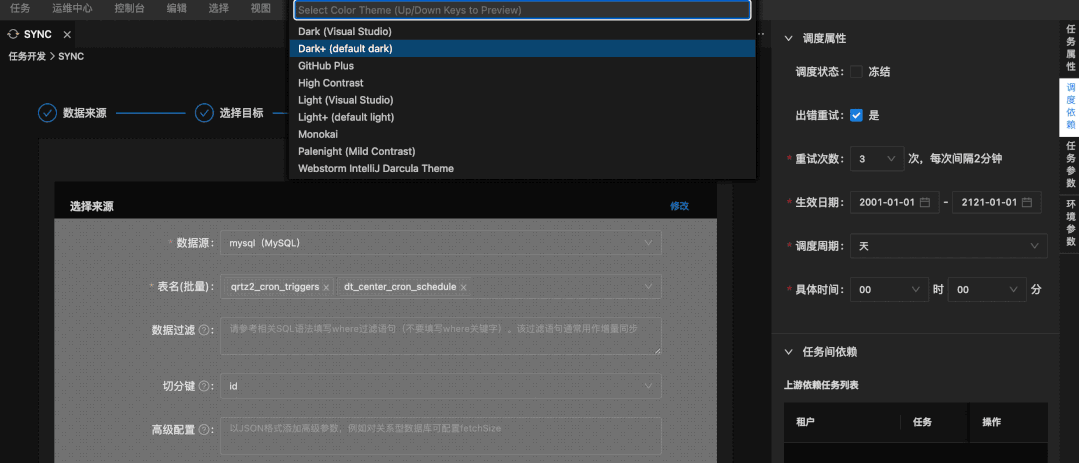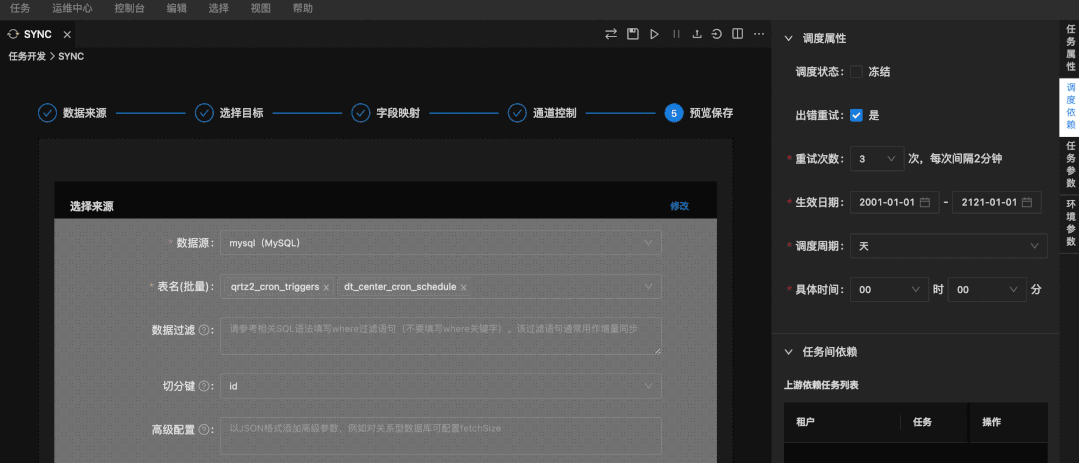
07 全新暗黑主题上线
Taier开发界面暗黑主题上线,提供多种主题切换,用户可自行选择。Taier 1.1可支持用户自由选择Dark Default 主题或 Light Default 主题等等界面风格,用户体验显著提升。
未来规划
Taier作为一个新开源的项目,我们的迭代和更新一直在进行中,后续Taier将在扩展性、用户自主性方向上继续探索扩展,比如我们正在努力让用户可以基于Taier去自定义开发自己需要的类型任务等等。
Taier的每一次进步都离不开社区开发者们的帮助和建议,希望大家保持关注,和Taier一起继续前进,不断攀登新高峰!