CVPR2017_CNN-SLAM Real-time dense monocular SLAM with learned depth prediction
关键词:基于CNN的单张图深度估计,语义SLAM,半稠密的直接法SLAM
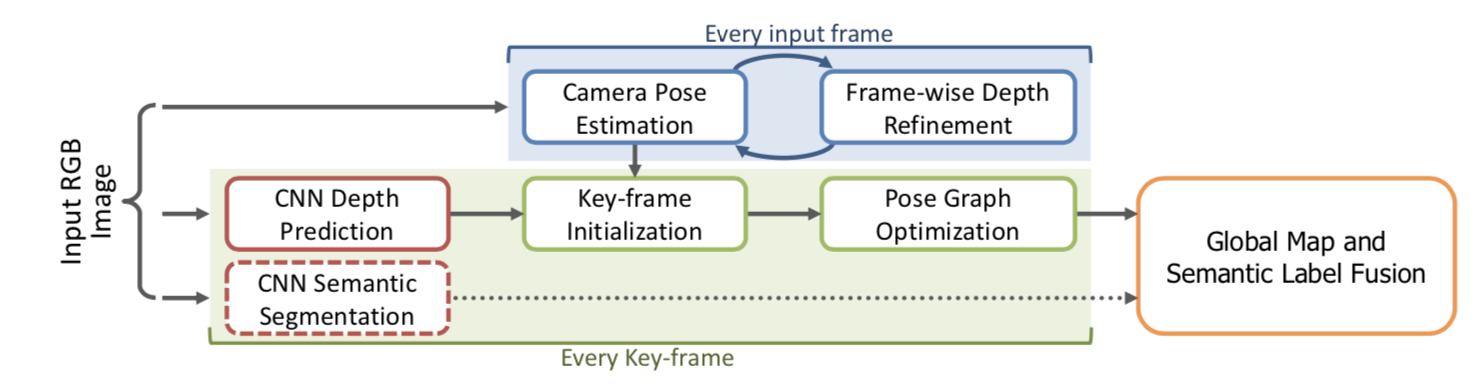
作者提出了一个利用CNN结合SLAM的应用,其SLAM过程如上图,具体解释如下:
- 作者首先筛选出关键帧,在关键帧上用训练好的CNN网络[1]来预测单帧图深度值得到深度图,并以此深度图作为SLAM架构先验深度。同时在关键帧上用训练好的另一个CNN网络来做语义分割。
- 随后像直接法SLAM的一样做BA(Bundle Adjustment),用高斯牛顿法,基于pose graph方法优化得到pose,和普通的半稠密 SLAM过程基本一样。
- 将深度图和语义分割图融合进全局已有的场景深度图(实际上是三维地图点集合了)和三维语义分割图中
作者的主要贡献是提出一个不确定性传播框架,将新产生的深度融合进已有的场景深度中,并refine CNN网络得到的深度(融合和普通深度融合比较相似,但refine过程和《Semi-densevisualodom- etry for a monocular camera》相似)。
此过程中,每个关键帧带一个深度图,一个(深度)不确定图(之所以称为图是因为不确定值与深度图的每个值一一对应),一个pose。不确定图是由当前关键帧的和最近邻的关键帧的深度差的平方距离:
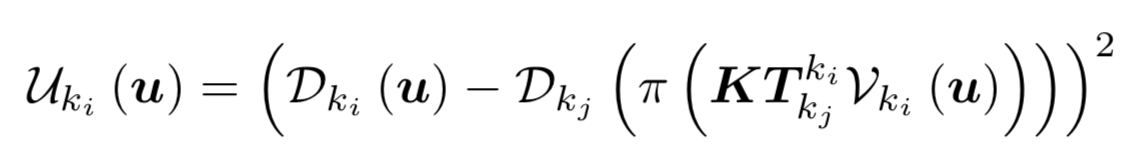
随着不断新传入的帧中选出的得到的深度图,将新产生的深度图与已存在的地图(深度图)进行融合。如果两个深度数据的焦距不一样,易知两个深度数据的尺度之比即是焦距之比。所以乘上焦距的比值即可。第i个关键帧ki与第j个关键帧kj的深度图、不确定度图的融合方程:
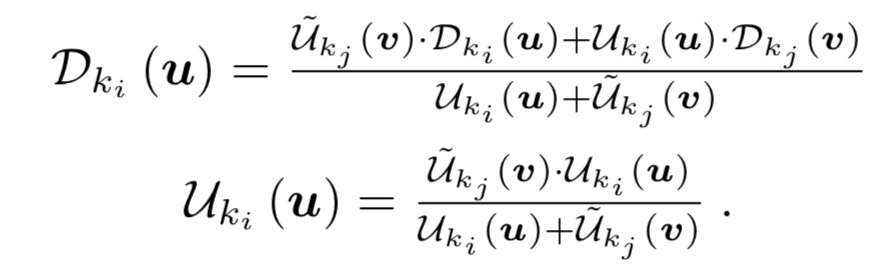
最后过程除了对深度图进行融合,还对语义图进行融合( Global Segmentation Model (GSM)方法),最后生成一个三维点的语义地图。
附注:
[1] CNN估计深度部分受论文《 Deeper depth prediction with fully convolutional residual networks》的启发