- 通常情况下,如果要更新网页的内容,需要重新加载整个网页。而Ajax动态请求则能在不重新加载整个网页的情况下,与服务器交换数据并更新网页中的部分内容。因此,严格来说,Ajax动态请求并不是一种反爬手段,而是一种网页展示手段。不过它的确在一定程度上给数据的爬取造成了困难,所以本书也将其视为一种反爬手段。本章将介绍Ajax动态请求的基本原理与破解方法,并以开源中国博客频道和新浪微博为例进行实战演练。
3.1 Ajax 简介
- Ajax动态请求在本质上就是把常规的翻页操作做成了动态刷新的效果。最典型的例子就是开源中国博客频道和新浪微博等博客类网站,大家在浏览页面时会发现,用鼠标滚轮向下滚动页面的过程中会自动加载新的内容,但是地址栏中的网址没有发生变化,这就是用Ajax动态请求实现的。本节先来讲解Ajax动态请求的基础知识。
3.1.1 不同的网页翻页方式的对比
- 首先来对比3中不同的网页翻页方式,这对理解Ajax动态请求的基本原理与破解方法有较大的帮助。
1.网页中有翻页参数
- 先来看看百度新闻的翻页方式。如下图所示,对于不同的页面,网址中有用于控制页数的参数pn(page number的缩写),其变化规律为(页码 - 1)X 10.
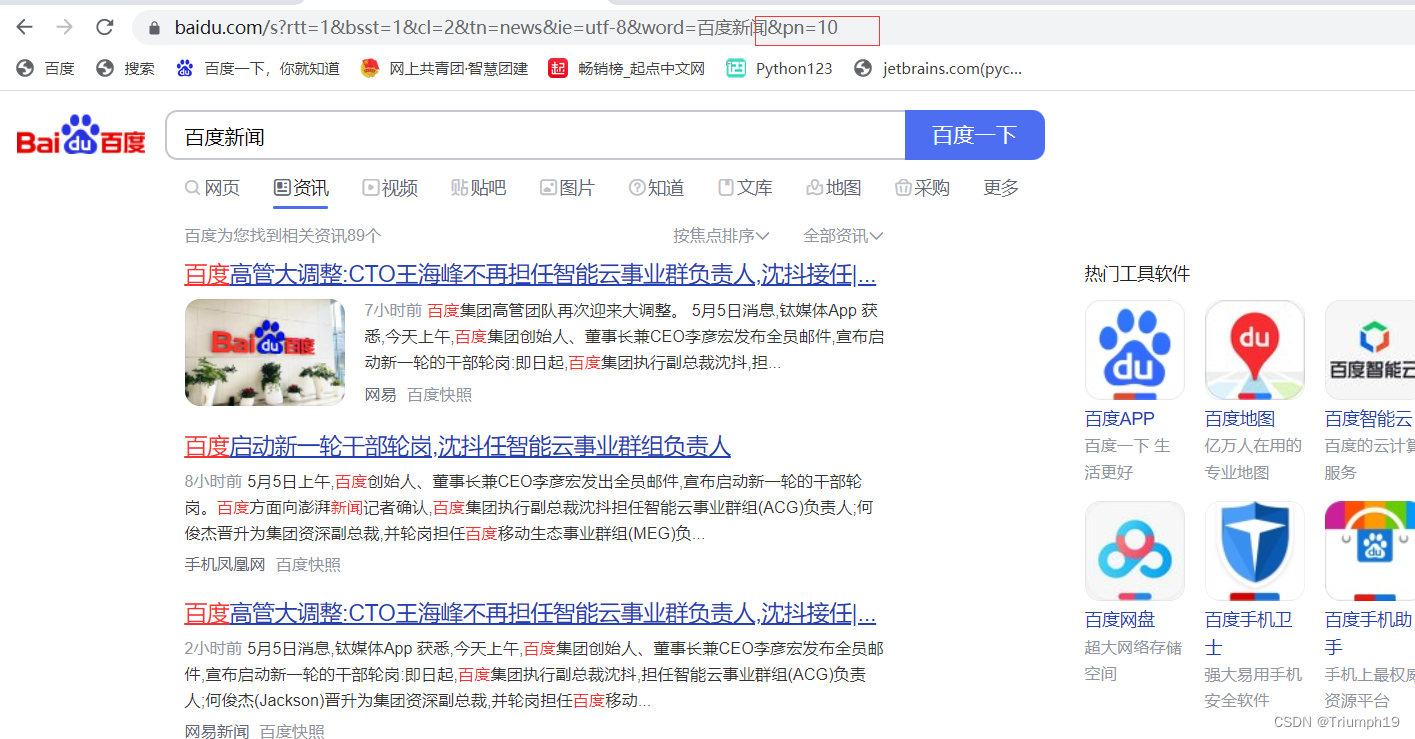
- 因此,当想爬取多页内容时,在网址中变化翻页参数即可。当然也可以利用Selenium库模拟单击“下一页”按钮,不过在网址中可以找到页数规律的情况下,显得不太灵巧。
2.网址中没有翻页参数,网页中有翻页按钮
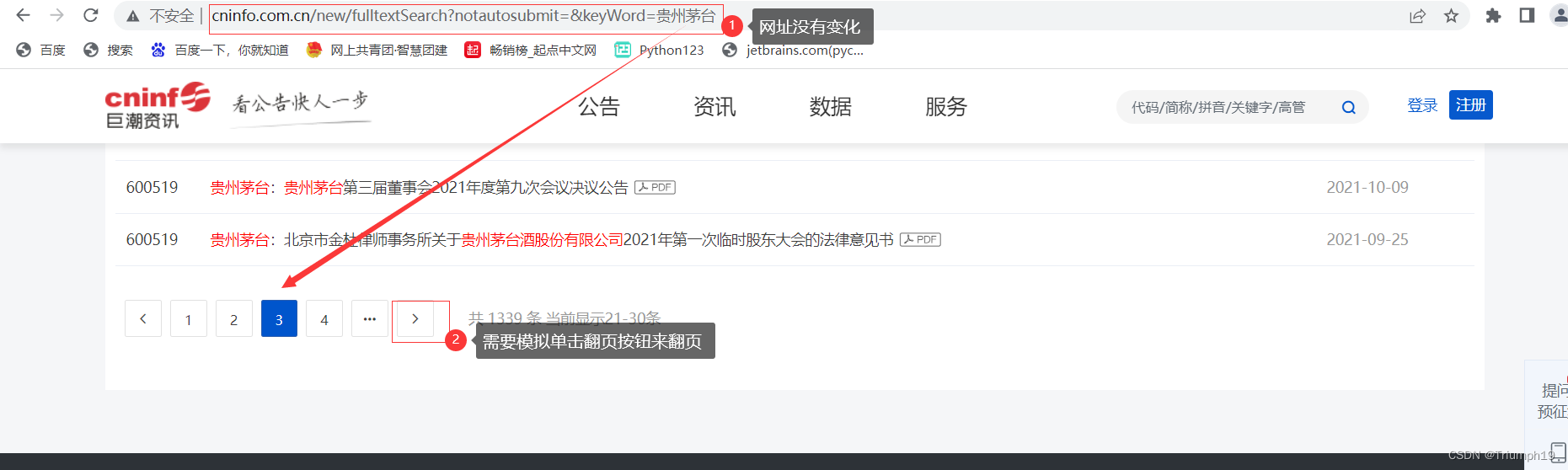
- 再来看巨潮资讯网的翻页方式。如下图所示,在翻页过程中网址没有变化,因而无法通过构造网址来翻页,而是需要利用Selenium库模拟单击翻页按钮来翻页。
3.既没有网页参数也没有翻页按钮,通过滚动页面来加载新内容
- 最后来看开源中国博客频道的翻页方式。如下图所示,在“翻页”(实际操作为向下滚动页面)的过程中,网址没有变化,同时网页上也没有翻页按钮,因而既无法通过构造网页来翻页,又无法通过Selenium库模拟单击翻页按钮来翻页。在手动操作的情况下,需要用鼠标滚轮将页面滚动到底部,然后继续滚动才能看到新的内容。这种“翻页”加载新内容的方式就是通过Ajax动态请求实现的。
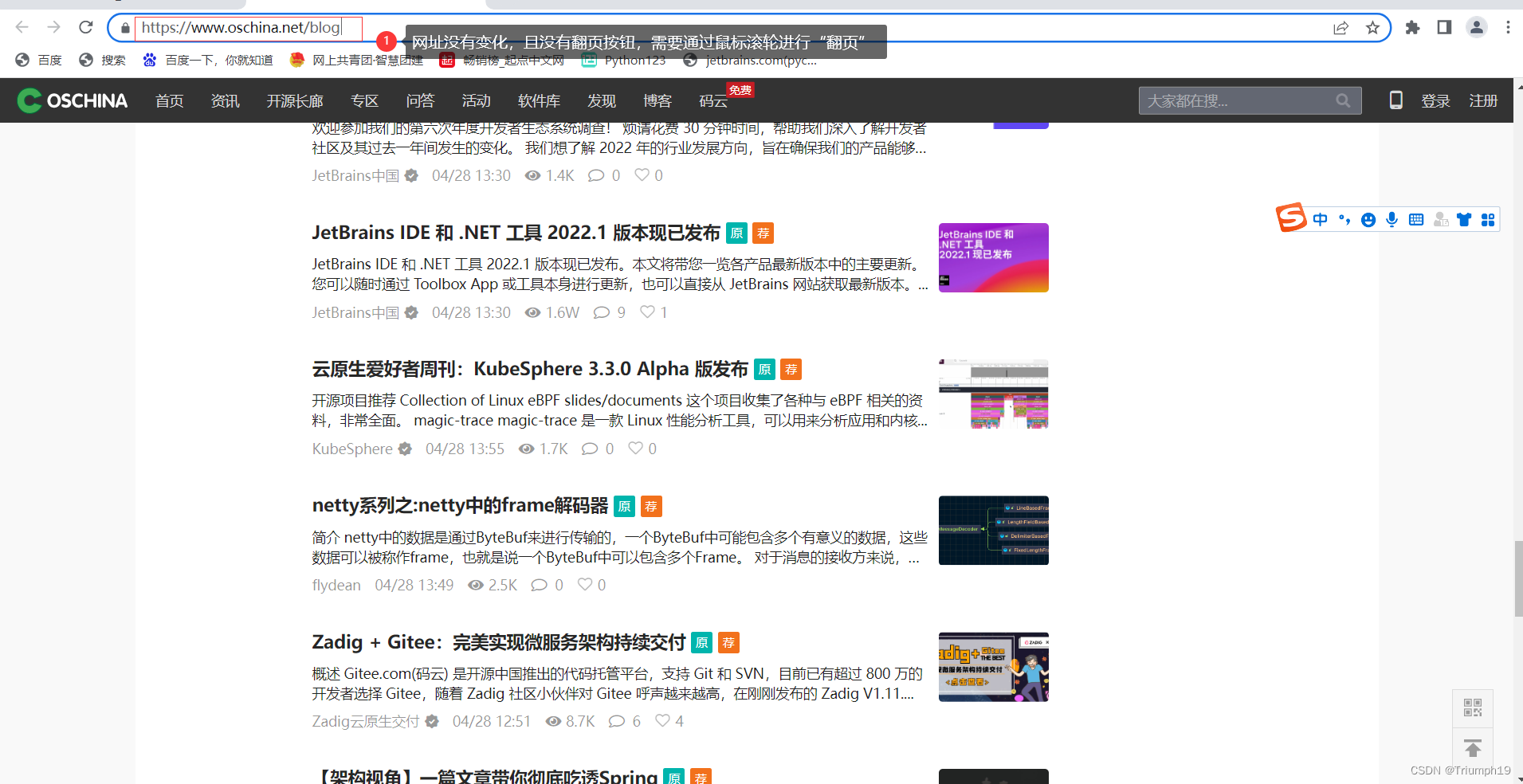
- 对于这种用Ajax动态请求实现的网页,如果只是爬取第1页(通常为最新的内容),那么用Requests库或Selenium库一般都可以完成。但是,如果想一次爬取“多页”(即爬取需要通过向下滚动页面才能加载的新内容),那么就需要对Ajax动态请求进行破解。
- 常用的破解方法其实和前两种翻页方式也有关联:(1)参照翻页方式1,找到真正的网址中的翻页参数,然后通过Requests库进行请求;(2)参照翻页方式2,通过Selenium库模拟鼠标滚轮滚动,变相实现翻页。这两种破解方法具体又该如何实现呢?这就涉及Ajax动态请求的基本概念和工作原理,3.1.2节会进行讲解,并从中实现这两种破解方法的突破口。
3.1.2 Ajax 的基本原理与工作原理
- Ajax与Python不同,它不是一门编程语言,而是一种技术方案。
- Ajax的全称是Asynchronous JavaScript and XML(异步的JavaScript和XML)。在传统网页中,如果需要更新页面内容,哪怕知识更新其中的很小部分,都必须重新加载整个页面,这样会造成很大的资源浪费。而在前面所举的的开源中国博客频道等例子中,通过应用Ajax动态请求,无须重新加载整个页面,就能局部动态更新页面内容:当页面已经滚动到底部时,如果继续往下滚动,Ajax就会向网站服务器发送一个“指令”——已经到底了,请提供一些新内容——此时网站服务器就会传一些新内容,供Ajax显示在网页中。
- 上面用一些形象的方式描述了Ajax的工作过程,下面用更严谨的语言描述Ajax的工作过程:
- (1)触发条件:用户在网页中触发某些条件,如将页面滚动到底部。
- (2)请求数据:前端代码使用Ajax向后端后发送请求,要求服务器提供一些数据。
- (3)获取数据:前端代码获得服务器的响应后,对接收到的数据进行处理并呈现在页面上。
- 下面则是用技术性更强的语言对上述过程进行了细化,读者无须深究,简单了解即可。

- 这里重点关注上图右侧的两种破解方法。
- 方法1:以请求数据为突破口,用Requests库破解。
- 触发条件后,Ajax会向服务器发送请求,以获取新的数据。为通过Requests库获取新的数据,就需要知道发往服务器接口的真正网址及携带的参数。3.2节会讲解如何通过通过分析一个具体的Ajax请求来找到网页向服务器请求的真正网址及携带的参数(主要讲翻页参数)。
- 方法2:以触发条件为突破口,用Selenium库破解。
- 通过Selenium库破解Ajax的核心是模拟滚动页面的操作,其核心代码如下:
browser.execute_script('window.scrollTo(0,document.body.scrollHeight)')
- 这行代码利用Selenium库的execute_script()函数模拟执行代码(JavaScript可在网页中执行动态操作,读者简单了解即可)。这里执行的JavaScript代码是window.scrollTo(0,document.body.scrollHeight)。其中window.scrollTo()函数用于把页面滚动到指定的像素点。该函数的第1个参数为x轴像素坐标,这里设置为0;第2个参数为y轴像素坐标,这里设置为document.body.scrollHeight,表示目前页面的高度。实现的效果就是把页面滚动到已展示区域的最底端。通过不停地向下滚动,就能加载新内容了。3.3节会以新浪微博为例具体讲解。
- 方法1不需要打开模拟浏览器,所以爬取速度稍快,但是需要分析真正的网址,得多动一些脑筋。而方法2不需要做额外的分析,实现起来相对比较简单,只是爬取速度稍慢。两种破解方法各有优缺点,建议读者都要掌握。