文章目录

容器解决了什么?又遇到了什么问题
容器,到底是怎么一回事儿?
在Docker出现之前,最为流行的是PaaS 项目。
PaaS 项目被大家接纳的一个主要原因,就是它提供了一种名叫“应用托管”的能力。
像 Cloud Foundry 这样的 PaaS 项目,最核心的组件就是一套应用的打包和分发机制。更好地模拟本地服务器环境,能带来更好的“上云”体验。
Cloud Foundry 会调用操作系统的 Cgroups 和 Namespace 机制为每一个应用单独创建一个称作“沙盒”的隔离环境,然后在“沙盒”中启动这些应用进程。这样,就实现了把多个用户的应用互不干涉地在虚拟机里批量地、自动地运行起来的目的。
Docker 实际上只是一个同样使用 Cgroups 和 Namespace 实现的“沙盒”而已,没有什么特别的黑科技,也不需要特别关注。
事实上,Docker 项目确实与 Cloud Foundry 的容器在大部分功能和实现原理上都是一样的,可偏偏就是这剩下的一小部分不一样的功能,成了 Docker 项目接下来“呼风唤雨”的不二法宝。
这个功能,就是 Docker 镜像。
Docker 镜像解决的,恰恰就是打包这个根本性的问题。 所谓 Docker 镜像,其实就是一个压缩包。但是这个压缩包里的内容,比 PaaS 的应用可执行文件 + 启停脚本的组合就要丰富多了。实际上,大多数 Docker 镜像是直接由一个完整操作系统的所有文件和目录构成的,所以这个压缩包里的内容跟你本地开发和测试环境用的操作系统是完全一样的。
其实只打包了文件系统,不包括操作系统内核
扫描二维码关注公众号,回复: 13969028 查看本文章
容器核心
0.“程序”运行
“程序”被执行起来,它就从磁盘上的二进制文件,变成了计算机内存中的数据、寄存器里的值、堆栈中的指令、被打开的文件,以及各种设备的状态信息的一个集合。像这样一个程序运起来后的计算机执行环境的总和,就是我们今天的主角:进程。
所以,对于进程来说,它的静态表现就是程序,平常都安安静静地待在磁盘上;而一旦运行起来,它就变成了计算机里的数据和状态的总和,这就是它的动态表现。
而容器技术的核心功能,就是通过约束和修改进程的动态表现,从而为其创造出一个“边界”。
一个正在运行的 Docker 容器,其实就是一个启用了多个 Linux Namespace 的应用进程,而这个进程能够使用的资源量,则受 Cgroups 配置的限制。
1. Namespace
Linux Namespace 是一种 Linux Kernel 提供的资源隔离方案:
系统可以为进程分配不同的 Namespace;
并保证不同的 Namespace 资源独立分配、进程彼此隔离,即 不同的 Namespace 下的进程互不干扰 。
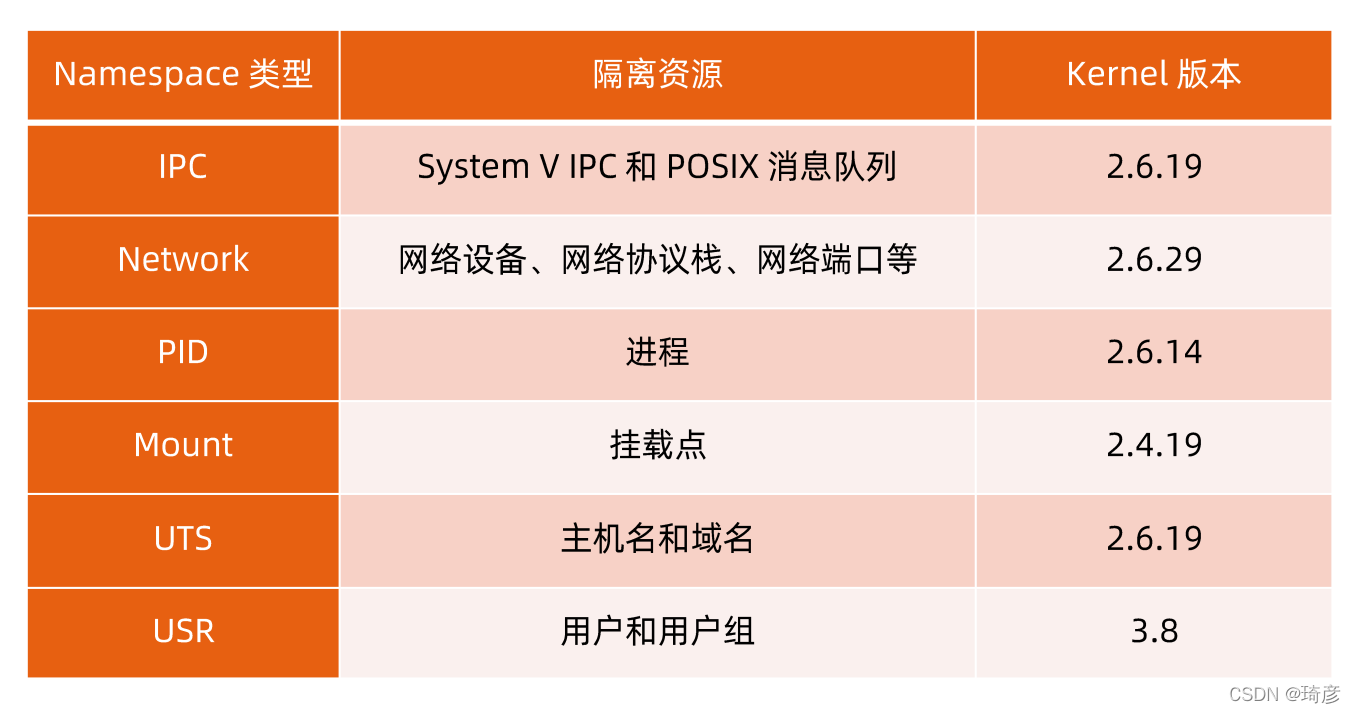
除了PID Namespace,Linux 操作系统还提供了 Mount、UTS、IPC、Network 和 User 这些 Namespace,用来对各种不同的进程上下文进行“障眼法”操作。
比如,Mount Namespace,用于让被隔离进程只看到当前 Namespace 里的挂载点信息;Network Namespace,用于让被隔离进程看到当前 Namespace 里的网络设备和配置。
这,就是 Linux 容器最基本的实现原理了。
Namespce练习
# 在新 network namespace 执行 sleep 指令:
unshare -fn sleep 60
# 查看进程信息
ps -eflgrep sleep
# 查看网络 Namespace
lsns -t net
# 进入改进程所在 Namespace 查看网络配置,与主机不一致
nsenter -t 32882 -n ip a
2. Cgroups
Linux Cgroups 的全称是 Linux Control Group。它最主要的作用,就是限制一个进程组能够使用的资源上限,包括 CPU、内存、磁盘、网络带宽等等。
除 CPU 子系统外,Cgroups 的每一项子系统都有其独有的资源限制能力,比如:
- blkio,为块设备设定I/O 限制,一般用于磁盘等设备;
- cpuset,为进程分配单独的 CPU 核和对应的内存节点;
- memory,为进程设定内存使用的限制。
CPU 子系统练习
在 Linux 中,Cgroups 给用户暴露出来的操作接口是文件系统,即它以文件和目录的方式组织在操作系统的 /sys/fs/cgroup 路径下。
[root@gv41New95 ~]# mount -t cgroup
cgroup on /sys/fs/cgroup/systemd type cgroup
...
它的输出结果,是一系列文件系统目录。
可以看到,在 /sys/fs/cgroup 下面有很多诸如 cpuset、cpu、 memory 这样的子目录,也叫子系统。这些都是我这台机器当前可以被 Cgroups 进行限制的资源种类。而在子系统对应的资源种类下,你就可以看到该类资源具体可以被限制的方法。比如,对 CPU 子系统来说,我们就可以看到如下几个配置文件,这个指令是:
[root@gv41New95 ~]# ls /sys/fs/cgroup/cpu
cgroup.clone_children cpuacct.stat cpu.cfs_quota_us cpu.stat release_agent
cgroup.event_control cpuacct.usage cpu.rt_period_us kubepods.slice system.slice
cgroup.procs cpuacct.usage_percpu cpu.rt_runtime_us machine.slice tasks
cgroup.sane_behavior cpu.cfs_period_us cpu.shares notify_on_release user.slice
如果熟悉 Linux CPU 管理的话,你就会在它的输出里注意到 cfs_period 和 cfs_quota 这样的关键词。这两个参数需要组合使用,可以用来限制进程在长度为 cfs_period 的一段时间内,只能被分配到总量为 cfs_quota 的 CPU 时间。
使用配额方式分配CPU给容器,这里面需要一对参数,cpu-period设置评估周期,cpu-quota设置配额,cpu-quota/cpu-period为实际分配的CPU量,这个商是小数就表示分配的CPU量不足一个vCPU,如果商大于1就表示分配的CPU量超过一个vCPU。
cpu-period设置是一个评估周期,区间在1ms~1s之间。
cpu-quota设置是这个评估周期的内CPU配额。
而这样的配置文件又如何使用呢?
你需要在对应的子系统下面创建一个目录,比如,我们现在进入 /sys/fs/cgroup/cpu 目录下:
### 在 cgroup cpu 子系统目录中创建目录结构
cd /sys/fs/cgroup/cpu
mkdir cpudemo
cd cpudemo
### 在后台执行这样一条脚本,显然,它执行了一个死循环,可以把计算机的 CPU 吃到 100%
while : ; do : ; done &
### 执行 top 查看 CPU 使用情况,CPU 占用 200%
### 查看 container 目录下的文件,看到 container 控制组里的 CPU quota 还没有任何限制(即:-1),CPU period 则是默认的 100 ms(100000 us):
### 通过 cgroup 限制 cpu
cat /sys/fs/cgroup/cpu/cpudemo/cpu.cfs_quota_us
-1
cat /sys/fs/cgroup/cpu/cpudemo/cpu.cfs_period_us
100000
### 设置 cpuquota
echo 10000 > /sys/fs/cgroup/cpu/cpudemo/cpu.cfs_quota_us
### 我们把被限制的进程的 PID 写入 container 组里的 tasks 文件,上面的设置就会对该进程生效了:
echo 7152 > /sys/fs/cgroup/cpu/cpudemo/tasks
### 执行 top 查看 CPU 使用情况,CPU 占用变为 10%
而至于在这些控制组下面的资源文件里填上什么值,就靠用户执行 docker run 时的参数指定了,比如这样一条命令:
docker run -d --name test-cpu --cpu-period=100000 --cpu-quota=20000 nginx
在启动这个容器后,我们可以通过查看 Cgroups 文件系统下,CPU 子系统中,“docker”这个控制组里的资源限制文件的内容来确认:
# `/sys/fs/cgroup/cpu/docker/<longid>/`在 cgroup v1 上,`cgroupfs`驱动程序
cat /sys/fs/cgroup/cpu/docker/7be62ae914a3/cpu.cfs_period_us
100000
cat /sys/fs/cgroup/cpu/docker/7ee16258ec08/cpu.cfs_quota_us
20000
# `/sys/fs/cgroup/memory/system.slice/docker-<longid>.scope/`在 cgroup v1 上,`systemd`驱动程序
[root@gv41New95 ~]# cat /sys/fs/cgroup/cpu/system.slice/docker-54b567daf241d5c29f0bd4016a1025b97c81c7b018a2f51a5613def29be6bd99.scope/cpu.cfs_period_us
100000
[root@gv41New95 ~]# cat /sys/fs/cgroup/cpu/system.slice/docker-54b567daf241d5c29f0bd4016a1025b97c81c7b018a2f51a5613def29be6bd99.scope/cpu.cfs_quota_us
20000
这就意味着这个 Docker 容器,只能使用到 20% 的 CPU 带宽。
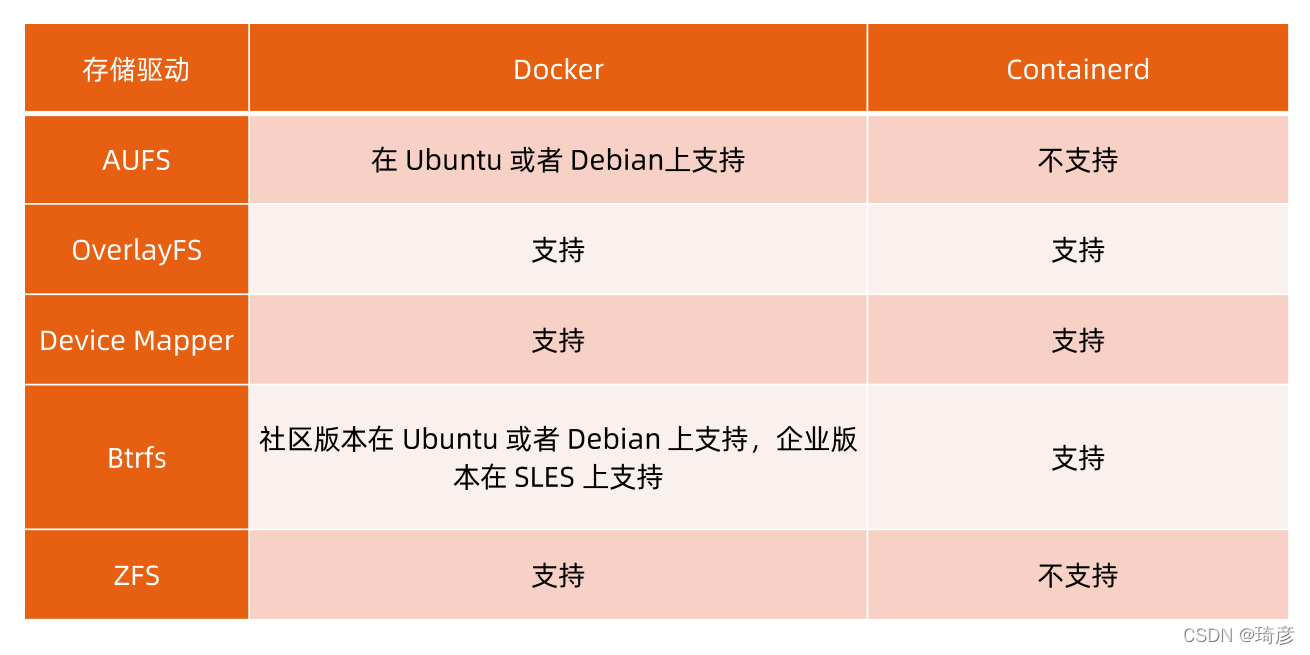
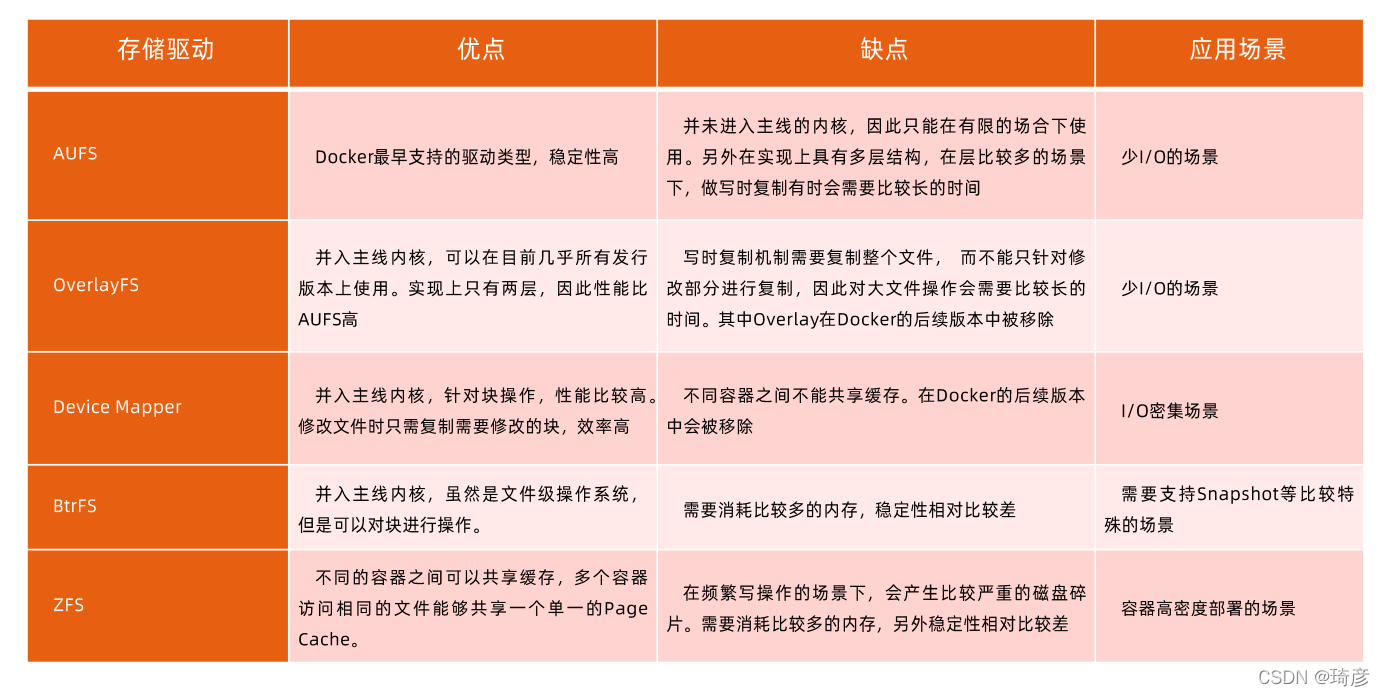
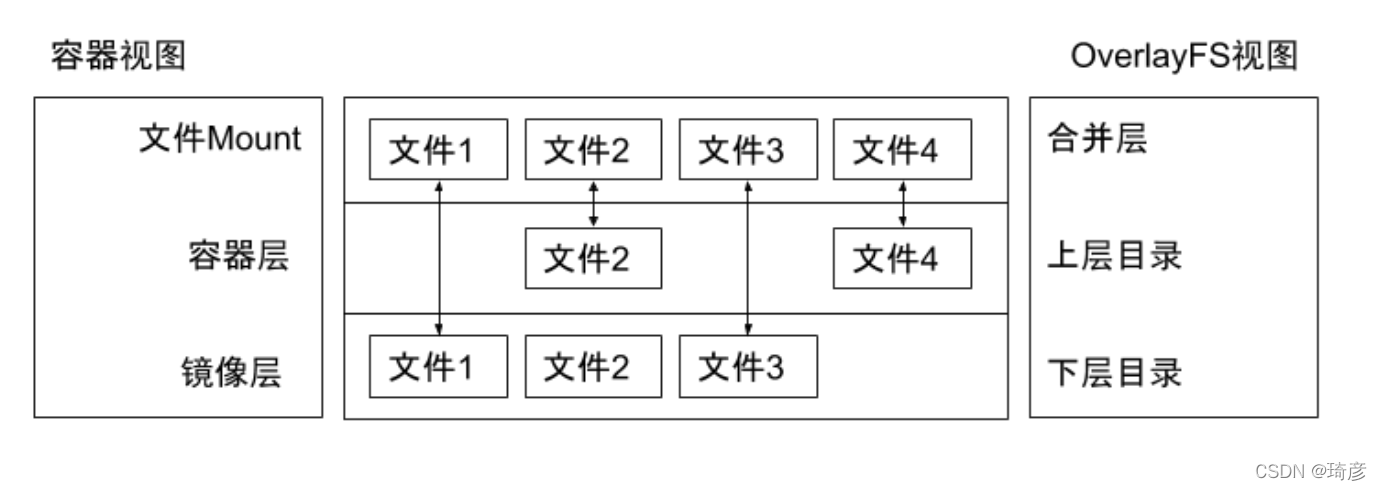
3. 文件系统
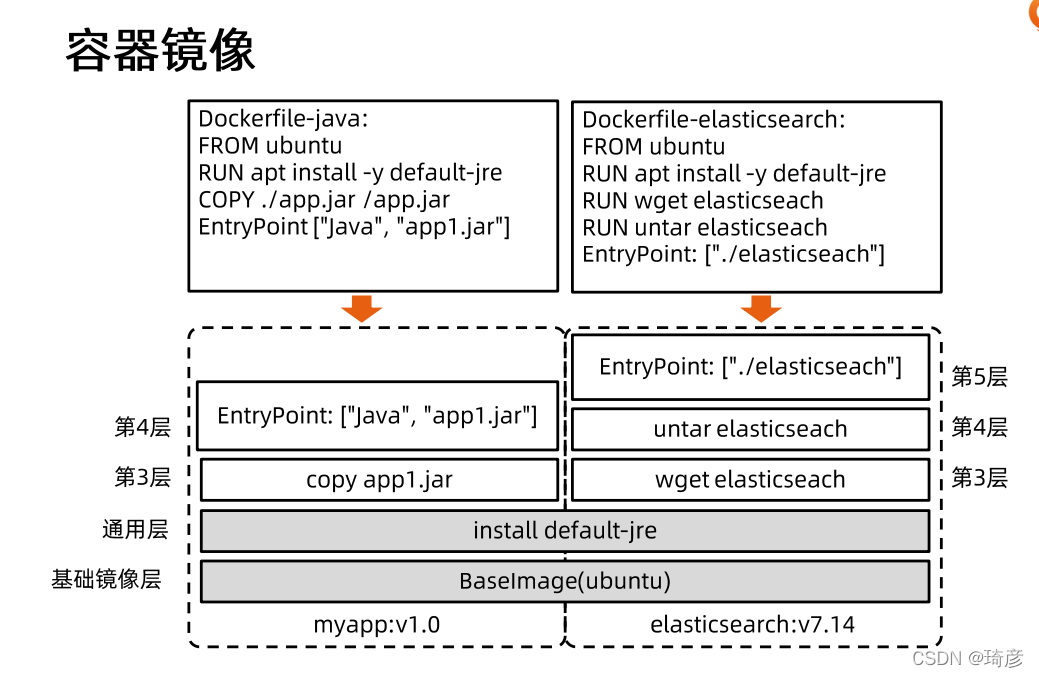
Docker 公司在实现 Docker 镜像时并没有沿用以前制作 rootfs 的标准流程,而是做了一个小小的创新:
Docker 在镜像的设计中,引入了层(layer)的概念。也就是说,用户制作镜像的每一步操作,都会生成一个层,也就是一个增量 rootfs。
当然,这个想法不是凭空臆造出来的,而是用到了一种叫作联合文件系统(Union File System)的能力。
rootfs。它只是一个操作系统的所有文件和目录,并不包含内核,最多也就几百兆。而相比之下,传统虚拟机的镜像大多是一个磁盘的“快照”,磁盘有多大,镜像就至少有多大。
Union FS
- 将不同目录挂载到同一个虚拟文件系统下(unite several directories into a single virtual filesystem)
的文件系统 - 支持为每一个成员目录(类似Git Branch)设定 readonly、readwrite 和 whiteout-able 权限
- 文件系统分层,对readonly权限的branch可以逻辑上进行修改(增量地,不影响readonly部分的)。
- 通常Union FS 有两个用途,一方面可以将多个 disk 挂到同一个目录下,另一个更常用的就是将一个
readonly的branch和一个writeable的branch联合在一起。
对于 Docker的AuFS 来说,它最关键的目录结构在 /var/lib/docker 路径下的 diff 目录:
/var/lib/docker/aufs/diff/<layer_id>
而这个目录的作用,我们不妨通过一个具体例子来看一下。
现在,我们启动一个容器,比如:
$ docker run -d ubuntu:latest sleep 3600
这时候,Docker 就会从 Docker Hub 上拉取一个 Ubuntu 镜像到本地。
这个所谓的“镜像”,实际上就是一个 Ubuntu 操作系统的 rootfs,它的内容是 Ubuntu 操作系统的所有文件和目录。不过,与之前我们讲述的 rootfs 稍微不同的是,Docker 镜像使用的 rootfs,往往由多个“层”组成:
$ docker image inspect ubuntu:latest | grep Layers -C 10
...
"RootFS": {
"Type": "layers",
"Layers": [
"sha256:f49017d4d5ce9c0f544c...",
"sha256:8f2b771487e9d6354080...",
"sha256:ccd4d61916aaa2159429...",
"sha256:c01d74f99de40e097c73...",
"sha256:268a067217b5fe78e000..."
]
}
可以看到,这个 Ubuntu 镜像,实际上由五个层组成。这五个层就是五个增量 rootfs,每一层都是 Ubuntu 操作系统文件与目录的一部分;而在使用镜像时,Docker 会把这些增量联合挂载在一个统一的挂载点上(等价于前面例子里的“/C”目录)。
容器镜像
容器存储驱动
OverlayFS练习
OverlayFS也是一种与 AUFS 类似的联合文件系统,同样属于文件级的存储驱动,包含了最初的 Overlay和
更新更稳定的overlay2。
Overlay只有两层:upper 层和 lower 层,lower层代表镜像层;upper 层代表容器可写层。
### Create test lab
mkdir testOverlay && cd $_
mkdir upper lower merged work
echo "from lower" > lower/in_lower.txt
echo "from upper" > upper/in_upper.txt
echo "from lower" > lower/in_both.txt
echo "from upper" > upper/in_both.txt
### Check it
tree .
.
├── lower
│ ├── in_both.txt
│ └── in_lower.txt
├── merged
├── upper
│ ├── in_both.txt
│ └── in_upper.txt
└── work
4 directories, 4 files
### Combine
sudo mount -t overlay overlay -o lowerdir=`pwd`/lower,upperdir=`pwd`/upper,workdir=`pwd`/work `pwd`/merged
### Check the merged file
cat merged/in_both.txt
cat merged/in_lower.txt
cat merged/in_upper.txt
df -h | grep testOverlay
overlay 29G 9.7G 18G 36% /root/testlab/merged
### Delete merged file
delete merged/in_both.txt
delete merged/in_lower.txt
delete merged/in_upper.txt
所以说,容器,其实是一种特殊的进程而已。
现在,你应该可以理解,对 Docker 项目来说,它最核心的原理实际上就是为待创建的用户进程:
- 启用 Linux Namespace 配置;
- 设置指定的 Cgroups 参数;
- 切换进程的根目录(Change Root)
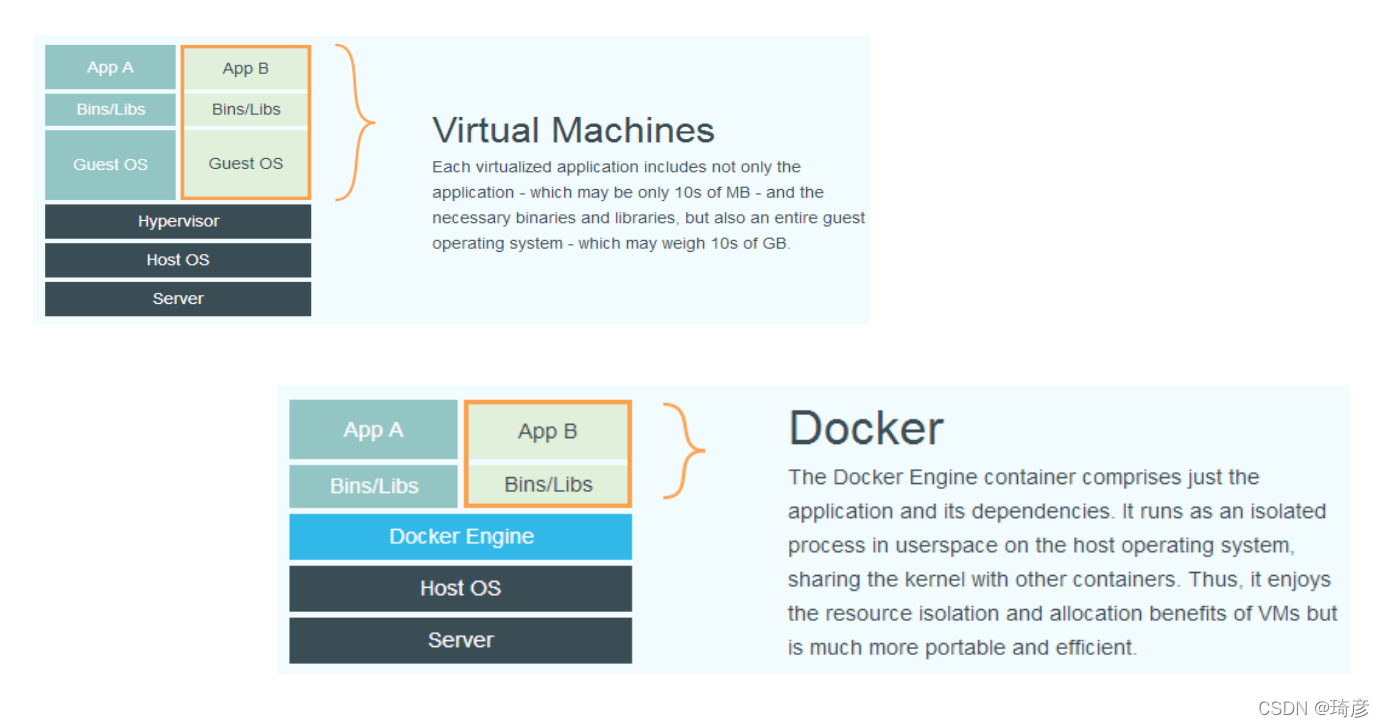
虚拟机与容器技术的对比图
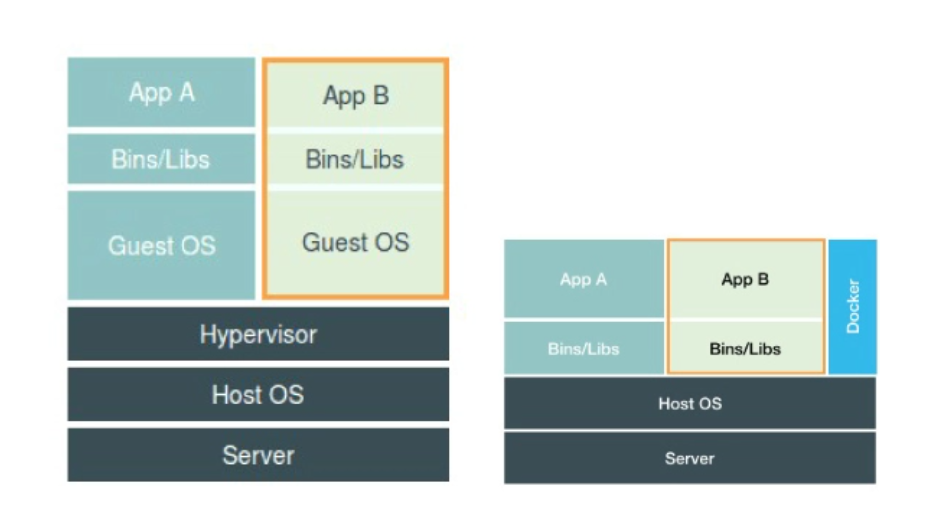
在之前虚拟机与容器技术的对比图里,不应该把 Docker Engine 或者任何容器管理工具放在跟 Hypervisor 相同的位置,因为它们并不像 Hypervisor 那样对应用进程的隔离环境负责,也不会创建任何实体的“容器”,真正对隔离环境负责的是宿主机操作系统本身。
所以,在这个对比图里,我们应该把 Docker 画在跟应用同级别并且靠边的位置。这意味着,用户运行在容器里的应用进程,跟宿主机上的其他进程一样,都由宿主机操作系统统一管理,只不过这些被隔离的进程拥有额外设置过的 Namespace 参数。而 Docker 项目在这里扮演的角色,更多的是旁路式的辅助和管理工作。
Docker优势
Kubernetes
容器本身没有价值,有价值的是“容器编排”。
一个“容器”,实际上是一个由 Linux Namespace、Linux Cgroups 和 rootfs 三种技术构建出来的进程的隔离环境。
从这个结构中我们不难看出,一个正在运行的 Linux 容器,其实可以被“一分为二”地看待:
- 一组联合挂载在 /var/lib/docker/aufs/mnt 上的 rootfs,这一部分我们称为“容器镜像”(Container Image),是容器的静态视图;
- 一个由 Namespace+Cgroups 构成的隔离环境,这一部分我们称为“容器运行时”(Container Runtime),是容器的动态视图。
更进一步地说,作为一名开发者,我并不关心容器运行时的差异。因为,在整个“开发 - 测试 - 发布”的流程中,真正承载着容器信息进行传递的,是容器镜像,而不是容器运行时。
这个重要假设,正是容器技术圈在 Docker 项目成功后不久,就迅速走向了“容器编排”这个“上层建筑”的主要原因:作为一家云服务商或者基础设施提供商,我只要能够将用户提交的 Docker 镜像以容器的方式运行起来,就能成为这个非常热闹的容器生态图上的一个承载点,从而将整个容器技术栈上的价值,沉淀在我的这个节点上。
更重要的是,只要**从我这个承载点向 Docker 镜像制作者和使用者方向回溯,整条路径上的各个服务节点,比如 CI/CD、监控、安全、网络、存储等等,都有我可以发挥和盈利的余地。**这个逻辑,正是所有云计算提供商如此热衷于容器技术的重要原因:通过容器镜像,它们可以和潜在用户(即,开发者)直接关联起来。
容器,提供应用级的主机抽象;Kubernetes,提供应用级的集群抽象。
时光回溯
让我们回顾一下为什么 Kubernetes 如此有用。
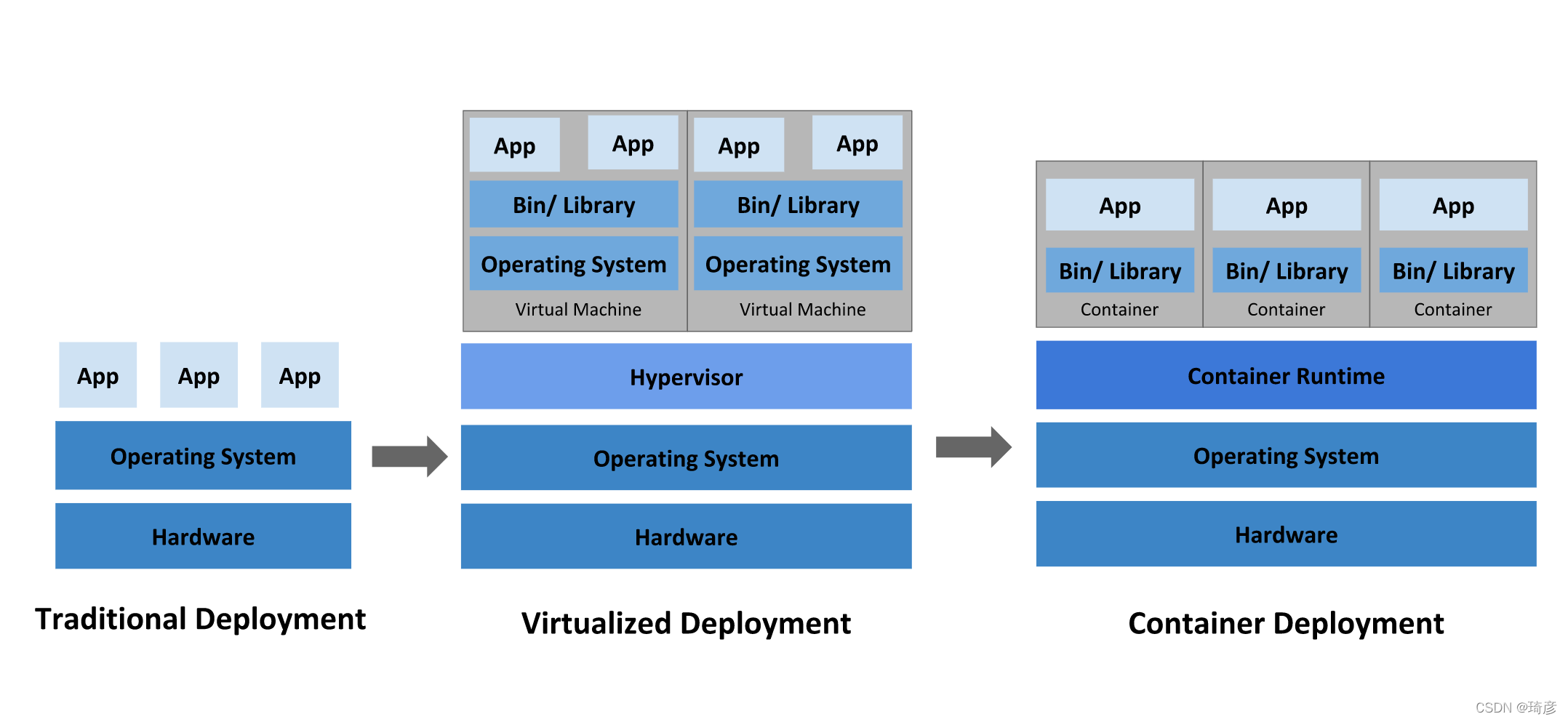
传统部署时代:
早期,各个组织机构在物理服务器上运行应用程序。无法为物理服务器中的应用程序定义资源边界,这会导致资源分配问题。 例如,如果在物理服务器上运行多个应用程序,则可能会出现一个应用程序占用大部分资源的情况, 结果可能导致其他应用程序的性能下降。 一种解决方案是在不同的物理服务器上运行每个应用程序,但是由于资源利用不足而无法扩展, 并且维护许多物理服务器的成本很高。
虚拟化部署时代:
作为解决方案,引入了虚拟化。虚拟化技术允许你在单个物理服务器的 CPU 上运行多个虚拟机(VM)。 虚拟化允许应用程序在 VM 之间隔离,并提供一定程度的安全,因为一个应用程序的信息 不能被另一应用程序随意访问。
虚拟化技术能够更好地利用物理服务器上的资源,并且因为可轻松地添加或更新应用程序 而可以实现更好的可伸缩性,降低硬件成本等等。
每个 VM 是一台完整的计算机,在虚拟化硬件之上运行所有组件,包括其自己的操作系统。
容器部署时代:
容器类似于 VM,但是它们具有被放宽的隔离属性**,可以在应用程序之间共享操作系统(OS)。 因此,容器被认为是轻量级的**。容器与 VM 类似,具有自己的文件系统、CPU、内存、进程空间等。 由于它们与基础架构分离,因此可以跨云和 OS 发行版本进行移植。
容器因具有许多优势而变得流行起来。下面列出的是容器的一些好处:
-
敏捷应用程序的创建和部署:与使用 VM 镜像相比,提高了容器镜像创建的简便性和效率。
-
持续开发、集成和部署:通过快速简单的回滚(由于镜像不可变性),支持可靠且频繁的 容器镜像构建和部署。
-
关注开发与运维的分离:在构建/发布时而不是在部署时创建应用程序容器镜像, 从而将应用程序与基础架构分离。
-
可观察性:不仅可以显示操作系统级别的信息和指标,还可以显示应用程序的运行状况和其他指标信号。
-
跨开发、测试和生产的环境一致性:在便携式计算机上与在云中相同地运行。
-
跨云和操作系统发行版本的可移植性:可在 Ubuntu、RHEL、CoreOS、本地、 Google Kubernetes Engine 和其他任何地方运行。
-
以应用程序为中心的管理:提高抽象级别,从在虚拟硬件上运行 OS 到使用逻辑资源在 OS 上运行应用程序。
-
松散耦合、分布式、弹性、解放的微服务:应用程序被分解成较小的独立部分, 并且可以动态部署和管理 - 而不是在一台大型单机上整体运行。
-
资源隔离:可预测的应用程序性能。
-
资源利用:高效率和高密度。
Borg 项目
在容器编排领域,Kubernetes 项目需要面对来自 Docker 公司和 Mesos 社区两个方向的压力。
不难看出,Swarm 和 Mesos 实际上分别从两个不同的方向讲出了自己最擅长的故事:
- Swarm 擅长的是跟 Docker 生态的无缝集成,
- 而 Mesos 擅长的则是大规模集群的调度与管理。
这两个方向,也是大多数人做容器集群管理项目时最容易想到的两个出发点。也正因为如此,Kubernetes 项目如果继续在这两个方向上做文章恐怕就不太明智了。
所以这一次,Kubernetes 选择的应对方式是:Borg。
跟很多基础设施领域先有工程实践、后有方法论的发展路线不同,Kubernetes 项目的理论基础则要比工程实践走得靠前得多,这当然要归功于 Google 公司在 2015 年 4 月发布的 Borg 论文了。
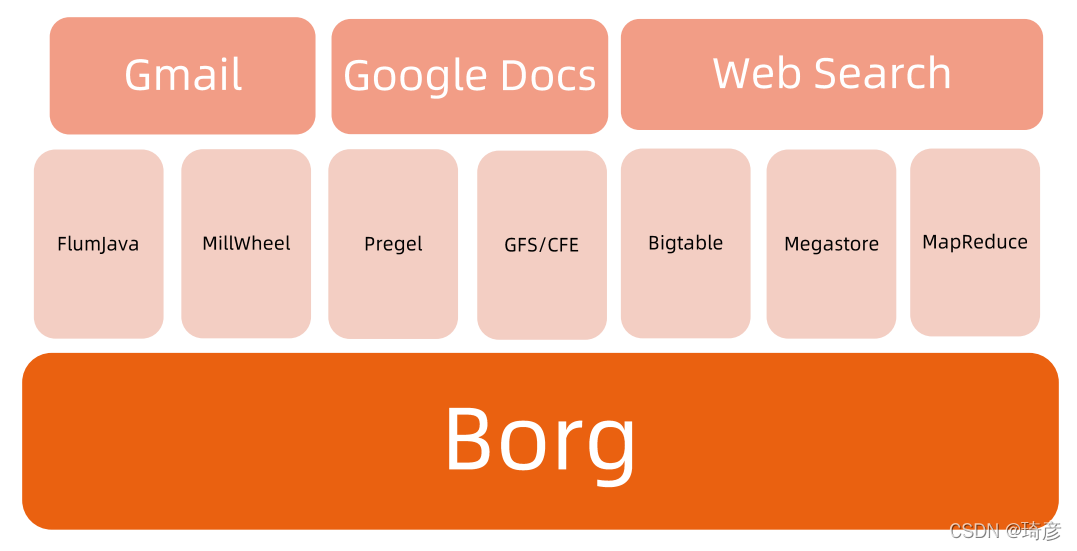
Borg 系统,一直以来都被誉为 Google 公司内部最强大的“秘密武器”。虽然略显夸张,但这个说法倒不算是吹牛。
因为,相比于 Spanner、BigTable 等相对上层的项目,Borg 要承担的责任,是承载 Google 公司整个基础设施的核心依赖。在 Google 公司已经公开发表的基础设施体系论文中,Borg 项目当仁不让地位居整个基础设施技术栈的最底层。
架构
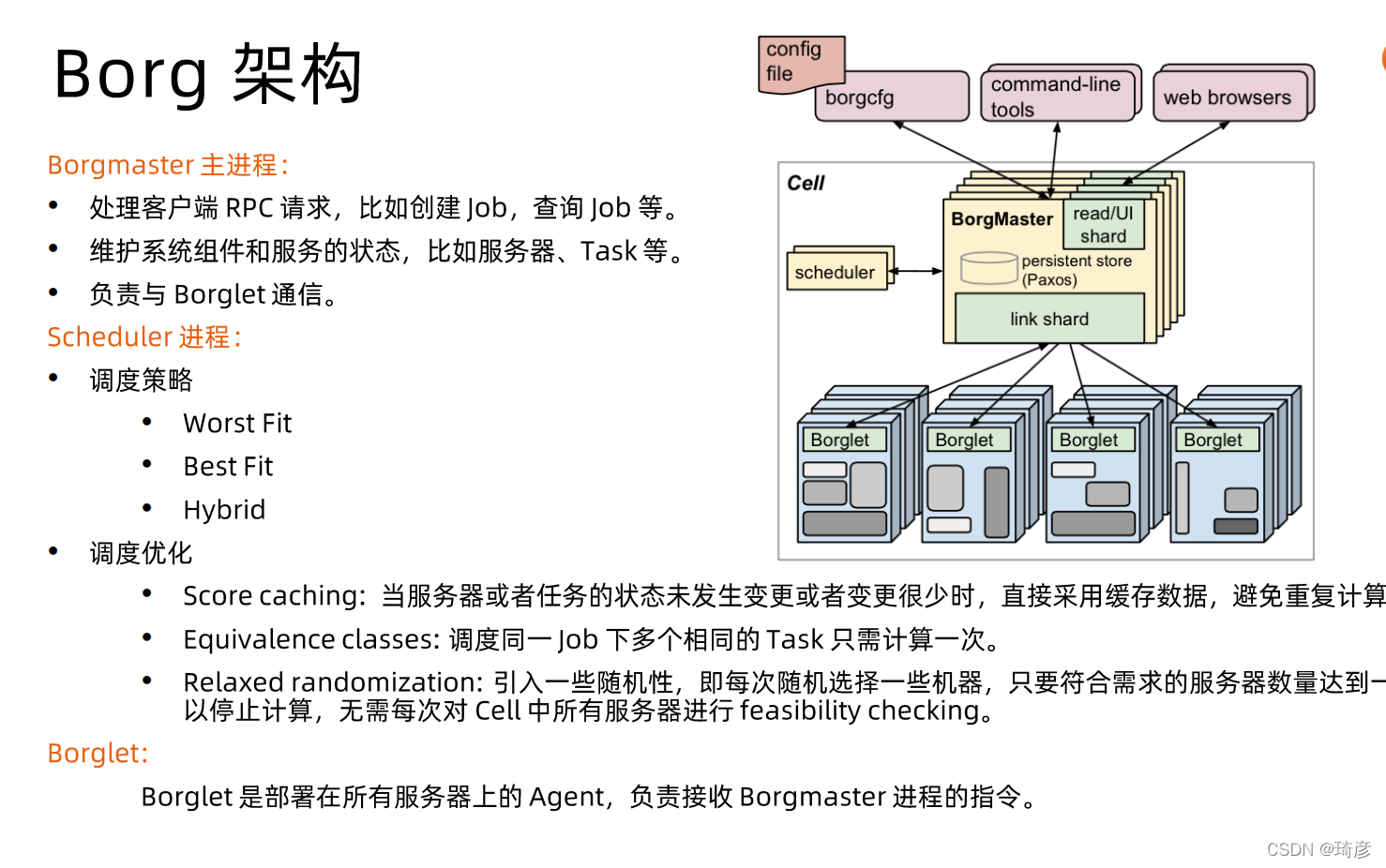
Worst Fit: 找资源类利用率最低的节点;空闲的资源和你的资源需求的差异最大; 使用使得节点的承载能力尽可能均衡
Best Fit: 堆叠模式,尽可能堆叠到一个节点,有利于后面的降本
Hybrid: 混合模式
Borg之前使用E-PVM算法用来评分,E-PVM对异构资源生成一个成本值,最小化部署一个任务的成本。在实践中,E-PVM将负载传播到了所有的机器上,为负载突刺留出了资源——但代价是增加了资源碎片,尤其是对需要占据一台机器大部分资源的大型task来说。有时候我们称之为**“最差匹配(worst fit)”**。与之相反的是**“最佳匹配(best fit)”。**“最佳匹配”尽可能的将任务填满机器。这使得某些机器没有在运行用户的job(但仍然运行着存储服务),因此部署大型任务就会非常直接,但是如果
Borg或用户误判了资源的需求,这样紧实的任务整合策略会导致性能受损,当有突发的高负载时会损害应用,尤其是对指定了低CPU需求的批处理job有负面影响,它们本应能轻易被调度并且抓住机会使用空闲的资源:20%的non-prod优先级的tasks只请求了少于0.1核的CPU。
隔离性
安全性隔
早期采用Chroot jail (iphone的越狱技术就是如此),后期版本基于 Namespace。
性能隔离
采用基于 Cgroup 的容器技术实现。Cgroup 也是由Google工程师贡献给Linux的。
在线任务(prod)是延时敏感(latency-sensitive)型的,优先级高,而离线任务(non-prod,
Batch)优先级低。
Borg 通过不同优先级之间的抢占式调度来优先保障在线任务的性能,牺牲离线任务。Borg 将资源类型分成两类:
可压榨的(compressible),CPU 是可压榨资源,资源耗尽不会终止进程;
不可压榨的(non-compressible),内存是不可压榨资源,资源耗尽进程会被终止。
特性
- 物理资源利用率高。
- 服务器共享,在进程级别做隔离。
- 应用高可用,故障恢复时间短。
- 调度策略灵活。
- 应用接入和使用方便,提供了完备的Job 描述语言,服务发现,实时状态监控和诊断工具。
优势
- 对外隐藏底层资源管理和调度、故障处理等。
- 实现应用的高可靠和高可用。
- 足够弹性,支持应用跑在成千上万的机器上。

Kubernetes架构
Kubernetes 项目正是依托着 Borg 项目的理论优势,才在短短几个月内迅速站稳了脚跟,进而确定了一个如下图所示的全局架构:
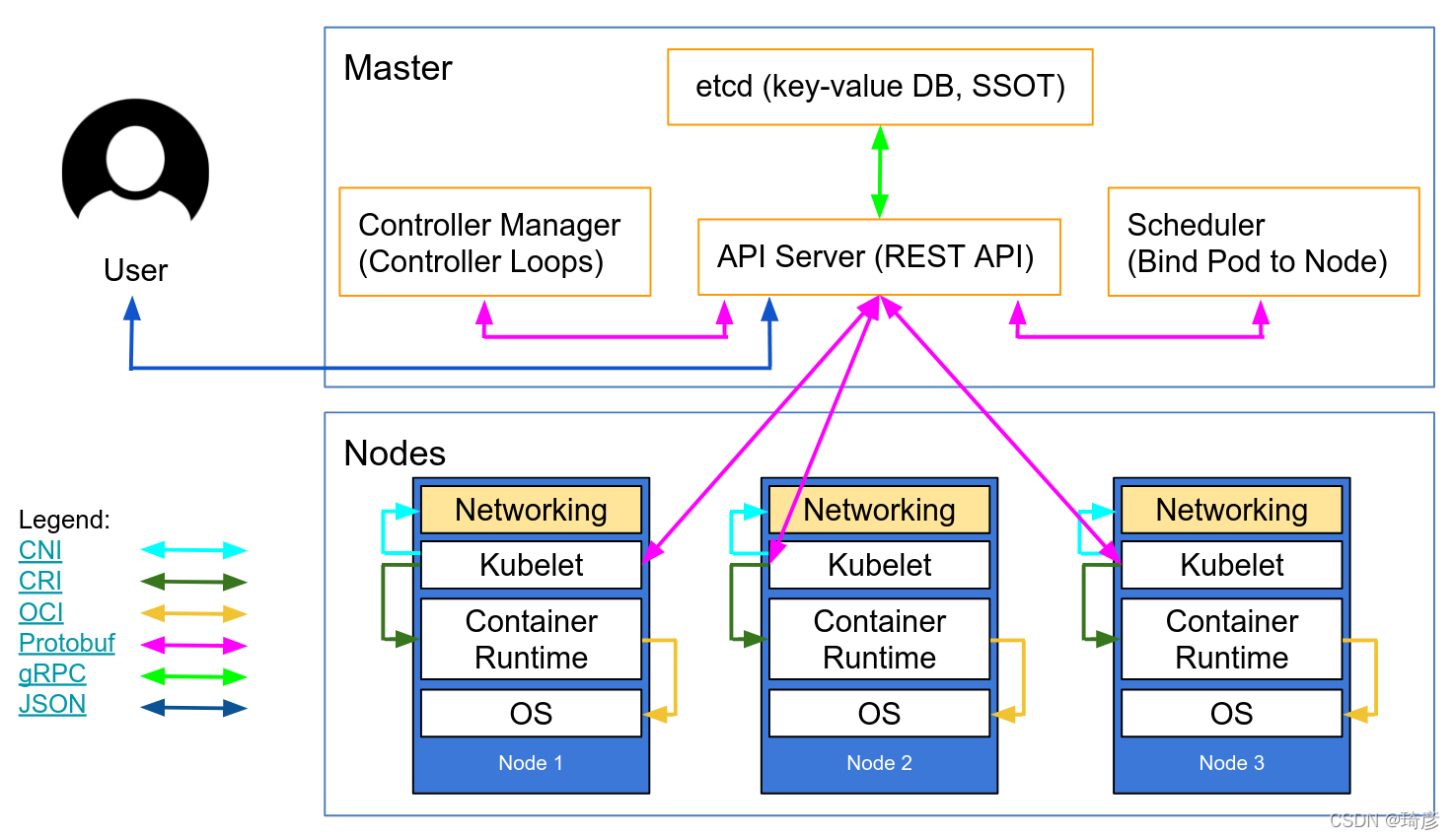
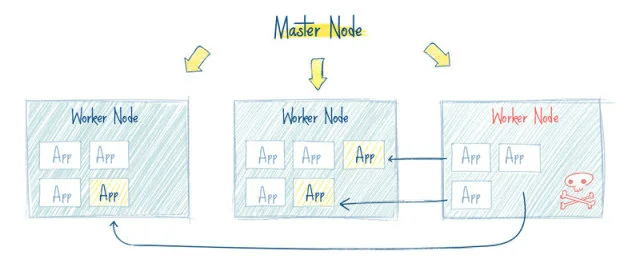
我们可以看到,Kubernetes 项目的架构,跟它的原型项目 Borg 非常类似,都由 Master 和 Node 两种节点组成,而这两种角色分别对应着控制节点和计算节点。
从一开始,Kubernetes 项目就没有像同时期的各种“容器云”项目那样,把 Docker 作为整个架构的核心,而仅仅把它作为最底层的一个容器运行时实现。
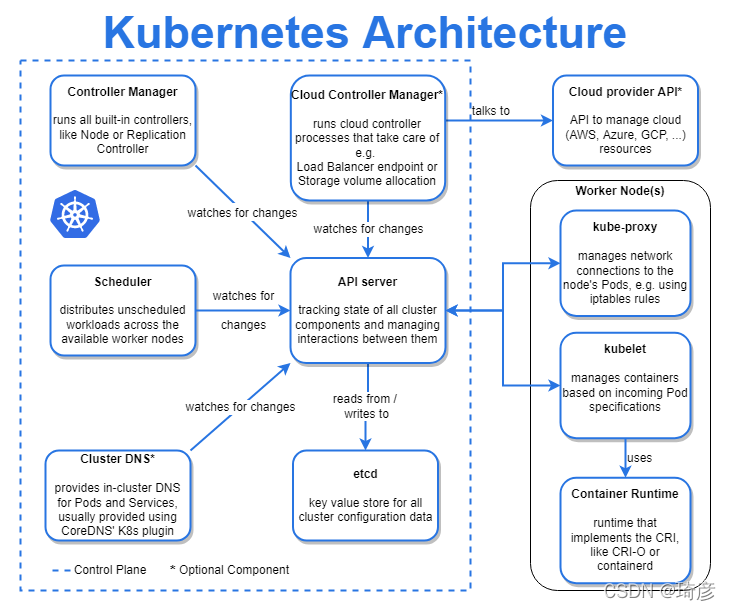
控制平面组件(Control Plane Components)
控制平面的组件对集群做出全局决策(比如调度),以及检测和响应集群事件(例如,当不满足部署的 replicas 字段时,启动新的 pod)。
控制平面组件可以在集群中的任何节点上运行。 然而,为了简单起见,设置脚本通常会在同一个计算机上启动所有控制平面组件, 并且不会在此计算机上运行用户容器。 请参阅使用 kubeadm 构建高可用性集群 中关于跨多机器控制平面设置的示例。
kube-apiserver
API 服务器是 Kubernetes 控制面的组件, 该组件公开了 Kubernetes API。 API 服务器是 Kubernetes 控制面的前端。
Kubernetes API 服务器的主要实现是 kube-apiserver。 kube-apiserver 设计上考虑了水平伸缩,也就是说,它可通过部署多个实例进行伸缩。 你可以运行 kube-apiserver 的多个实例,并在这些实例之间平衡流量。
Kube-APIServer 是 Kubernetes 最重要的核心组件之一,主要提供以下功能:
提供集群管理的 REST API 接口,包括:
- 认证 Authentication;
- 授权 Authorization;
- 准入 Admission(Mutating& Valiating)。
• 提供其他模块之间的数据交互和通信的枢纽(其他模块通过 APIServer 查询或
修改数据,只有 APIServer 才直接操作 etcd)。
• APIServer 提供 etcd 数据缓存以减少集群对 etcd 的访问。
etcd
etcd 是兼具一致性和高可用性的键值数据库,可以作为保存 Kubernetes 所有集群数据的后台数据库。
您的 Kubernetes 集群的 etcd 数据库通常需要有个备份计划。
要了解 etcd 更深层次的信息,请参考 etcd 文档。
etcd 是 CoreOS 基于 Raft 开发的分布式 key-value 存储,可用于服务发现、共享配置以及一致性保障(如数据库选主、分布式锁等)。
- 基本的 key-value 存储;
- 监听机制;
- key 的过期及续约机制,用于监控和服务发现;
- 原子 CAS 和 CAD,用于分布式锁和 leader 选举。
Kubernetes:etcdctl3的常用命令
#查询数据
export ETCDCTL_API=3
etcdctl --endpoints https://localhost:2379 --cert /etc/kubernetes/pki/etcd/server.crt --key
/etc/kubernetes/pki/etcd/server.key --cacert /etc/kubernetes/pki/etcd/ca.crt get --keys-only --prefix /
# 监听对象变化
etcdctl --endpoints https://localhost:2379 --cert /etc/kubernetes/pki/etcd/server.crt --key
/etc/kubernetes/pki/etcd/server.key --cacert /etc/kubernetes/pki/etcd/ca.crt watch --prefix
/registry/services/specs/default/mynginx
kube-scheduler
控制平面组件,负责监视新创建的、未指定运行节点(node)的 Pods,选择节点让 Pod 在上面运行。
调度决策考虑的因素包括单个 Pod 和 Pod 集合的资源需求、硬件/软件/策略约束、亲和性和反亲和性规范、数据位置、工作负载间的干扰和最后时限。
kube-controller-manager
在机器人技术和自动化领域,控制回路(Control Loop)是一个非终止回路,用于调节系统状态。
这是一个控制环的例子:房间里的温度自动调节器。
当你设置了温度,告诉了温度自动调节器你的期望状态(Desired State)。 房间的实际温度是当前状态(Current State)。
通过对设备的开关控制,温度自动调节器让其当前状态接近期望状态。在 Kubernetes 中,控制器通过监控集群 的公共状态,并致力于将当前状态转变为期望的状态。
控制器的协同工作原理
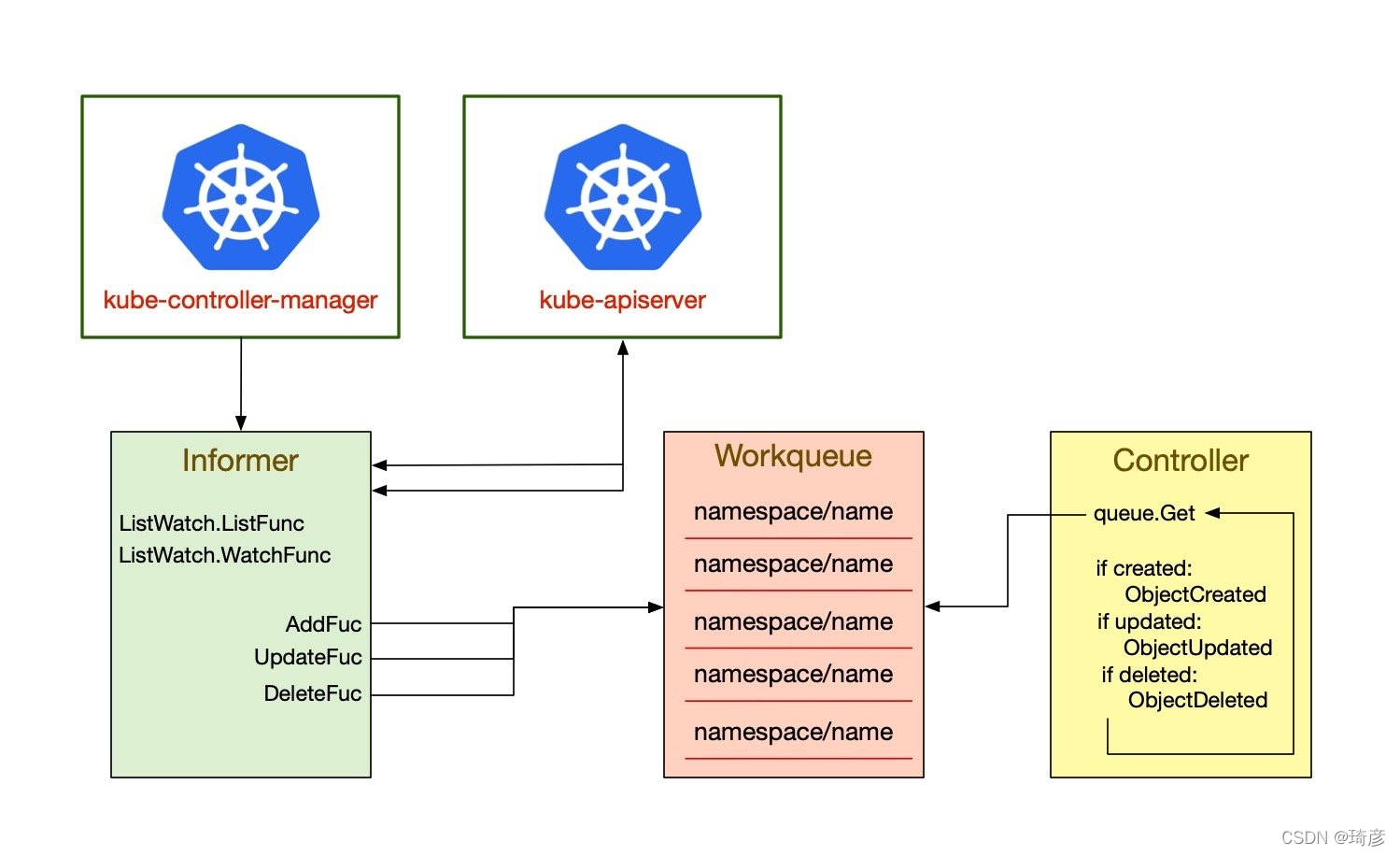
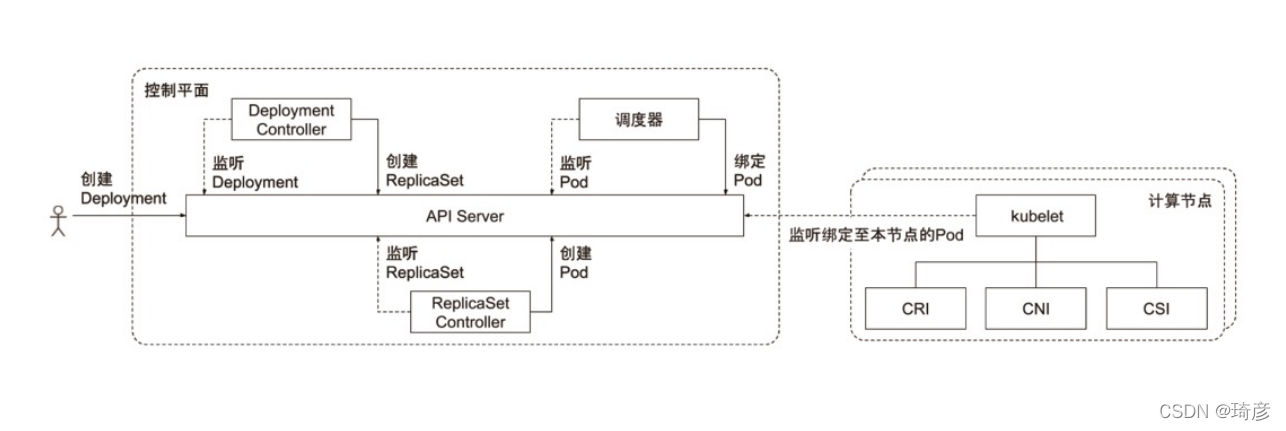
运行控制器进程的控制平面组件。
从逻辑上讲,每个控制器都是一个单独的进程, 但是为了降低复杂性,它们都被编译到同一个可执行文件,并在一个进程中运行。
这些控制器包括:
- 节点控制器(Node Controller): 负责在节点出现故障时进行通知和响应
- 任务控制器(Job controller): 监测代表一次性任务的 Job 对象,然后创建 Pods 来运行这些任务直至完成
- 端点控制器(Endpoints Controller): 填充端点(Endpoints)对象(即加入 Service 与 Pod)
- 服务帐户和令牌控制器(Service Account & Token Controllers): 为新的命名空间创建默认帐户和 API 访问令牌
Node 组件
节点组件在每个节点上运行,维护运行的 Pod 并提供 Kubernetes 运行环境。
kubelet
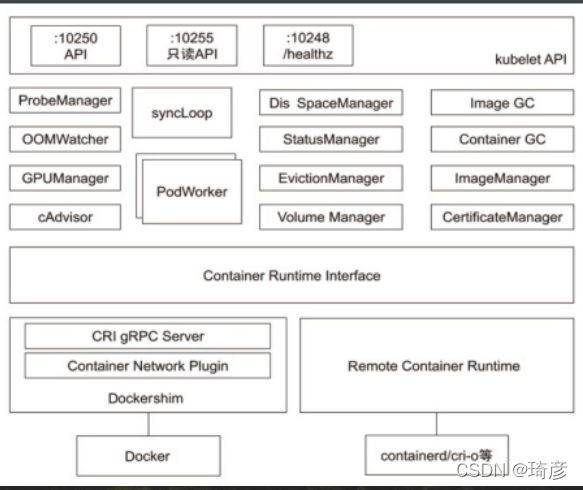
一个在集群中每个节点(node)上运行的代理。 它保证容器(containers)都 运行在 Pod 中。
kubelet 接收一组通过各类机制提供给它的 PodSpecs,确保这些 PodSpecs 中描述的容器处于运行状态且健康。 kubelet 不会管理不是由 Kubernetes 创建的容器。
Kubernetes 的初始化系统(init system)
• 从不同源获取 Pod 清单,并按需求启停 Pod 的核心组件:
- Pod 清单可从本地文件目录,给定的 HTTPServer 或 Kube-APIServer 等源头获取;
- Kubelet将运行时,网络和存储抽象成了 CRI,CNI,CSI。
负责汇报当前节点的资源信息和健康状态; • 负责 Pod 的健康检查和状态汇报
kube-proxy
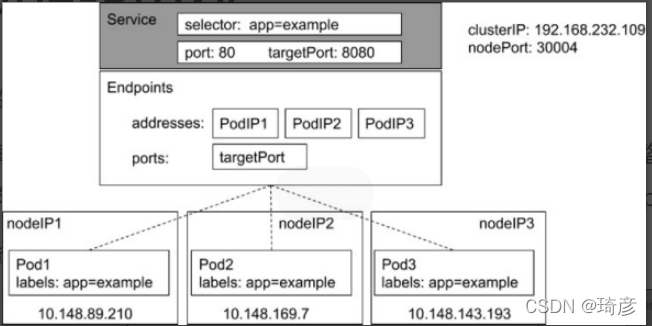
kube-proxy 是集群中每个节点上运行的网络代理, 实现 Kubernetes 服务(Service) 概念的一部分。
kube-proxy 维护节点上的网络规则。这些网络规则允许从集群内部或外部的网络会话与 Pod 进行网络通信。
如果操作系统提供了数据包过滤层并可用的话,kube-proxy 会通过它来实现网络规则。否则, kube-proxy 仅转发流量本身。
监控集群中用户发布的服务,并完成负载均衡配置。
每个节点的 Kube-Proxy 都会配置相同的负载均衡策略,使得整个集群的服务发现建立在分布式负载
均衡器之上,服务调用无需经过额外的网络跳转(Network Hop)。
负载均衡配置基于不同插件实现:
- userspace。
- 操作系统网络协议栈不同的 Hooks 点和插件:
– iptables;
– ipvs。
容器运行时(Container Runtime)
容器运行环境是负责运行容器的软件。
Kubernetes 支持容器运行时,例如 Docker、 containerd、CRI-O 以及 Kubernetes CRI (容器运行环境接口) 的其他任何实现。
Kubernetes 项目要解决的问题是什么?
编排?调度?容器云?还是集群管理?
实际上,这个问题到目前为止都没有固定的答案。因为在不同的发展阶段,Kubernetes 需要着重解决的问题是不同的。
但是,对于大多数用户来说,他们希望 Kubernetes 项目带来的体验是确定的:现在我有了应用的容器镜像,请帮我在一个给定的集群上把这个应用运行起来。
更进一步地说,我还希望 Kubernetes 能给我提供路由网关、水平扩展、监控、备份、灾难恢复等一系列运维能力。
等一下,这些功能听起来好像有些耳熟?这不就是经典 PaaS(比如,Cloud Foundry)项目的能力吗?
而且,有了 Docker 之后,我根本不需要什么 Kubernetes、PaaS,只要使用 Docker 公司的 Compose+Swarm 项目,就完全可以很方便地 DIY 出这些功能了!
所以说,如果 Kubernetes 项目只是停留在拉取用户镜像、运行容器,以及提供常见的运维功能的话,那么别说跟“原生”的 Docker Swarm 项目竞争了,哪怕跟经典的 PaaS 项目相比也难有什么优势可言。
Kubernetes能做什么?
容器是打包和运行应用程序的好方式。在生产环境中,你需要管理运行应用程序的容器,并确保不会停机。 例如,如果一个容器发生故障,则需要启动另一个容器。如果系统处理此行为,会不会更容易?
这就是 Kubernetes 来解决这些问题的方法! Kubernetes 为你提供了一个可弹性运行分布式系统的框架。 Kubernetes 会满足你的扩展要求、故障转移、部署模式等。 例如,Kubernetes 可以轻松管理系统的 Canary 部署。
而 Kubernetes 项目要着重解决的问题,则来自于 Borg 的研究人员在论文中提到的一个非常重要的观点:
运行在大规模集群中的各种任务之间,实际上存在着各种各样的关系。这些关系的处理,才是作业编排和管理系统最困难的地方。事实也正是如此。
Kubernetes 项目最主要的设计思想也是,从更宏观的角度,以统一的方式来定义任务之间的各种关系,并且为将来支持更多种类的关系留有余地。
云原生景观图
云原生景观始于基础架构,每一层都更接近实际应用程序。
https://landscape.cncf.io/
系列翻译
叮,你收到一份云原生景观简介
云原生景观:供应层(Provisioning)解决了什么问题?如何解决的?
云原生景观:运行时层解决了什么问题?如何解决的?
云原生景观:编排和管理层解决了什么问题?如何解决的?
云原生景观:应用程序定义和开发层解决了什么问题?如何解决的?
云原生景观:可观察性和分析解决了什么问题?如何解决的
原文链接:https://blog.csdn.net/fly910905/article/details/108032192
Kubernetes 生态系统
不妨从以下几个方面来看看,你一定会喜欢上它的哦!
1 一个平台搞定所有
使用 Kubernetes部署任何应用都是小菜一碟。只要应用可以打包成镜像,能够容器部署,Kubernetes就一定能启动它。
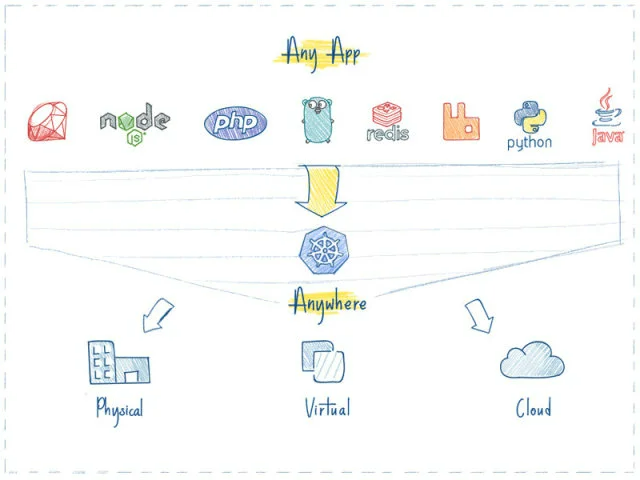
不管什么语言、什么框架写的应用(如:Java, Python, Node.js),Kubernetes都可以在任何环境中安全的启动它,如:物理服务器、虚拟机、云环境。
2 云环境无缝迁移
如果你有换云环境的需求,例如从 GCP 到 AWS,使用Kubernetes的话,你就不用有任何担心。

Kubernetes完全兼容各种云服务提供商,例如 Google Cloud、Amazon、Microsoft Azure,还可以工作在 CloudStack, OpenStack, OVirt, Photon, VSphere等。
3 高效的利用资源
看下图,左边是 4 个虚拟机,黄色和蓝色部分是运行的应用,白色部分是未使用的内存和处理器资源。
右边,同样的应用打包运行在容器中。
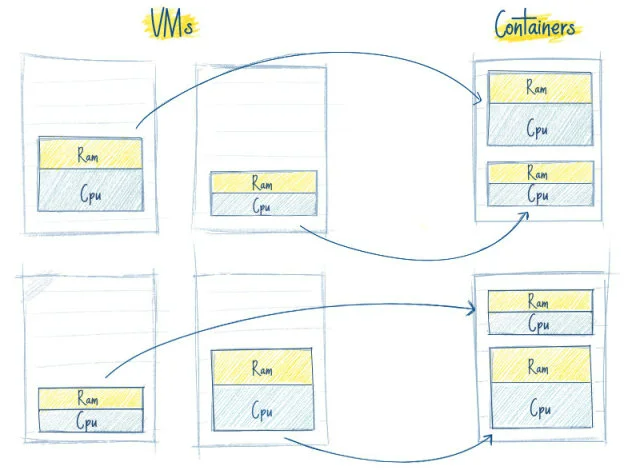
Kubernetes如果发现有节点工作不饱和,便会重新分配pod,帮助我们节省开销,高效的利用内存、处理器等资源。
如果一个节点宕机了,Kubernetes会自动重新创建之前运行在此节点上的pod,在其他节点上运行。
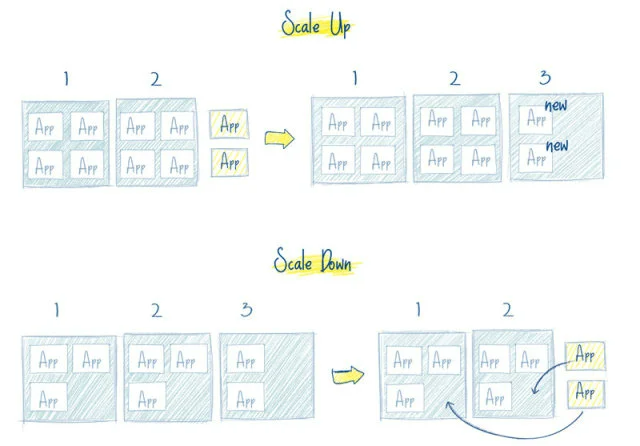
4 开箱即用的自动缩放能力
网络、负载均衡、复制等特性,对于Kubernetes都是开箱即用的。
pod 是无状态运行的,任何时候有 pod 宕了,立马会有其他 pod 接替它的工作,用户完全感觉不到。
如果用户量突然暴增,现有的 pod 规模不足了,那么会自动创建出一批新的 pod,以适应当前的需求。
反之亦然,当负载降下来的时候,Kubernetes也会自动缩减 pod 的数量。
5 使 CI/CD 更简单
你不必精通于Chef 和 Ansible这类工具,只需要对 CI 服务写个简单的脚本然后运行它,就会使用你的代码创建一个新的 pod,并部署到 Kubernetes集群里面。
应用打包在容器中使其可以安全的运行在任何地方,例如你的 PC、一个云服务器,使得测试极其简单。
6 可靠性
Kubernetes如此流行的一个重要原因是:应用会一直顺利运行,不会被 pod 或节点的故障所中断。
如果出现故障,Kubernetes会创建必要数量的应用镜像,并分配到健康的 pod 或节点中,直到系统恢复。
而且用户不会感到任何不适。
一个容器化的基础设施是有自愈能力的,可以提供应用程序的不间断操作,即使一部分基础设施出现故障。
Kubernetes使得应用的启动、迁移、部署变得简单又安全。
不必担心应用迁移后工作出现问题,也不用担心一台服务器无法应付突发的用户量。
需要注意的是,你的应用最好使用微服务架构进行开发,因为微服务应用比单体应用更适合做容器化。
从Pod 谈起
在一个真正的操作系统里,进程并不是“孤苦伶仃”地独自运行的,而是以进程组的方式,“有原则的”组织在一起。在这个进程的树状图中,每一个进程后面括号里的数字,就是它的进程组 ID(Process Group ID, PGID)
而 Kubernetes 项目所做的,其实就是将“进程组”的概念映射到了容器技术中,并使其成为了这个云计算“操作系统”里的“一等公民”。
Pod 就是 Kubernetes 世界里的“应用”;而一个应用,可以由多个容器组成。
首先,关于 Pod 最重要的一个事实是:它只是一个逻辑概念。
Pod,其实是一组共享了某些资源的容器。
具体的说:Pod 里的所有容器,共享的是同一个 Network Namespace,并且可以声明共享同一个 Volume。
共享Network Namespace(Infra 容器)
所以,在 Kubernetes 项目里,Pod 的实现需要使用一个中间容器,这个容器叫作 Infra 容器。在这个 Pod 中,Infra 容器永远都是第一个被创建的容器,而其他用户定义的容器,则通过 Join Network Namespace 的方式,与 Infra 容器关联在一起。这样的组织关系,可以用下面这样一个示意图来表达:
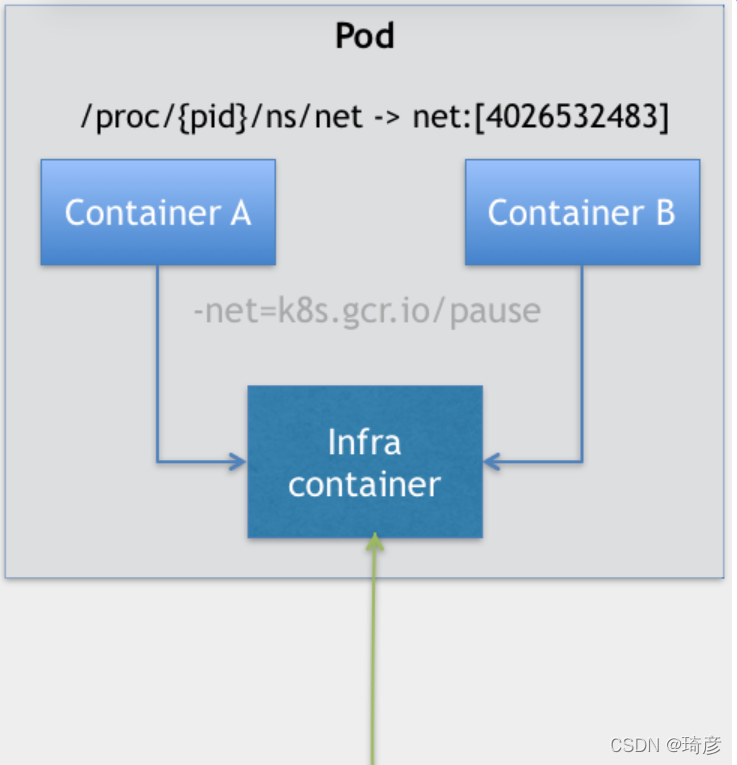
如上图所示,这个 Pod 里有两个用户容器 A 和 B,还有一个 Infra 容器。很容易理解,在 Kubernetes 项目里,Infra 容器一定要占用极少的资源,所以它使用的是一个非常特殊的镜像,叫作:k8s.gcr.io/pause。
像这样,围绕着容器和 Pod 不断向真实的技术场景扩展,我们就能够摸索出一幅如下所示的 Kubernetes 项目核心功能的“全景图”。
这也就意味着,对于 Pod 里的容器 A 和容器 B 来说:
-
它们可以直接使用 localhost 进行通信;
-
它们看到的网络设备跟 Infra 容器看到的完全一样;
-
一个 Pod 只有一个 IP 地址,也就是这个 Pod 的 Network Namespace 对应的 IP 地址;
-
当然,其他的所有网络资源,都是一个 Pod 一份,并且被该 Pod 中的所有容器共享;
-
Pod 的生命周期只跟 Infra 容器一致,而与容器 A 和 B 无关。
共享 Volume
有了这个设计之后,共享 Volume 就简单多了:Kubernetes 项目只要把所有 Volume 的定义都设计在 Pod 层级即可。
这样,一个 Volume 对应的宿主机目录对于 Pod 来说就只有一个,Pod 里的容器只要声明挂载这个 Volume,就一定可以共享这个 Volume 对应的宿主机目录。比如下面这个例子:
apiVersion: v1
kind: Pod
metadata:
name: two-containers
spec:
restartPolicy: Never
volumes:
- name: shared-data
hostPath:
path: /data
containers:
- name: nginx-container
image: nginx
volumeMounts:
- name: shared-data
mountPath: /usr/share/nginx/html
- name: debian-container
image: debian
volumeMounts:
- name: shared-data
mountPath: /pod-data
command: ["/bin/sh"]
args: ["-c", "echo Hello from the debian container > /pod-data/index.html"]
在这个例子中,debian-container 和 nginx-container 都声明挂载了 shared-data 这个 Volume。而 shared-data 是 hostPath 类型。所以,它对应在宿主机上的目录就是:/data。而这个目录,其实就被同时绑定挂载进了上述两个容器当中。
这就是为什么,nginx-container 可以从它的 /usr/share/nginx/html 目录中,读取到 debian-container 生成的 index.html 文件的原因。
容器间“紧密协作”关系
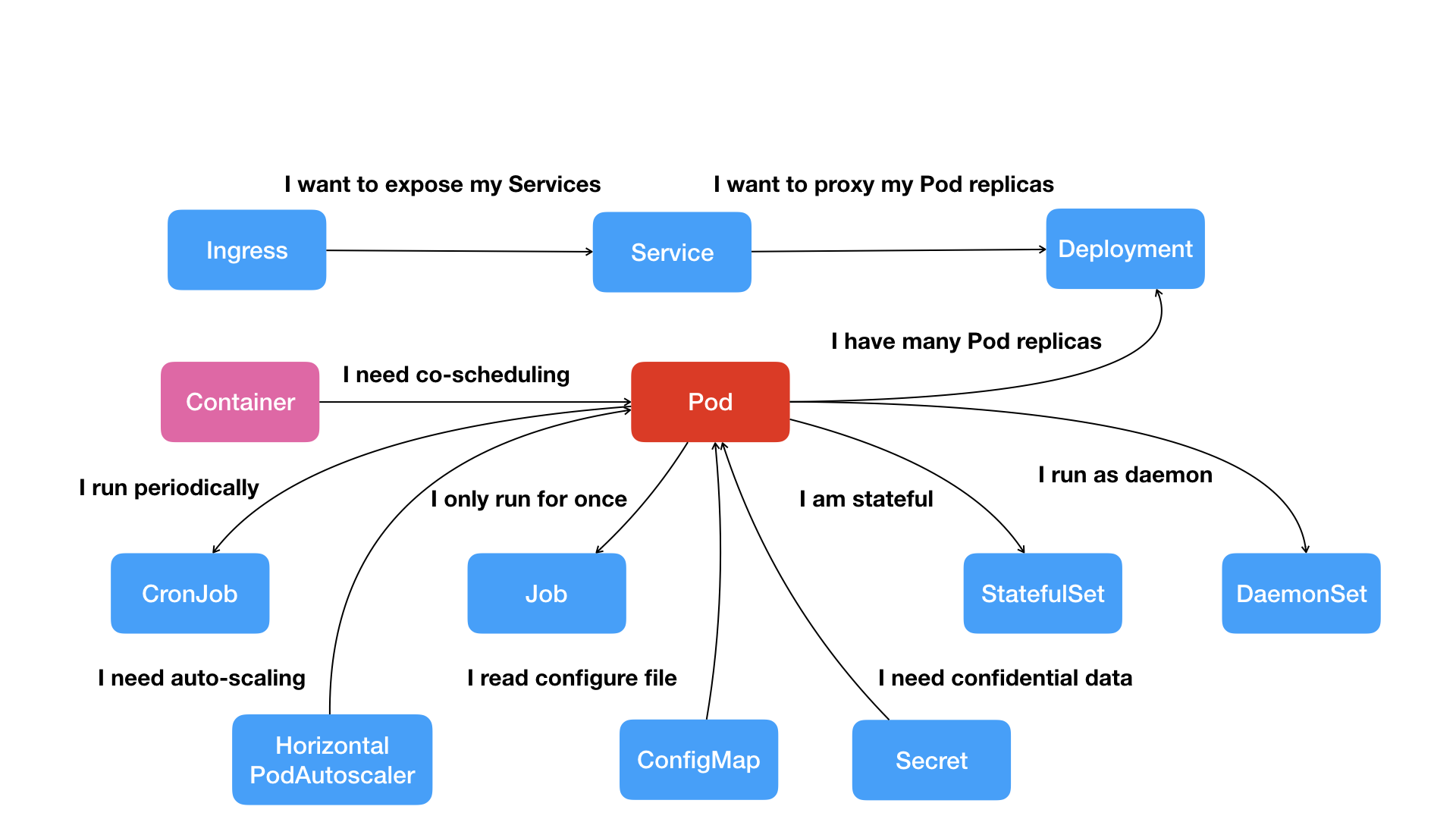
按照这幅图的线索,我们从容器这个最基础的概念出发,首先遇到了容器间“紧密协作”关系的难题,于是就扩展到了 Pod;
Pod 这个看似复杂的 API 对象,实际上就是对容器的进一步抽象和封装而已。
所以,Pod 对象,其实就是容器的升级版。它对容器进行了组合,添加了更多的属性和字段。这就好比给集装箱四面安装了吊环,使得 Kubernetes 这架“吊车”,可以更轻松地操作它。
在具体实现中,实际状态往往来自于 Kubernetes 集群本身。
比如,kubelet 通过心跳汇报的容器状态和节点状态,或者监控系统中保存的应用监控数据,或者控制器主动收集的它自己感兴趣的信息,这些都是常见的实际状态的来源。
而期望状态,一般来自于用户提交的 YAML 文件。
有了 Pod 之后,我们希望能一次启动多个应用的实例,这样就需要 Deployment 这个 Pod 的多实例管理器;
像 Deployment 这种控制器的设计原理,就是“用一种对象管理另一种对象”的“艺术”。
而有了这样一组相同的 Pod 后,我们又需要通过一个固定的 IP 地址和端口以负载均衡的方式访问它,于是就有了 Service。
可是,**如果现在两个不同 Pod 之间不仅有“访问关系”,还要求在发起时加上授权信息。**最典型的例子就是 Web 应用对数据库访问时需要 Credential(数据库的用户名和密码)信息。那么,在 Kubernetes 中这样的关系又如何处理呢?
Kubernetes 项目提供了一种叫作 Secret 的对象,它其实是一个保存在 Etcd 里的键值对数据。这样,你把 Credential 信息以 Secret 的方式存在 Etcd 里,Kubernetes 就会在你指定的 Pod(比如,Web 应用的 Pod)启动时,自动把 Secret 里的数据以 Volume 的方式挂载到容器里。这样,这个 Web 应用就可以访问数据库了。
除了应用与应用之间的关系外,应用运行的形态是影响“如何容器化这个应用”的第二个重要因素。
为此,Kubernetes 定义了新的、基于 Pod 改进后的对象。
比如 Job,用来描述一次性运行的 Pod(比如,大数据任务);
再比如 DaemonSet,用来描述每个宿主机上必须且只能运行一个副本的守护进程服务;
又比如 CronJob,则用于描述定时任务等等。
如此种种,正是 Kubernetes 项目定义容器间关系和形态的主要方法。
可以看到,Kubernetes 项目并没有像其他项目那样,为每一个管理功能创建一个指令,然后在项目中实现其中的逻辑。这种做法,的确可以解决当前的问题,但是在更多的问题来临之后,往往会力不从心。
相比之下**,在 Kubernetes 项目中,我们所推崇的使用方法是**:
- 首先,通过一个“编排对象”,比如 Pod、Job、CronJob 等,来描述你试图管理的应用;
- 然后,再为它定义一些“服务对象”,比如 Service、Secret、Horizontal Pod Autoscaler(自动水平扩展器)等。这些对象,会负责具体的平台级功能。
这种使用方法,就是所谓的“声明式 API”。这种 API 对应的“编排对象”和“服务对象”,都是 Kubernetes 项目中的 API 对象(API Object)。
这就是 Kubernetes 最核心的设计理念。
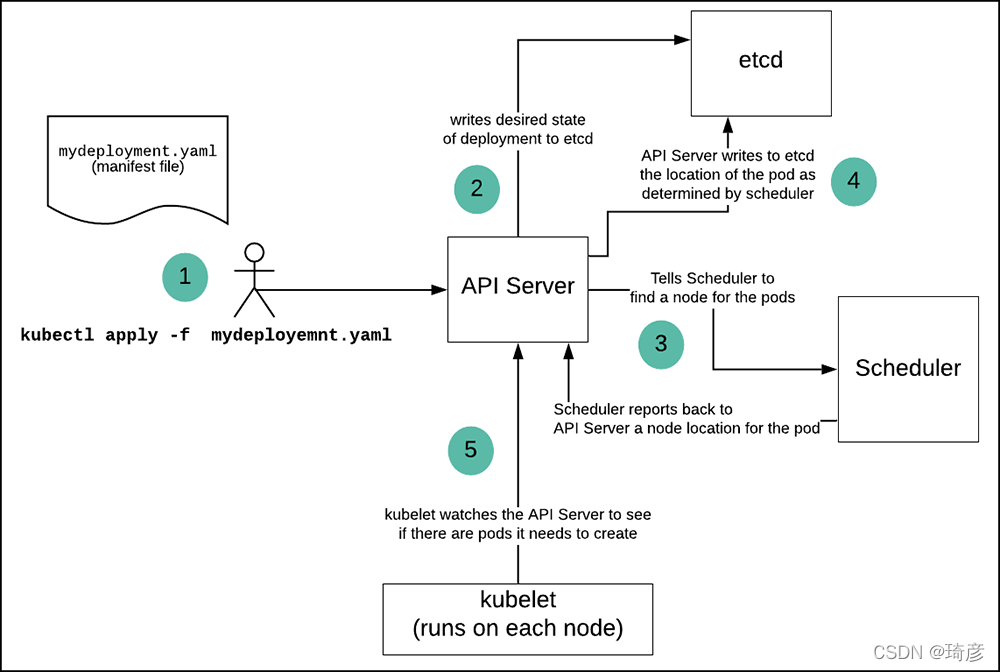
Kubernetes 项目如何启动一个容器化任务呢?
比如,我现在已经制作好了一个 Nginx 容器镜像,希望让平台帮我启动这个镜像。并且,我要求平台帮我运行两个完全相同的 Nginx 副本,以负载均衡的方式共同对外提供服务。
-
如果是自己 DIY 的话,可能需要启动两台虚拟机,分别安装两个 Nginx,然后使用 keepalived 为这两个虚拟机做一个虚拟 IP。
-
而如果使用 Kubernetes 项目呢?你需要做的则是编写如下这样一个 YAML 文件(比如名叫 nginx-deployment.yaml):
Kubernetes测试
部署 Deployment
kubectl apply -f <https://k8s.io/examples/application/deployment.yaml>
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment
spec:
selector:
matchLabels:
app: nginx
replicas: 2 # tells deployment to run 2 pods matching the template
template:
metadata:
labels:
app: nginx
spec:
containers:
- name: nginx
image: nginx:1.14.2
ports:
- containerPort: 80
部署 NodePort
apiVersion: v1
kind: Service
metadata:
name: my-nginx
spec:
selector:
app: nginx
type: NodePort
ports:
- protocol: TCP
port: 80
通过kubectl get services查看nginx服务对外暴露的端口, 浏览器访问如下

声明式API

-
声明式
-
符合OpenAPI规范的 https://kubernetes.io/zh/docs/concepts/overview/kubernetes-api/
GVK 和 GVR
Groups、Versions 和 Kinds 之间的关系
-
Kubernetes 中的
API Group只是相关功能的集合, 每个group包含一个或者多个
versions, 这样的关系可以让我们随着时间的推移,通过创建不同的versions来更改 API 的工作方式。 -
Kind - 每个
API group-version包含一个或者多个 API 类型, 我们称之为Kinds.
虽然同类型Kind在不同的version之间的表现形式可能不同,但是同类型Kind
必须能够存储其他Kind的全部数据,也就是说同类型Kind之间必须是互相兼容的(我们可 以把数据存到 fields 或者 annotations),这样当你使用老版本的API group-version时不会造成丢失或损坏,有关更多信息,请参见KubernetesAPI指南。 -
Resources: 你应该听别人提到过Resources,Resource是Kind在 API 中的标识,通常情况下
Kind和Resource是一一对应的, 但是有时候相同的Kind可能对应多个Resources, 比如
Scale Kind 可能对应很多 Resources:deployments/scale 或者 replicasets/scale,
但是在 CRD 中,每个Kind只会对应一种Resource。
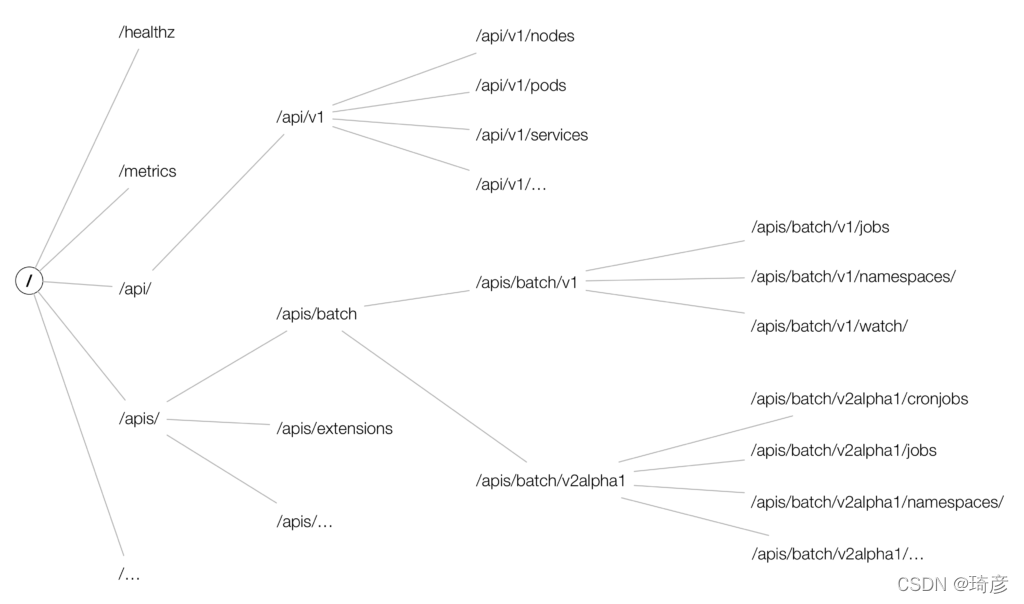
Kubernetes 组织资源的方式是以 REST 的 URI 的形式来的,而组织的路径就是:

GVR
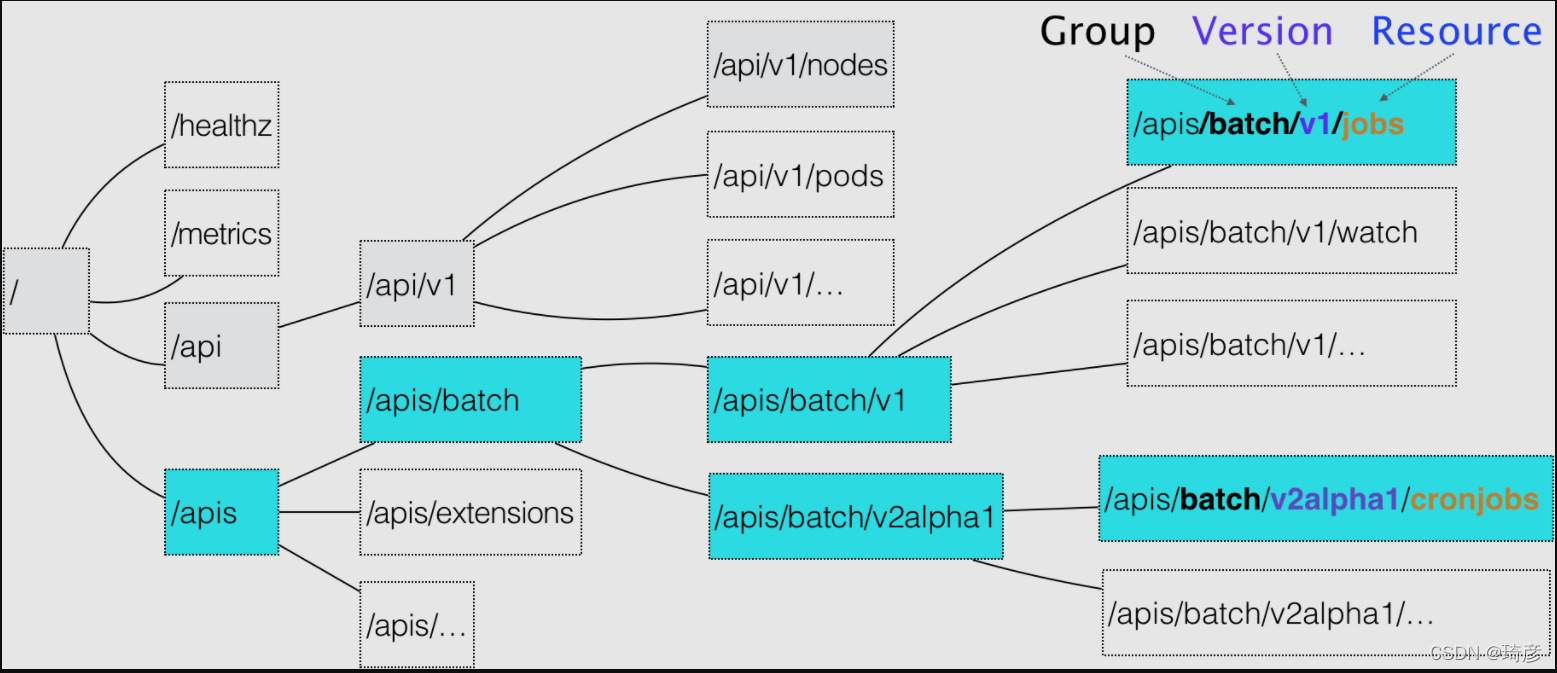
在这幅图中,你可以很清楚地看到Kubernetes 里 API 对象的组织方式,其实是层层递进的。
其实,理解了 GVK 之后再理解 GVR 就很容易了,这就是面向对象编程里面的类和对象的概念是一样的:
| Kubernetes | OOP |
|---|---|
| Kind | Class |
| Resource | Object |
好理解吧,Kind 其实就是一个类,用于描述对象的;而 Resource 就是具体的 Kind,可以理解成类已经实例化成对象了。
结构
TypeMeta
metadata
- finalizer
- resourceVersion
label
annotations
Spec
status