1.自动微分以及思考 tf版
写在前面
大家从最近的blog也可以看出,我最近一直在学习前后端相关的内容。不管是由于项目原因还是个人原因,都已经很久没有写python,也没有碰机器学习,深度学习的内容,偶尔看到公众号推的一些最新论文方法,心中也再无一丝波澜。最近呢,事情慢慢定下来,想搞学术(水论文)还是逃不开这些,所以打算重新学一遍深度学习主要还是框架的使用。涉及到的相关知识点看情况会进行补充,所以如果也有想入门深度学习,还不太了解框架使用的朋友们,我们可以一起学习交流,看看这个专栏或许可以有所收获。
这次涉及到的框架还是主流的tensorflow 2.X和pytorch,具体的内容是网上各种资料例如花书、d2l、入门教程、官方文档……总结而成。顺序呢还是先学tf再pytorch,再次说明侧重点还是框架api的使用,涉及到基础知识的部分大家可以自己去看花书或者d2l。
另外推荐大家可以去B站看看沐神的视频,每一个视频时长都不长但是讲的非常清楚。
正式开始
首先,环境的搭建是必须的,TF的版本只要是2以上都可以,最好安装GPU版本。
第一步,检查版本以及是否GPU可用
import tensorflow as tf
import os
os.environ['TF_CPP_MIN_LOG_LEVEL']='1'
print(tf.__version__)
print(tf.config.list_physical_devices('GPU'))

版本之间到底有什么区别
我第一次接触tensorflow是两年多前,老师教了一丢丢深度学习的东西,然后让我们安装tensorflow环境,当时还是1.9。在github上面找了一些例子跑了一下,最难忘的应该就是下面这样的代码
with tf.Session(graph = g) as sess:
sess.run(...)
有幸今天帮一个朋友找他想要的数据的时候把之前笔记本里几年前的代码也翻出来了
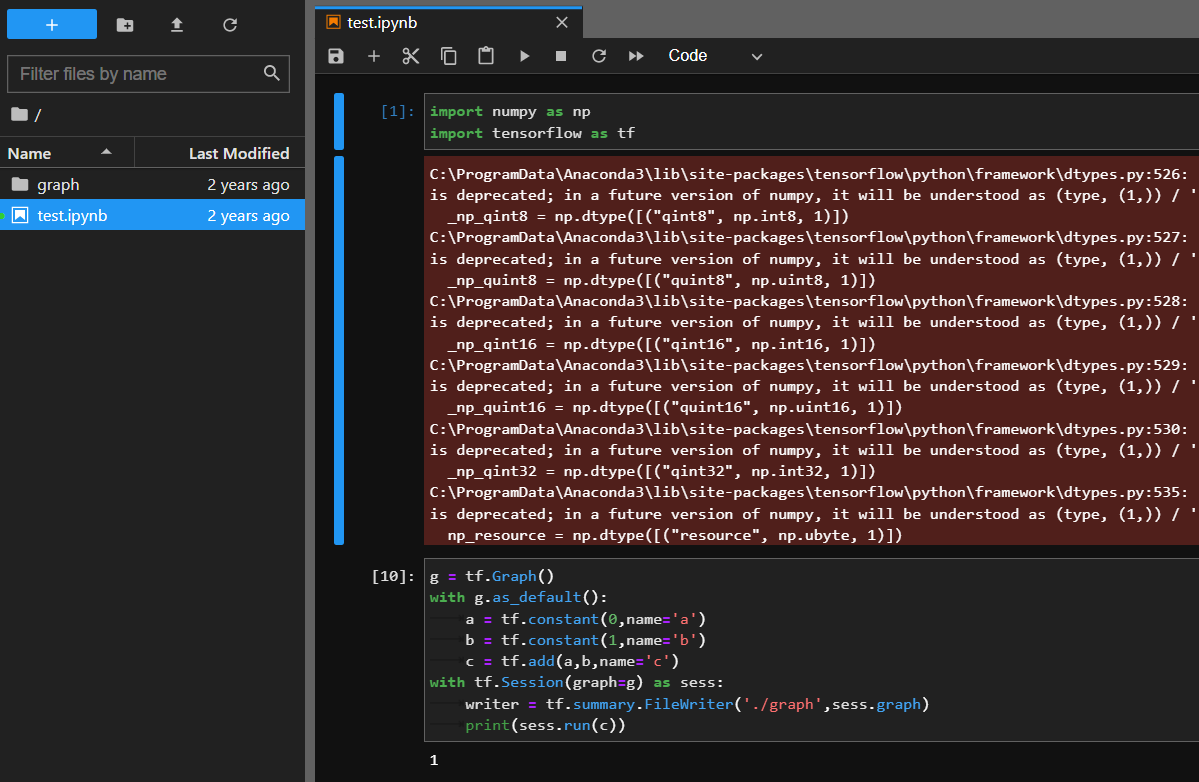
在TF1中,默认使用的是静态图,第一步是先定义计算图,第二步才是开启会话进行计算;但是在我刚上手TF1不久,TF2.0就发布了,默认使用动态图,不用再先定义再执行而是定义后立刻执行,这才更加贴近Python coder编辑的习惯,喜欢Python一个原因可能就是不用先 int a=1;而是直接a=1。动态图方便的同时也就意味着代码运行效率的降低,但是这种降低对于我们研究学习上的便利性来说还是可以容忍的。
动态图效率低的原因: 静态图定义好之后就全部在TF内核上用C++执行,而动态图由于实时性,也就是说Python进程随时可能会与TF的C++进程进行通信传输数据,这无疑是消耗时间的;而且静态图定义后可以自己对计算步骤进行优化,动态图丧失了这个能力。
下面是动态图上进行计算的例子
import tensorflow as tf
import os
os.environ['TF_CPP_MIN_LOG_LEVEL']='1'
a=tf.constant(2)
b=tf.constant(1)
#c=tf.add(a,b)
c=a+b
print(c)
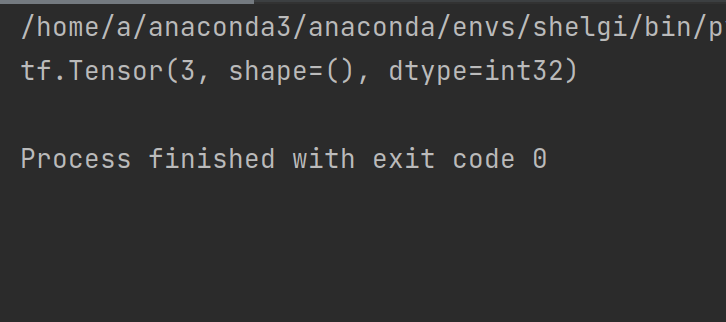
函数转为静态计算图
有的时候为了解决动态图的效率问题,加上@tf.function将函数转为对应的静态图构建来计算
@tf.function
def my_add(x,y):
return x**2+y**2
res=my_add(a,b)
print(res)

习惯性的还是去看看装饰器源码
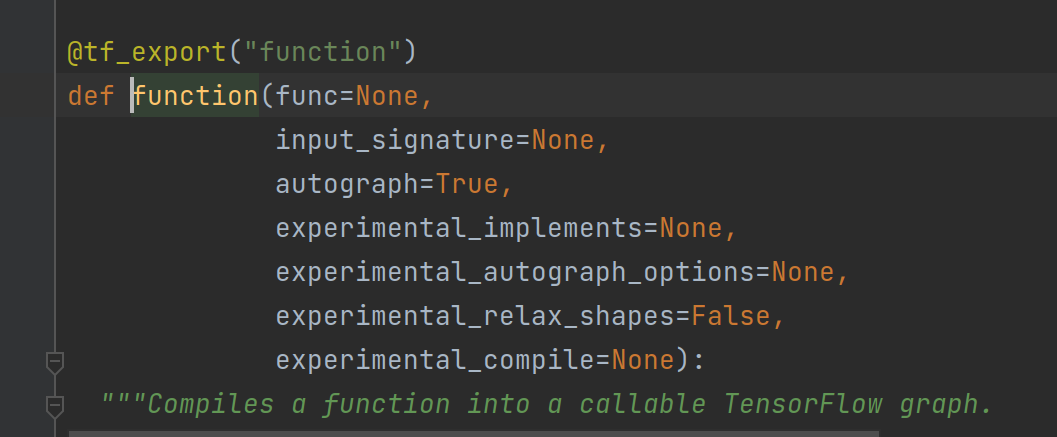
decorated()里面就把我们需要的函数功能留下并且tf_export装饰器再装饰一次变成最终静态图模式构建的函数

这里最终的partial()在.pyi文件中,也就是存根文件,已经定义好了静态类型
终于开始微分
我们之所以使用深度学习框架,或者说这些框架最主要的功能,就是解决微分问题。我们学过梯度下降、反向传播之后就应该知道,为了实现神经网络的参数更新,我们必须在反向传播时计算每一层的梯度,涉及到梯度那就离不开求微分这个功能。
在TF中,我们使用tf.GradientTape正向传播,然后自动微分求梯度。首先来看一个例子
import tensorflow as tf
# 输入一个x
x=tf.Variable(int(input()),dtype=tf.float32)
# 首先设计待微分函数 y=5x^3+3x^2-8x+10
@tf.function
def f():
a=tf.constant(5.0)
b=tf.constant(3.0)
c=tf.constant(-8.0)
with tf.GradientTape() as tape:
tape.watch(x)
y=a*tf.pow(x,3)+b*tf.pow(x,2)+c*x+10
dy_dx=tape.gradient(y,x)
tf.print(dy_dx)
return y
# 打印微分结果
f()
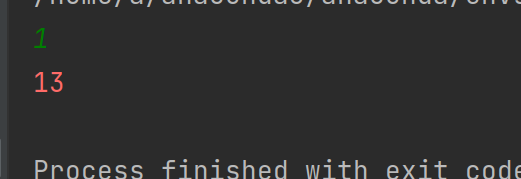
先不考虑装饰器tf.funtion的作用,那在动态图模式下tf.GradientTape是如何求梯度的呢?
遇到疑惑点击进去看看源码
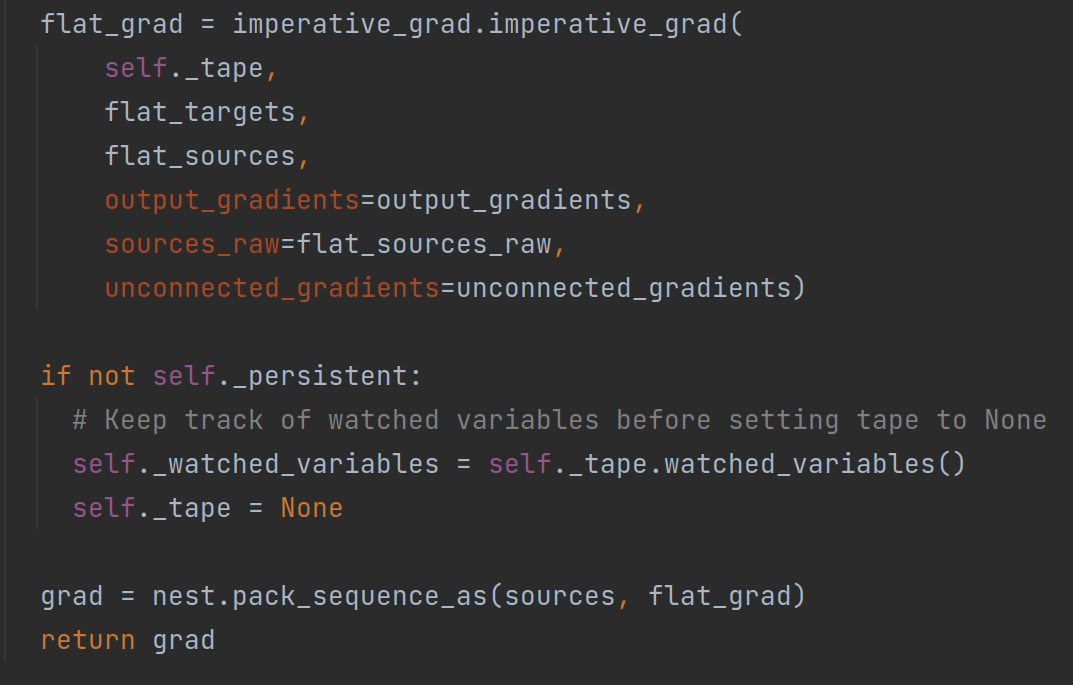
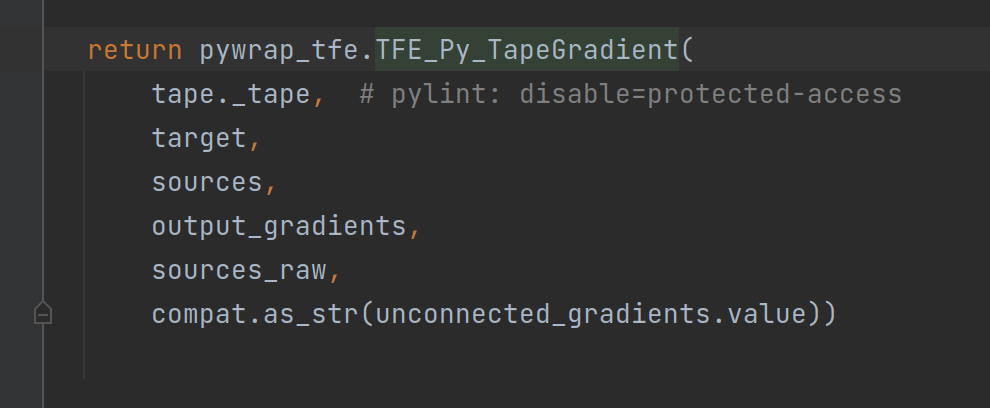
核心部分代码就是imperative_grad.imperative_grad()函数部分,继续点击查看
查看这个链接库中的函数nm -D xxx.so
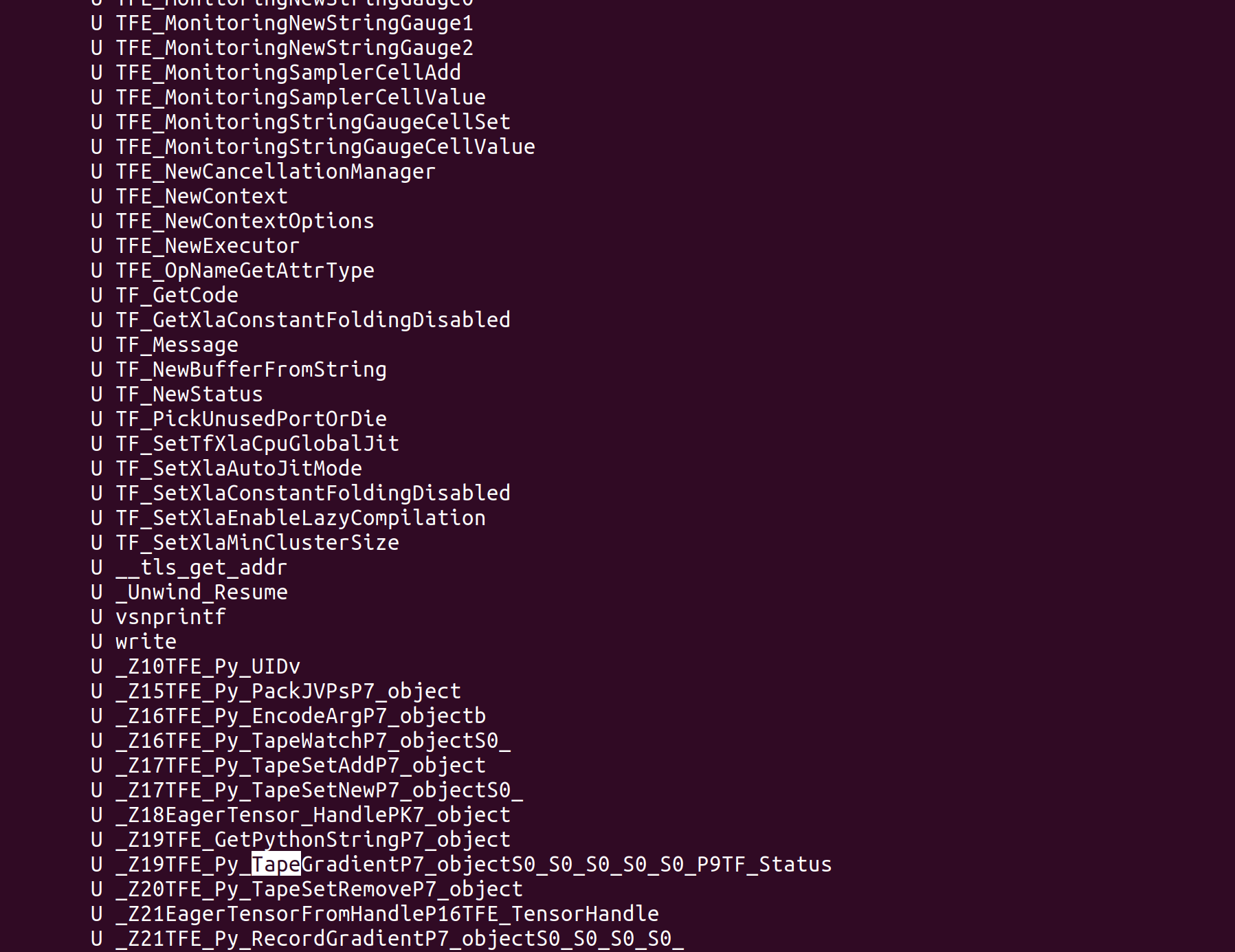
最终应该就是这里实现梯度计算的接口,但是我们使用的时候不用考虑底层到底是符号求导、数值求导还是前向模式、反向模式,这里我只是今天顺便深挖了一下。
微分求最小值
深度学习的最终目标就是最小化损失函数,还是归根于求最小值问题。tensorflow中也提供了一系列优化器来供我们优化参数,最小化损失函数。利用上面的例子,我们找找这个函数的最小值。
import tensorflow as tf
import os
os.environ['TF_CPP_MIN_LOG_LEVEL']='1'
# 输入一个x
x=tf.Variable(int(input()),dtype=tf.float32)
# 首先设计待微分函数 y=5x^3+3x^2-8x+10
@tf.function
def f():
a=tf.constant(5.0)
b=tf.constant(3.0)
c=tf.constant(-8.0)
with tf.GradientTape() as tape:
tape.watch(x)
y=a*tf.pow(x,3)+b*tf.pow(x,2)+c*x+10
dy_dx=tape.gradient(y,x)
tf.print(dy_dx)
return y
# 打印微分结果
f()
# 寻找函数最小值
# global_step = tf.Variable(100)
# lr=tf.compat.v1.train.exponential_decay(0.01,global_step=global_step,decay_rate=0.8,decay_steps=10)
lr=0.01
optimizer=tf.keras.optimizers.SGD(learning_rate=lr)
for _ in range(100):
optimizer.minimize(f,x)
print(f().numpy(),x.numpy())
输入3,结果如下
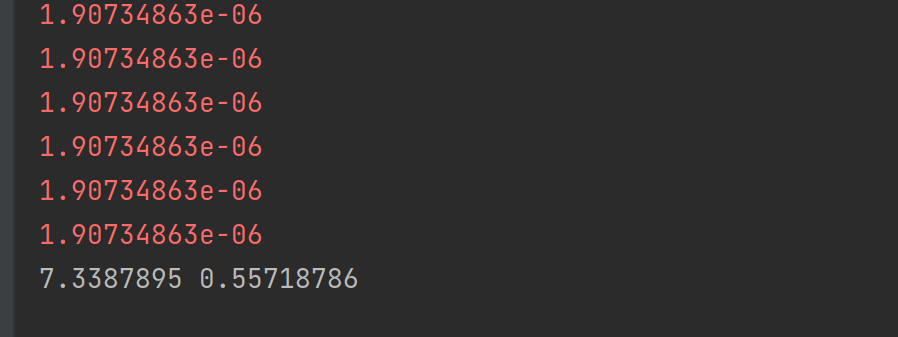
貌似还不错,但是如果我输入的是比较大的数,比如10呢
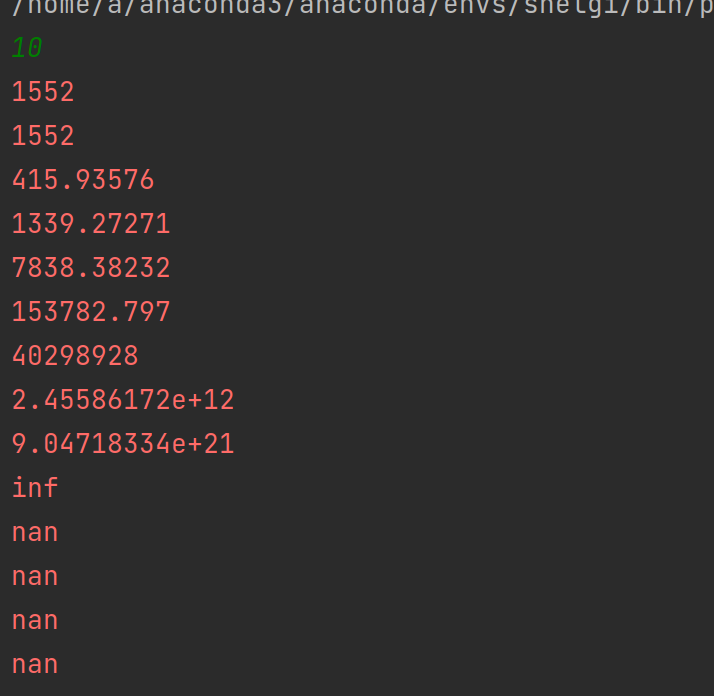
我们可以看到梯度先下降了一点点,然后一直增大,直到无法拟合nan
我们之前一直被教,学习率的选取很重要,太小会难以收敛,太大会梯度爆炸,如下图所示
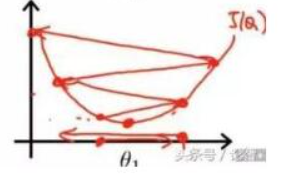
当学习率太大直接越过最小值点,然后梯度一路猛增,这也算是直观的看到学习率对梯度的影响。
既然我们知道了是因为学习率过大导致,那我们减小学习率再试试,将lr=0.001
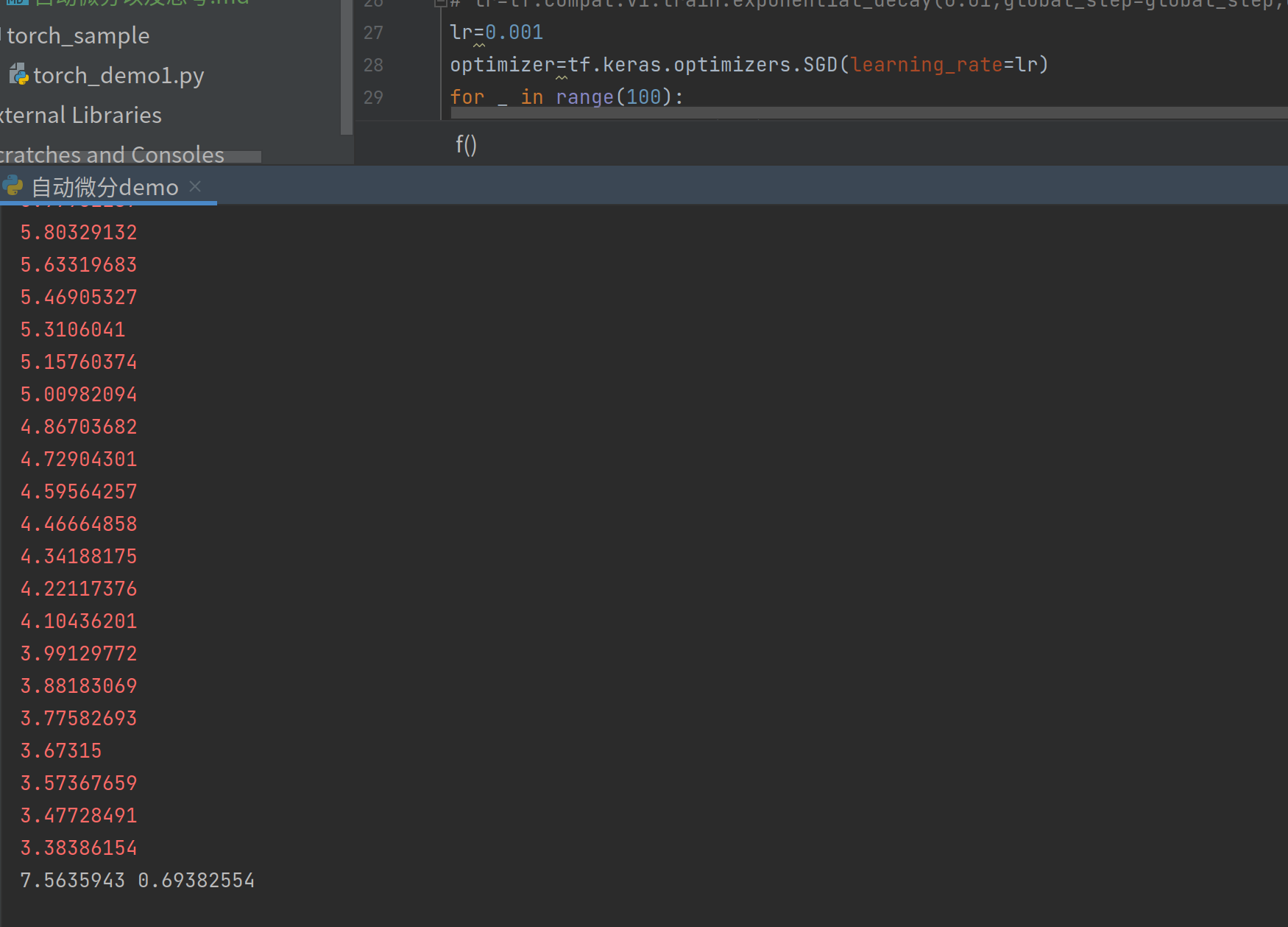
成功收敛,最小值与之前相差不大。还有兴趣的可以试试我注释掉的部分,利用指数衰减学习率,效果如下
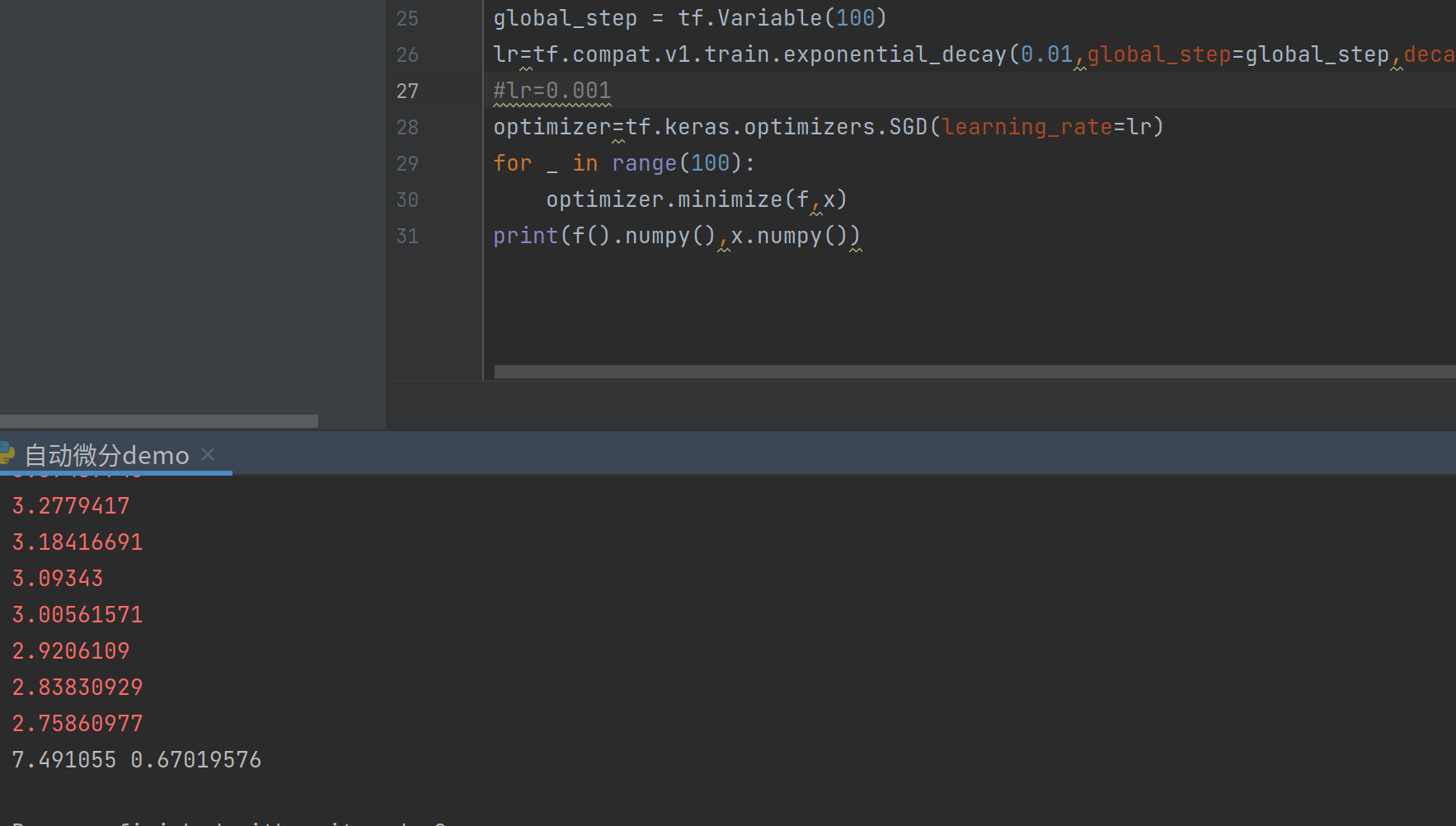
还可以试试Adam和其他优化器,之前说Adam性能特别好,但是真的是这样吗?
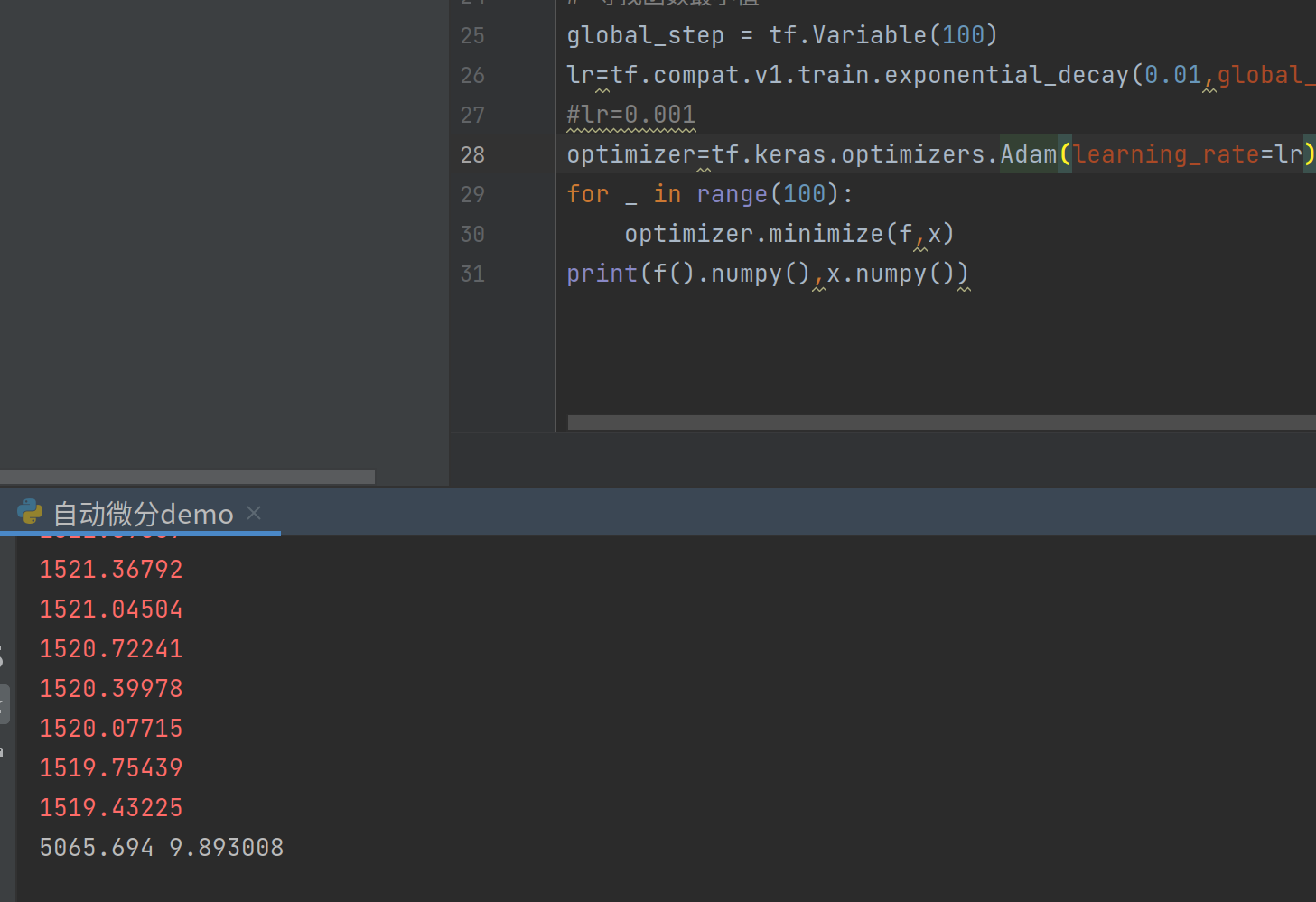
同样的参数条件下,Adam的表现貌似并没有SGD好
结尾
今天重新开始学一遍框架,还挺兴奋的,发现了很多以前没有考虑到的地方,后面的话进度应该会加快,不会太过于细致。