Cache技术实战分析
在计算机存储系统的层次结构中,介于中央处理器和主存储器之间的高速小容量存储器。与主存储器一起构成一级的存储器。高速缓冲存储器和主存储器之间信息的调度和传送是由硬件自动进行的。
某些机器甚至有二级三级缓存,每级缓存比前一级缓存速度慢且容量大。

组成结构
高速缓冲存储器是存在于主存与CPU之间的一级存储器, 由静态存储芯片(SRAM)组成,容量比较小但速度比主存高得多, 接近于CPU的速度。
主要由三大部分组成:
Cache存储体:存放由主存调入的指令与数据块。
地址转换部件:建立目录表以实现主存地址到缓存地址的转换。
替换部件:在缓存已满时按一定策略进行数据块替换,并修改地址转换部件。
参考文献链接
https://mp.weixin.qq.com/s/PddkCP_tE-TwOyXMGM2jvA
https://mp.weixin.qq.com/s/z_rQnSD8DFGIMaj2H0–gg
https://product.pconline.com.cn/itbk/diy/cpu/1107/2474321.html
cache写好代码
CACHE基础
对cache的掌握,对于Linux工程师(其他的非Linux工程师也一样)写出高效能代码,以及优化Linux系统的性能是至关重要的。简单来说,cache快,内存慢,硬盘更慢。在一个典型的现代CPU中比较接近改进的哈佛结构,cache的排布大概是这样的:
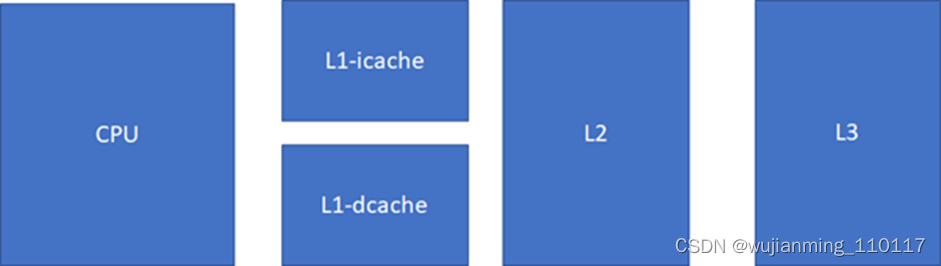
L1速度> L2速度> L3速度> RAM
L1容量< L2容量< L3容量< RAM
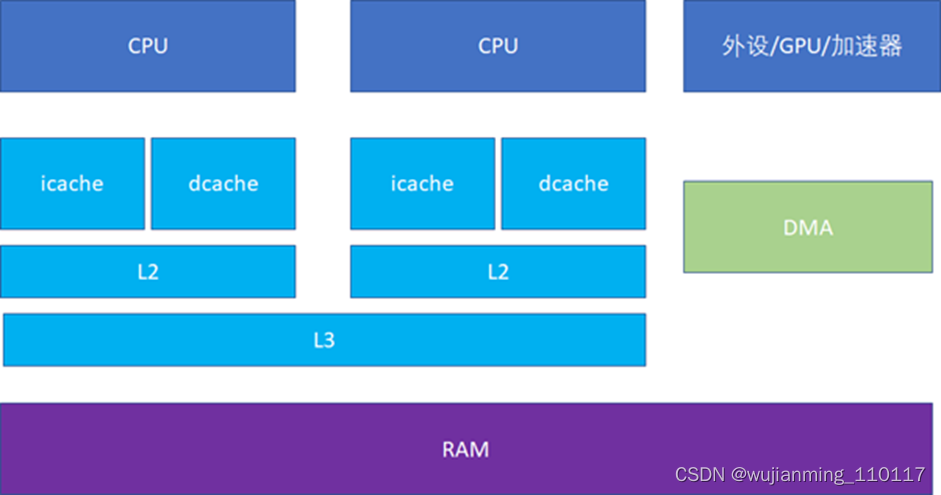
现代CPU,通常L1 cache的指令和数据是分离的。这样可以实现2条高速公路并行访问,CPU可以同时load指令和数据。当然,cache也不一定是一个core独享,现代很多CPU的典型分布是这样的,比如多个core共享一个L3。比如这台的Linux里面运行lstopo命令:

人们也常常称呼L2cache为MLC(MiddleLevel Cache),L3cache为LLC(Last LevelCache)。这些Cache究竟有多块呢?看看Intel的数据,具体配置:Intel i7-4770 (Haswell), 3.4 GHz (Turbo Boostoff), 22 nm. RAM: 32 GB (PC3-12800 cl11 cr2)
访问延迟:

数据来源:https://www.7-cpu.com/cpu/Haswell.html
应该尽可能追求cache的命中率高,以避免延迟,最好是低级cache的命中率越高越好。
CACHE的组织
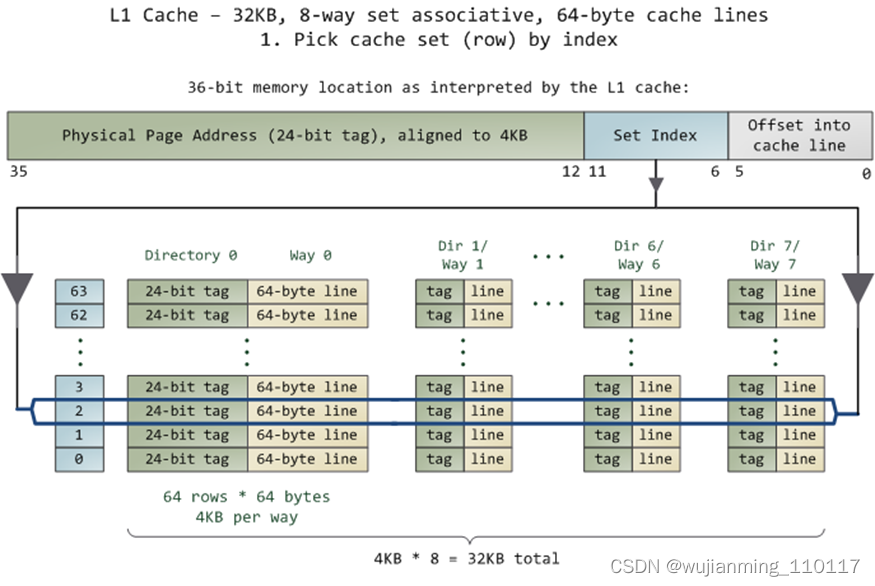
现代的cache基本按照这个模式来组织:SET、WAY、TAG、INDEX,这几个概念是理解Cache的关键。随便打开一个数据手册,就可以看到这样的字眼:

翻译成中文就是4路(way)组(set)相联,VIPT表现为(behave as)PIPT --cacheline的长度是64字节。
想象一个16KB大小的cache,假设是4路组相联,cacheline的长度是64字节。Cacheline的概念比较简单,cache的整个替换是以行为单位的,一行64个字节里面读了任何一个字节,其实整个64字节就进入了cache。
比如下面两段程序,前者的计算量是后者的8倍:

但是执行时间,远远不到后者的8倍:

16KB的cache是4way的话,每个set包括4*64B,则整个cache分为16KB/64B/4 = 64set,也即2的6次方。当CPU从cache里面读数据的时候,用地址位的BIT6-BIT11来寻址set,BIT0-BIT5是cacheline内的offset。
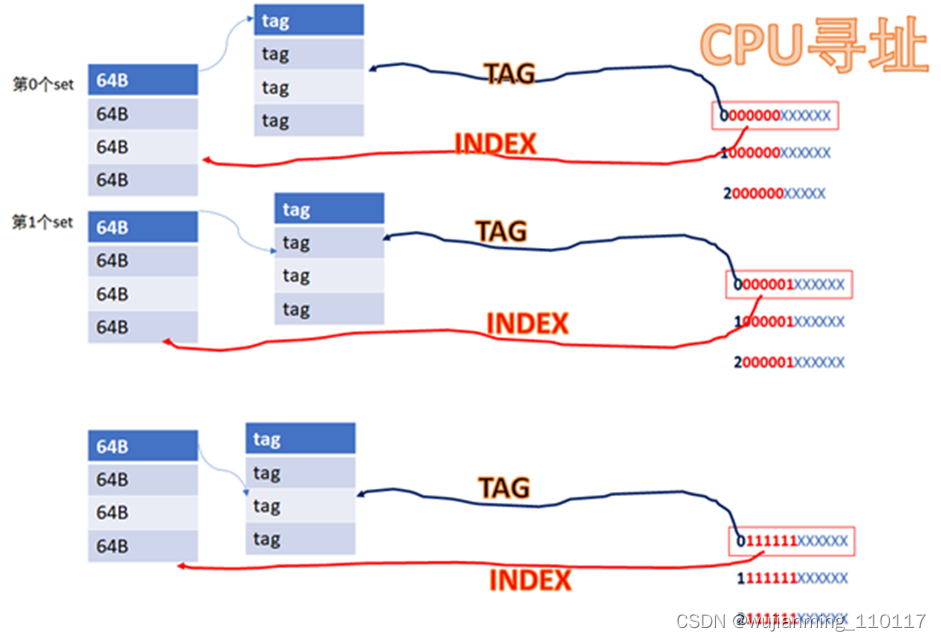
比如CPU访问地址
0 000000 XXXXXX
或者
1 000000 XXXXXX
或者
YYYY 000000 XXXXXX
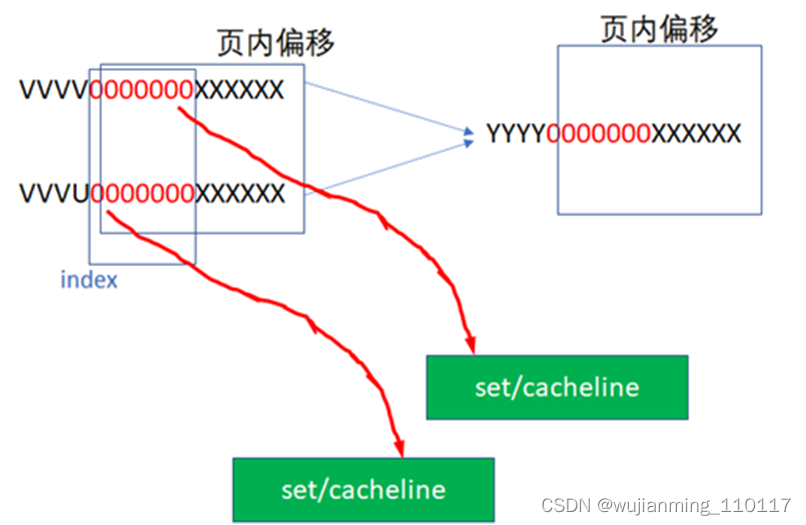
由于红色的6位都相同,所以全部都会找到第0个set的cacheline。第0个set里面有4个way,之后硬件会用地址的高位如0,1,YYYY作为tag,去检索这4个way的tag是否与地址的高位相同,而且cacheline是否有效,如果tag匹配且cacheline有效,则cache命中。
所以地址YYYYYY000000XXXXXX全部都是找第0个set,YYYYYY000001XXXXXX全部都是找第1个set,YYYYYY111111XXXXXX全部都是找第63个set。每个set中的4个way,都有可能命中。
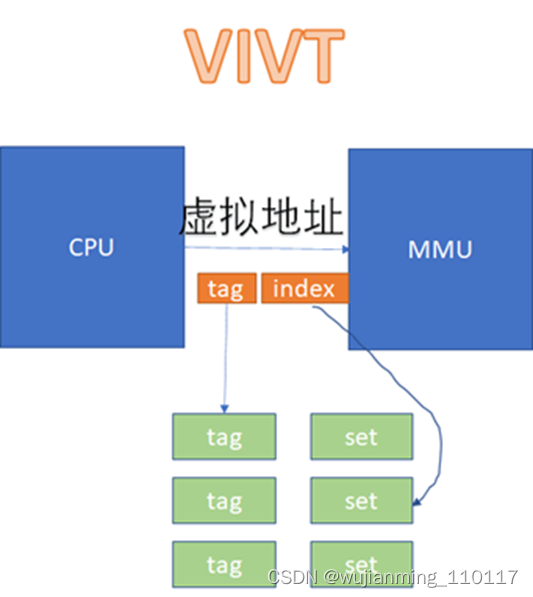
中间红色的位就是INDEX,前面YYYY这些位就是TAG。具体的实现可以是用虚拟地址或者物理地址的相应位做TAG或者INDEX。如果用虚拟地址做TAG,叫VT;如果用物理地址做TAG,叫PT;如果用虚拟地址做INDEX,叫VI;如果用物理地址做TAG,叫PT。工程中碰到的cache可能有这么些组合:
VIVT、VIPT、PIPT。
VIVT的硬件实现开销最低,但是软件维护成本高;PIPT的硬件实现开销最高,但是软件维护成本最低;VIPT介于二者之间,但是有些硬件是VIPT,但是behave as PIPT,这样对软件而言,维护成本与PIPT一样。
在VIVT的情况下,CPU发出的虚拟地址,不需要经过MMU的转化,直接就可以去查cache。
在VIPT和PIPT的场景下,都涉及到虚拟地址转换为物理地址后,再去比对cache的过程。VIPT如下:
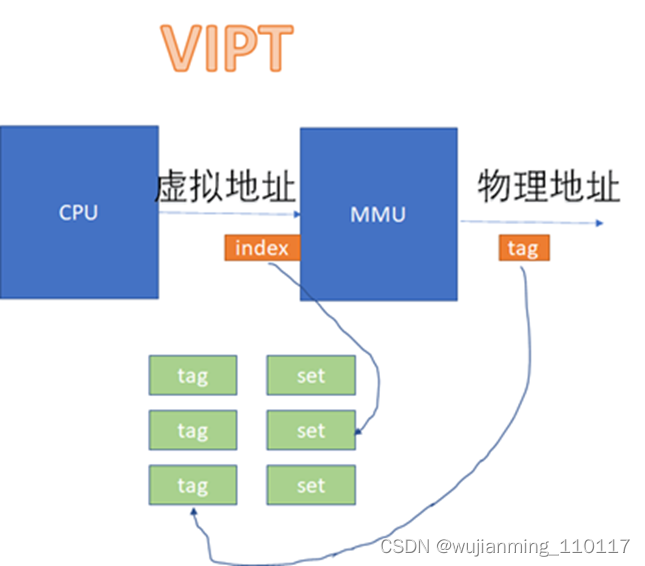
PIPT如下:
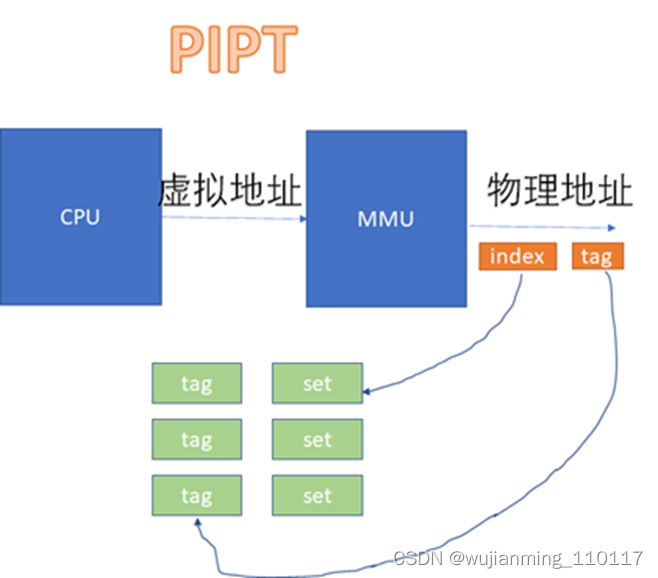
从图上看起来,VIVT的硬件实现效率很高,不需要经过MMU就可以去查cache了。不过,对软件来说,这是个灾难。因为VIVT有严重的歧义和别名问题。
歧义:一个虚拟地址先后指向两个(或者多个)物理地址
别名:两个(或者多个)虚拟地址同时指向一个物理地址
这里重点看别名问题。比如2个虚拟地址对应同一个物理地址,基于VIVT的逻辑,无论是INDEX还是TAG,2个虚拟地址都是可能不一样的(尽管物理地址一样,但是物理地址在cache比对中完全不掺和),这样完全可能在2个cacheline同时命中。
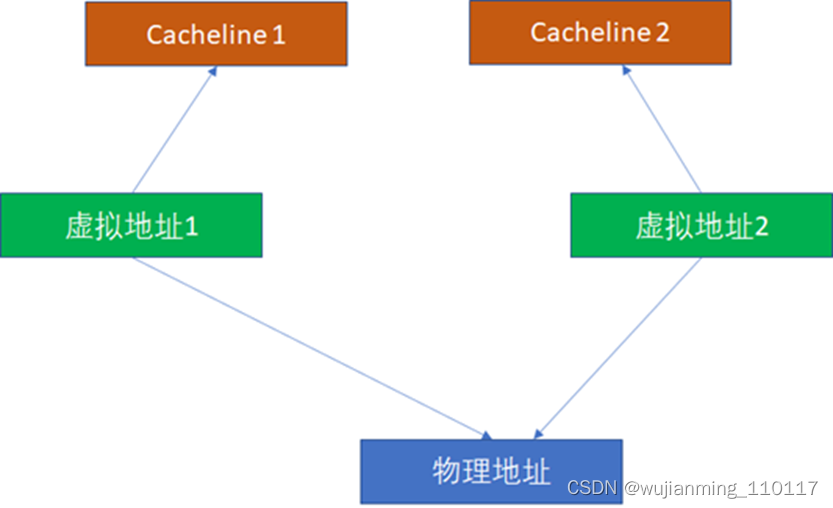
由于2个虚拟地址指向1个物理地址,这样CPU写过第一个虚拟地址后,写入cacheline1。CPU读第2个虚拟地址,读到的是过时的cacheline2,这样就出现了不一致。所以,为了避免这种情况,软件必须写完虚拟地址1后,对虚拟地址1对应的cache执行clean,对虚拟地址2对应的cache执行invalidate。
而PIPT完全没有这样的问题,因为无论多少虚拟地址对应一个物理地址,由于物理地址一样,是基于物理地址去寻找和比对cache的,所以不可能出现这种别名问题。
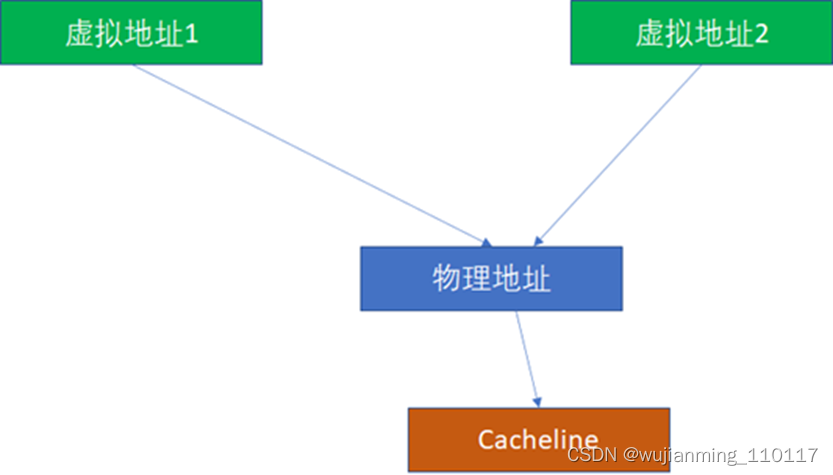
那么VIPT有没有可能出现别名呢?答案是有可能,也有可能不能。如果VI恰好对于PI,就不可能,这个时候,VIPT对软件而言就是PIPT了:
VI=PI
PT=PT
那么什么时候VI会等于PI呢?这个时候来回忆下虚拟地址往物理地址的转换过程,以页为单位的。假设一页是4K,那么地址的低12位虚拟地址和物理地址是完全一样的。回忆前面的地址:
YYYYY000000XXXXXX
其中红色的000000是INDEX。在例子中,红色的6位和后面的XXXXXX(cache内部偏移)加起来正好12位,所以这个000000经过虚实转换后,其实还是000000的,这个时候VI=PI,VIPT没有别名问题。
原先假设的cache是:16KB大小的cache,假设是4路组相联,cacheline的长度是64字节,这样正好需要红色的6位来作为INDEX。但是如果把cache的大小增加为32KB,这样需要 32KB/4/64B=128=2^7,也即7位来做INDEX。
YYYY0000000XXXXXX
这样VI就可能不等于PI了,因为红色的最高位超过了2^12的范围,完全可能出现如下2个虚拟地址,指向同一个物理地址:
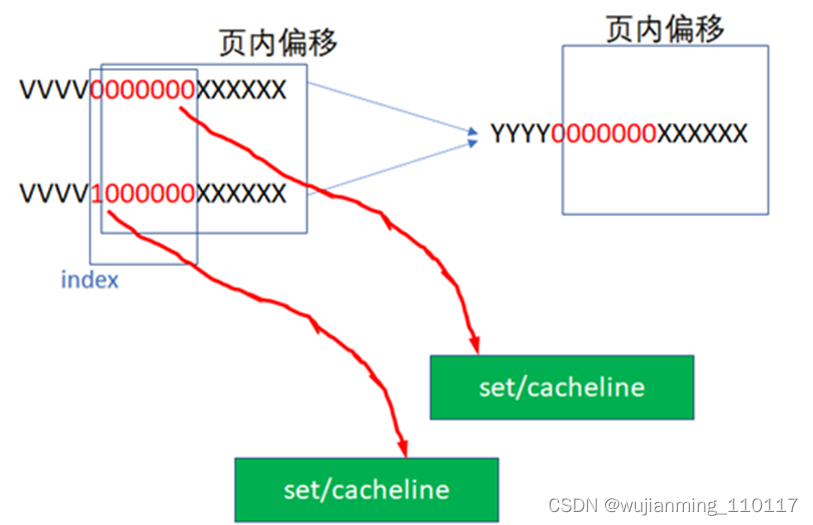
这样就出现了别名问题,在工程里,可能可以通过一些办法避免这种别名问题,比如软件在建立虚实转换的时候,把虚实转换往213而不是212对齐,让物理地址的低13位而不是低12位与物理地址相同,这样强行绕开别名问题,下图中,2个虚拟地址指向了同一个物理地址,但是INDEX是相同的,这样VI=PI,就绕开了别名问题。这通常是PAGE COLOURING技术中的一种技巧。
如果这种PAGE COLOURING的限制对软件仍然不可接受,而又想享受VIPT的INDEX不需要经过MMU虚实转换的快捷?有没有什么硬件技术来解决VIPT别名问题呢?确实是存在的,现代CPU很多都是把L1 CACHE做成VIPT,但是表现地(behave as)像PIPT。这是怎么做到的呢?
这要求VIPT的cache,硬件上具备alias detection的能力。比如,硬件知道YYYY0000000XXXXXX既有可能出现在第0000000,又可能出现在1000000这2个set,然后硬件自动去比对这2个set里面是否出现映射到相同物理地址的cacheline,并从硬件上解决好别名同步,那么软件就完全不用操心了。
下面记住一个简单的规则:
对于VIPT,如果cache的size除以WAY数,小于等于1个page的大小,则天然VI=PI,无别名问题;
对于VIPT,如果cache的size除以WAY数,大于1个page的大小,则天然VI≠PI,有别名问题;这个时候又分成2种情况:
• 硬件不具备alias detection能力,软件需要pagecolouring;
• 硬件具备alias detection能力,软件把cache当成PIPT用。
比如cache大小64KB,4WAY,PAGE SIZE是4K,显然有别名问题;这个时候,如果cache改为16WAY,或者PAGE SIZE改为16K,不再有别名问题。为什么?感觉小学数学知识也能算得清。
CACHE的一致性
Cache的一致性有这么几个层面
-
一个CPU的icache和dcache的同步问题 -
多个CPU各自的cache同步问题 -
CPU与设备(其实也可能是个异构处理器,不过在Linux运行的CPU眼里,都是设备,都是DMA)的cache同步问题
先看一下ICACHE和DCACHE同步问题。由于程序的运行而言,指令流的都流过icache,而指令中涉及到的数据流经过dcache。所以对于自修改的代码(Self-Modifying Code)而言,比如修改了内存p这个位置的代码(典型多见于JIT compiler),这个时候是通过store的方式去写的p,所以新的指令会进入dcache。但是接下来去执行p位置的指令的时候,icache里面可能命中的是修改之前的指令。
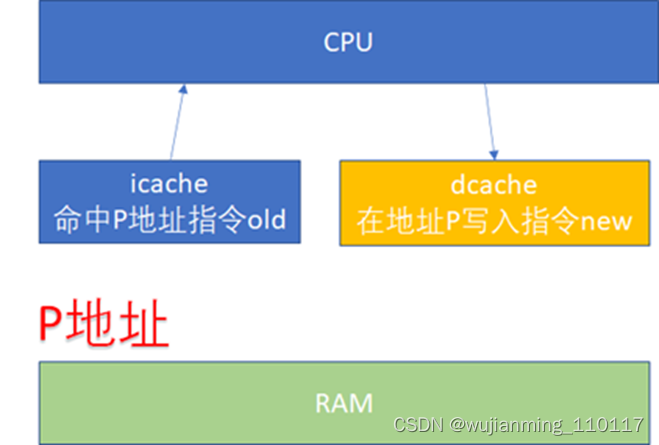
所以这个时候软件需要把dcache的东西clean出去,然后让icache invalidate,这个开销显然还是比较大的。
但是,比如ARM64的N1处理器,支持硬件的icache同步,详见文档:The Arm Neoverse N1 Platform: Building Blocks for the Next-Gen Cloud-to-Edge Infrastructure SoC

特别注意画红色的几行。软件维护的成本实际很高,还涉及到icache的invalidation向所有核广播的动作。
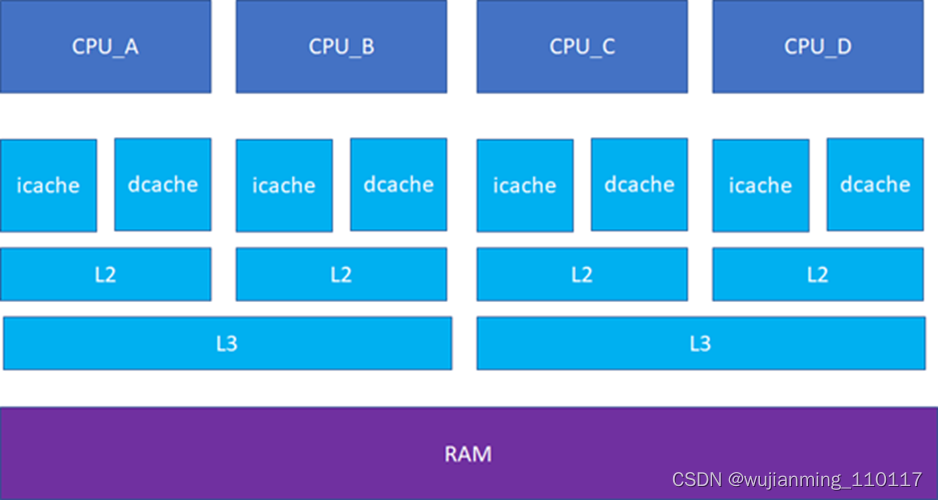
接下来的一个问题就是多个核之间的cache同步。下面是一个简化版的处理器,CPU_A和B共享了一个L3,CPU_C和CPU_D共享了一个L3。实际的硬件架构由于涉及到NUMA,会比这个更加复杂,但是这个图反映层级关系是足够了。
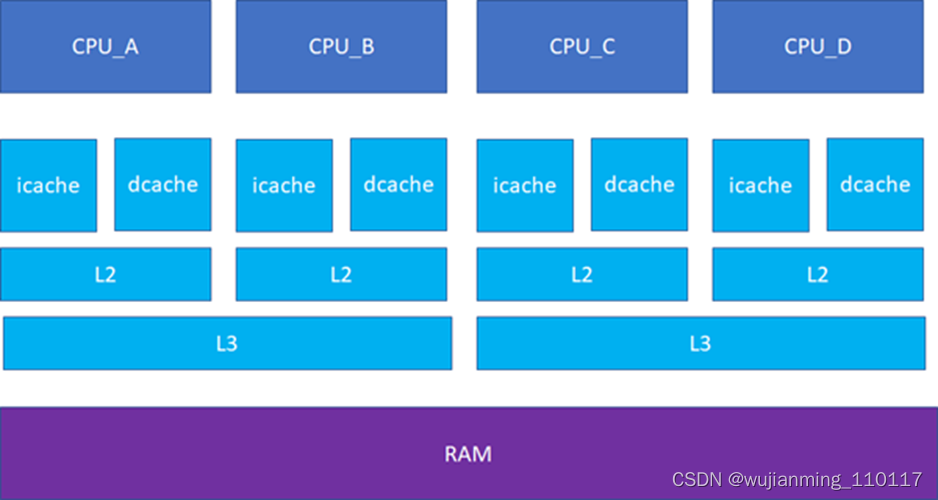
比如CPU_A读了一个地址p的变量?CPU_B、C、D又读,难道B,C,D又必须从RAM里面经过L3,L2,L1再读一遍吗?这个显然是没有必要的,在硬件上,cache的snooping控制单元,可以协助直接把CPU_A的p地址cache拷贝到CPU_B、C和D的cache。
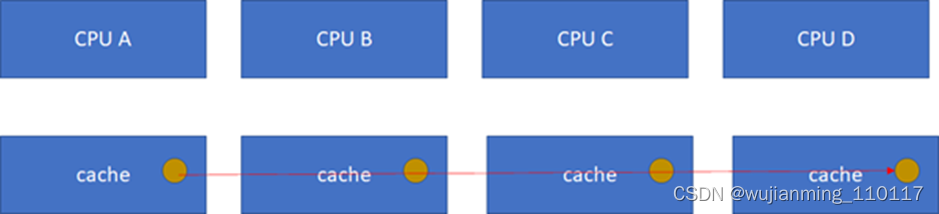
这样A-B-C-D都得到了相同的p地址的棕色小球。
假设CPU B这个时候,把棕色小球写成红色,而其他CPU里面还是棕色,这样就会不一致了:
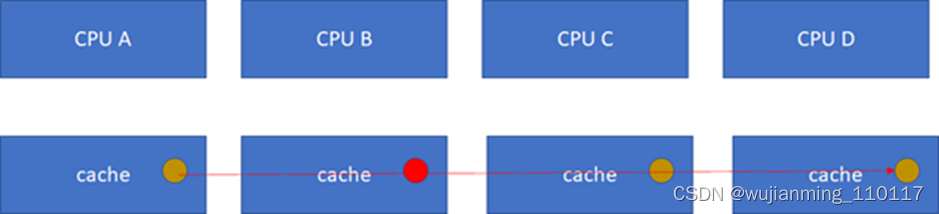
这个时候怎么办?这里面显然需要一个协议,典型的多核cache同步协议有MESI和MOESI。MOESI相对MESI有些细微的差异,不影响对全局的理解。下面重点看MESI协议。
MESI协议定义了4种状态:
M(Modified): 当前cache的内容有效,数据已被修改而且与内存中的数据不一致,数据只在当前cache里存在;类似RAM里面是棕色球,B里面是红色球(CACHE与RAM不一致),A、C、D都没有球。
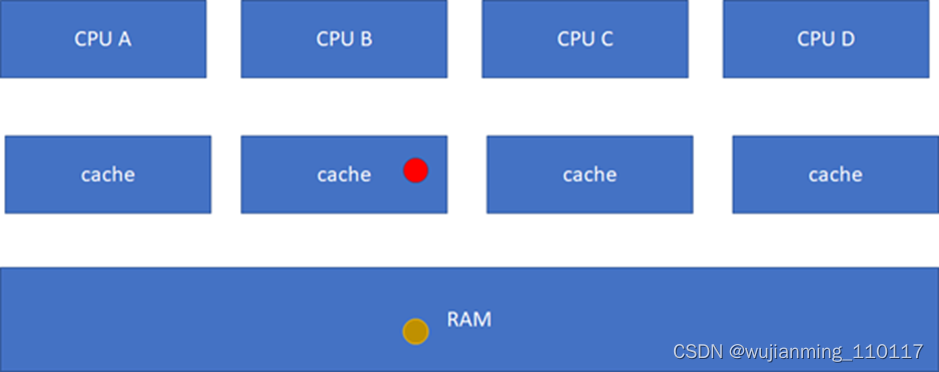
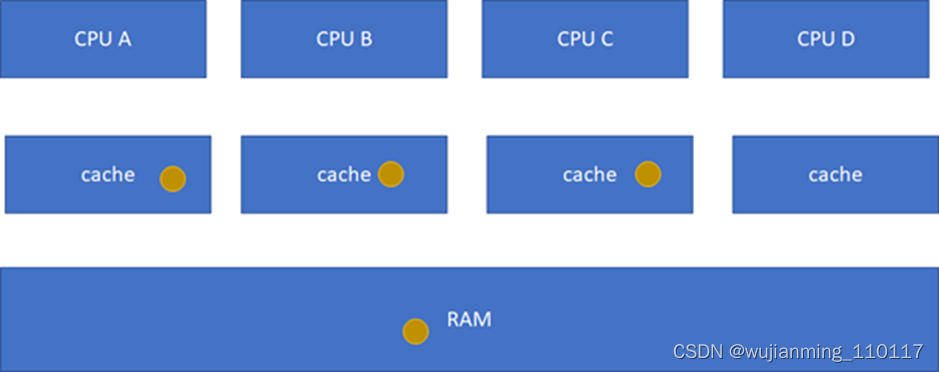
E(Exclusive):当前cache的内容有效,数据与内存中的数据一致,数据只在当前cache里存在;类似RAM里面是棕色球,B里面是棕色球(RAM和CACHE一致),A、C、D都没有球。
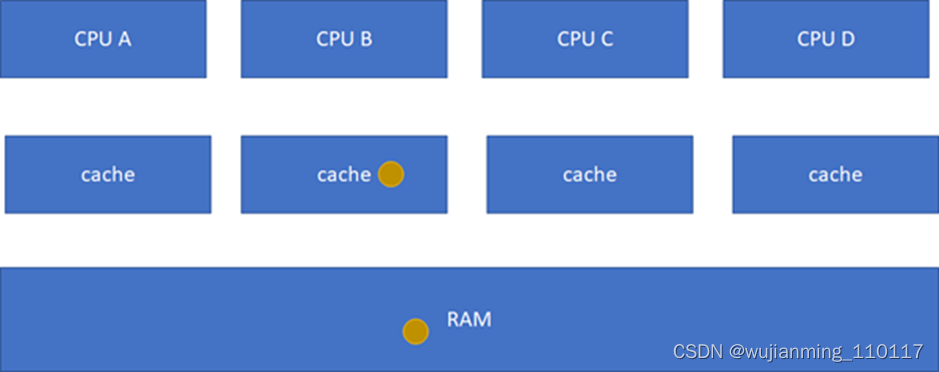
S(Shared):当前cache的内容有效,数据与内存中的数据一致,数据在多个cache里存在。类似如下图,在CPU A-B-C里面cache的棕色球都与RAM一致。
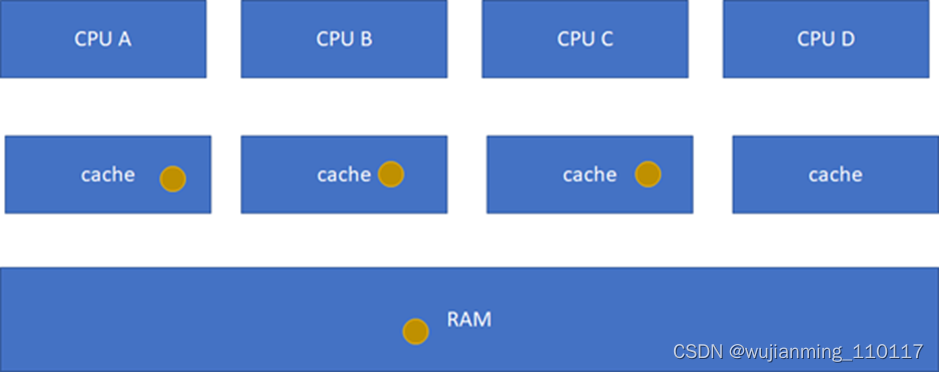
I(Invalid): 当前cache无效。前面三幅图里面cache没有球的那些都是属于这个情况。
然后有个状态机
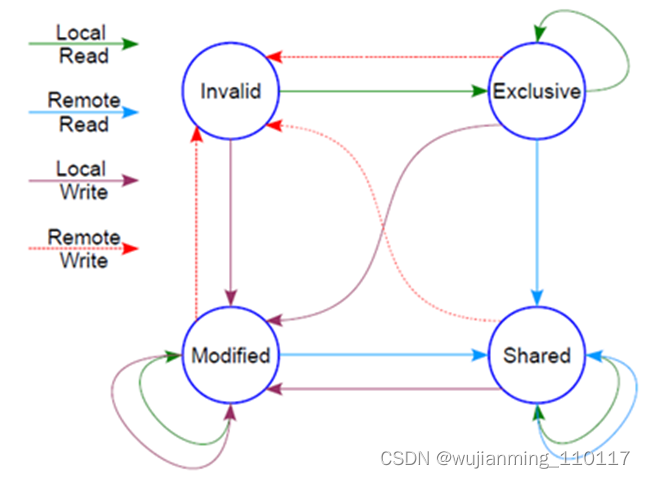
这个状态机比较难记,死记硬背是记不住的,也没必要记,讲的cache原先的状态,经过一个硬件在本cache或者其他cache的读写操作后,各个cache的状态会如何变迁。所以,硬件上不仅仅是监控本CPU的cache读写行为,还会监控其他CPU的。只需要记住一点:这个状态机是为了保证多核之间cache的一致性,比如一个干净的数据,可以在多个CPU的cache share,这个没有一致性问题;但是,假设其中一个CPU写过了,比如A-B-C本来是这样:
然后B被写过了:
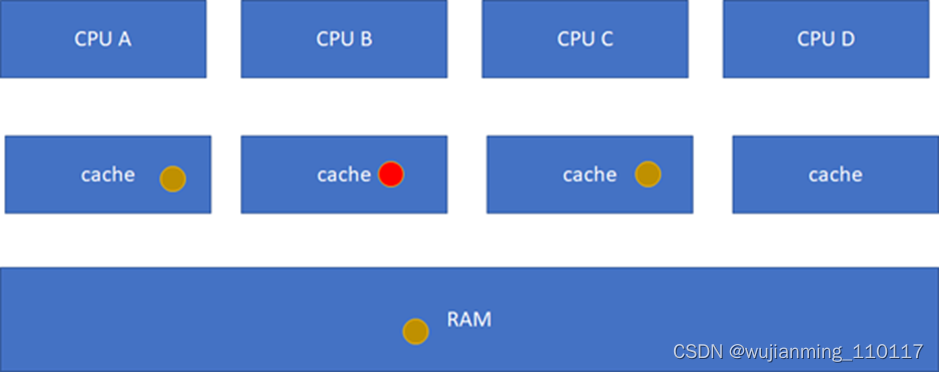
这样A、C的cache实际是过时的数据,这是不允许的。这个时候,硬件会自动把A、C的cache invalidate掉,不需要软件的干预,A、C其实变地相当于不命中这个球了:
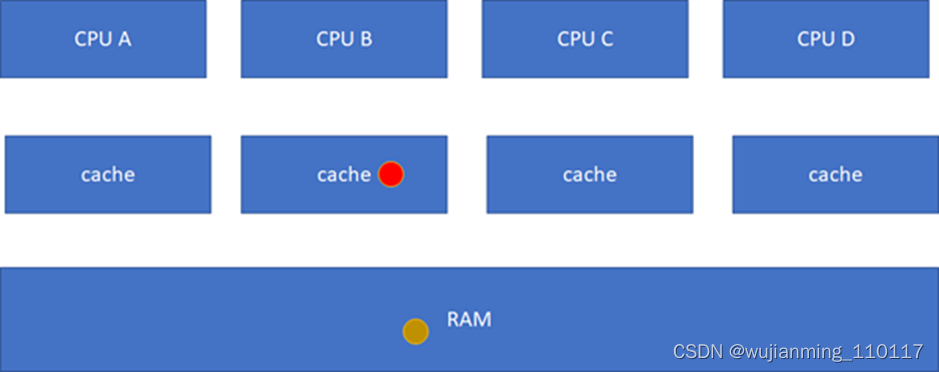
这个时候,可能会继续问,如果C要读这个球呢?目前的状态在B里面是modified的,而且与RAM不一致,这个时候,硬件会把红球clean,然后B、C、RAM变地一致,B、C的状态都变化为S(Shared):
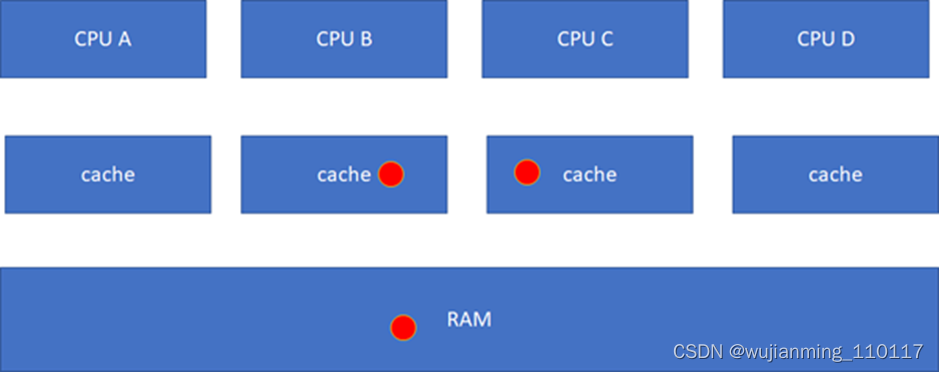
这一系列的动作虽然由硬件完成,但是对软件而言不是免费的,因为耗费了时间。如果编程的时候不注意,引起了硬件的大量cache同步行为,则程序的效率可能会急剧下降。
为了让大家直观感受到这个cache同步的开销,下面写一个程序,这个程序有2个线程,一个写变量,一个读变量:

这个程序里,x和y都是cacheline对齐的,这个程序的thread1的写,会不停地与thread2的读,进行cache同步。
执行时间为:
$ time ./a.out real 0m3.614suser 0m7.021ssys 0m0.004s
在2个CPU上的userspace共运行了7.021秒,累计这个程序从开始到结束的对应真实世界的时间是3.614秒(就是从命令开始到命令结束的时间)。
如果把程序改一句话,把thread2里面的c = x改为c = y,这样2个线程在2个CPU运行的时候,读写的是不同的cacheline,就没有这个硬件的cache同步开销了:
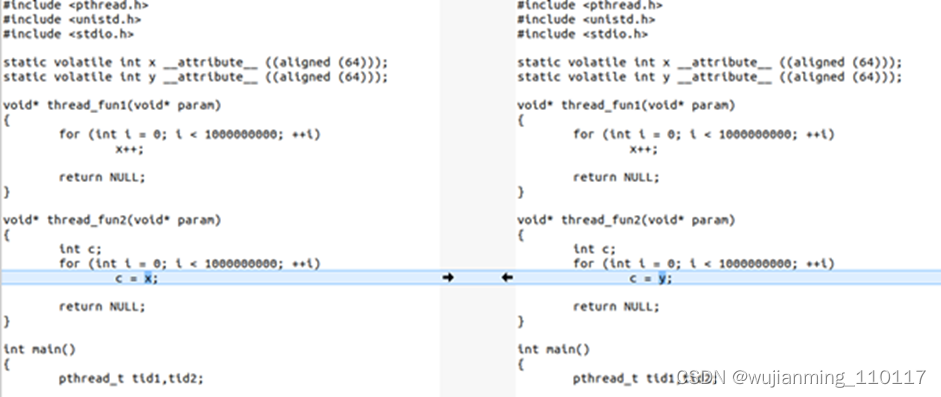
运行时间:
$ time ./b.out real 0m1.820suser 0m3.606ssys 0m0.008s
现在只需要1.8秒,几乎减小了一半。
感觉前面那个a.out,双核的帮助甚至都不大。如果改为单核跑呢?
$ time taskset -c 0 ./a.out real 0m3.299suser 0m3.297ssys 0m0.000s
单核跑,居然只需要3.299秒跑完,而双核跑,需要3.614s跑完。单核跑完这个程序,甚至比双核还快!因为单核里面没有cache同步的开销。
下一个cache同步的重大问题,就是设备与CPU之间。如果设备感知不到CPU的cache的话(下图中的红色数据流向不经过cache),这样,做DMA前后,CPU就需要进行相关的cacheclean和invalidate的动作,软件的开销会比较大。
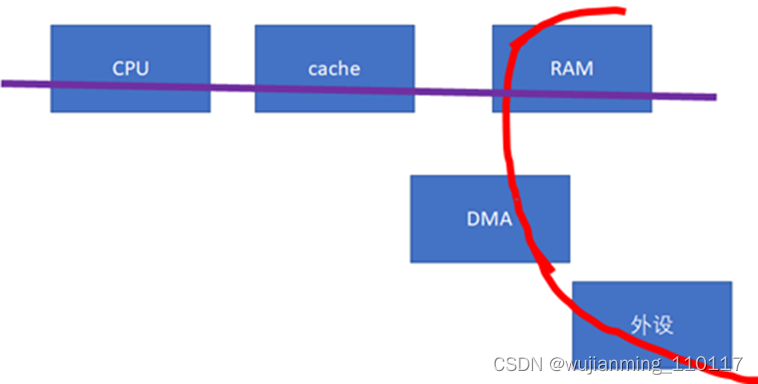
这些软件的动作,若在Linux编程的时候,使用的是streaming DMA APIs的话,都会被类似这样的API自动搞定:
dma_map_single()dma_unmap_single()dma_sync_single_for_cpu()dma_sync_single_for_device()dma_sync_sg_for_cpu()dma_sync_sg_for_device()
如果是使用的dma_alloc_coherent() API呢,则设备和CPU之间的buffer是cache一致的,不需要每次DMA进行同步。对于不支持硬件cache一致性的设备而言,很可能dma_alloc_coherent()会把CPU对那段DMA buffer的访问设置为uncachable的。
这些API把底层的硬件差异封装掉了,如果硬件不支持CPU和设备的cache同步的话,延时还是比较大的。那么,对于底层硬件而言,更好的实现方式,应该仍然是硬件帮来搞定。比如需要修改总线协议,延伸红线的触角:
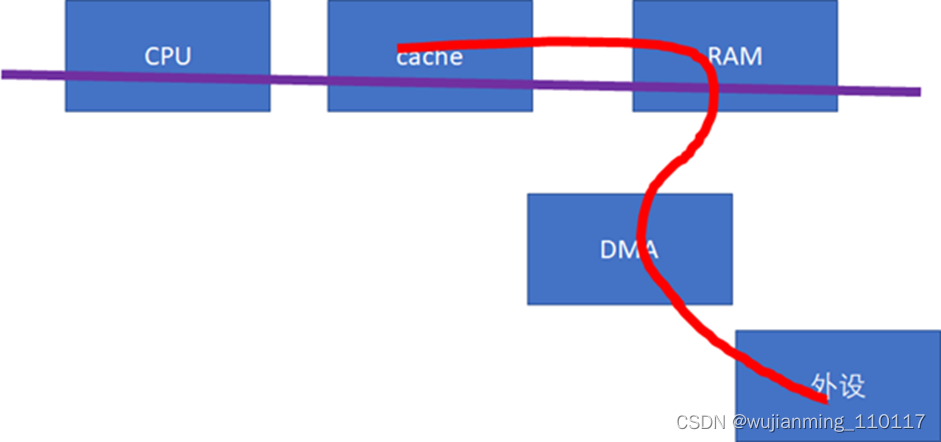
当设备访问RAM的时候,可以去snoop CPU的cache:
如果做内存到外设的DMA,则直接从CPU的cache取modified的数据;
如果做外设到内存的DMA,则直接把CPU的cache invalidate掉。
这样,就实现硬件意义上的cache同步。当然,硬件的cache同步,还有一些其他方法,原理上是类似的。注意,这种同步仍然不是免费的,仍然会消耗bus cycles的。实际上,cache的同步开销还与距离相关,可以说距离越远,同步开销越大,比如下图中A、B的同步开销比A、C小。
对于一个NUMA服务器而言,跨NUMA的cache同步开销显然是要比NUMA内的同步开销大。
意识到CACHE的编程
通过上一节的代码,读者应该意识到了cache的问题不处理好,程序的运行性能会急剧下降。所以意识到cache的编程,对程序员是至关重要的。
cache 访问延迟原理
CPU 的 cache 往往是分多级的金字塔模型,L1 最靠近 CPU,访问延迟最小,但 cache 的容量也最小。本文介绍如何测试多级 cache 的访存延迟,以及背后蕴含的计算机原理。
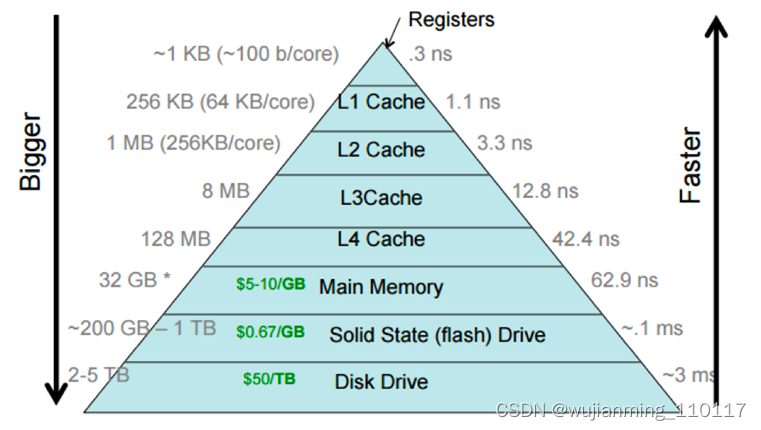
图源:https://cs.brown.edu/courses/csci1310/2020/assign/labs/lab4.html
Cache Latency
Wikichip[1] 提供了不同 CPU 型号的 cache 延迟,单位一般为 cycle,通过简单的运算,转换为 ns。以 skylake 为例,CPU 各级 cache 延迟的基准值为:
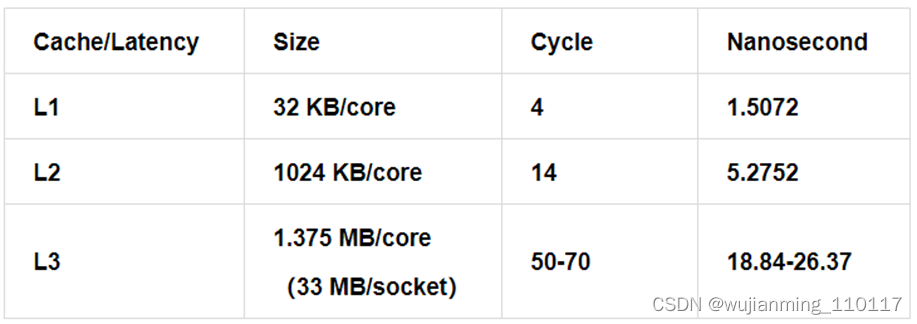
CPU Frequency:2654MHz (0.3768 nanosec/clock)
设计实验

- naive thinking
申请一个 buffer,buffer size 为 cache 对应的大小,第一次遍历进行预热,将数据全部加载到 cache 中。第二次遍历统计耗时,计算每次 read 的延迟平均值。代码实现 mem-lat.c 如下:
#include <sys/types.h>#include <stdlib.h>#include <stdio.h>#include <sys/mman.h>#include <sys/time.h>#include <unistd.h>
#define ONE p = (char *)p;#define FIVE ONE ONE ONE ONE ONE#define TEN FIVE FIVE#define FIFTY TEN TEN TEN TEN TEN#define HUNDRED FIFTY FIFTY
static void usage(){ printf(“Usage: ./mem-lat -b xxx -n xxx -s xxx\n”); printf(" -b buffer size in KB\n"); printf(" -n number of read\n\n"); printf(" -s stride skipped before the next access\n\n"); printf(“Please don’t use non-decimal based number\n”);}
int main(int argc, char argv[]){ unsigned long i, j, size, tmp; unsigned long memsize = 0x800000; / 1/4 LLC size of skylake, 1/5 of broadwell / unsigned long count = 1048576; / memsize / 64 * 8 / unsigned int stride = 64; / skipped amount of memory before the next access */ unsigned long sec, usec; struct timeval tv1, tv2; struct timezone tz; unsigned int *indices;
while (argc-- > 0) { if ((argv)[0] == ‘-’) { / look at first char of next */ switch ((argv)[1]) { / look at second */ case ‘b’: argv++; argc–; memsize = atoi(*argv) * 1024; break;
case ‘n’: argv++; argc–; count = atoi(*argv); break;
case ‘s’: argv++; argc–; stride = atoi(*argv); break;
default: usage(); exit(1); break; } } argv++; }
char* mem = mmap(NULL, memsize, PROT_READ | PROT_WRITE, MAP_PRIVATE | MAP_ANON, -1, 0); // trick3: init pointer chasing, per stride=8 byte size = memsize / stride; indices = malloc(size * sizeof(int));
for (i = 0; i < size; i++) indices[i] = i; // trick 2: fill mem with pointer references for (i = 0; i < size - 1; i++) *(char **)&mem[indices[i]stride]= (char)&mem[indices[i+1]*stride]; *(char **)&mem[indices[size-1]stride]= (char)&mem[indices[0]stride];
char **p = (char ) mem; tmp = count / 100;
gettimeofday (&tv1, &tz); for (i = 0; i < tmp; ++i) { HUNDRED; //trick 1 } gettimeofday (&tv2, &tz); if (tv2.tv_usec < tv1.tv_usec) { usec = 1000000 + tv2.tv_usec - tv1.tv_usec; sec = tv2.tv_sec - tv1.tv_sec - 1; } else { usec = tv2.tv_usec - tv1.tv_usec; sec = tv2.tv_sec - tv1.tv_sec; }
printf(“Buffer size: %ld KB, stride %d, time %d.%06d s, latency %.2f ns\n”, memsize/1024, stride, sec, usec, (sec * 1000000 + usec) * 1000.0 / (tmp 100)); munmap(mem, memsize); free(indices);}
这里用到了 3 个小技巧:
• HUNDRED 宏:通过宏展开,尽可能避免其他指令对访存的干扰。
• 二级指针:通过二级指针将buffer串起来,避免访存时计算偏移。
• char 和 char 为 8 字节,因此,stride 为 8。
测试方法:
#set -x
work=./mem-latbuffer_size=1stride=8
for i in seq 1 15; do taskset -ac 0 $work -b $buffer_size -s s t r i d e b u f f e r s i z e = stride buffer_size= stridebuffersize=(($buffer_size2))done
测试结果如下:
//L1Buffer size: 1 KB, stride 8, time 0.003921 s, latency 3.74 nsBuffer size: 2 KB, stride 8, time 0.003928 s, latency 3.75 nsBuffer size: 4 KB, stride 8, time 0.003935 s, latency 3.75 nsBuffer size: 8 KB, stride 8, time 0.003926 s, latency 3.74 nsBuffer size: 16 KB, stride 8, time 0.003942 s, latency 3.76 nsBuffer size: 32 KB, stride 8, time 0.003963 s, latency 3.78 ns//L2Buffer size: 64 KB, stride 8, time 0.004043 s, latency 3.86 nsBuffer size: 128 KB, stride 8, time 0.004054 s, latency 3.87 nsBuffer size: 256 KB, stride 8, time 0.004051 s, latency 3.86 nsBuffer size: 512 KB, stride 8, time 0.004049 s, latency 3.86 nsBuffer size: 1024 KB, stride 8, time 0.004110 s, latency 3.92 ns//L3Buffer size: 2048 KB, stride 8, time 0.004126 s, latency 3.94 nsBuffer size: 4096 KB, stride 8, time 0.004161 s, latency 3.97 nsBuffer size: 8192 KB, stride 8, time 0.004313 s, latency 4.11 nsBuffer size: 16384 KB, stride 8, time 0.004272 s, latency 4.07 ns
相比基准值,L1 延迟偏大,L2 和 L3 延迟偏小,不符合预期。
2. thinking with hardware: cache line
现代处理器,内存以 cache line 为粒度,组织在 cache 中。访存的读写粒度都是一个 cache line,最常见的缓存线大小是 64 字节。
如果简单的以 8 字节为粒度,顺序读取 128KB 的 buffer,假设数据命中的是 L2,那么数据就会被缓存到 L1,一个 cache line 其他的访存操作都只会命中 L1,从而导致测量的 L2 延迟明显偏小。
本文测试的 CPU,cacheline 大小 64 字节,只需将 stride 设为 64。
测试结果如下:
//L1Buffer size: 1 KB, stride 64, time 0.003933 s, latency 3.75 nsBuffer size: 2 KB, stride 64, time 0.003930 s, latency 3.75 nsBuffer size: 4 KB, stride 64, time 0.003925 s, latency 3.74 nsBuffer size: 8 KB, stride 64, time 0.003931 s, latency 3.75 nsBuffer size: 16 KB, stride 64, time 0.003935 s, latency 3.75 nsBuffer size: 32 KB, stride 64, time 0.004115 s, latency 3.92 ns//L2Buffer size: 64 KB, stride 64, time 0.007423 s, latency 7.08 nsBuffer size: 128 KB, stride 64, time 0.007414 s, latency 7.07 nsBuffer size: 256 KB, stride 64, time 0.007437 s, latency 7.09 nsBuffer size: 512 KB, stride 64, time 0.007429 s, latency 7.09 nsBuffer size: 1024 KB, stride 64, time 0.007650 s, latency 7.30 nsBuffer size: 2048 KB, stride 64, time 0.007670 s, latency 7.32 ns//L3Buffer size: 4096 KB, stride 64, time 0.007695 s, latency 7.34 nsBuffer size: 8192 KB, stride 64, time 0.007786 s, latency 7.43 nsBuffer size: 16384 KB, stride 64, time 0.008172 s, latency 7.79 ns
虽然相比方案 1,L2 和 L3 的延迟有所增大,但还是不符合预期。
3. thinking with hardware: prefetch
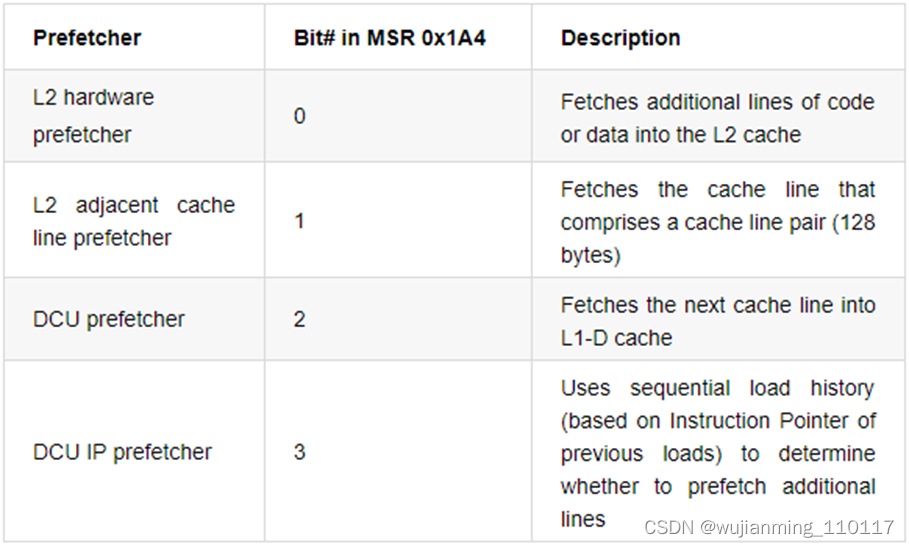
现代处理器,通常支持预取(prefetch)。数据预取通过将代码中后续可能使用到的数据提前加载到 cache 中,减少 CPU 等待数据从内存中加载的时间,提升 cache 命中率,进而提升软件的运行效率。
Intel 处理器支持 4 种硬件预取,可以通过 MSR 控制关闭和打开:
这里简单的将 stride 设为 128 和 256,避免硬件预取。测试的 L3 访存延迟明显增大:
// stride 128Buffer size: 1 KB, stride 256, time 0.003927 s, latency 3.75 nsBuffer size: 2 KB, stride 256, time 0.003924 s, latency 3.74 nsBuffer size: 4 KB, stride 256, time 0.003928 s, latency 3.75 nsBuffer size: 8 KB, stride 256, time 0.003923 s, latency 3.74 nsBuffer size: 16 KB, stride 256, time 0.003930 s, latency 3.75 nsBuffer size: 32 KB, stride 256, time 0.003929 s, latency 3.75 nsBuffer size: 64 KB, stride 256, time 0.007534 s, latency 7.19 nsBuffer size: 128 KB, stride 256, time 0.007462 s, latency 7.12 nsBuffer size: 256 KB, stride 256, time 0.007479 s, latency 7.13 nsBuffer size: 512 KB, stride 256, time 0.007698 s, latency 7.34 nsBuffer size: 512 KB, stride 128, time 0.007597 s, latency 7.25 nsBuffer size: 1024 KB, stride 128, time 0.009169 s, latency 8.74 nsBuffer size: 2048 KB, stride 128, time 0.010008 s, latency 9.55 nsBuffer size: 4096 KB, stride 128, time 0.010008 s, latency 9.55 nsBuffer size: 8192 KB, stride 128, time 0.010366 s, latency 9.89 nsBuffer size: 16384 KB, stride 128, time 0.012031 s, latency 11.47 ns
// stride 256Buffer size: 512 KB, stride 256, time 0.007698 s, latency 7.34 nsBuffer size: 1024 KB, stride 256, time 0.012654 s, latency 12.07 nsBuffer size: 2048 KB, stride 256, time 0.025210 s, latency 24.04 nsBuffer size: 4096 KB, stride 256, time 0.025466 s, latency 24.29 nsBuffer size: 8192 KB, stride 256, time 0.025840 s, latency 24.64 nsBuffer size: 16384 KB, stride 256, time 0.027442 s, latency 26.17 ns
L3 的访存延迟基本上是符合预期的,但是 L1 和 L2 明显偏大。
如果测试随机访存延迟,更加通用的做法是,在将buffer指针串起来时,随机化一下。
// shuffle indices for (i = 0; i < size; i++) { j = i + rand() % (size - i); if (i != j) { tmp = indices[i]; indices[i] = indices[j]; indices[j] = tmp; } }
可以看到,测试结果与 stride 为 256 基本上是一样的。
Buffer size: 1 KB, stride 64, time 0.003942 s, latency 3.76 nsBuffer size: 2 KB, stride 64, time 0.003925 s, latency 3.74 nsBuffer size: 4 KB, stride 64, time 0.003928 s, latency 3.75 nsBuffer size: 8 KB, stride 64, time 0.003931 s, latency 3.75 nsBuffer size: 16 KB, stride 64, time 0.003932 s, latency 3.75 nsBuffer size: 32 KB, stride 64, time 0.004276 s, latency 4.08 nsBuffer size: 64 KB, stride 64, time 0.007465 s, latency 7.12 nsBuffer size: 128 KB, stride 64, time 0.007470 s, latency 7.12 nsBuffer size: 256 KB, stride 64, time 0.007521 s, latency 7.17 nsBuffer size: 512 KB, stride 64, time 0.009340 s, latency 8.91 nsBuffer size: 1024 KB, stride 64, time 0.015230 s, latency 14.53 nsBuffer size: 2048 KB, stride 64, time 0.027567 s, latency 26.29 nsBuffer size: 4096 KB, stride 64, time 0.027853 s, latency 26.56 nsBuffer size: 8192 KB, stride 64, time 0.029945 s, latency 28.56 nsBuffer size: 16384 KB, stride 64, time 0.034878 s, latency 33.26 ns
4. thinking with compiler: register keyword
解决掉 L3 偏小的问题后,继续看 L1 和 L2 偏大的原因。为了找出偏大的原因,先反汇编可执行程序,看看执行的汇编指令是否是想要的:
objdump -D -S mem-lat > mem-lat.s
• -D: Display assembler contents of all sections.
• -S:Intermix source code with disassembly. (gcc编译时需使用-g,生成调式信息)
生成的汇编文件 mem-lat.s:
char **p = (char **)mem; 400b3a: 48 8b 45 c8 mov -0x38(%rbp),%rax 400b3e: 48 89 45 d0 mov %rax,-0x30(%rbp) // push stack
//… HUNDRED; 400b85: 48 8b 45 d0 mov -0x30(%rbp),%rax 400b89: 48 8b 00 mov (%rax),%rax 400b8c: 48 89 45 d0 mov %rax,-0x30(%rbp) 400b90: 48 8b 45 d0 mov -0x30(%rbp),%rax 400b94: 48 8b 00 mov (%rax),%rax
首先,变量 mem 赋值给变量 p,变量 p 压入栈-0x30(%rbp)。
char **p = (char **)mem; 400b3a: 48 8b 45 c8 mov -0x38(%rbp),%rax 400b3e: 48 89 45 d0 mov %rax,-0x30(%rbp)
访存的逻辑:
HUNDRED; // p = (char **)*p 400b85: 48 8b 45 d0 mov -0x30(%rbp),%rax 400b89: 48 8b 00 mov (%rax),%rax 400b8c: 48 89 45 d0 mov %rax,-0x30(%rbp)
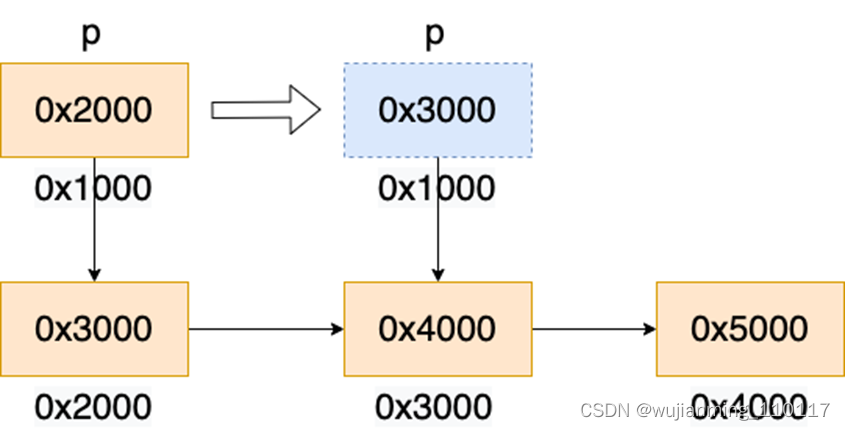
• 先从栈中读取指针变量 p 的值到rax寄存器(变量 p 的类型为char **,是一个二级指针,也就是说,指针 p 指向一个char 的变量,即 p 的值也是一个地址)。下图中变量 p 的值为 0x2000。
• 将rax寄存器指向变量的值读入rax寄存器,对应单目运算p。下图中地址 0x2000的值为 0x3000,rax 更新为 0x3000。
• 将rax寄存器赋值给变量p。下图中变量p的值更新为0x3000。
根据反汇编的结果可以看到,期望的 1 条 move 指令被编译成了 3 条,cache 的延迟也就增加了 3 倍。C 语言的 register 关键字,可以让编译器将变量保存到寄存器中,从而避免每次从栈中读取的开销。
It’s a hint to the compiler that the variable will be heavily used and that you recommend it be kept in a processor register if possible.
在声明 p 时,加上 register 关键字。
register char **p = (char **)mem;

测试结果如下:
// L1Buffer size: 1 KB, stride 64, time 0.000030 s, latency 0.03 nsBuffer size: 2 KB, stride 64, time 0.000029 s, latency 0.03 nsBuffer size: 4 KB, stride 64, time 0.000030 s, latency 0.03 nsBuffer size: 8 KB, stride 64, time 0.000030 s, latency 0.03 nsBuffer size: 16 KB, stride 64, time 0.000030 s, latency 0.03 nsBuffer size: 32 KB, stride 64, time 0.000030 s, latency 0.03 ns// L2Buffer size: 64 KB, stride 64, time 0.000030 s, latency 0.03 nsBuffer size: 128 KB, stride 64, time 0.000030 s, latency 0.03 nsBuffer size: 256 KB, stride 64, time 0.000029 s, latency 0.03 nsBuffer size: 512 KB, stride 64, time 0.000030 s, latency 0.03 nsBuffer size: 1024 KB, stride 64, time 0.000030 s, latency 0.03 ns// L3Buffer size: 2048 KB, stride 64, time 0.000030 s, latency 0.03 nsBuffer size: 4096 KB, stride 64, time 0.000029 s, latency 0.03 nsBuffer size: 8192 KB, stride 64, time 0.000030 s, latency 0.03 nsBuffer size: 16384 KB, stride 64, time 0.000030 s, latency 0.03 ns
访存延迟全部变为不足 1 ns,明显不符合预期。
5. thinking with compiler: Touch it!
重新反汇编,看看哪里出了问题,编译代码如下:
for (i = 0; i < tmp; ++i) { 40155e: 48 c7 45 f8 00 00 00 movq $0x0,-0x8(%rbp) 401565: 00 401566: eb 05 jmp 40156d <main+0x37e> 401568: 48 83 45 f8 01 addq $0x1,-0x8(%rbp) 40156d: 48 8b 45 f8 mov -0x8(%rbp),%rax 401571: 48 3b 45 b0 cmp -0x50(%rbp),%rax 401575: 72 f1 jb 401568 <main+0x379> HUNDRED; } gettimeofday (&tv2, &tz); 401577: 48 8d 95 78 ff ff ff lea -0x88(%rbp),%rdx 40157e: 48 8d 45 80 lea -0x80(%rbp),%rax 401582: 48 89 d6 mov %rdx,%rsi 401585: 48 89 c7 mov %rax,%rdi 401588: e8 e3 fa ff ff callq 401070 gettimeofday@plt
HUNDRED 宏没有产生任何汇编代码。涉及到变量 p 的语句,并没有实际作用,只是数据读取,大概率被编译器优化掉了。
register char **p = (char *) mem; tmp = count / 100;
gettimeofday (&tv1, &tz); for (i = 0; i < tmp; ++i) { HUNDRED; } gettimeofday (&tv2, &tz);
/ touch pointer p to prevent compiler optimization */ char **touch = p;
反汇编验证一下:
HUNDRED; 401570: 48 8b 1b mov (%rbx),%rbx 401573: 48 8b 1b mov (%rbx),%rbx 401576: 48 8b 1b mov (%rbx),%rbx 401579: 48 8b 1b mov (%rbx),%rbx 40157c: 48 8b 1b mov (%rbx),%rbx
HUNDRED 宏产生的汇编代码只有操作寄存器 rbx 的 mov 指令,高级。
延迟的测试结果如下:
// L1Buffer size: 1 KB, stride 64, time 0.001687 s, latency 1.61 nsBuffer size: 2 KB, stride 64, time 0.001684 s, latency 1.61 nsBuffer size: 4 KB, stride 64, time 0.001682 s, latency 1.60 nsBuffer size: 8 KB, stride 64, time 0.001693 s, latency 1.61 nsBuffer size: 16 KB, stride 64, time 0.001683 s, latency 1.61 nsBuffer size: 32 KB, stride 64, time 0.001783 s, latency 1.70 ns// L2Buffer size: 64 KB, stride 64, time 0.005896 s, latency 5.62 nsBuffer size: 128 KB, stride 64, time 0.005915 s, latency 5.64 nsBuffer size: 256 KB, stride 64, time 0.005955 s, latency 5.68 nsBuffer size: 512 KB, stride 64, time 0.007856 s, latency 7.49 nsBuffer size: 1024 KB, stride 64, time 0.014929 s, latency 14.24 ns// L3Buffer size: 2048 KB, stride 64, time 0.026970 s, latency 25.72 nsBuffer size: 4096 KB, stride 64, time 0.026968 s, latency 25.72 nsBuffer size: 8192 KB, stride 64, time 0.028823 s, latency 27.49 nsBuffer size: 16384 KB, stride 64, time 0.033325 s, latency 31.78 ns
L1 延迟 1.61 ns,L2 延迟 5.62 ns,终于,符合预期!
小结
本文的思路和代码参考自 lmbench,和团队内其他同学的工具 mem-lat。最后给自己挖个坑,在随机化 buffer 指针时,没有考虑硬件 TLB miss 的影响,如果有读者有兴趣,待日后有空补充。
参考文献:
[1] https://en.wikichip.org/wiki/intel/microarchitectures/skylake_(server)
[2]https://software.intel.com/content/www/us/en/develop/articles/disclosure-of-hw-prefetcher-control-on-some-intel-processors.html
[3]McVoy L W, Staelin C. lmbench: Portable Tools for Performance Analysis[C]//USENIX annual technical conference. 1996: 279-294.
参考文献链接
https://mp.weixin.qq.com/s/PddkCP_tE-TwOyXMGM2jvA
https://mp.weixin.qq.com/s/z_rQnSD8DFGIMaj2H0–gg
https://product.pconline.com.cn/itbk/diy/cpu/1107/2474321.html